A Long Voyage into Groupware
Wednesday, August 26th, 2015A while ago, I noted that I had moved on from attempting to contribute to Kolab and had started to explore other ways of providing groupware through existing infrastructure options. Once upon a time, I had hoped that I could contribute to Kolab on the basis of things I mostly knew about, whilst being able to rely on the solution itself (and those who made it) to take care of the things I didn’t really know very much about.
But that just didn’t work out: I ultimately had to confront issues of reliably configuring Postfix, Cyrus, 389 Directory Server, and a variety of other things. Of course, I would have preferred it if they had just worked so that I could have got on with doing more interesting things.
Now, I understand that in order to pitch a total solution for someone’s groupware needs, one has to integrate various things, and to simplify that integration and to lower the accompanying support burden, it can help to make various choices on behalf of potential users. After all, if they don’t have a strong opinion about what kind of mail storage solution they should be using, or how their user database should be managed, it can save them from having to think about such things.
One certainly doesn’t want to tell potential users or customers that they first have to go off, read some “how to” documents, get some things working, and then come back and try and figure out how to integrate everything. If they were comfortable with all that, maybe they would have done it all already.
And one can also argue about whether Kolab augments and re-uses or merely replaces existing infrastructure. If the recommendation is that upon adopting Kolab, one replaces an existing Postfix installation with one that Kolab provides in one form or another, then maybe it is possible to re-use the infrastructure that is already there.
It is harder to make that case if one is already using something else like Exim, however, because Kolab doesn’t support Exim. Then, there is the matter of how those components are used in a comprehensive groupware solution. Despite people’s existing experiences with those components, it can quickly become a case of replacing the known with the unknown: configuring them to identify users of the system in a different way, or to store messages in a different fashion, and so on.
Incremental Investments
I don’t have such prior infrastructure investments, of course. And setting up an environment to experiment with such things didn’t involve replacing anything. But it is still worthwhile considering what kind of incremental changes are required to provide groupware capabilities to an existing e-mail infrastructure. After all, many of the concerns involved are orthogonal:
- Where the mail gets stored has little to do with how recipients are identified
- How recipients are identified has little to do with how the mail is sent and received
- How recipients actually view their messages and calendars has little to do with any of the above
Where components must talk to one another, we have the benefit of standards and standardised protocols and interfaces. And we also have a choice amongst these things as well.
So, what if someone has a mail server delivering messages to local users with traditional Unix mailboxes? Does it make sense for them to schedule events and appointments via e-mail? Must they migrate to another mail storage solution? Do they have to start using LDAP to identify each other?
Ideally, such potential users should be able to retain most of their configuration investments, adding the minimum necessary to gain the new functionality, which in this case would merely be the ability to communicate and coordinate event information. Never mind the idea that potential users would be “better off” adopting LDAP to do so, or whichever other peripheral technology seems attractive for some kinds of users, because it is “good practice” or “good experience for the enterprise world” and that they “might as well do it now”.
The difference between an easily-approachable solution and one where people give you a long list of chores to do first (involving things that are supposedly good for you) is more or less equivalent to the difference between you trying out a groupware solution or just not bothering with groupware features at all. So, it really does make sense as someone providing a solution to make things as easy as possible for people to get started, instead of effectively turning them away at the door.
Some Distractions
But first, let us address some of the distractions that usually enter the picture. A while ago, I had the displeasure of being confronted with the notion of “integrated e-mail and calendar” solutions, and it turned out that such terminology is coined as a form of euphemism for adopting proprietary, vendor-controlled products that offer some kind of lifestyle validation for people with relatively limited imagination or experience: another aspirational possession to acquire, and with it the gradual corruption of organisations with products that shun interoperability and ultimately limit flexibility and choice.
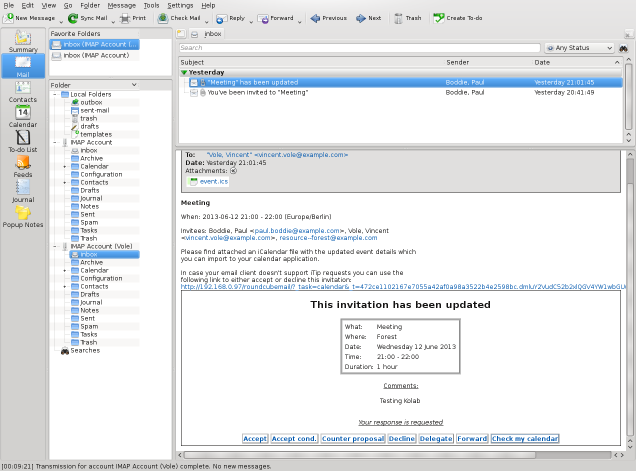
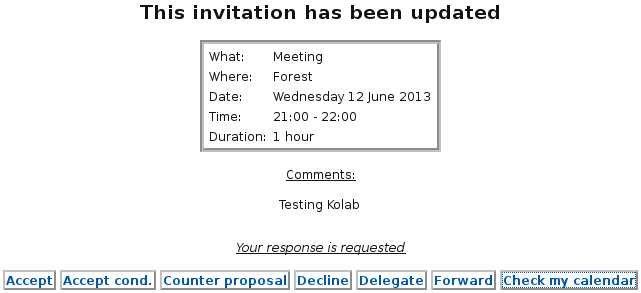
When standards-based calendaring has always involved e-mail, such talk of “integrated calendars” can most charitably be regarded as a clumsy way of asking for something else, namely an e-mail client that also shows calendars, and in the above case, the one that various people already happened to be using that they wanted to impose on everyone else as well. But the historical reality of the integration of calendars and e-mail has always involved e-mails inviting people to events, and those people receiving and responding to those invitation e-mails. That is all there is to it!
But in recent times, the way in which people’s calendars are managed and the way in which notifications about events are produced has come to involve “a server”. Now, some people believe that using a calendar must involve “a server” and that organising events must also involve doing so “on the server”, and that if one is going to start inviting people to things then they must also be present “on the same server”, but it is clear from the standards documents that “a server” was never a prerequisite for anything: they define mechanisms for scheduling based on peer-to-peer interactions through some unspecified medium, with e-mail as a specific medium defined in a standards document of its own.
Having “a server” is, of course, a convenient way for the big proprietary software vendors to sell their “big server” software, particularly if it encourages the customer to corrupt various other organisations with which they do business, but let us ignore that particular area of misbehaviour and consider the technical and organisational justifications for “the server”. And here, “server” does not mean a mail server, with all the asynchronous exchanges of information that the mail system brings with it: it is the Web server, at least in the standards-adhering realm, that is usually the kind of server being proposed.

The Superfluous Server
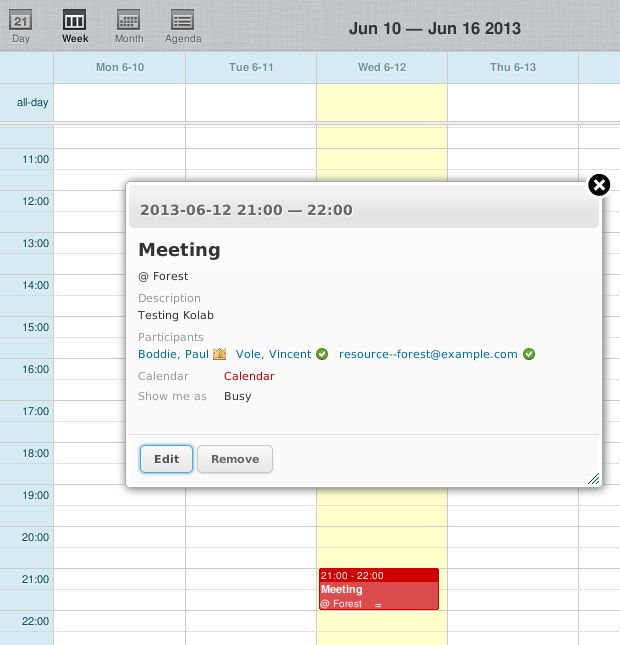
Given that you can send and receive messages containing events and other calendar-related things, and given that you can organise attendance of events over e-mail, what would the benefit of another kind of server be, exactly? Well, given that you might store your messages on a server supporting POP or IMAP (in the standards-employing realm, that is), one argument is that you might need somewhere to store your calendar in a similar way.
But aside from the need for messages to be queued somewhere while they await delivery, there is no requirement for messages to stay on the server. Indeed, POP server usage typically involves downloading messages rather than leaving them on the server. Similarly, one could store and access calendar information locally rather than having to go and ask a server about event details all the time. Various programs have supported such things for a long time.
Another argument for a server involves it having the job of maintaining a central repository of calendar and event details, where the “global knowledge” it has about everybody’s schedules can be used for maximum effect. So, if someone is planning a meeting and wants to know when the potential participants are available, they can instantly look such availability information up and decide on a time that is likely to be acceptable to everyone.
Now, in principle, this latter idea of being able to get everybody’s availability information quickly is rather compelling. But although a central repository of calendars could provide such information, it does not necessarily mean that a centralised calendar server is a prerequisite for convenient access to availability data. Indeed, the exchange of such data – referred to as “free/busy” data in the various standards – was defined for e-mail (and in general) at the end of the last century, although e-mail clients that can handle calendar data typically neglect to support such data exchanges, perhaps because it can be argued that e-mail might not obtain availability information quickly enough for someone impatiently scheduling a meeting.
But then again, the routine sharing of such information over e-mail, plus the caching of such data once received, would eliminate most legitimate concerns about being able to get at it quickly enough. And at least this mechanism would facilitate the sharing of such data between organisations, whereas people relying on different servers for such services might not be able to ask each other’s servers about such things (unless they have first implemented exotic and demanding mechanisms to do so). Even if a quick-to-answer service provided by, say, a Web server is desirable, there is nothing to stop e-mail programs from publishing availability details directly to the server over the Web and downloading them over the Web. Indeed, this has been done in certain calendar-capable e-mail clients for some time, too, and we will return to this later.
And so, this brings us to perhaps the real reason why some people regard a server as attractive: to have all the data residing in one place where it can potentially be inspected by people in an organisation who feel that they need to know what everyone is doing. Of course, there might be other benefits: backing up the data would involve accessing one location in the system architecture instead of potentially many different places, and thus it might avoid the need for a more thorough backup regime (that organisations might actually have, anyway). But the temptation to look and even change people’s schedules directly – invite them all to a mandatory meeting without asking, for example – is too great for some kinds of leadership.
With few truly-compelling reasons for a centralised server approach, it is interesting to see that many Free Software calendar solutions do actually use the server-centric CalDAV standard. Maybe it is just the way of the world that Web-centric solutions proliferate, requiring additional standardisation to cover situations already standardised in general and for e-mail specifically. There are also solutions, Free Software and otherwise, that may or may not provide CalDAV support but which depend on calendar details being stored in IMAP-accessible mail stores: Kolab does this, but also provides a CalDAV front-end, largely for the benefit of mobile and third-party clients.
Decentralisation on Demand
Ignoring, then, the supposed requirement of a central all-knowing server, and just going along with the e-mail infrastructure we already have, we do actually have the basis for a usable calendar environment already, more or less:
- People can share events with each other (using iCalendar)
- People can schedule events amongst themselves (using iTIP, specifically iMIP)
- People can find out each other’s availability to make the scheduling more efficient (preferably using iTIP but also in other ways)
Doing it this way also allows users to opt out of any centralised mechanisms – even if only provided for convenience – that are coordinating calendar-related activities in any given organisation. If someone wants to manage their own calendar locally and not have anything in the infrastructure trying to help them, they should be able to take that route. Of course, this requires them to have capable-enough software to handle calendar data, which can be something of an issue.
That Availability Problem Mentioned Earlier
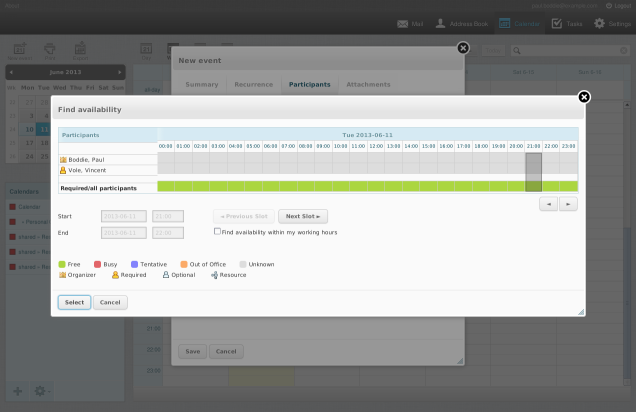
For instance, finding an e-mail program that knows how to send requests for free/busy information is a challenge, even though there are programs (possibly augmented with add-ons) that can send and understand events and other kinds of objects. In such circumstances, workarounds are required: one that I have implemented for the Lightning add-on for Thunderbird (or the Iceowl add-on for Icedove, if you use Debian) fetches free/busy details from a Web site, and it is also able to look up the necessary location of those details using LDAP. So, the resulting workflow looks like this:
- Create or open an event.
- Add someone to the list of people invited to that event.
- View that person’s availability.
- Lightning now uses the LDAP database to discover the free/busy URL.
- It then visits the free/busy URL and obtains the data.
- Finally, it presents the data in the availability panel.
Without LDAP, the free/busy URL could be obtained from a vCard property instead. In case you’re wondering, all of this is actually standardised or at least formalised to the level of a standard (for LDAP and for vCard).
If only I had the patience, I would add support for free/busy message exchange to Thunderbird, just as RFC 6047 would have had us do all along, and then the workflow would look like this:
- Create or open an event.
- Add someone to the list of people invited to an event.
- View that person’s availability.
- Lightning now uses the cached free/busy data already received via e-mail for the person, or it could send an e-mail to request it.
- It now presents any cached data. If it had to send a request, maybe a response is returned while the dialogue is still open.
Some people might argue that this is simply inadequate for “real-world needs”, but they forget that various calendar clients are likely to ask for availability data from some nominated server in an asynchronous fashion, anyway. That’s how a lot of this software is designed these days – Thunderbird uses callbacks everywhere – and there is no guarantee that a response will be instant.
Moreover, a request over e-mail to a recipient within the same organisation, which is where one might expect to get someone’s free/busy details almost instantly, could be serviced relatively quickly by an automated mechanism providing such information for those who are comfortable with it doing so. We will look at such automated mechanisms in a moment.
So, there are plenty of acceptable solutions that use different grades of decentralisation without needing to resort to that “big server” approach, if only to help out clients which don’t have the features one would ideally want to use. And there are ways of making the mail infrastructure smarter as well, not just to provide workarounds for clients, but also to provide genuinely useful functionality.

Agents and Automation
Groupware solutions offer more than just a simple means for people to organise things with each other: they also offer the means to coordinate access to organisational resources. Traditionally, resources such as meeting rooms, but potentially anything that could be borrowed or allocated, would have access administered using sign-up sheets and other simple mechanisms, possibly overseen by someone in a secretarial role. Such work can now be done automatically, and if we’re going to do everything via e-mail, the natural point of integrating such work is also within the mail system.
This is, in fact, one of the things that got me interested in Kolab to begin with. Once upon a time, back at the end of my degree studies, my final project concerned mobile software agents: code that was transmitted by e-mail to run once received (in a safe fashion) in order to perform some task. Although we aren’t dealing with mobile code here, the notion still applies that an e-mail is sent to an address in order for a task to be performed by the recipient. Instead of some code sent in the message performing the task, it is the code already deployed and acting as the recipient that determines the effect of the transaction by using the event information given in the message and combining it with the schedule information it already has.
Such agents, acting in response to messages sent to particular e-mail addresses, need knowledge about schedules and policies, but once again it is interesting to consider how much information and how many infrastructure dependencies they really need within a particular environment:
- Agents can be recipients of e-mail, waiting for booking requests
- Agents will respond to requests over e-mail
- Agents can manage their own schedule and availability
- Other aspects of their operation might require some integration with systems having some organisational knowledge
In other words, we could implement such agents as message handlers operating within the mail infrastructure. Can this be done conveniently? Of course: things like mail filtering happen routinely these days, and many kinds of systems take advantage of such mechanisms so that they can be notified by incoming messages over e-mail. Can this be done in a fairly general way? Certainly: despite the existence of fancy mechanisms involving daemons and sockets, it appears that mail transport agents (MTAs) like Postfix and Exim tend to support the invocation of programs as the least demanding way of handling incoming mail.
The Missing Pieces
So what specifically is needed to provide calendaring features for e-mail users in an incremental and relatively non-invasive way? If everyone is using e-mail software that understands calendar information and can perform scheduling, the only remaining obstacles are the provision of free/busy data and, for those who need it, the provision of agents for automated scheduling of resources and other typically-inanimate things.
Since those agents are interesting (at least to me), and since they may be implemented as e-mail handler programs, let us first look at what they would do. A conversation with an agent listening to mail on an address representing a resource would work like this (ignoring sanity checks and the potential for mischief):
- Someone sends a request to an address to book a resource, whereupon the agent provided by a handler program examines the incoming message.
- The agent figures out which periods of time are involved.
- The agent then checks its schedule to see if the requested periods are free for the resource.
- Where the periods can be booked, the agent replies indicating the “attendance” of the resource (that it reserves the resource). Otherwise, the agent replies “declining” the invitation (and does not reserve the resource).
With the agent needing to maintain a schedule for a resource, it is relatively straightforward for that information to be published in another form as free/busy data. It could be done through the sending of e-mail messages, but it could also be done by putting the data in a location served by a Web server. And so, details of the resource’s availability could be retrieved over the Web by e-mail programs that elect to retrieve such information in that way.
But what about the people who are invited to events? If their mail software cannot prepare free/busy descriptions and send such information to other people, how might their availability be determined? Well, using similar techniques to those employed during the above conversation, we can seek to deduce the necessary information by providing a handler program that examines outgoing messages:
- Someone sends a request to schedule an event.
- The request is sent to its recipients. Meanwhile, it is inspected by a handler program that determines the periods of time involved and the sender’s involvement in those periods.
- If the sender is attending the event, the program notes the sender’s “busy” status for the affected periods.
Similarly, when a person responds to a request, they will indicate their attendance and thus “busy” status for the affected periods. And by inspecting the outgoing response, the handler will get to know whether the person is going to be busy or not during those periods. And as a result, the handler is in a position to publish this data, either over e-mail or on the Web.
Mail handler programs can also be used to act upon messages received by individuals, too, just as is done for resources, and so a handler could automatically respond to e-mail requests for a person’s free/busy details (if that person chose to allow this). Such programs could even help support separate calendar management interfaces for those people whose mail software doesn’t understand anything at all about calendars and events.

Building on Top
So, by just adding a few handler programs to a mail system, we can support the following:
- Free/busy publishing and sharing for people whose software doesn’t support it already
- Autonomous agents managing resource availability
- Calendar interfaces for people without calendar-aware mail programs
Beyond some existing part of the mail system deciding who can receive mail and telling these programs about it, they do not need to care about how an organisation’s user information is managed. And through standardised interfaces, these programs can send messages off for storage without knowing what kind of system is involved in performing that task.
With such an approach, one can dip one’s toe into the ocean of possibilities and gradually paddle into deeper waters, instead of having to commit to the triathlon that multi-system configuration can often turn out to be. There will always be configuration issues, and help will inevitably be required to deal with them, but they will hopefully not be bound up in one big package that leads to the cry for help of “my groupware server doesn’t work any more, what has changed since I last configured it?” that one risks with solutions that try to solve every problem – real or imagined – all at the same time.
I don’t think things like calendaring should have to be introduced with a big fanfare, lots of change, a new “big box” product introducing different system components, and a stiff dose of upheaval for administrators and end-users. So, I intend to make my work available around this approach to groupware, not because I necessarily think it is superior to anything else, but because Free Software development should involve having a conversation about the different kinds of solutions that might meet user needs: a conversation that I suspect hasn’t really been had, or which ended in jeering about e-mail being a dead technology, replaced by more fashionable “social” or “responsive” technologies; a bizarre conclusion indeed when you aren’t even able to get an account with most fancy social networking services without an e-mail address.
It is possible that no-one but myself sees any merit in the strategy I have described, but maybe certain elements might prove useful or educational to others interested in similar things. And perhaps groupware will be less mysterious and more mundane as a result: not something that is exclusive to fancy cloud services, but something that is just another tiny part of the software available through each user’s and each organisation’s chosen operating system distribution, doing the hard work and not making a fuss about it. Which, like e-mail, is what it probably should have been all along.