Paul Boddie's Free Software-related blog
Paul's activities and perspectives around Free Software
Concise Attribute Initialisation in Lichen… and Python?
January 22nd, 2018
In my review of 2017, I mentioned a project of mine to make a Python-like language called Lichen that is more amenable to compile-time analysis than Python is, while still having a feature set I might actually be able to use in “real” programs one day. There are a lot of different “moving parts” in the Lichen toolchain, and being preoccupied with various other projects and activities, I haven’t been able to get back into working on it properly in the last few months.
Recently, as I found myself writing Python code for another of my projects, I got to wondering about something in Python that can occur a lot: the initialisation of instance attributes. Here is a classic example:
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
# For illustration, here is how the class is used...
p = Point(640, 512)
print p.x, p.y # 640 512
In this example, having to assign the parameter values to the instance attributes is not much of a hardship. But with more verbose initialisation methods with more parameters and more attributes involved, writing everything out can be tiresome. Moreover, mistakes can be made, particularly if the interfaces and structures are evolving. Naturally, there are a range of improvements and measures that attempt to alleviate the problem. Here is the most obvious:
class Point:
def __init__(self, x, y):
self.x = x; self.y = y
This just puts the same statements on one line, so let us move beyond it to the next attempt:
class Point:
def __init__(self, x, y):
self.x, self.y = x, y
Here, we are actually performing “tuple assignment”, with the parameter values being placed in a tuple whose elements are then assigned to the names in the corresponding positions on the left-hand side of the assignment.
Now, without any Python “magic”, this is probably as far as you can get. The “magic” involves introspection and a feature known as “decorators” (which Lichen doesn’t support) to let us use something like this:
class Point:
@initialising("x", "y")
def __init__(self, x, y):
pass
Here, I am taking inspiration from a collection of actual suggestions and solutions, but none of them look like the above. Indeed, many of them take the approach of initialising attributes using every parameter in the method signature which isn’t always what you want, although it does seem to be requested every now and again.
Although the above example looks quite nice, the mechanism responsible for performing the attribute assignments will not look as nice, and so I won’t show it here. And unless a mode is supported where the names can be omitted, thus initialising attributes using all parameters (except self) when you do want to, it is perhaps tiresome to have to write the names out again somewhere else, even more so as strings.
You will also find people advocating more transparent use of the ** catch-all parameter (also not supported by Lichen), sometimes in response to people worried that writing out lots of assignments is a sign of bad code. This yields solutions like this one:
class Point:
def __init__(self, **kw):
for name in ("x", "y"):
setattr(self, name, kw.get(name))
But keeping named parameters in the signature helps to prevent certain kinds of errors, which is one reason why I don’t intend to support catch-all parameters in Lichen.
But what I wondered is why Python never supported something closer to C++’s initialisation lists. In C++, we might write the code somewhat as follows:
class Point
{
Number x, y;
public:
Point(Number x, Number y) : x(x), y(y) {};
}
Here, it is evident that repetition occurs just as in the “magic” Python example, which is something I might want to eliminate. Maybe we would want to have a shorthand for attribute initialisation within the parameter list itself. And then I thought of a possible syntax:
class Point:
def __init__(self, .x, .y):
pass
So, any parameter employing a dot before its name would result in the assignment of its value to the instance attribute having the same name. Of course, this wouldn’t support a parameter with one name having its value assigned to an attribute with another name, but I thought it best to stick to the simple cases. “Why not add this to Lichen?” I thought.
And in line with not getting too immersed in the toolchain straight away after such a long break, I decided on some rather simple semantics for this feature: dot-prefixed names would still exist as local names; dot-prefixing would just be a form of shorthand meaning that an assignment would be generated at the very start of the function body. So, the above would really translate to the very first example given at the start of this article or, indeed, the second one which is equivalent and is reproduced below:
# Lichen-only... # Python and Lichen...
class Point: class Point:
def __init__(self, .x, .y): def __init__(self, x, y):
pass self.x = x; self.y = y
Keeping the sophistication of the feature at an unambitious level, besides letting me slowly familiarise myself again with the code, also helps to deal with potential conflicts with other mechanisms. For example, what if someone wanted to employ a name twice – once dot-prefixed, once unprefixed – like this…?
class Point:
def __init__(self, .x, .y, x):
self.intensity = x ** 2
By asserting that the dot-prefixed x is really just x that also initialises the attribute of the same name, we can fall back on the normal rules around parameters and forbid such duplicate names without having to think very hard about temporary names or more exotic mechanisms that might be used to initialise attributes directly. One other thing worth mentioning is that I don’t reserve the use of such parameters for the exclusive use of initialiser methods, so other applications are possible. For example:
class Point:
def __init__(.x, .y): pass
def update(.x, .y): pass
Here, I also omit self because Lichen defines it as always being present in methods, anyway. And we could actually make the update method an alias of the initialiser method, too, but let us not get too carried away!
Fortunately, I adopted a parser framework in Lichen that was originally written for PyPy that allows relatively straightforward modification of the language grammar. Conveniently, the grammar changes required for this feature are minimal and I don’t even have to add any extra tokens. That made me wonder whether such a syntax had been suggested for Python at some point or other. Some quick searches haven’t yielded any results, and I can’t be bothered to trawl the different mailing list archives to find mentions of such features. I can easily imagine that such a feature might have been discussed rather early in Python’s lifetime, possibly in the mid-1990s.
Arguments for new syntax in Python are often met with arguments against “syntactic sugar”, with such “sugar” introducing more convenient notation or a form of shorthand for particular operations. Over the years, people have argued for more concise ways of referencing instance attributes and class attributes instead of using the almost-special self name (that is rather more special in Lichen). Compound assignments to instance attributes have probably been discussed, too, maybe proposing things like this:
# Compound assignment idea... # Equivalent assignment... self.(x, y) = x, y self.x, self.y = x, y
In response to such suggestions, people seem to be asked how often they need to write such things, whether it is really such a burden to do so, and whether their programming tools cannot help them write out the conventional assignments semi-automatically instead. Proposed general language constructs may well risk introducing conflicts with other language features in unanticipated ways, and if such constructs only ever get used in certain, rather limited, circumstances then one can justifiably ask whether it is really worth the effort to support them. They will, after all, need people to implement them, test them, maintain them, and keep fixing them long into the future.
As is evident from the discussion of the problem of concise initialisation, Python’s community has grown accustomed to solving simple problems in fairly complicated ways using general mechanisms introduced to support broad classes of functionality. Decorators were introduced into Python as a way of inserting extra code around methods and functions to modify or extend their behaviour, allowing people to tackle such problems by getting that extra code to initialise attributes or to do many other weird, wild and wonderful things. Providing such mechanisms lets the language designers send people elsewhere when those people descend on the designers demanding a quick syntactic fix for a specific problem they might be having.
But it really does surprise me that something as simple as dot-prefixing parameter names never managed to get suggested and quickly introduced into an early version of Python. I did wonder whether other Python-inspired languages might have subconsciously inspired me, but a brief perusal of the Boo, Cobra, Delight and Genie documentation turned up nothing. And so, without any more insight into my inspiration, that is the tale of my first experiment in extending Lichen’s syntax beyond that of Python.
Update
I finally remembered where I had seen the dot-prefixed name notation before. When initialising structures in C, you can explicitly indicate a structure member when specifying a value, and I do this all the time in the code generated for Lichen programs. I even define macros that use this feature. For example:
#define __INTVALUE(VALUE) ((__attr) {.intvalue=((VALUE) << 1) | 1})
So I suppose it shows how long it has been since I had to look at that part of the toolchain! Of course, this is directly initialising a structure member by indicating a value, whereas the Lichen syntax enhancement associates an attribute, which is similar to a member, with a parameter received in a method call. But there are some similarities in purpose, nevertheless.
The End of Gratipay
December 20th, 2017
Having discussed issues of Free Software funding before, it would seem inappropriate to let the closing down of Gratipay pass unmentioned. Gratipay is a service where people can commit to giving a sum of money at regular intervals for donation to one or more recipients, offering what the service itself calls a “voluntary subscription revenue model” that is perhaps more familiar to those who have used other, similar funding platforms such as Patreon. In effect, creators sign up to receive payments, donors sign up to support the creators, and then the money flows from the latter group to the former, facilitated by the service.
A Quick Primer
The fundamental model of Gratipay is that “contributors” (donors, “patrons”) support “projects” (recipients, creators) on a weekly basis. Unlike Patreon, where creators are likely to be producing “creations” in a way that best matches artistic and creative pursuits, with the delivery of content to be consumed in discrete parcels, there are no “per-creation” options in Gratipay. Instead, the aim is to provide a reliable source of funding for ongoing work that cannot be so easily split up into chunks and delivered to paying customers one piece at a time.
Another thing that makes Gratipay different to Patreon is the way fees are handled. Patreon charges obligatory fees for handling donations in addition to the other service fees incurred when money is transferred between the different parties. Meanwhile, Gratipay donors are instead merely encouraged to send some of their donations to Gratipay as a way of acknowledging the service’s role and to help fund the service. In addition, Gratipay has always aimed to pass on transaction processing fees “at cost”, with a particularly important aspect of the service’s operation being that it aimed to perform such transactions in an efficient way.
So, instead of charging a donor for the separate transfer of each amount written up against that donor’s different recipients, Gratipay would charge that donor only once per week for the combined total of their donations that happened to be active during that week. And instead of sending each separate donation to its recipient in a distinct transaction, Gratipay would aggregate the donations directed towards a recipient from all its donors and then issue a single transaction to transfer the money. This arrangement would become central in the story of Gratipay and may well have to role to play elsewhere, as we shall see.
The Perils of Payments
In light of recent events, it is particularly pertinent to mention Patreon in the context of Gratipay. Recently, Patreon sought to change its fee structure, justifying it as a way of minimising the impact of fees on creators and the uncertainty around how much each of them could expect to receive every month. This has proved to be controversial, with some people now deciding that they have had quite enough of Patreon’s fees, and with Patreon subsequently deciding to abandon the proposed change.
Part of the motivation for Patreon to rock the boat in this way might simply be to improve profitability and discourage usage patterns that impact profitability, as some people have suggested. Others, however, aware of what happened to Gratipay, suggest that the motivation may involve regulatory compliance. Some may claim that this latter motivation has been “debunked”, and it perhaps isn’t appropriate to speculate in any depth, anyway, but the potential application of specific finance industry regulations certainly was enough to interrupt Gratipay’s operations, in what was known as the Gratipocalypse, suspending those operations for sufficiently long and introducing sufficient uncertainty that it most likely put the service on a course towards its now-impending closure.
Now, non-compliance with finance industry regulation is the kind of very serious matter that cannot so easily be waved away with “good enough” workarounds unless one likes explaining them to a judge, which is why Gratipay took legal advice and changed its operating model. Maybe this has nothing to do with Patreon’s recent actions, but it would be rather cruel if Gratipay, having become aware of such pitfalls, did the right thing at considerable cost to the service and its competitiveness while other, similar services carried on doing broadly similar things – oblivious to such problems, perhaps – cultivating businesses that might now demand more scrutiny.
The Gratipay Legacy
Much of the above is something of an aside to what I really wanted to focus on, however. In bringing this topic to the attention of a Free Software audience, I aim to make the point that Gratipay, being a platform developed as Free Software, should be credited for trying out different approaches for funding Free Software and for allowing others to continue where it left off, to take the platform in new directions, even as it must itself close and send its users elsewhere.
Upon experiencing the Gratipocalypse and regulatory difficulties, the platform was forked to establish Liberapay (by various existing Gratipay developers, as I understand it). Liberapay is a service that is regulated in the European Union. Thanks to that decision to make a transparently-developed Free Software service, the platform can be thought to live on in some way. The cultivation of a durable legacy is surely why many people choose to develop Free Software in the first place, and in this regard Gratipay has perhaps achieved one of its objectives regardless of its own fate.
The fundamental question of how people can be sustained in their activities developing Free Software, outside traditional employment paradigms that is, was explored by Gratipay in a few different ways. As Chad Whitacre, Gratipay’s founder, noted in a blog post, there are many projects in the Free Software universe that make the whole thing viable. However, few of them are likely to see any serious financial investment. Of course, some people might suggest that most Free Software projects are not worthy of any significant investment, that “healthy competition” (coupled to the usual dubious misrepresentation of Darwin’s theories) should decide on the rewards and pick a winner.
It may be a coincidence that in attempting to address this “long tail” problem, Gratipay selected npm (the Node.js package manager) as a candidate to trial better integration between the tools people use and Gratipay’s mechanisms for facilitating donations, effectively letting people discover whose works they make use of and providing them with an easier-than-normal way of rewarding those responsible. A year or so earlier, in a demonstration of how a seemingly trivial piece of software can underpin entire development ecosystems, the deletion of one npm package entry (of many entries controlled by a single developer) caused numerous systems and services to fail, with extensive chaos amongst affected developers and service operators being the immediate result.
Although the npm package deletion fiasco has a number of causes that are beyond the scope of this article, and while one may or may not identify the library responsible for the apparently-widespread breakage as being particularly worthy of sustained funding, it reminds us that there are many seemingly-insignificant building blocks supporting the larger, more well-known projects that are potentially already well-funded. It is also worth noting that Gratipay also attempted to provide mechanisms for the fair distribution of contributions across teams as opposed to focusing on individuals. Recognising that success is usually a team effort is also rather important in a world where celebrity is all too frequently cultivated and rewarded at the expense of those who quietly made that success happen.
One might argue that the conditions for “crowdfunding” people to work on software are very rarely likely to be present. Certainly, the odd Internet celebrity can have a million followers on some “social media” platform or other, and when those followers all chip in a few cents every now and again, the celebrity can focus on whatever it is that they do on that platform. But it takes a lot of small contributions to fund something that resembles a salary. And when the follower demographic for software is likely to be narrower than for random entertainment, it would seem to be a futile task to find a desirable number of donors who might appreciate the value they derive from the software in question and collectively contribute enough funding to pay someone such a salary.
On this front, Gratipay appears to have tried another strategy: to identify those parties who do derive significant value from software and who would be willing to contribute more significant sums. It seems rather obvious, but the people who are making the most money from using software and who are spending the most money, some of it on software, potentially little of it on Free Software, are surely the people to encourage when attempting to secure sustainable Free Software funding. However, this may have been one strategic turn too many, perhaps leading the service in a direction that cannot be pursued with the resources it has at its disposal.
Hiding in Plain Sight
One might well ask whether conventional employment, not the “open work” that Gratipay has aimed to support, is really the mundane and obvious-all-along solution to Free Software funding. Surely, if people want to be paid by others to work on things, then they should be prepared to actually work for the people with the money. And it is true that companies and other organisations can act in sustainable ways that seek to strengthen the foundations shared between their operations and those of others.
But one can also respond to this with observations about conflicts of interests, of developers being hired to not continue working on the Free Software projects they had contributed to, of selfishness and doing things for competitive advantage rather than improving the quality of everybody’s offerings. And of the general inefficiency of recruitment processes these days, meaning that capable developers cannot find positions and yet there are companies almost desperate to identify and hire exactly those developers.
So, as Chad points out in his summary of crowdfunding platforms, the “roll your own” model of accepting donations may be a viable way of engaging with companies directly, at least for projects with sufficient reputational stature. However, let us take the example of one such project providing a technology featuring in many Python job advertisements and surely responsible for a fair amount of money changing hands. Through its supporting organisation, it manages to attract enough funding for just one core developer alongside a number of other activities. It can be debated whether this is an inspiring signpost towards better things or a depressing summary of how much investment in infrastructure people feel they can get away with.
Fundamentally, though, there are projects that just won’t be funded until someone declares a crisis. And even then, the nature of the game is that people will do just enough to avert disaster, throw some funds the way of the overworked maintainers caught in the spotlight, and then carry on as if nothing was really wrong in the first place. Gratipay may not have succeeded in providing a lasting solution to the broader – seemingly less urgent – crisis facing sustainable Free Software development, but we can at least be thankful that a group of dedicated people tried their best to explore some of the options and, through their commitment to Free Software licensing, have allowed others to carry on the work they started.
2017 in Review
December 7th, 2017
On Planet Debian there seems to be quite a few regularly-posted articles summarising the work done by various people in Free Software over the month that has most recently passed. I thought it might be useful, personally at least, to review the different things I have been doing over the past year. The difference between this article and many of those others is that the work I describe is not commissioned or generally requested by others, instead relying mainly on my own motivation for it to happen. The rate of progress can vary somewhat as a result.
Learning KiCad
Over the years, I have been playing around with Arduino boards, sensors, displays and things of a similar nature. Although I try to avoid buying more things to play with, sometimes I manage to acquire interesting items regardless, and these aren’t always ready to use with the hardware I have. Last December, I decided to buy a selection of electronics-related items for interfacing and experimentation. Some of these items have yet to be deployed, but others were bought with the firm intention of putting different “spare” pieces of hardware to use, or at least to make them usable in future.
One thing that sits in this category of spare, potentially-usable hardware is a display circuit board that was once part of a desk telephone, featuring a two-line, bitmapped character display, driven by the Hitachi HD44780 LCD controller. It turns out that this hardware is so common and mundane that the Arduino libraries already support it, but the problem for me was being able to interface it to the Arduino. The display board uses a cable with a connector that needs a special kind of socket, and so some research is needed to discover the kind of socket needed and how this might be mounted on something else to break the connections out for use with the Arduino.
Fortunately, someone else had done all this research quite some time ago. They had even designed a breakout board to hold such a socket, making it available via the OSH Park board fabricating service. So, to make good on my plan, I ordered the mandatory minimum of three boards, also ordering some connectors from Mouser. When all of these different things arrived, I soldered the socket to the board along with some headers, wired up a circuit, wrote a program to use the LiquidCrystal Arduino library, and to my surprise it more or less worked straight away.

Breakout board for the Molex 52030 connector

Hitachi HD44780 LCD display boards driven by an Arduino
This satisfying experience led me to consider other boards that I might design and get made. Previously, I had only made a board for the Arduino using Fritzing and the Fritzing Fab service, and I had held off looking at other board design solutions, but this experience now encouraged me to look again. After some evaluation of the gEDA tools, I decided that I might as well give KiCad a try, given that it seems to be popular in certain “open source hardware” circles. And after a fair amount of effort familiarising myself with it, with a degree of frustration finding out how to do certain things (and also finding up-to-date documentation), I managed to design my own rather simple board: a breakout board for the Acorn Electron cartridge connector.

Acorn Electron cartridge breakout board (in 3D-printed case section)
In the back of my mind, I have vague plans to do other boards in future, but doing this kind of work can soak up a lot of time and be rather frustrating: you almost have to get into some modified mental state to work efficiently in KiCad. And it isn’t as if I don’t have other things to do. But at least I now know something about what this kind of work involves.
Retro and Embedded Hardware
With the above breakout board in hand, a series of experiments were conducted to see if I could interface various circuits to the Acorn Electron microcomputer. These mostly involved 7400-series logic chips (ICs, integrated circuits) and featured various logic gates and counters. Previously, I had re-purposed an existing ROM cartridge design to break out signals from the computer and make it access a single flash memory chip instead of two ROM chips.
With a dedicated prototyping solution, I was able to explore the implementation of that existing board, determine various aspects of the signal timings that remained rather unclear (despite being successfully handled by the existing board’s logic), and make it possible to consider a dedicated board for a flash memory cartridge. In fact, my brother, David, also wanting to get into board design, later adapted the prototyping cartridge to make such a board.
But this experimentation also encouraged me to tackle some other items in the electronics shipment: the PIC32 microcontrollers that I had acquired because they were MIPS-based chips, with somewhat more built-in RAM than the Atmel AVR-based chips used by the average Arduino, that could also be used on a breadboard. I hoped that my familiarity with the SoC (system-on-a-chip) in the Ben NanoNote – the Ingenic JZ4720 – might confer some benefits when writing low-level code for the PIC32.

PIC32 on breadboard with Arduino programming circuit (and some LEDs for diagnostic purposes)
I do not need to reproduce an account of my activities here, given that I wrote about the effort involved in getting started with the PIC32 earlier in the year, and subsequently described an unusual application of such a microcontroller that seemed to complement my retrocomputing interests. I have since tried to make that particular piece of work more robust, but deducing the actual behaviour of the hardware has been frustrating, the documentation can be vague when it needs to be accurate, and much of the community discussion is focused on proprietary products and specific software tools rather than techniques. Maybe this will finally push me towards investigating programmable logic solutions in the future.
Compiling a Python-like Language
As things actually happened, the above hardware activities were actually distractions from something I have been working on for a long time. But at this point in the article, this can be a diversion from all the things that seem to involve hardware or low-level software development. Many years ago, I started writing software in Python. Over the years since, alternative implementations of the Python language (the main implementation being CPython) have emerged and seen some use, some continuing to be developed to this day. But around fifteen years ago, it became a bit more common for people to consider whether Python could be compiled to something that runs more efficiently (and more quickly).
I followed some of these projects enthusiastically for a while. Starkiller promised compilation to C++ but never delivered any code for public consumption, although the associated academic thesis might have prompted the development of Shed Skin which does compile a particular style of Python program to C++ and is available as Free Software. Meanwhile, PyPy elevated to prominence the notion of writing a language and runtime library implementation in the language itself, previously seen with language technologies like Slang, used to implement Squeak/Smalltalk.
Although other projects have also emerged and evolved to attempt the compilation of Python to lower-level languages (Pyrex, Cython, Nuitka, and so on), my interests have largely focused on the analysis of programs so that we may learn about their structure and behaviour before we attempt to run them, this alongside any benefits that might be had in compiling them to something potentially faster to execute. But my interests have also broadened to consider the evolution of the Python language since the point fifteen years ago when I first started to think about the analysis and compilation of Python. The near-mythical Python 3000 became a real thing in the form of the Python 3 development branch, introducing incompatibilities with Python 2 and fragmenting the community writing software in Python.
With the risk of perfectly usable software becoming neglected, its use actively (and destructively) discouraged, it becomes relevant to consider how one might take control of one’s software tools for long-term stability, where tools might be good for decades of use instead of constantly changing their behaviour and obliging their users to constantly change their software. I expressed some of my thoughts about this earlier in the year having finally reached a point where I might be able to reflect on the matter.
So, the result of a great deal of work, informed by experiences and conversations over the years related to previous projects of my own and those of others, is a language and toolchain called Lichen. This language resembles Python in many ways but does not try to be a Python implementation. The toolchain compiles programs to C which can then be compiled and executed like “normal” binaries. Programs can be trivially cross-compiled by any available C cross-compilers, too, which is something that always seems to be a struggle elsewhere in the software world. Unlike other Python compilers or implementations, it does not use CPython’s libraries, nor does it generate in “longhand” the work done by the CPython virtual machine.
One might wonder why anyone should bother developing such a toolchain given its incompatibility with Python and a potential lack of any other compelling reason for people to switch. Given that I had to accept some necessary reductions in the original scope of the project and to limit my level of ambition just to feel remotely capable of making something work, one does need to ask whether the result is too compromised to be attractive to others. At one point, programs manipulating integers were slower when compiled than when they were run by CPython, and this was incredibly disheartening to see, but upon further investigation I noticed that CPython effectively special-cases integer operations. The design of my implementation permitted me to represent integers as tagged references – a classic trick of various language implementations – and this overturned the disadvantage.
For me, just having the possibility of exploring alternative design decisions is interesting. Python’s design is largely done by consensus, with pronouncements made to settle disagreements and to move the process forward. Although this may have served the language well, depending on one’s perspective, it has also meant that certain paths of exploration have not been followed. Certain things have been improved gradually but not radically due to backwards compatibility considerations, this despite the break in compatibility between the Python 2 and 3 branches where an opportunity was undoubtedly lost to do greater things. Lichen is an attempt to explore those other paths without having to constantly justify it to a group of people who may regard such exploration as hostile to their own interests.
Lichen is not really complete: it needs floating point number and other useful types; its library is minimal; it could be made more robust; it could be made more powerful. But I find myself surprised that it works at all. Maybe I should have more confidence in myself, especially given all the preparation I did in trying to understand the good and bad aspects of my previous efforts before getting started on this one.
Developing for MIPS-based Platforms
A couple of years ago I found myself wondering if I couldn’t write some low-level software for the Ben NanoNote. One source of inspiration for doing this was “The CI20 bare-metal project“: a series of blog articles discussing the challenges of booting the MIPS Creator CI20 single-board computer. The Ben and the CI20 use CPUs (or SoCs) from the same family: the Ingenic JZ4720 and JZ4780 respectively.
For the Ben, I looked at the different boot payloads, principally those written to support booting from a USB host, but also the version of U-Boot deployed on the Ben. I combined elements of these things with the framebuffer driver code from the Linux kernel supporting the Ben, and to my surprise I was able to get the device to boot up and show a pattern on the screen. Progress has not always been steady, though.
For a while, I struggled to make the CPU leave its initial exception state without hanging, and with the screen as my only debugging tool, it was hard to see what might have been going wrong. Some careful study of the code revealed the problem: the code I was using to write to the framebuffer was using the wrong address region, meaning that as soon as an attempt was made to update the contents of the screen, the CPU would detect a bad memory access and an exception would occur. Such exceptions will not be delivered in the initial exception state, but with that state cleared, the CPU will happily trigger a new exception when the program accesses memory it shouldn’t be touching.
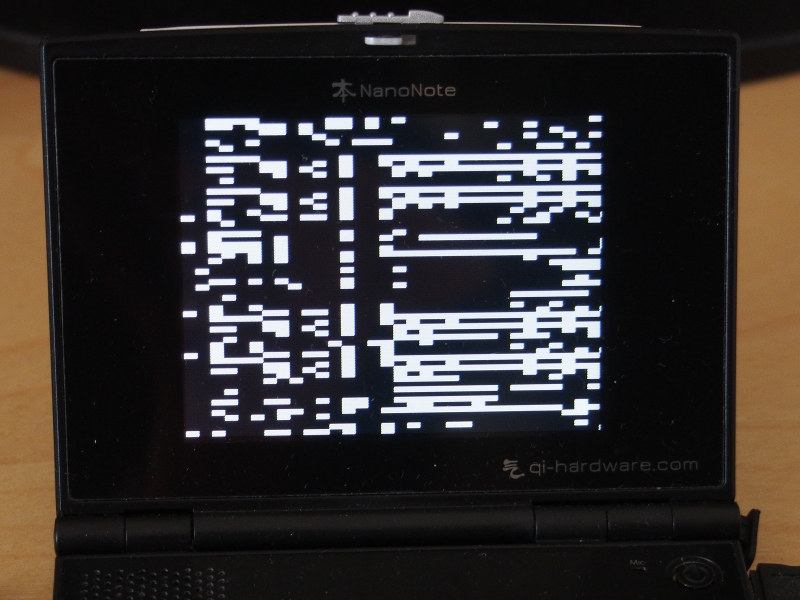
Debugging low-level code on the Ben NanoNote (the hard way)
I have since plodded along introducing user mode functionality, some page table initialisation, trying to read keypresses, eventually succeeding after retracing my steps and discovering my errors along the way. Maybe this will become a genuinely useful piece of software one day.
But one useful purpose this exercise has served is that of familiarising myself with the way these SoCs are organised, the facilities they provide, how these may be accessed, and so on. My brother has the Letux 400 notebook containing yet another SoC in the same family, the JZ4730, which seems to be almost entirely undocumented. This notebook has proven useful under certain circumstances. For instance, it has been used as a kind of appliance for document scanning, driving a multifunction scanner/printer over USB using the enduring SANE project’s software.
However, the Letux 400 is already an old machine, with products based on this hardware platform being almost ten years old, and when originally shipped it used a 2.4 series Linux kernel instead of a more recent 2.6 series kernel. Like many products whose software is shipped as “finished”, this makes the adoption of newer software very difficult, especially if the kernel code is not “upstreamed” or incorporated into the official Linux releases.
As software distributions such as Debian evolve, they depend on newer kernel features, but if a device is stuck on an older kernel (because the special functionality that makes it work on that device is specific to that kernel) then the device, unable to run the newer kernels, gradually becomes unable to run newer versions of the distribution as well. Thus, Debian Etch was the newest distribution version that would work on the 2.4 kernel used by the Letux 400 as shipped.
Fortunately, work had been done to make a 2.6 series kernel work on the Letux 400, and this made Debian Lenny functional. But time passes and even this is now considered ancient. Although David was running some software successfully, there was other software that really needed a newer distribution to be able to run, and this meant considering what it might take to support Debian Squeeze on the hardware. So he set to work adding patches to the 2.6.24 kernel to try and take it within the realm of Squeeze support, making it beyond the bare minimum of 2.6.29 and into the “release candidate” territory of 2.6.30. And this was indeed enough to run Squeeze on the notebook, at least supporting the devices needed to make the exercise worthwhile.
Now, at a much earlier stage in my own experiments with the Ben NanoNote, I had tried without success to reproduce my results on the Letux 400. And I had also made a rather tentative effort at modifying Ben NanoNote kernel drivers to potentially work with the Letux 400 from some 3.x kernel version. David’s success in updating the kernel version led me to look again at the tasks of familiarising myself with kernel drivers, machine details and of supporting the Letux 400 in even newer kernels.
The outcome of this is uncertain at present. Most of the work on updating the drivers and board support has been done, but actual testing of my work still needs to be done, something that I cannot really do myself. That might seem strange: why start something I cannot finish by myself? But how I got started in this effort is also rather related to the topic of the next section.
The MIPS Creator CI20 and L4/Fiasco.OC
Low-level programming on the Ben NanoNote is frustrating unless you modify the device and solder the UART connections to the exposed pads in the battery compartment, thereby enabling a serial connection and allowing debugging information to be sent to a remote display for perusal. My soldering skills are not that great, and I don’t want to damage my device. So debugging was a frustrating exercise. Since I felt that I needed a bit more experience with the MIPS architecture and the Ingenic SoCs, it occurred to me that getting a CI20 might be the way to go.
I am not really a supporter of Imagination Technologies, producer of the CI20, due to the company’s rather hostile attitude towards Free Software around their PowerVR technologies, meaning that of the different graphics acceleration chipsets, PowerVR has been increasingly isolated as a technology that is consistently unsupportable by Free Software drivers. However, the CI20 is well-documented and has been properly supported with Free Software, apart from the PowerVR parts of the hardware, of course. Ingenic were seemingly persuaded to make the programming manual for the JZ4780 used by the CI20 publicly available, unlike the manuals for other SoCs in that family. And the PowerVR hardware is not actually needed to be able to use the CI20.

The MIPS Creator CI20 single-board computer
I had hoped that the EOMA68 campaign would have offered a JZ4775 computer card, and that the campaign might have delivered such a card by now, but with both of these things not having happened I took the plunge and bought a CI20. There were a few other reasons for doing so: I wanted to see how a single-board computer with a decent amount of RAM (1GB) might perform as a working desktop machine; having another computer to offload certain development and testing tasks, rather than run virtual machines, would be useful; I also wanted to experiment with and even attempt to port other operating systems, loosening my dependence on the Linux monoculture.
One of these other operating systems involves two components: the Fiasco.OC microkernel and the L4 Runtime Environment (L4Re). Over the years, microkernels in the L4 family have seen widespread use, and at one point people considered porting GNU Hurd to one of the L4 family microkernels from the Mach microkernel it then used (and still uses). It seems to me like something worth looking at more closely, and fortunately it also seemed that this software combination had been ported to the CI20. However, it turned out that my expectations of building an image, testing the result, and then moving on to developing interesting software were a little premature.
The first real problem was that GCC produced position-independent code that was not called correctly. This meant that upon trying to get the addresses of functions, the program would end up loading garbage addresses and trying to call any code that might be there at those addresses. So some fixes were required. Then, it appeared that the JZ4780 doesn’t support a particular MIPS instruction, meaning that the CPU would encounter this instruction and cause an exception. So, with some guidance, I wrote a handler to decode the instruction and generate the rather trivial result that the instruction should produce. There were also some more generic problems with the microkernel code that had previously been patched but which had not appeared in the upstream repository. But in the end, I got the “hello” program to run.
With a working foundation I tried to explore the hardware just as I had done with the Ben NanoNote, attempting to understand things like the clock and power management hardware, general purpose input/output (GPIO) peripherals, and also the Inter-Integrated Circuit (I2C) peripherals. Some assistance was available in the form of Linux kernel driver code, although the style of code can vary significantly, and it also takes time to “decode” various mechanisms in the Linux code and to unpick the useful bits related to the hardware. I had hoped to get further, but in trying to use the I2C peripherals to talk to my monitor using the DDC protocol, I found that the data being returned was not entirely reliable. This was arguably a distraction from the more interesting task of enabling the display, given that I know what resolutions my monitor supports.
However, all this hardware-related research and detective work at least gave me an insight into mechanisms – software and hardware – that would inform the effort to “decode” the vendor-written code for the Letux 400, making certain things seem a lot more familiar and increasing my confidence that I might be understanding the things I was seeing. For example, the JZ4720 in the Ben NanoNote arranges its hardware registers for GPIO configuration and access in a particular way, but the code written by the vendor for the JZ4730 in the Letux 400 accesses GPIO registers in a different way.
Initially, I might have thought that I was missing some important detail: are the two products really so different, and if not, then why is the code so different? But then, looking at the JZ4780, I encountered another scheme for GPIO register organisation that is different again, but which does have similarities to the JZ4730. With the JZ4780 being publicly documented, the code for the Letux 400 no longer seemed quite so bizarre or unfathomable. With more experience, it is possible to have a little more confidence in one’s understanding of the mechanisms at work.
I would like to spend a bit more time looking at microkernels and alternatives to Linux. While many people presumably think that Linux is running on everything and has “won”, it is increasingly likely that the Linux one sees on devices does not completely control the hardware and is, in fact, virtualised or confined by software systems like L4/Fiasco.OC. I also have reservations about the way Linux is developed and how well it is able to handle the demands of its proliferation onto every kind of device, many of them hooked up to the Internet and being left to fend for themselves.
Developing imip-agent
Alongside Lichen, a project that has been under development for the last couple of years has been imip-agent, allowing calendar-based scheduling activities to be integrated with mail transport agents. I haven’t been able to spend quite as much time on imip-agent this year as I might have liked, although I will also admit that I haven’t always been motivated to spend much time on it, either. Still, there have been brief periods of activity tidying up, fixing, or improving the code. And some interest in packaging the software led me to reconsider some of the techniques used to deploy the software, in particular the way scheduling extensions are discovered, and the way the system configuration is processed (since Debian does not want “executable scripts” in places like /etc, even if those scripts just contain some simple configuration setting definitions).
It is perhaps fairly typical that a project that tries to assess the feasibility of a concept accumulates the necessary functionality in order to demonstrate that it could do a particular task. After such an initial demonstration, the effort of making the code easier to work with, more reliable, more extensible, must occur if further progress is to be made. One intervention that kept imip-agent viable as a project was the introduction of a test suite to ensure that the basic functionality did indeed work. There were other architectural details that I felt needed remedying or improving for the code to remain manageable.
Recently, I have been refining the parts of the code that support editing of calendar objects and the exchange of updates caused by changes to calendar events. Such work is intended to make the Web client easier to understand and to expose such functionality to proper testing. One side-effect of this may be the introduction of a text-based client for people using e-mail programs like Mutt, as well as a potentially usable library for other mail clients. Such tidying up and fixing does not show off fancy new features or argue the case for developing such software in the first place, but I suppose it makes me feel better about the software I have written.
Whither Moin?
There are probably plenty of other little projects of my own that I have started or at least contemplated this year. And there are also projects that are not mine but which I use and which have had contributions from me over the years. One of these is the MoinMoin wiki software that powers a number of Free Software and other Web sites where collaborative editing is made available to the communities involved. I use MoinMoin – or Moin for short – to publish content on the Web myself, and I have encouraged others to use it in the past. However, it worries me now that the level of maintenance it is receiving has fallen to a level where updates for faults in the software are not likely to be forthcoming and where it is no longer clear where such updates should be coming from.
Earlier in the year, having previously read queries about the static export output from Moin, which can be rather basic and not necessarily resemble the appearance of the wiki such output has come from, I spent some time considering my own use of Moin for documentation publishing. For some of my projects, I don’t take advantage of the “through the Web” editing of the solution when publishing the public documentation. Instead, I use Moin locally, store the pages in a separate repository, and then make page packages that get installed on a public instance of Moin. This means that I do not have to worry about Web-based authentication and can just have a wiki as a read-only resource.
Obviously, the parts of Moin that I really need here are just the things that parse the wiki formatting (which I regard as more usable than other document markup formats in various respects) and that format the content as HTML. If I could format it as static content with some pages, some stylesheets, some images, with some Web server magic to make the URLs look nice, then that would probably be sufficient. For some things like the automatic generation of SVG from Graphviz-format files, I would also need to have the relevant parsers available, too. Having a complete Web framework, which is what Moin really is, is rather unnecessary with these diminished requirements.
But I do use Moin as a full wiki solution as well, and so it made me wonder whether I shouldn’t try and bring it up to date. Of course, there is already the MoinMoin 2.0 effort that was intended to modernise and tidy up the software, but since this effort made a clean break from Moin 1.x, it was never an attractive choice for those people already using Moin in anything more than a basic sense. Since there wasn’t an established API for extensions, it was not readily usable for many existing sites that rely on such extensions. In a way, Moin 2 has suffered from something that Python 3 only avoided by having a lot more people working on it, including people being paid to work on it, together with a policy of openly shaming those people who had made Python 2 viable – by developing software for it – into spending time migrating their code to Python 3.
I don’t have an obvious plan of action here. Moin perhaps illustrates the fundamental problem facing many Free Software projects, this being a theme that I have discussed regularly this year: how they may remain viable by having people able to dedicate their time to writing and maintaining Free Software without this work being squeezed in around the edges of people’s “actual work” and thus burdening them with yet another obligation in their lives, particularly one that is not rewarded by a proper appreciation of the sacrifice being made.
Plenty of individuals and organisations benefit from Moin, but we live in an age of “comparison shopping” where people will gladly drop one thing if someone offers them something newer and shinier. This is, after all, how everyone ends up using “free” services where the actual costs are hidden. To their credit, when Moin needed to improve its password management, the Python Software Foundation stepped up and funded this work rather than dropping Moin, which is what I had expected given certain Python community attitudes. Maybe other, more well-known organisations that use Moin also support its development, but I don’t really see much evidence of it.
Maybe they should consider doing so. The notion that something else will always come along, developed by some enthusiastic developer “scratching their itch”, is misguided and exploitative. And a failure to sustain Free Software development can only undermine Free Software as a resource, as an activity or a cause, and as the basis of many of those organisations’ continued existence. Many of us like developing Free Software, as I hope this article has shown, but motivation alone does not keep that software coming forever.
In Defence of Mail
November 6th, 2017
A recent LWN.net article, “The trouble with text-only email“, gives us an insight through an initially-narrow perspective into a broader problem: how the use of e-mail by organisations and its handling as it traverses the Internet can undermine the viability of the medium. And how organisations supposedly defending the Internet as a platform can easily find themselves abandoning technologies that do not sit well with their “core mission”, not to mention betraying that mission by employing dubious technological workarounds.
To summarise, the Mozilla organisation wants its community to correspond via mailing lists but, being the origin of the mails propagated to list recipients when someone communicates with one of their mailing lists, it finds itself under the threat of being blacklisted as a spammer. This might sound counterintuitive: surely everyone on such lists signed up for mails originating from Mozilla in order to be on the list.
Unfortunately, the elevation of Mozilla to being a potential spammer says more about the stack of workaround upon workaround, second- and third-guessing, and the “secret handshakes” that define the handling of e-mail today than it does about anything else. Not that factions in the Mozilla organisation have necessarily covered themselves in glory in exploring ways of dealing with their current problem.
The Elimination Problem
Let us first identify the immediate problem here. No, it is not spamming as such, but it is the existence of dubious “reputation” services who cause mail to be blocked on opaque and undemocratic grounds. I encountered one of these a few years ago when trying to send a mail to a competition and finding that such a service had decided that my mail hosting provider’s Internet address was somehow “bad”.
What can one do when placed in such a situation? Appealing to the blacklisting service will not do an individual any good. Instead, one has to ask one’s mail provider to try and fix the issue, which in my case they had actually been trying to do for some time. My mail never got through in the end. Who knows how long it took to persuade the blacklisting service to rectify what might have been a mistake?
Yes, we all know that the Internet is awash with spam. And yes, mechanisms need to be in place to deal with it. But such mechanisms need to be transparent and accountable. Without these things, all sorts of bad things can take place: censorship, harassment, and forms of economic crime spring readily to mind. It should be a general rule of thumb in society that when someone exercises power over others, such power must be controlled through transparency (so that it is not arbitrary and so that everyone knows what the rules are) and through accountability (so that decisions can be explained and judged to have been properly taken and acted upon).
We actually need better ways of eliminating spam and other misuse of common communications mechanisms. But for now we should at least insist that whatever flawed mechanisms that exist today uphold the democratic principles described above.
The Marketing Problem
Although Mozilla may have distribution lists for marketing purposes, its problem with mailing lists is something of a different creature. The latter are intended to be collaborative and involve multiple senders of the original messages: a many-to-many communications medium. Meanwhile, the former is all about one-to-many messaging, and in this regard we stumble across the root of the spam problem.
Obviously, compulsive spammers are people who harvest mail addresses from wherever they can be found, trawling public data or buying up lists of addresses sourced during potentially unethical activities. Such spammers create a huge burden on society’s common infrastructure, but they are hardly the only ones cultivating that burden. Reputable businesses, even when following the law communicating with their own customers, often employ what can be regarded as a “clueless” use of mail as a marketing channel without any thought to the consequences.
Businesses might want to remind you of their products and encourage you to receive their mails. The next thing you know, you get messages three times a week telling you about products that are barely of interest to you. This may be a “win” for the marketing department – it is like advertising on television but cheaper because you don’t have to bid against addiction-exploiting money launderers gambling companies, debt sharks consumer credit companies or environment-trashing, cure peddlers nutritional supplement companies for “eyeballs” – but it cheapens and worsens the medium for everybody who uses it for genuine interpersonal communication and not just for viewing advertisements.
People view e-mail and mail software as a lost cause in the face of wave after wave of illegal spam and opportunistic “spammy” marketing. “Why bother with it at all?” they might ask, asserting that it is just a wastebin that one needs to empty once a week as some kind of chore, before returning to one’s favourite “social” tools (also plagued with spam and surveillance, but consistency is not exactly everybody’s strong suit).
The Authenticity Problem
Perhaps to escape problems with the overly-zealous blacklisting services, it is not unusual to get messages ostensibly from a company, being a customer of theirs, but where the message originates from some kind of marketing communications service. The use of such a service may be excusable depending on how much information is shared, what kinds of safeguards are in place, and so on. What is less excusable is the way the communication is performed.
I actually experience this with financial institutions, which should be a significant area of concern both for individuals, the industry and its regulators. First of all, the messages are not encrypted, which is what one might expect given that the sender would need some kind of public key information that I haven’t provided. But provided that the message details are not sensitive (although sometimes they have been, which is another story), we might not set our expectations so high for these communications.
However, of more substantial concern is the way that when receiving such mails, we have no way of verifying that they really originated from the company they claim to have come from. And when the mail inevitably contains links to things, we might be suspicious about where those links, even if they are URLs in plain text messages, might want to lead us.
The recipient is now confronted with a collection of Internet domain names that may or may not correspond to the identities of reputable organisations, some of which they might know as a customer, others they might be aware of, but where the recipient must also exercise the correct judgement about the relationship between the companies they do use and these other organisations with which they have no relationship. Even with a great deal of peripheral knowledge, the recipient needs to exercise caution that they do not go off to random places on the Internet and start filling out their details on the say-so of some message or other.
Indeed, I have a recent example of this. One financial institution I use wants me to take a survey conducted by a company I actually have heard of in that line of business. So far, so plausible. But then, the site being used to solicit responses is one I have no prior knowledge of: it could be a reputable technology business or it could be some kind of “honeypot”; that one of the domains mentioned contains “cloud” also does not instil confidence in the management of the data. To top it all, the mail is not cryptographically signed and so I would have to make a judgement on its authenticity based on some kind of “tea-leaf-reading” activity using the message headers or assume that the institution is likely to want to ask my opinion about something.
The Identity Problem
With the possibly-authentic financial institution survey message situation, we can perhaps put our finger on the malaise in the use of mail by companies wanting our business. I already have a heavily-regulated relationship with the company concerned. They seemingly emphasise issues like security when I present myself to their Web sites. Why can they not at least identify themselves correctly when communicating with me?
Some banks only want electronic communications to take place within their hopefully-secure Web site mechanisms, offering “secure messaging” and similar things. Others also offer such things, either two-way or maybe only customer-to-company messaging, but then spew e-mails at customers anyway, perhaps under the direction of the sales and marketing branches of the organisation.
But if they really must send mails, why can they not leverage their “secure” assets to allow me to obtain identifying information about them, so that their mails can be cryptographically signed and so that I can install a certificate and verify their authenticity? After all, if you cannot trust a bank to do these things, which other common institutions can you trust? Such things have to start somewhere, and what better place to start than in the banking industry? These people are supposed to be good at keeping things under lock and key.
The Responsibility Problem
This actually returns us to the role of Mozilla. Being a major provider of software for accessing the Internet, the organisation maintains a definitive list of trusted parties through whom the identity of Web sites can be guaranteed (to various degrees) when one visits them with a browser. Mozilla’s own sites employ certificates so that people browsing them can have their privacy upheld, so it should hardly be inconceivable for the sources of Mozilla’s mail-based communications to do something similar.
Maybe S/MIME would be the easiest technology to adopt given the similarities between its use of certificates and certificate authorities and the way such things are managed for Web sites. Certainly, there are challenges with message signing and things like mailing lists, this being a recurring project for GNU Mailman if I remember correctly (and was paying enough attention), but nothing solves a longstanding but largely underprioritised problem than a concrete need and the will to get things done. Mozilla has certainly tried to do identity management in the past, recalling initiatives like Mozilla Persona, and the organisation is surely reasonably competent in that domain.
In the referenced article, Mozilla was described as facing an awkward technical problem: their messages were perceived as being delivered indiscriminately to an audience of which large portions may not have been receiving or taking receipt of the messages. This perception of indiscriminate, spam-like activity being some kind of metric employed by blacklisting services. The proposed remedy for potential blacklisting involved the elimination of plain text e-mail from Mozilla’s repertoire and the deployment of HTML-only mail, with the latter employing links to images that would load upon the recipient opening the message. (Never mind that many mail programs prevent this.)
The rationale for this approach was that Mozilla would then know that people were getting the mail and that by pruning away those who didn’t reveal their receipt of the message, the organisation could then be more certain of not sending mail to large numbers of “inactive” recipients, thus placating the blacklisting services. Now, let us consider principle #4 of the Mozilla manifesto:
Individuals’ security and privacy on the Internet are fundamental and must not be treated as optional.
Given such a principle, why then is the focus on tracking users and violating their privacy, not on deploying a proper solution and just sending properly-signed mail? Is it because the mail is supposedly not part of the Web or something?
The Proprietary Service Problem
Mozilla can be regarded as having a Web-first organisational mentality which, given its origins, should not be too surprising. Although the Netscape browser was extended to include mail facilities and thus Navigator became Communicator, and although the original Mozilla browser attempted to preserve a range of capabilities not directly related to hypertext browsing, Firefox became the organisation’s focus and peripheral products such as Thunderbird have long struggled for their place in the organisation’s portfolio.
One might think that the decision-makers at Mozilla believe that mundane things like mail should be done through a Web site as webmail and that everyone might as well use an established big provider for their webmail needs. After all, the vision of the Web as a platform in its own right, once formulated as Netscape Constellation in more innocent times, can be used to justify pushing everything onto the Web.
The problem here is that as soon as almost everyone has been herded into proprietary service “holding pens”, expecting a free mail service while having their private communications mined for potential commercial value, things like standards compliance and interoperability suffer. Big webmail providers don’t need to care about small mail providers. Too bad if the big provider blacklists the smaller one: most people won’t even notice, and why don’t the users of the smaller provider “get with it” and use what everybody else is using, anyway?
If everyone ends up almost on the same server or cluster of servers or on one of a handful of such clusters, why should the big providers bother to do anything by the book any more? They can make all sorts of claims about it being more efficient to do things their own way. And then, mail is no longer a decentralised, democratic tool any more: its users end up being trapped in a potentially exploitative environment with their access to communications at risk of being taken away at a moment’s notice, should the provider be persuaded that some kind of wrong has been committed.
The Empowerment Problem
Ideally, everyone would be able to assert their own identity and be able to verify the identity of those with whom they communicate. With this comes the challenge in empowering users to manage their own identities in a way which is resistant to “identity theft”, impersonation, and accidental loss of credentials that could have a severe impact on a person’s interactions with necessary services and thus on their life in general.
Here, we see the failure of banks and other established, trusted organisations to make this happen. One might argue that certain interests, political and commercial, do not want individuals controlling their own identity or their own use of cryptographic technologies. Even when such technologies have been deployed so that people can be regarded as having signed for something, it usually happens via a normal secured Web connection with a button on a Web form, everything happening at arm’s length. Such signatures may not even be any kind of personal signature at all: they may just be some kind of transaction surrounded by assumptions that it really was “that person” because they logged in with their credentials and there are logs to “prove” it.
Leaving the safeguarding of cryptographic information to the average Internet user seems like a scary thing to do. People’s computers are not particularly secure thanks to the general neglect of security by the technology industry, nor are they particularly usable or understandable, especially when things that must be done right – like cryptography – are concerned. It also doesn’t help that when trying to figure out best practices for key management, it almost seems like every expert has their own advice, leaving the impression of a cacophony of voices, even for people with a particular interest in the topic and an above-average comprehension of the issues.
Most individuals in society might well struggle if left to figure out a technical solution all by themselves. But institutions exist that are capable of operating infrastructure with a certain level of robustness and resilience. And those institutions seem quite happy with the credentials I provide to identify myself with them, some of which being provided by bits of hardware they have issued to me.
So, it seems to me that maybe they could lead individuals towards some kind of solution whereupon such institutions could vouch for a person’s digital identity, provide that person with tools (possibly hardware) to manage it, and could help that person restore their identity in cases of loss or theft. This kind of thing is probably happening already, given that smartcard solutions have been around for a while and can be a component in such solutions, but here the difference would be that each of us would want help to manage our own identity, not merely retain and present a bank-issued identity for the benefit of the bank’s own activities.
The Real Problem
The LWN.net article ends with a remark mentioning that “the email system is broken”. Given how much people complain about it, yet the mail still keeps getting through, it appears that the brokenness is not in the system as such but in the way it has been misused and undermined by those with the power to do something about it.
That the metric of being able to get “pull requests through to Linus Torvalds’s Gmail account” is mentioned as some kind of evidence perhaps shows that people’s conceptions of e-mail are themselves broken. One is left with an impression that electronic mail is like various other common resources that are systematically and deliberately neglected by vested interests so that they may eventually fail, leaving those vested interests to blatantly profit from the resulting situation while making remarks about the supposed weaknesses of those things they have wilfully destroyed.
Still, this is a topic that cannot be ignored forever, at least if we are to preserve things like genuinely open and democratic channels of communication whose functioning may depend on decent guarantees of people’s identities. Without a proper identity or trust infrastructure, we risk delegating every aspect of our online lives to unaccountable and potentially hostile entities. If it all ends up with everyone having to do their banking inside their Facebook account, it would be well for the likes of Mozilla to remember that at such a point there is no consolation to be had any more that at least everything is being done in a Web browser.
End of Support for Fairphone 1: Some Unanswered Questions
September 16th, 2017
I previously followed the goings-on at Fairphone a lot more closely than I have done recently, so after having mentioned the obsolescence risks of the first model in an earlier article, it was interesting to discover a Fairphone blog post explaining why the company will no longer support the Fairphone 1. Some of the reasons given are understandable: they went to market with an existing design, focusing instead on minimising the use of conflict minerals; as a result various parts are no longer manufactured or available; the manufacturer they used even stopped producing phones altogether!
A mention of batteries is made in the article, and in community reaction to the announcement, a lot of concern has been expressed about how long the batteries will be good for, whether any kind of replacements might be found, and so on. With today’s bewildering proliferation of batteries of different shapes and sizes, often sealed into devices for guaranteed obsolescence, we are surely storing up a great deal of trouble for the future in this realm. But that is a topic for another time.
In the context of my previous articles about Fairphone, however, what is arguably more interesting is why this recent article fails to properly address the issues of software longevity and support. My first reaction to the Fairphone initiative was caution: it was not at all clear that the company had full control over the software stack, at least within the usual level of expectations. Subsequent information confirmed my suspicions: critical software components were being made available only as proprietary software by MediaTek.
To be fair to Fairphone, the company did acknowledge its shortcomings and promise to do better for Fairphone 2, although I decided to withhold judgement on that particular matter. And for the Fairphone 1, some arrangements were apparently made to secure access to certain software components that had been off-limits. But as I noted in an article on the topic, despite the rather emphatic assurances (“Fairphone has control over the Fairphone 1 source code”), the announcement perhaps raised more questions than it gave answers.
Now, it would seem, we do not get our questions answered as such, but we appear to learn a few things nevertheless. As some people noted in the discussion of the most recent announcement – that of discontinuing support for the device altogether – ceasing the sale of parts and accessories is one thing, but what does that have to do with the software? The only mention of software with any kind of detail in the entire discussion appears to be this:
This is a question of copyright. All the stuff that we would be allowed to publish is pretty boring because it is out there already. The juicy parts are proprietary to Mediatek. There are some Fairphone related changes to open source parts. But they are really really minor…
So what do we learn? That “control over the Fairphone 1 source code” is, in reality, the stuff that is Free Software already, plus various Android customisations done by their software vendor, plus some kind of licence for the real-time operating system deployed on the device. But the MediaTek elephant in the room kept on standing there and everyone agreed not to mention it again.
Naturally, I am far from alone in having noticed the apparent discrepancy between the assurances given and the capabilities Fairphone appeared to have. One can now revisit “the possibility of replacing the Android software by alternative operating systems” mentioned in the earlier, more optimistic announcement and wonder whether this was ever truly realistic, whether it might have ended up being dependent on reverse-engineering efforts or MediaTek suddenly having an episode of uncharacteristic generosity.
I guess that “cooperation from license holders and our own resources” said it all. Although the former thing sounds like the pipedream it always seemed to be, the latter is understandable given the stated need for the company to focus on newer products and keep them funded. We might conclude from this statement that the licensing arrangements for various essential components involved continuing payments that were a burdensome diversion of company resources towards an increasingly unsupportable old product.
If anything this demonstrates why Free Software licensing will always be superior to contractual arrangements around proprietary software that only function as long as everyone feels that the arrangement is lucrative enough. With Free Software, the community could take over the maintenance in as seamless a transition as possible, but in this case they are instead presumably left “high and dry” and in need of a persuasive and perpetually-generous “rich uncle” character to do the necessary deals. It is obvious which one of these options makes more sense. (I have experienced technology communities where people liked to hope for the latter, and it is entertaining only for a short while.)
It is possible that Fairphone 2 provides a platform that is more robust in the face of sourcing and manufacturing challenges, and that there may be a supported software variant that will ultimately be completely Free Software. But with “binary blobs” still apparently required by Fairphone 2, people are right to be concerned that as new products are considered, the company’s next move might not be the necessary step in the right direction that maintains the flexibility that modularity should be bringing whilst remedying the continuing difficulties that the software seems to be causing.
With other parties now making loud noises about phones that run Free Software, promising big things that will eventually need to be delivered to be believed, maybe it would not be out of place to suggest that instead of “big bang” funding campaigns for entirely new one-off products, these initiatives start to work together. Maybe someone could develop a “compute module” for the Fairphone 2 modular architecture, if it lends itself to that. If not, maybe people might consider working towards something that would allow everyone to deliver the things they do best. Otherwise, I fear that we will keep seeing the same mistakes occur over and over again.
Three-and-a-half years’ support is not very encouraging for a phone that should promote sustainability, and the software inputs to this unfortunate situation were clear to me as an outsider over four years ago. That cannot be changed now, and so I just hope Fairphone has learned enough from this and from all the other things that have happened since, so that they may make better decisions in the future and make phones that truly are, as they claim themselves, “built to last”.
Public Money, Public Code, Public Control
September 14th, 2017
An interesting article published by the UK Government Digital Service was referenced in a response to the LWN.net coverage of the recently-launched “Public Money, Public Code” campaign. Arguably, the article focuses a little too much on “in the open” and perhaps not enough on the matter of control. Transparency is a good thing, collaboration is a good thing, no-one can really argue about spending less tax money and getting more out of it, but it is the matter of control that makes this campaign and similar initiatives so important.
In one of the comments on the referenced article you can already see the kind of resistance that this worthy and overdue initiative will meet. There is this idea that the public sector should just buy stuff from companies and not be in the business of writing software. Of course, this denies the reality of delivering solutions where you have to pay attention to customer needs and not just have some package thrown through the doorway of the customer as big bucks are exchanged for the privilege. And where the public sector ends up managing its vendors, you inevitably get an under-resourced customer paying consultants to manage those vendors, maybe even their own consultant colleagues. Guess how that works out!
There is a culture of proprietary software vendors touting their wares or skills to public sector departments, undoubtedly insisting that their products are a result of their own technological excellence and that they are doing their customers a favour by merely doing business with them. But at the same time, those vendors need a steady – perhaps generous – stream of revenue consisting largely of public money. Those vendors do not want their customers to have any real control: they want their customers to be obliged to come back year after year for updates, support, further sales, and so on; they want more revenue opportunities rather than their customers empowering themselves and collaborating with each other. So who really needs whom here?
Some of these vendors undoubtedly think that the public sector is some kind of vehicle to support and fund enterprises. (Small- and medium-sized enterprises are often mentioned, but the big winners are usually the corporate giants.) Some may even think that the public sector is a vehicle for “innovation” where publicly-funded work gets siphoned off for businesses to exploit. Neither of these things cultivate a sustainable public sector, nor do they even create wealth effectively in wider society: they lock organisations into awkward, even perilous technological dependencies, and they undermine competition while inhibiting the spread of high-quality solutions and the effective delivery of services.
Unfortunately, certain flavours of government hate the idea that the state might be in a role of actually doing anything itself, preferring that its role be limited to delegating everything to “the market” where private businesses will magically do everything better and cheaper. In practice, under such conditions, some people may benefit (usually the rich and well-represented) but many others often lose out. And it is not unknown for the taxpayer to have to pick up the bill to fix the resulting mess that gets produced, anyway.
We need sustainable public services and a sustainable software-producing economy. By insisting on Free Software – public code – we can build the foundations of sustainability by promoting interoperability and sharing, maximising the opportunities for those wishing to improve public services by upholding proper competition and establishing fair relationships between customers and vendors. But this also obliges us to be vigilant to ensure that where politicians claim to support this initiative, they do not try and limit its impact by directing money away from software development to the more easily subverted process of procurement, while claiming that procured systems not be subject to the same demands.
Indeed, we should seek to expand our campaigning to cover public procurement in general. When public money is used to deliver any kind of system or service, it should not matter whether the code existed in some form already or not: it should be Free Software. Otherwise, we indulge those who put their own profits before the interests of a well-run public sector and a functioning society.
Stupid Git
August 28th, 2017
This kind of thing has happened to me a lot in recent times…
$ git pull remote: Counting objects: 1367008, done. remote: Compressing objects: 100% (242709/242709), done. remote: Total 1367008 (delta 1118135), reused 1330194 (delta 1113455) Receiving objects: 100% (1367008/1367008), 402.55 MiB | 3.17 MiB/s, done. Resolving deltas: 100% (1118135/1118135), done. fatal: missing blob object '715c19c45d9adbf565c28839d6f9d45cdb627b15' error: git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git did not send all necessary objects
OK, but now what? At least it hasn’t downloaded gigabytes of data and thrown it all away this time. No, just a few hundred megabytes instead.
Looking around on the Internet, I see various guides that are like having your car engine repeatedly stall at traffic lights and being told to crack open the bonnet/hood and start poking at random components, hoping that the thing will jump back to life. After all, isn’t that supposed to be one of the joys of motoring?
Or to translate the usual kind of response about Git when anyone dares to question its usability: “Do you not understand that you are not merely driving a car but are instead interacting with an extensible automotive platform?” And to think that the idea was just to get from A to B conveniently.
I cannot remember a single time when a Mercurial repository failed to update in such a fashion. But I suppose that we will all have to continue to endure the fashionable clamour for projects to move to Git and onto GitHub so that they can become magically popular and suddenly receive a bounty of development attention from the Internet pixies. Because they all love Git, apparently.
One Step Forward, Two Steps Back
August 10th, 2017
I have written about the state of “The Free Software Desktop” before, and how change apparently for change’s sake has made it difficult for those of us with a technology background to provide a stable and reliable computing experience to others who are less technically inclined. It surprises me slightly that I have not written about this topic more often, but the pattern of activity usually goes something like this:
- I am asked to upgrade or troubleshoot a computer running a software distribution I have indicated a willingness to support.
- I investigate confusing behaviour, offer advice on how to perform certain tasks using the available programs, perhaps install or upgrade things.
- I get exasperated by how baroque or unintuitive the experience must be to anyone not “living the dream” of developing software for one of the Free Software desktop environments.
- Despite getting very annoyed by the lack of apparent usability of the software, promising myself that I should at least mention how frustrating and unintuitive it is, I then return home and leave things for a few days.
- I end up calming down sufficiently about the matter to not to be so bothered about saying something about it after all.
But it would appear that this doesn’t really serve my interests that well because the situation apparently gets no better as time progresses. Back at the end of 2013, it took some opining from a community management “expert” to provoke my own commentary. Now, with recent experience of upgrading a system between Kubuntu long-term support releases, I feel I should commit some remarks to writing just to communicate my frustration while the experience is still fresh in my memory.
Back in 2013, when I last wrote something on the topic, I suppose I was having to manage the transition of Kubuntu from KDE 3 to KDE 4 on another person’s computer, perhaps not having to encounter this yet on my own Debian system. This transition required me to confront the arguably dubious user interface design decisions made for KDE 4. I had to deal with things like the way the desktop background no longer behaved as it had done on most systems for many years, requiring things like the “folder view” widget to show desktop icons. Disappointingly, my most recent experience involved revisiting and replaying some of these annoyances.
Actual Users
It is worth stepping back for a moment and considering how people not “living the dream” actually use computers. Although a desktop cluttered with icons might be regarded as the product of an untidy or disorganised user, like the corporate user who doesn’t understand filesystems and folders and who saves everything to the desktop just to get through the working day, the ability to put arbitrary icons on the desktop background serves as a convenient tool to present a range of important tasks and operations to less confident and less technically-focused users.
Let us consider the perspective of such users for a moment. They may not be using the computer to fill their free time, hang out online, or whatever the kids do these days. Instead, they may have a set of specific activities that require the use of the computer: communicate via e-mail, manage their photographs, read and prepare documents, interact with businesses and organisations.
This may seem quaint to members of the “digital native” generation for whom the interaction experience is presumably a blur of cloud service interactions and social media posts. But unlike the “digital natives” who, if you read the inevitably laughable articles about how today’s children are just wizards at technology and that kind of thing, probably just want to show their peers how great they are, there are also people who actually need to get productive work done.
So, might it not be nice to show a few essential programs and actions as desktop icons to direct the average user? I even had this set up having figured out the “folder view” widget which, as if embarrassed at not having shown up for work in the first place, actually shows the contents of the “Desktop” directory when coaxed into appearing. Problem solved? Well, not forever. (Although there is a slim chance that the problem will solve itself in future.)
The Upgrade
So, Kubuntu had been moaning for a while about a new upgrade being available. And being the modern way with KDE and/or Ubuntu, the user is confronted with parade after parade of notifications about all things important, trivial, and everything in between. Admittedly, it was getting to the point where support might be ending for the distribution version concerned, and so the decision was taken to upgrade. In principle this should improve the situation: software should be better supported, more secure, and so on. Sadly, with Ubuntu being a distribution that particularly likes to rearrange the furniture on a continuous basis, it just created more “busy work” for no good reason.
To be fair, the upgrade script did actually succeed. I remember trying something similar in the distant past and it just failing without any obvious remedy. This time, there were some messages nagging about package configuration changes about which I wasn’t likely to have any opinion or useful input. And some lengthy advice about reconfiguring the PostgreSQL server, popping up in some kind of packaging notification, seemed redundant given what the script did to the packages afterwards. I accept that it can be pretty complicated to orchestrate this kind of thing, though.
It was only afterwards that the problems began to surface, beginning with the login manager. Since we are describing an Ubuntu derivative, the default login manager was the Unity-styled one which plays some drum beats when it starts up. But after the upgrade, the login manager was obsessed with connecting to the wireless network and wouldn’t be denied the chance to do so. But it also wouldn’t connect, either, even if given the correct password. So, some work needed to be done to install a different login manager and to remove the now-malfunctioning software.
An Empty Desk
Although changing the login manager also changes the appearance of the software and thus the experience of using it, providing an unnecessary distraction from the normal use of the machine and requiring unnecessary familiarisation with the result of the upgrade, at least it solved a problem of functionality that had “gone rogue”. Meanwhile, the matter of configuring the desktop experience has perhaps not yet been completely and satisfactorily resolved.
When the machine in question was purchased, it was running stock Ubuntu. At some point, perhaps sooner rather than later, the Unity desktop became the favoured environment getting the attention of the Ubuntu developers, and finding that it was rather ill-suited for users familiar with more traditional desktop paradigms, a switch was made to the KDE environment instead. This is where a degree of peace ended up being made with the annoyingly disruptive changes introduced by KDE 4 and its Plasma environment.
One problem that KDE always seems to have had is that of respecting user preferences and customisations across upgrades. On this occasion, with KDE Plasma 5 now being offered, no exception was made: logging in yielded no “folder view” widgets with all those desktop icons; panels were bare; the desktop background was some stock unfathomable geometric form with blurry edges. I seem to remember someone associated with KDE – maybe even the aforementioned “expert” – saying how great it had been to blow away his preferences and experience the awesomeness of the raw experience, or something. Well, it really isn’t so awesome if you are a real user.
As noted above, persuading the “folder view” widgets to return was easy enough once I had managed to open the fancy-but-sluggish widget browser. This gave me a widget showing the old icons that was too small to show them all at once. So, how do you resize it? Since I don’t use such features myself, I had forgotten that it was previously done by pointing at the widget somehow. But because there wasn’t much in the way of interactive help, I had to search the Web for clues.
This yielded the details of how to resize and move a folder view widget. That’s right: why not emulate the impoverished tablet/phone interaction paradigm and introduce a dubious “long click” gesture instead? Clearly because a “mouseover” gesture is non-existent in the tablet/phone universe, it must be abolished elsewhere. What next? Support only one mouse button because that is how the Mac has always done it? And, given that context menus seem to be available on plenty of other things, it is baffling that one isn’t offered here.
Restoring the desktop icons was easy enough, but showing them all was more awkward because the techniques involved are like stepping back to an earlier era where only a single control is available for resizing, where combinations of moves and resizes are required to get the widget in the right place and to be the right size. And then we assume that the icons still do what they had done before which, despite the same programs being available, was not the case: programs didn’t start but also didn’t give any indication why they didn’t start, this being familiar to just about anyone who has used a desktop environment in the last twenty years. Maybe there is a log somewhere with all the errors in it. Who knows? Why is there never any way of troubleshooting this?
One behaviour that I had set up earlier was single-click activation of icons, where programs could be launched with a single click with the mouse. That no longer works, nor is it obvious how to change it. Clearly the usability police have declared the unergonomic double-click action the “winner”. However, some Qt widgets are still happy with single-click navigation. Try explaining such inconsistencies to anyone already having to remember how to distinguish between multiple programs, what each of them does and doesn’t do, and so on.
The Developers Know Best
All of this was frustrating enough, but when trying to find out whether I could launch programs from the desktop or whether such actions had been forbidden by the usability police, I found that when programs were actually launching they took a long time to do so. Firing up a terminal showed the reason for this sluggishness: Tracker and Baloo were wanting to index everything.
Despite having previously switched off KDE’s indexing and searching features and having disabled, maybe even uninstalled, Tracker, the developers and maintainers clearly think that coercion is better than persuasion, that “everyone” wants all their content indexed for “desktop search” or “semantic search” (or whatever they call it now), the modern equivalent of saving everything to the desktop and then rifling through it all afterwards. Since we’re only the stupid users, what would we really have to say about it? So along came Tracker again, primed to waste computing time and storage space, together with another separate solution for doing the same thing, “just in case”, because the different desktop developers cannot work together.
Amongst other frustrations, the process of booting to the login prompt is slower, and so perhaps switching from Upstart to systemd wasn’t such an entirely positive idea after all. Meanwhile, with reduced scrollbar and control affordances, it would seem that the tendency to mimic Microsoft’s usability disasters continues. I also observed spontaneous desktop crashes and consequently turned off all the fancy visual effects in order to diminish the chances of such crashes recurring in future. (Honestly, most people don’t want Project Looking Glass and similar “demoware” guff: they just want to use their computers.)
Of Entitlement and Sustainable Development
Some people might argue that I am just another “entitled” user who has never contributed anything to these projects and is just whining incorrectly about how bad things are. Well, I do not agree. I enthusiastically gave constructive feedback and filed bugs while I still believed that the developers genuinely wanted to know how they might improve the software. (Admittedly, my enthusiasm had largely faded by the time I had to migrate to KDE 4.) I even wrote software using some of the technologies discussed in this article. I always wanted things to be better and stuck with the software concerned.
And even if I had never done such things, I would, along with other users, still have invested a not inconsiderable amount of effort into familiarising people with the software, encouraging others to use it, and trying to establish it as a sustainable option. As opposed to proprietary software that we neither want to use, nor wish to support, nor are necessarily able to support. Being asked to support some Microsoft product is not only ethically dubious but also frustrating when we end up having to guess our way around the typically confusing and poorly-designed interfaces concerned. And we should definitely resent having to do free technical support for a multi-billion-dollar corporation even if it is to help out other people we know.
I rather feel that the “entitlement” argument comes up when both the results of the development process and the way the development is done are scrutinised. There is this continually perpetuated myth that “open source” can only be done by people when those people have “enough time and interest to work on it”, as if there can be no other motivations or models to sustain the work. This cultivates the idea of the “talented artist” developer lifestyle: that the developers do their amazing thing and that its proliferation serves as some form of recognition of its greatness; that, like art, one should take it or leave it, and that the polite response is to applaud it or to remain silent and not betray a supposed ignorance of what has been achieved.
I do think that the production of Free Software is worthy of respect: after all, I am a developer of Free Software myself and know what has to go into making potentially useful systems. But those producing it should understand that people depend on it, too, and that the respect its users have for the software’s development is just as easily lost as it is earned, indeed perhaps more easily lost. Developers have power over their users, and like anyone in any other position of power, we expect them to behave responsibly. They should also recognise that any legitimate authority they have over their users can only exist when they acknowledge the role of those users in legitimising and validating the software.
In a recent argument about the behaviour of systemd, its principal developer apparently noted that as Free Software, it may be forked and developed as anyone might wish. Although true, this neglects the matter of sustainable software development. If I disagree with the behaviour of some software or of the direction of a software project, and if there is no reasonable way to accommodate this disagreement within the framework of the project, then I must maintain my own fork of that software indefinitely if I am to continue using it.
If others cannot be convinced to participate in this fork, and if other software must be changed to work with the forked code, then I must also maintain forks of other software packages. Suddenly, I might be looking at having to maintain an entire parallel software distribution, all because the developers of one piece of software are too precious to accept other perspectives as being valid and are unwilling to work with others in case it “compromises their vision”, or whatever.
Keeping Up on the Treadmill
Most people feel that they have no choice but to accept the upgrade treadmill, the constant churn of functionality, the shiny new stuff that the developers “living the dream” have convinced their employers or their peers is the best and most efficient way forward. It just isn’t a practical way of living for most users to try and deal with the consequences of this in a technical fashion by trying to do all those other people’s jobs again so that they may be done “properly”. So that “most efficient way” ends up incurring inefficiencies and costs amongst everybody else as they struggle to find new ways of doing the things that just worked before.
How frustrating it is that perhaps the only way to cope might be to stop using the software concerned altogether! And how unfortunate it is that for those who do not value Free Software in its own right or who feel that the protections of Free Software are unaffordable luxuries, it probably means that they go and use proprietary software instead and just find a way of rationalising the decision and its inconvenient consequences as part of being a modern consumer engaging in yet another compromised transaction.
So, unhindered by rants like these and by more constructive feedback, the Free Software desktop seems to continue on its way, seemingly taking two steps backward for every one step forward, testing the tolerance even of its most patient users to disruptive change. I dread having to deal with such things again in a few years’ time or even sooner. Maybe CDE will once again seem like an attractive option and bring us full circle for “Unix on the desktop”, saving many people a lot of unnecessary bother. And then the tortoise really will have beaten the hare.
The Mobile Web
July 26th, 2017
I was tempted to reply to a comment on LWN.net’s news article “The end of Flash”, where the following observation was made:
So they create a mobile site with a bit fewer graphics and fewer scripts loading up to try to speed it up.
But I found that I had enough to say that I might as well put it here.
A recent experience I had with one airline’s booking Web site involved an obvious pandering to “mobile” users. But to the designers this seemed to mean oversized widgets on any non-mobile device coupled with a frustratingly sequential mode of interaction, as if Fisher-Price had an enterprise computing division and had been contracted to do the work. A minimal amount of information was displayed at any given time, and even normal widget navigation failed to function correctly. (Maybe this is completely unfair to Fisher-Price as some of their products appear to encourage far more sophisticated interaction.)
And yet, despite all the apparent simplification, the site ran abominably slow. Every – single – keypress – took – ages – to – process. Even in normal text boxes. My desktop machine is ancient and mostly skipped the needless opening and closing animations on widgets because it just isn’t fast enough to notice that it should have been doing them before the time limit for doing them runs out. And despite fewer graphics and scripts, it was still heavy on the CPU.
After fighting my way through the booking process, I was pointed to the completely adequate (and actually steadily improving) conventional site that I’d used before but which was now hidden by the new and shiny default experience. And then I noticed a message about customer feedback and the continued availability of the old site: many of their other customers were presumably so appalled by the new “made for mobile” experience and, with some of them undoubtedly having to use the site for their job, booking travel for their colleagues or customers, they’d let the airline know what they thought. I imagine that some of the conversations were pretty frank.
I suppose that when companies manage to decouple themselves from fads and trends and actually listen to their customers (and not via Twitter), they can be reminded to deliver usable services after all. And I am thankful for the “professional customers” who are presumably all that stand in the way of everyone being obliged to download an “app” to book their flights. Maybe that corporate urge will lead to the next reality check for the airline’s “digital strategists”.
Some Thoughts on Python-Like Languages
June 6th, 2017
A few different things have happened recently that got me thinking about writing something about Python, its future, and Python-like languages. I don’t follow the different Python implementations as closely as I used to, but certain things did catch my attention over the last few months. But let us start with things closer to the present day.
I was neither at the North American PyCon event, nor at the invitation-only Python Language Summit that occurred as part of that gathering, but LWN.net has been reporting the proceedings to its subscribers. One of the presentations of particular interest was covered by LWN.net under the title “Keeping Python competitive”, apparently discussing efforts to “make Python faster”, the challenges faced by different Python implementations, and the limitations imposed by the “canonical” CPython implementation that can frustrate performance improvement efforts.
Here is where this more recent coverage intersects with things I have noticed over the past few months. Every now and again, an attempt is made to speed Python up, sometimes building on the CPython code base and bolting on additional technology to boost performance, sometimes reimplementing the virtual machine whilst introducing similar performance-enhancing technology. When such projects emerge, especially when a large company is behind them in some way, expectations of a much faster Python are considerable.
Thus, when the Pyston reimplementation of Python became more widely known, undertaken by people working at Dropbox (who also happen to employ Python’s creator Guido van Rossum), people were understandably excited. Three years after that initial announcement, however, and those ambitious employees now have to continue that work on their own initiative. One might be reminded of an earlier project, Unladen Swallow, which also sought to perform just-in-time compilation of Python code, undertaken by people working at Google (who also happened to employ Python’s creator Guido van Rossum at the time), which was then abandoned as those people were needed to go and work on other things. Meanwhile, another apparently-broadly-similar project, Pyjion, is being undertaken by people working at Microsoft, albeit as a “side project at work”.
As things stand, perhaps the most dependable alternative implementation of Python, at least if you want one with a just-in-time compiler that is actively developed and supported for “production use”, appears to be PyPy. And this is only because of sustained investment of both time and funding over the past decade and a half into developing the technology and tracking changes in the Python language. Heroically, the developers even try and support both Python 2 and Python 3.
Motivations for Change
Of course, Google, Dropbox and Microsoft presumably have good reasons to try and get their Python code running faster and more efficiently. Certainly, the first two companies will be running plenty of Python to support their services; reducing the hardware demands of delivering those services is definitely a motivation for investigating Python implementation improvements. I guess that there’s enough Python being run at Microsoft to make it worth their while, too. But then again, none of these organisations appear to be resourcing these efforts at anything close to what would be marshalled for their actual products, and I imagine that even similar infrastructure projects originating from such companies (things like Go, for example) have had many more people assigned to them on a permanent basis.
And now, noting the existence of projects like Grumpy – a Python to Go translator – one has to wonder whether there isn’t some kind of strategy change afoot: that it now might be considered easier for the likes of Google to migrate gradually to Go and steadily reduce their dependency on Python than it is to remedy identified deficiencies with Python. Of course, the significant problem remains of translating Python code to Go and still have it interface with code written in C against Python’s extension interfaces, maintaining reliability and performance in the result.
Indeed, the matter of Python’s “C API”, used by extensions written in C for Python programs to use, is covered in the LWN.net article. As people have sought to improve the performance of their software, they have been driven to rewrite parts of it in C, interfacing these performance-critical parts with the rest of their programs. Although such optimisation techniques make sense and have been a constant presence in software engineering more generally for many decades, it has almost become the path of least resistance when encountering performance difficulties in Python, even amongst the maintainers of the CPython implementation.
And so, alternative implementations need to either extract C-coded functionality and offer it in another form (maybe even written in Python, can you imagine?!), or they need to have a way of interfacing with it, one that could produce difficulties and impair their own efforts to deliver a robust and better-performing solution. Thus, attempts to mitigate CPython’s shortcomings have actually thwarted the efforts of other implementations to mitigate the shortcomings of Python as a whole.
Is “Python” Worth It?
You may well be wondering, if I didn’t manage to lose you already, whether all of these ambitious and brave efforts are really worth it. Might there be something with Python that just makes it too awkward to target with a revised and supposedly better implementation? Again, the LWN.net article describes sentiments that simpler, Python-like languages might be worth considering, mentioning the Hack language in the context of PHP, although I might also suggest Crystal in the context of Ruby, even though the latter is possibly closer to various functional languages and maybe only bears syntactic similarities to Ruby (although I haven’t actually looked too closely).
One has to be careful with languages that look dynamic but are really rather strict in how types are assigned, propagated and checked. And, should one choose to accept static typing, even with type inference, it could be said that there are plenty of mature languages – OCaml, for instance – that are worth considering instead. As people have experimented with Python-like languages, others have been quick to criticise them for not being “Pythonic”, even if the code one writes is valid Python. But I accept that the challenge for such languages and their implementations is to offer a Python-like experience without frustrating the programmer too much about things which look valid but which are forbidden.
My tuning of a Python program to work with Shedskin needed to be informed about what Shedskin was likely to allow and to reject. As far as I am concerned, as long as this is not too restrictive, and as long as guidance is available, I don’t see a reason why such a Python-like language couldn’t be as valid as “proper” Python. Python itself has changed over the years, and the version I first used probably wouldn’t measure up to what today’s newcomers would accept as Python at all, but I don’t accept that the language I used back in 1995 was not Python: that would somehow be a denial of history and of my own experiences.
Could I actually use something closer to Python 1.4 (or even 1.3) now? Which parts of more recent versions would I miss? And which parts of such ancient Pythons might even be superfluous? In pursuing my interests in source code analysis, I decided to consider such questions in more detail, partly motivated by the need to keep the investigation simple, partly motivated by laziness (that something might be amenable to analysis but more effort than I considered worthwhile), and partly motivated by my own experiences developing Python-based solutions.
A Leaner Python
Usually, after a title like that, one might expect to read about how I made everything in Python statically typed, or that I decided to remove classes and exceptions from the language, or do something else that would seem fairly drastic and change the character of the language. But I rather like the way Python behaves in a fundamental sense, with its classes, inheritance, dynamic typing and indentation-based syntax.
Other languages inspired by Python have had a tendency to diverge noticeably from the general form of Python: Boo, Cobra, Delight, Genie and Nim introduce static typing and (arguably needlessly) change core syntactic constructs; Converge and Mython focus on meta-programming; MyPy is the basis of efforts to add type annotations and “optional static typing” to Python itself. Meanwhile, Serpentine is a project being developed by my brother, David, and is worth looking at if you want to write software for Android, have some familiarity with user interface frameworks like PyQt, and can accept the somewhat moderated type discipline imposed by the Android APIs and the Dalvik runtime environment.
In any case, having already made a few rounds trying to perform analysis on Python source code, I am more interested in keeping the foundations of Python intact and focusing on the less visible characteristics of programs: effectively reading between the lines of the source code by considering how it behaves during execution. Solutions like Shedskin take advantage of restrictions on programs to be able to make deductions about program behaviour. These deductions can be sufficient in helping us understand what a program might actually do when run, as well as helping the compiler make more robust or efficient programs.
And the right kind of restrictions might even help us avoid introducing more disruptive restrictions such as having to annotate all the types in a program in order to tell us similar things (which appears to be one of the main directions of Python in the current era, unfortunately). I would rather lose exotic functionality that I have never really been convinced by, than retain such functionality and then have to tell the compiler about things it would otherwise have a chance of figuring out for itself.
Rocking the Boat
Certainly, being confronted with any list of restrictions, despite the potential benefits, can seem like someone is taking all the toys away. And it can be difficult to deliver the benefits to make up for this loss of functionality, no matter how frivolous some of it is, especially if there are considerable expectations in terms of things like performance. Plenty of people writing alternative Python implementations can attest to that. But there are other reasons to consider a leaner, more minimal, Python-like language and accompanying implementation.
For me, one rather basic reason is merely to inform myself about program analysis, figure out how difficult it is, and hopefully produce a working solution. But beyond that is the need to be able to exercise some level of control over the tools I depend on. Python 2 will in time no longer be maintained by the Python core development community; a degree of agitation has existed for some time to replace it with Python 3 in Free Software operating system distributions. Yet I remain unconvinced about Python 3, particularly as it evolves towards a language that offers “optional” static typing that will inevitably become mandatory (despite assertions that it will always officially be optional) as everyone sprinkles their code with annotations and hopes for the magic fairies and pixies to come along and speed it up, that latter eventuality being somewhat less certain.
There are reasons to consider alternative histories for Python in the form of Python-like languages. People argue about whether Python 3’s Unicode support makes it as suitable for certain kinds of programs as Python 2 has been, with the Mercurial project being notable in its refusal to hurry along behind the Python 3 adoption bandwagon. Indeed, PyPy was devised as a platform for such investigations, being only somewhat impaired in some respects by its rather intensive interpreter generation process (but I imagine there are ways to mitigate this).
Making a language implementation that is adaptable is also important. I like the ability to be able to cross-compile programs, and my own work attempts to make this convenient. Meanwhile, cross-building CPython has been a struggle for many years, and I feel that it says rather a lot about Python core development priorities that even now, with the need to cross-build CPython if it is to be available on mobile platforms like Android, the lack of a coherent cross-building strategy has left those interested in doing this kind of thing maintaining their own extensive patch sets. (Serpentine gets around this problem, as well as the architectural limitations of dropping CPython on an Android-based device and trying to hook it up with the different Android application frameworks, by targeting the Dalvik runtime environment instead.)
No Need for Another Language?
I found it depressingly familiar when David announced his Android work on the Python mobile-sig mailing list and got the following response:
In case you weren't aware, you can just write Android apps and services in Python, using Kivy. No need to invent another language.
Fortunately, various other people were more open-minded about having a new toolchain to target Android. Personally, the kind of “just use …” rhetoric reminds me of the era when everyone writing Web applications in Python were exhorted to “just use Zope“, which was a complicated (but admittedly powerful and interesting) framework whose shortcomings were largely obscured and downplayed until enough people had experienced them and felt that progress had to be made by working around Zope altogether and developing other solutions instead. Such zero-sum games – that there is one favoured approach to be promoted, with all others to be terminated or hidden – perhaps inspired by an overly-parroted “only one way to do it” mantra in the Python scene, have been rather damaging to both the community and to the adoption of Python itself.
Not being Python, not supporting every aspect of Python, has traditionally been seen as a weakness when people have announced their own implementations of Python or of Python-like languages. People steer clear of impressive works like PyPy or Nuitka because they feel that these things might not deliver everything CPython does, exactly like CPython does. Which is pretty terrible if you consider the heroic effort that the developer of Nuitka puts in to make his software work as similarly to CPython as possible, even going as far as to support Python 2 and Python 3, just as the PyPy team do.
Solutions like MicroPython have got away with certain incompatibilities with the justification that the target environment is rather constrained. But I imagine that even that project’s custodians get asked whether it can run Django, or whatever the arbitrarily-set threshold for technological validity might be. Never mind whether you would really want to run Django on a microcontroller or even on a phone. And never mind whether large parts of the mountain of code propping up such supposedly essential solutions could actually do with an audit and, in some cases, benefit from being retired and rewritten.
I am not fond of change for change’s sake, but new opportunities often bring new priorities and challenges with them. What then if Python as people insist on it today, with all the extra features added over the years to satisfy various petitioners and trends, is actually the weakness itself? What if the Python-like languages can adapt to these changes, and by having to confront their incompatibilities with hastily-written code from the 1990s and code employing “because it’s there” programming techniques, they can adapt to the changing environment while delivering much of what people like about Python in the first place? What if Python itself cannot?
“Why don’t you go and use something else if you don’t like what Python is?” some might ask. Certainly, Free Software itself is far more important to me than any adherence to Python. But I can also choose to make that other language something that carries forward the things I like about Python, not something that looks and behaves completely differently. And in doing so, at least I might gain a deeper understanding of what matters to me in Python, even if others refuse the lessons and the opportunities such Python-like languages can provide.