The Scandisplaining of Digital Freedoms
Monday, April 6th, 2026Recently, the Norwegian Consumer Council has been enjoying a degree of publicity for a campaign they have been running about the “enshittification” of the Internet, riffing on the overused term coined by Cory Doctorow to describe the deliberate degradation of products and services given an absence of real choice and competition in the marketplace. Naturally, international news organisations have lapped this up as another example of supposedly progressive Scandinavian social and political priorities. That plucky Norway could show the rest of the world how to deal with predatory Big Tech.
As always, the story is rather more nuanced if one is more familiar with how things typically go in Norway and, I can well imagine, the rest of Scandinavia. First of all, one can justifiably wonder where these people have been living for the past quarter century. Time and again, Free Software advocates have pointed out that a reliance on proprietary software and platforms ultimately harms individuals, institutions and societies. Over ten years ago now, I myself sought to prevent the introduction of a proprietary groupware platform in a public institution that had been my employer. By the time I was meeting the hostile and dismissive leadership of that institution, I wasn’t even working there any more. The meeting ended with the overpromoted head of the institution, flanked by his privileged and/or hectoring enforcers, insisting that “Microsoft would never do anything that wasn’t in their customers’ best interests”. In the sitcom version of events, cue the laughter track.
I ended up doing some legwork in my own time to dig into the nature of the commercial arrangements between the institution and its supplier, but all the “commercially sensitive” bits involving actual monetary amounts were redacted. My own motivation to pursue the matter was rather tempered by the fact that some of those who felt that this commercial arrangement impeded various workplace freedoms of theirs would not pursue the matter themselves. After all, they didn’t want their nice salary and other bespoke workplace arrangements in their permanent employment position endangered by any kind of actual activism. Evidently, this was the job of the guy whose temporary contract had ended. Having presented my findings, nothing further happened and those precious freedoms were not generally upheld. But technical workarounds let various people pretend that business could proceed as usual. Their nests remained fully feathered. Screw the plebs: they would have to get used to Exchange, anyway.
I wish I could claim prescience in the whole affair, but it was pretty obvious how things would end up going. I remarked that at some point, “on-premises” Exchange would be phased out in favour of a cloud-based solution, likely to be what I tend to call Office 360. Fast-forward to recent times, and of course that is exactly what has been happening, with the institution presumably pleading poverty. Why not just make your employees customers of a foreign corporation, regardless of the wrapping of the institutional package? They have to take that deal whether they like it or not. Now, there may have been some chatter about these new arrangements. Right now, I cannot consult my own archives to check, but I would have been right to say “I told you so”. Some of the supposed champions of freedom may be more concerned that with a full-on migration to the cloud, all those neat workarounds of theirs might finally become obsolete. Maybe it will finally become time for them to face up to everybody else’s reality.
Once Upon a Time
For a time, Norway had a public agency that was meant to promote Free Software and interoperability in the public sector. Lobbied by the usual proprietary software vultures, the incoming right-wing government happily shut it down in a wave of the usual austerity that such governments love to inflict on public institutions, public infrastructure, and the wider population, just as they slash taxes for the wealthy in the name of “wealth creation”. Precisely these kinds of political choices, familiar from countries with more obvious records of punitive austerity, like Britain under the likes of Margaret Thatcher, John Major, David Cameron, and the subsequent clown car parade of prime ministers in the last Conservative administration, degrade societal resilience and undermine things like digital and technological sovereignty that are now suddenly in vogue.
An international audience might be surprised that supposedly egalitarian and progressive Norway might exhibit such traits. Comparable political shifts in Sweden and Denmark, undoubtedly inspired by the cruelty-enabling culture of “personal aspiration” (selfishness, in other words) promoted by British Conservatism, have similarly gone unnoticed or have been gradually forgotten. That a bunch of people in Norway haven’t managed to follow along rather suggests that the tradition of navel-gazing is alive and surprisingly well. After all, if the gravy train kept running from your station, then what was the problem again, exactly?
This latest initiative’s open letter to the Norwegian government notes that the French public sector made concerted efforts to introduce Free Software from 2012 onwards. How quickly people forget that back in 2012, that soon-to-be-culled Norwegian public agency was trying to bring the Norwegian public sector round to undertaking similar kinds of endeavour, doing it the celebrated Scandinavian way of not treading on too many toes. Naturally, such an approach was never going to be resistant to the kind of predatory corporate interests who routinely siphon billions of crowns, pounds, euros and dollars from the public sector locally and internationally for supplying their mediocre and often blatantly deficient products and services, subjecting governments and thus taxpayers to coercive, ruinous and yet seemingly perpetual contracts.
Those previous efforts might have been envisaged as a viable means to a righteous end, but they may have ended up being regarded simply as a nice supplement for those already engaging in the kind of advocacy that makes people feel like they’re “doing something”. It was another voice in the chorus of righteousness, and with an accompanying annual conference, it was yet another venue to talk about things and congratulate each other, rather than do those things necessary to actually advance the cause. It was even held in Svalbard on one occasion, if I remember correctly, because nothing says more about a commitment to sustainability than having a bunch of people jet off to the realm of polar bears and those melting ice floes.
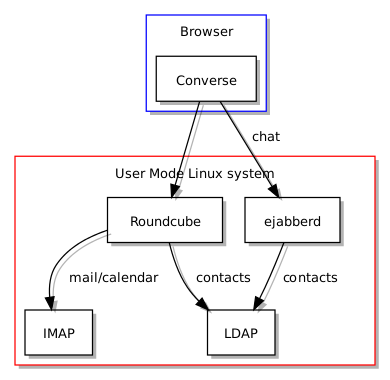
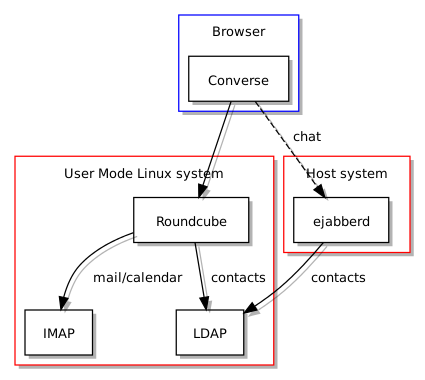
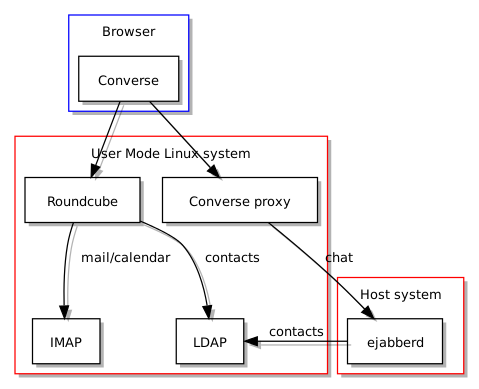
So, what things would have advanced the cause, then? Well, the first thing would have been to actually fund Free Software at scale and to make sure that when people tout solutions for widespread use, they are actually fit for the job. And no, gathering up a bunch of existing projects and promoting them is absolutely not the same thing. When I investigated Free Software groupware solutions, the popular wisdom was that Kolab had “solved” groupware many years earlier. It turned out that Kolab had been rewritten as version 3 and was inadequate in a number of ways: a half-finished solution. Efforts to try and engage with the developers became futile. Despite pitching the software as a collaboratively developed Free Software project, all they really cared about was whether the software would support the operations of a now-liquidated Swiss company riding the privacy bandwagon and largely targeting the Jason Bourne brigade.
Such experiences made me suspect that Kolabs 1 and 2 might not have been adequate all along, either, possibly pitched as a good-enough solution to a problem that hadn’t been fully understood, all to serve various big-fish, small-pond commercial interests. Later on, I discovered Zarafa, which became Kopano, and wished I had found it earlier. It may have been a better choice, not least because the dopes insisting on Microsoft Everything would have seen the Web interface and thought that it was straight out of Redmond, unlike Microsoft’s own Web-based Outlook solution, perversely. Sadly, as a sign of our depressing times, Kopano is now becoming (or has become) a cloud-only product.
It may seem obvious, but it still needs saying: general advocacy and encouragement isn’t sufficient; people need working solutions. And experience also shows that one cannot leave it to “the market”, whatever that is in Free Software. For many years, I have used KMail to read and send e-mail. It remains surprisingly usable today, “surprisingly” because its developers decided at one point to adopt some weird middleware layer called Akonadi, entranced by the promises made by Microsoft and/or Apple to deliver pervasive “desktop search” capabilities in their own products. Whether Microsoft or Apple actually delivered or, more likely, abandoned or scaled back those promises, I am now compelled to run the command “akonadictl restart” almost every day to “unwedge” my mail client and get to see newly arrived mail.
(It also didn’t help that the developers introduced MySQL – now MariaDB – into the mix, and that in the maintenance of that product, which throughout its existence under its various names could uncharitably be described as Monty Widenius’ Flying Shitshow, someone decided to bump a version number in a minor (or actually a patch-level) release that caused the whole stack of software to refuse to access the arguably unnecessary database underpinning KMail, making my mail inaccessible. Fortunately, my case was heard within Debian, and remedies were eventually applied. Before that, I had to recompile the package with an appropriate workaround. A victory for Free Software pragmatism, but good luck to the average user suddenly staring down a potentially indefinite e-mail outage.)
Free Software groupware applications, like the overall desktop experience, stopped showing year-on-year progress in functionality some time ago. Already degraded in various ways when the developers of such technology became distracted by what the big players said they would be doing, the arrival of social media seemed to make some developers believe that the era of the mail program had ended altogether. It apparently became more important to some of those developers to add “share on Facebook” menu items to random applications than to ensure that their applications were still usefully serving their loyal users.
(Observations that technologies like ActivityPub and applications like Mastodon can supplant boring old e-mail and that they have shown considerable growth, and yet remain in a niche, rather overlook – indeed, neglect – the fundamental variety in groupware and collaborative technologies. A strategy of “ActivityPub everywhere” is like keeping the big hammer and throwing away all the other tools in the toolbox. One might suspect that it is only now gaining traction because there are people who want a similar kind of buzz to the one they get from their favourite doomscrolling services but feel bad going back to the same, increasingly disreputable dealer.)
The lesson here is that someone firstly needs to develop functional software, but then to check and double-check that functionality, as well as continuously verifying whether the software meets people’s needs. This cannot be left to random developers or to companies. The big Linux distributions never really cared enough about the average user to finish the job, merely bundling stuff and maybe hiring developers to either dabble with their projects or to make them only good enough for narrow corporate advantage. As far as Red Hat’s bottom line was concerned, all that ever really mattered was a placeholder desktop good enough to do a bit of point-and-click system administration for a bunch of file and print servers propping up a bunch of Windows desktops, or for software development most likely involving Java and targeting “the enterprise”. Such companies happily make their own employees use proprietary software and services for the kinds of tasks that the average user does, regardless of whether they might be using Free Software office and groupware suites instead.
The right approach would have been a concerted government initiative resistant to lobbying and corruption, not mere advocacy, nudging and cajoling. Genuine standards and interoperability could have been mandated and corrupted pseudo-standards like Microsoft’s fast-tracked office formats rejected. Agencies like Statistics Norway should have been taken to task for stipulating “.doc” as their chosen “interoperable” format, with those responsible sent back to finish, or maybe even begin, their education. One might have learned from experiences in other countries, like that of the public key encryption software Gpg4win in Germany, where a genuine governmental need transformed the financial viability of the GnuPG software project from one which had been chronically underfunded and practically relying on the charity of its principal developer to a thriving, viable enterprise.
Proprietary software lobbyists had criticised Norway’s earlier soft-touch efforts, claiming that the public agency concerned was subsidising uncompetitive software that was presumably the work of hippies and communists. There was one case of a public institution wanting to give money to a Free Software project in the realm of PDF generation, if I recall correctly. Upon discovering that it was Free Software, decision-makers refused to make the donation: after all, if those people were giving their code away, why pay after the fact? Such paper-pushing idiots evidently failed to understand that such windfalls may only happen once. Some of them would undoubtedly and routinely use the Norwegian word for “farmers” in the pejorative way for people they might consider ignorant, and yet farmers manage to understand that harvests do not magically occur and re-occur without cultivation and sustenance.
The right approach would also have involved mandating Free Software for publicly funded projects and for public infrastructure, as advocated by the FSFE’s Public Money Public Code campaign. Proprietary software interests would undoubtedly howl at such stipulations, claiming that their secret sauce software, supposedly written by Top Men, would be unfairly excluded from such markets. But just as even some ostensibly left-wing politicians have forgotten, “markets” only exist at the indulgence of governments and regulators, and they only operate in the public interest if properly framed and regulated. Don’t want to give your customers the freedom to maintain the code they are paying for? Feel free to seek opportunities elsewhere, then. Cushy lock-in deals for the locally well-connected should have gone the way of Norsk Data when that company fell to Earth.
Planet Norway
Attitudes to societal threats seem to be remarkably relaxed in our supposedly enlightened democracies and their institutions. The casual, pervasive use of predatory social media platforms continues, propped up by state institutions claiming that they need to have a presence in all the different channels, but where one suspects that a few managers and their appointees just want to play with some toys and puff up their public profiles. Instead of leveraging the resources of the state and providing reliable channels of communication, such bodies post announcements, updates and nonsense via foreign-owned hate speech venues. Norwegian political party leaders even decided at one point that they had to promote themselves on Snapchat, egged on by one of the national broadcasters. Now, we see the unquestioning adoption and promotion of “AI” and chatbots by institutions that risk being obliterated by such technologies.
At the individual level, concerns about “screen time” and the use of tablets and other devices in places like primary schools have been aired and may well be justified, given the likely developmental impact on children of such devices, but it all comes across as pearl-clutching when one suspects that the lifestyle of the vocal parents probably revolves around their phone, “apps”, streaming services, and rather too much screen time of their own. And some of those concerned about screen time would probably drop their objections if a study conveniently came along to assuage their worries. It is just like those very Scandinavian traits of stuffing tobacco products into one’s mouth or spending time at the tanning studio, neither of which are actually healthy. Over the years, various pseudo-academic figures and findings have occasionally floated up into public prominence, insisting that such things are perfectly fine. Why wouldn’t that happen with technology? The companies involved could certainly afford to pay for a bit of fake research and a few willing advocates.
One gets the impression that many of the different factions that might coalesce around a campaign about “enshittification” aren’t really trying to achieve systemic change: they merely want to negotiate a better deal. Such people knew what they were getting into by using free-of-charge services and often explicitly rejecting genuinely free alternatives which cost only modest sums to run. Such people were also aware that their data might wander off into the cloud and away to places where it would be mined and exploited for all it is worth, but caring about it was just too much bother. In institutions, all it takes is for Microsoft to “pinky swear” that it complies with data protection regulations. Institutional capabilities are then run down and alternatives abandoned, just so the toys can be unpacked, sending non-trivial sums overseas instead of cultivating knowledge, opportunities and wealth locally.
One wonders how seriously people really want to take such matters, or whether they just want a hobby and to feel good about a bit of casual activism. I am reminded of the climate litigation brought against the Norwegian state for its continuing policy of fossil fuel extraction, noting that climate change presents an existential threat reaching far beyond the confines of the nation, affecting the population of the entire planet, but where the country’s constitution at least worries about the state of the nation for future generations. The outcome – a defeat for the litigants – might not merely be described as positioning Norway as having “first world problems”: that would be business as usual. Instead, it might reasonably be described as situating Norway on a planet of its very own. One where the mere accumulation of money protects and even “benefits future generations“, evidently.
Hobby activism is typical of places where the stakes remain relatively low for those doing the campaigning, but on Planet Norway it arguably reaches another level, where hardship along any given dimension is often perceived to be a problem that only foreigners in poorer countries experience (or poorer planets, maybe). Or it is marginalised and framed as something that only affects a vanishingly small number of people, conveniently aided by policies and attitudes that seek to hide those who are struggling and blame them for their own predicament. But a reckoning is surely overdue even in matters of preference as opposed to need. After all, what good is it to advocate that children learn to code if nothing is done about the way “AI” is devastating Free Software and undermining paid work?
Unlike outsider perceptions of the money flowing freely in Norway thanks to the oil fund, the purse strings are generally not loosened for those whose professions have been gutted. And for younger people, they are more likely to be told to take shifts at Ikea than get the help they need. Yes, this is actually a thing. It also explains why on one local recruitment site, when filling out one’s employment history, the default value in the employer field reads (or read when I last checked) “Ikea Furuset”: one of the two full-scale Ikea stores serving the Oslo area. Not that there’s anything wrong with working at Ikea, but I doubt that the kind of aspirational parents hoping to give their little darlings a head start in the world, funding their higher education and other ambitions, would see it as a fitting venue for their offspring’s many talents.
Yet Another Elephant in the Room
This latest campaign recommends Free Software and open protocols in public procurement, which is what previous efforts pretty much did, too. The accompanying report even suggests funding alternatives, but then delegates this to discretionary funds and foundations, conveniently avoiding the structural issues. But the very reason why “dominant big tech companies have deep pockets” is through a perversion of economic incentives. Firstly, they have cultivated an “expectation of zero” where individual and institutional customers expect software and services to cost nothing. Thus, any investment in software is regarded as unnecessary because those nice corporations are giving away shiny free stuff. They also front-run various standards to make any kind of competition ruinously expensive to pursue.
And yet software cannot be developed without expenditure, and certainly not with the latest instrument being used to sustain those cultivated consumer expectations. “AI”, which is hyped to make it seem like software can be whipped up at a moment’s notice at no cost, relies on industrial scale plagiarism, colossal data centre and hardware investments, and ruinous levels of power consumption. What has funded these scorched earth tactics is a corrosive business model that inflicts highly lucrative but consequence-free, unpoliced advertising channels on billions of people. Developers at predominantly American technology company aren’t expected to work for free, after all. We are apparently meant to feel sorry for them. Some of them have to pay gentrification-level prices for their homes in places gentrified by themselves and their colleagues. Their bosses expect huge bonuses, their own yacht, island, spaceship…
Claiming the juvenile right of unrestricted free speech to drive engagement, Big Tech has largely allowed unregulated commerce to proceed, undermining traditional safeguards, endangering individuals, and threatening and even shuttering viable, responsible businesses. Any efforts that ignore such structural issues will fail to find the money required to make a difference. I, or my Web publisher, may be held to account for what I write, but anything goes on the predatory Big Tech platforms, whether it is the puerile variant of “free speech” cultivated by the increasingly fragile American dream, or whether it is fraudulent or outright illegal advertising promoting dishonest and criminal enterprises. Allowing such business to continue as usual simply enriches these predators while impoverishing ourselves.
The operators of those platforms are getting a free ride at a severe cost to us and our societies. It may not seem like it to the random punter getting “a great deal”, but we all pay for that deal in the end. And even little Norway has its own commerce platforms that look the other way, especially where anything related to the property bubble is concerned. Why not advertise your rental property using the fancy sales prospectus from a few years ago when you or a previous owner bought the property from the developers? Oh, “caveat emptor“, of course. How about advertising a property with a non-existent address? How much money is laundered even in little Norway, or is that kind of thing only done by foreign people in less enlightened countries? Maybe even the same people whose oil is “dirty” while Norway’s is “clean”.
Anything short of changing the flawed terms under which those companies operate, which one can barely believe are legal in the first place, is nothing more than consumerist tinkering. Naturally, there will be howling from entitled consumers, happy to have random people scurrying around with their urgent shopping deliveries, just as established, essential services like postal mail risk being degraded to the point of near uselessness or even eliminated altogether (which is something that might blow the minds of media people in countries like the UK where postal services still largely hold up and where deliveries still happen six days a week). But society cannot pander to people’s elevated levels of personal entitlement forever, despite the best efforts of populist politicians living in their own bubble of affluence.
I suppose I could be accused of being a simple “outsider” who still doesn’t understand Norway after all these years. Recently, I read a ridiculous piece claiming that Norwegian culture and society does not tend to focus on personalities. That would be news to readers of gossip magazines, newspapers, and even the finance magazine I would read in a medical specialist’s waiting room, keeping us all up to date on which members of the Norwegian financial and legal elites were suing which other members of those elites, all while name-dropping and generally cultivating individuals as movers and shakers.
But instead of cherry picking parts of the nation’s broader, pan-Scandinavian heritage – Janteloven in that particular case – and perpetuating all the other familiar tropes, so often featured in selective, favourable cultural projection delivered through credulous or lazy journalistic coverage, maybe lessons could be learned from one of Hans Christian Andersen’s more famous tales. It really doesn’t take very much to point out that notions of Scandinavian preparedness in the face of digital exploitation and its accompanying threats are somewhat overstated. Anyone caring to take a closer look at the emperor’s reputation as a fully clothed, well-tailored individual can do it, if they actually care to.
I just wouldn’t recommend anyone holding their breath for too long in anticipation of decisive, credible Scandinavian action that might show the wider world the way forward. After that sharp intake of breath witnessing the emperor in the buff, please exhale or you might eventually expire. Just like in other countries, there would have to be a cultural shift away from shopping for “big brand” software, wheeling in the consultants, having retreats and “away days” learning about the next set of goodies on the proprietary software treadmill, and treating predatory social media platforms as merely a harmless guilty pleasure. Maybe local commerce wouldn’t have to be mediated by “apps” and trillion dollar corporations, either. And there would have to be more than tame, hobbyist lobbying and performative activism: quite the challenge when rocking the boat in countries like Norway is simply never done.
But it all made for a good story about Scandinavia leading the way, as usual, so “job done”, I guess.