Integrating libext2fs with a Filesystem Framework
Wednesday, February 20th, 2019Given the content covered by my previous articles, there probably doesn’t seem to be too much that needs saying about the topic covered by this article. Previously, I described the work involved in building libext2fs for L4Re and testing the library, and I described a framework for separating filesystem providers from programs that want to use files. But, as always, there are plenty of little details, detours and learning experiences that help to make the tale longer than it otherwise might have been.
Although this file access framework sounds intimidating, it is always worth remembering that the only exotic thing about the software being written is that it needs to request system resources and to communicate with other programs. That can be tricky in itself in many programming environments, and I have certainly spent enough time trying to figure out how to use the types and functions provided by the many L4Re libraries so that these operations may actually work.
But in the end, these are programs that are run just like any other. We aren’t building things into the kernel and having to conform to a particularly restricted environment. And although it can still be tiresome to have to debug things, particularly interprocess communication (IPC) problems, many familiar techniques for debugging and inspecting program behaviour remain available to us.
A Quick Translation
The test program I had written for libext2fs simply opened a file located in the “rom” filesystem, exposed it to libext2fs, and performed operations to extract content. In my framework, I had directed my attention towards opening and reading files, so it made sense to concentrate on providing this functionality in a filesystem server or “provider”.

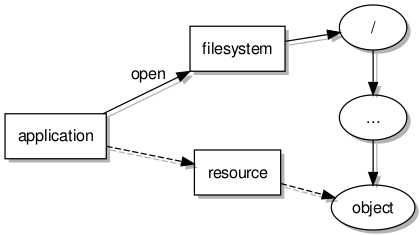
Accessing a filesystem server employing a "rom" file for the data
The user of the framework (shielded from the details by a client library) would request the opening of a file (thus obtaining a file descriptor able to communicate with a dedicated resource object) and then read from the file (causing communication with the resource object and some transfers of data). These operations, previously done in a single program employing libext2fs directly, would now require collaboration by two separate programs.
So, I would need to insert the appropriate code in the right places in my filesystem server and its objects to open a filesystem, search for a file of the given name, and to provide the file data. For the first of these, the test program was doing something like this in the main function:
retval = ext2fs_open(devname, EXT2_FLAG_RW, 0, 0, unix_io_manager, &fs);
In the main function of the filesystem server program, something similar needs to be done. A reference to the filesystem (fs) is then passed to the server object for it to use:
Fs_server server_obj(fs, devname);
When a request is made to open a file, the filesystem server needs to locate the file just as the test program needed to. The code to achieve this is tedious, employing the ext2fs_lookup function and traversing the directory hierarchy. Ultimately, something like this needs to be done to obtain a structure for accessing the file contents:
retval = ext2fs_file_open(_fs, ino_file, ext2flags, &file);
Here, the _fs variable is our reference in the server object to the filesystem structure, the ino_file variable refers to the place in the filesystem where the file is found (the inode), some flags indicate things like whether we are reading and/or writing, and a supplied file variable is set upon the successful opening of the file. In the filesystem server, we want to create a specific object to conduct access to the file:
Fs_object *obj = new Fs_object(file, EXT2_I_SIZE(&inode_file), fsobj, irq);
Here, this resource object is initialised with the file access structure, an indication of the file size, something encapsulating the state of the communication between client and server, and the IRQ object needed for cleaning up (as described in the last article). Meanwhile, in the resource object, the read operation is supported by a pair of libext2fs functions:
ext2fs_file_lseek(_file, _obj.position, EXT2_SEEK_SET, 0); ext2fs_file_read(_file, _obj.buffer, to_transfer, &read);
These don’t appear next to each other in the actual code, but the first call is used to seek to the indicated position in the file, this having been specified by the client. The second call appears in a loop to read into a buffer an indicated amount of data, returning the amount that was actually read.
In summary, the work done by a collection of function calls appearing together in a single function is now spread out over three places in the filesystem server program:
- The initialisation is done in the main function as the server starts up
- The locating and opening of a file in the filesystem is done in the general filesystem server object
- Reading and writing is done in the file-specific resource object
After initialisation, the performance of each part of the work only occurs upon receiving a distinct kind of message from a client program, of which more details are given below.
The Client Library
Although we cannot yet use the familiar C library functions for accessing files (fopen, fread, fwrite, fclose, and so on), we can employ functions that try to be as friendly. Thus, the following form of program may be used:
char buffer[80];
file_descriptor_t *desc = client_open("test.txt", O_RDONLY);
available = client_read(desc, buffer, 80);
if (available)
fwrite((void *) buffer, sizeof(char), available, stdout); /* using existing fwrite function */
client_close(desc);
As noted above, the existing fwrite function in L4Re may be used to write file data out to the console. Ultimately, we would want our modified version of the function to be doing this job.
These client library functions resemble lower-level C library functions such as open, read, write, close, and so on. By targeting this particular level of functionality, it is hoped that much of the logic in functions like fopen can be preserved, this logic having to deal with things like mode strings (“r”, “r+”, “w”, and so on) which have little to do with the actual job of transmitting file content around the system.
In order to do their work, the client library functions need to send and receive IPC messages, or at least need to get other functions to deal with this particular work. My approach has been to write a layer of functions that only deals with messaging and that hides the L4-specific details from the rest of the code.
This lower-level layer of functions allows us to treat interprocess interactions like normal function calls, and in this framework those calls would have the following signatures, with the inputs arriving at the server and the outputs arriving back at the client:
- fs_open: flags, buffer → file size, resource object
- fs_flush: (no parameters) → (no return values)
- fs_read: position → available
- fs_write: position, available → written, file size
The responsibilities of the client library functions can be summarised as follows:
- client_open: allocate memory for the buffer, obtain a server reference (“capability”) from the program’s environment
- client_close: deallocate the allocated resources
- client_flush: invoke fs_flush with any available data, resetting the buffer status
- client_read: provide data to the caller from its buffer, invoking fs_read whenever the buffer is empty
- client_write: commit data from the caller into the buffer, invoking fs_write whenever the buffer is full, also flushing the buffer when appropriate
The lack of a fs_close function might seem surprising, but as described in the previous article, the server process is designed to receive a notification when the client process discards a reference to the resource object dedicated to a particular file. So in client_close, we should be able to merely throw away the things acquired by client_open, and the system together with the server will hopefully handle the consequences.
Switching the Backend
Using a conventional file as the repository for file content is convenient, but since the aim is to replace the existing filesystem mechanisms, it would seem necessary to try and get libext2fs to use other ways of accessing the underlying storage. Previously, my considerations had led me to provide a “block” storage layer underneath the filesystem layer. So it made sense to investigate how libext2fs might communicate with a “block server” or “block device” in order to read and write raw filesystem data.

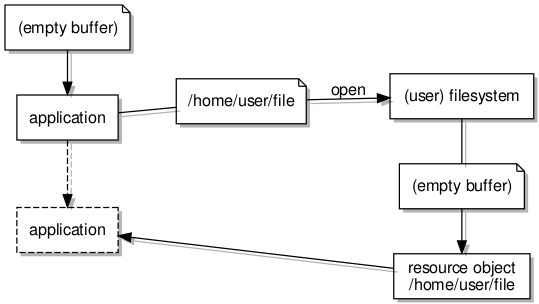
Employing a separate server to provide filesystem data
Changing the way libext2fs accesses its storage sounds like an ominous task, but fortunately some thought has evidently gone into accommodating different storage types and platforms. Indeed, the library code includes support for things like DOS and Windows, with this functionality evidently being used by various applications on those platforms (or, these days, the latter one, at least) to provide some kind of file browser support for ext2-family filesystems.
The kind of component involved in providing this variety of support is known as an “I/O manager”, and the one that we have been using is known as the “Unix” I/O manager, this employing POSIX or standard C library calls to access files and devices. Now, this may have been adequate until now, but with the requirement that we use the replacement IPC mechanisms to access a block server, we need to consider how a different kind of I/O manager might be implemented to use the client library functions instead of the C library functions.
This exercise turned out to be relatively straightforward and perhaps a little less work than envisaged once the requirements of initialising an io_channel object had been understood, this involving the allocation of memory and the population of a structure to indicate things like the block size, error status, and so on. Beyond this, the principal operations needing support are as follows:
- open: initialises the io_channel and calls client_open
- close: calls client_close
- set block size: sets the block size for transfers, something that gets done at various points in the opening of a filesystem
- read block: calls client_seek and client_read to obtain data from the block server
- write block: calls client_seek and client_write to commit data to the block server
It should be noted that the block server largely acts like a single-file filesystem, so the same interface supported by the filesystem server is also supported by the block server. This is how we get away with using the client libraries.
Meanwhile, in the filesystem server code, the only changes required are to declare the new I/O manager, implemented in a separate library package, and to use it instead of the previous one:
retval = ext2fs_open(devname, ext2flags, 0, 0, blockserver_io_manager, &fs);
The Final Trick
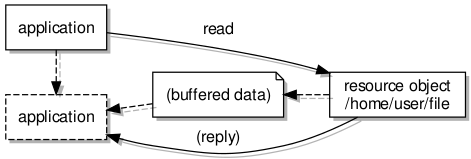
By pushing use of the “rom” filesystem further down in the system, use of the new file access mechanisms can be introduced and tested, with the only “unauthentic” aspect of the arrangement being that a parallel set of file access functions is being used instead of the conventional ones. The only thing left to do would be to change the C library to incorporate the new style of file access, probably by incorporating the client library internally, thus switching the C library away from its previous method of accessing files.
With the conventional file abstractions reimplemented, access to files would go via the virtual filesystem and hopefully end up encountering block devices that are able to serve up the needed data directly. And ultimately, we could end up switching back to using the Unix I/O manager with libext2fs.

Introducing the new IPC mechanisms at the C library level
Changing things so drastically would also force us to think about maintaining access to the “rom” filesystem through the revised architecture, at least at first, because it happens to provide a very convenient way of getting access to data for use as storage. We could try and implement storage hardware support in order to get round this problem, but that probably isn’t convenient – or would be a distraction – when running L4Re on Fiasco.OC-UX as a kind of hosted version of the software.
Indeed, tackling the C library is probably too much of a challenge at this early stage. Fortunately, there are plenty of other issues to be considered first, with the use of non-standard file access functions being only a minor inconvenience in the broader scheme of things. For instance, how are permissions and user identities to be managed? What about concurrent access to the filesystem? And what mechanisms would need to be provided for grafting filesystems onto a larger virtual filesystem hierarchy? I hope to try and discuss some of these things in future articles.