Integrating setup-kolab with Debian Packaging
Wednesday, December 18th, 2013My recent diversion via pykolab may appear to have rather little to do with the matter of improving the Debian packaging situation for Kolab, but after initial tidying exercises with the pykolab code, I started to consider how the setup-kolab program should behave in the context of Debian packaging operations: what it should do when a package is installed, if anything, and whether it can rely on anything having been configured in advance. Until now, setup-kolab has been regarded as a tool that is run once the Kolab software is mostly or completely present on a system, but this is a somewhat different approach to the way many service-providing Debian packages are set up.
Take MySQL as an example. Upon installing the appropriate Debian package providing the MySQL server, the user is prompted to set up the administrative credentials for the server. After this brief interaction, MySQL should be available for general use without further configuration work, although it may be the case that some tuning might be beneficial. It seems to me that Kolab could be delivered with the same convenience in Debian.
The Different Ways of Configuring Kolab
Until now, many of the individual Kolab meta-packages – those grouping together individual components as functional units providing mail transport (MTA), storage (IMAP) or directory (LDAP) functionality – have only indirectly relied on the presence of the kolab-conf package providing the setup-kolab program. Indeed, if the top-level kolab meta-package is installed, kolab-conf will be pulled in as a dependency and setup-kolab will be available, and as noted above, since setup-kolab has been the program that configures a complete system, this makes some sense. However, this causes the work of configuring Kolab to be put off until the very end and thus to pile up so that a user may have to undertake a lengthy question-and-answer process to get the software working, and this can lead to mistakes and a non-working installation.
But setup-kolab is familiar with the notion of configuring individual components. Although the Kolab documentation has emphasised a “one shot” configuration of everything at once, setup-kolab can be asked to configure different individual things, such as the LDAP integration or the integration with Roundcube (the webmail software supported by Kolab). Thus, it becomes interesting to consider whether individual packages can be configured one by one using setup-kolab until they have all been configured, and whether this produces the same desired result of everything having been set up (and hopefully without the same intensity of questioning).
To make setup-kolab available to packages during their configuration, the kolab-conf package providing the program must be a dependency of each of the packages concerned. Here is a nice little diagram illustrating the result of a few adjustments to the dependency graph:
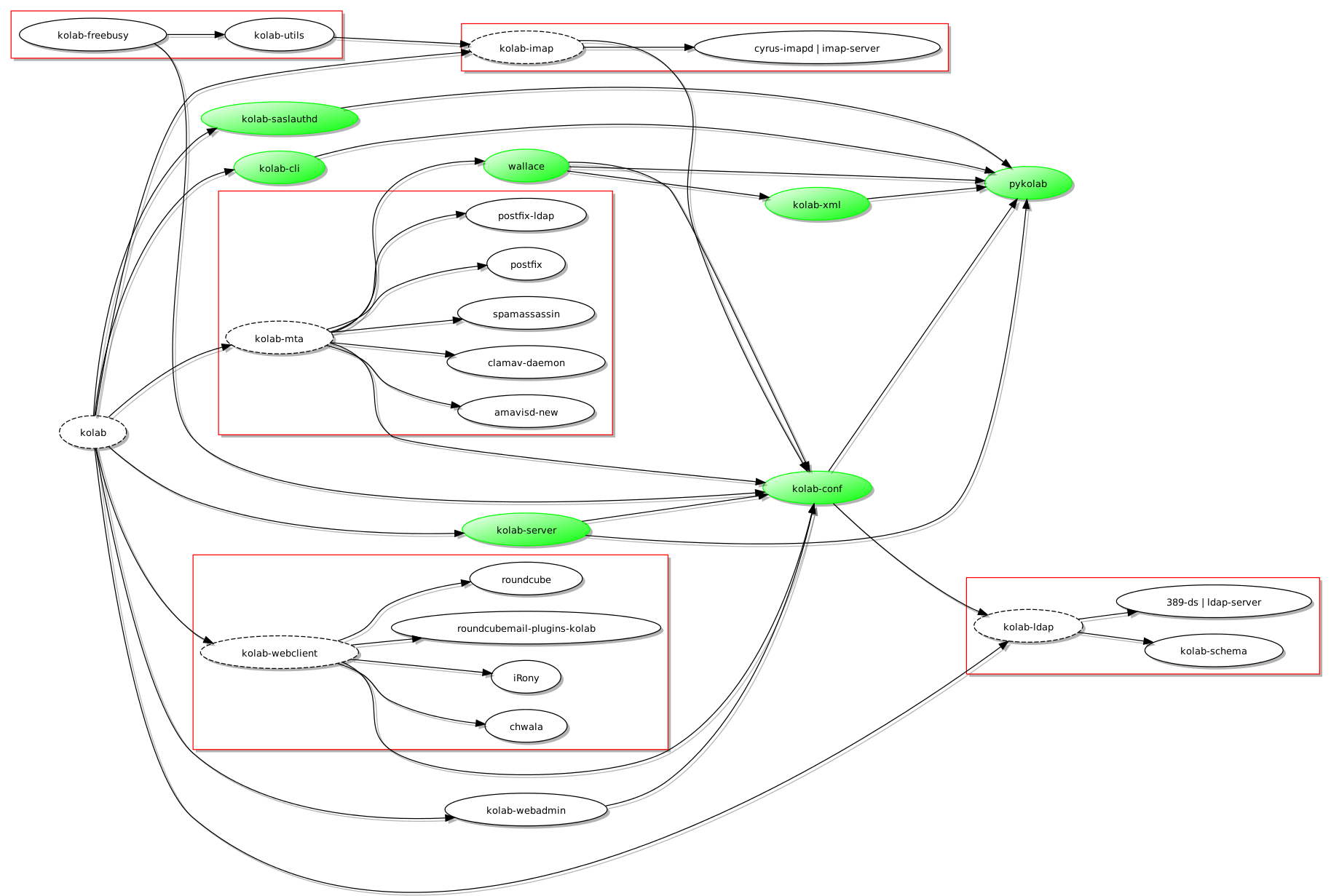
A revised dependency graph for Kolab (produced using Graphviz and tidied up using a modified version of vidarh's notugly.xsl stylesheet)
(Here, the pykolab packages are coloured in green and have been allowed to float freely to make the layout cleaner: pykolab contributes in a number of ways and the introduction of kolab-conf as a dependency of a few packages means that it is very much “in demand” by all parts of the graph.)
Now, with kolab-conf available when, for example, kolab-imap is being installed, the post-installation script of kolab-imap will be able to invoke setup-kolab and to make sure that a usable configuration is available by the time the Debian packaging system is done with the installation activity. But one thing might be bothering the attentive reader: why is kolab-ldap not dependent on kolab-conf? In fact, the configuration process has to start somewhere, and since information related to the LDAP directory is rather central to further configuration, this initial configuration takes place when the kolab-conf package is itself installed. And since this initial configuration needs access to the LDAP system, the dependency relationship is “inverted” for this single case, and kolab-conf populates the basic configuration so that subsequent package configuration can take advantage of this initial work.
Communicating with the User
Command line usage of setup-kolab involves some fairly straightforward console-style prompting and input, but during Debian packaging activities, it is widely regarded as a bad thing to have packaging scripts just ask for things from standard input and just write out messages to standard output or standard error: people may be using graphical package management tools that offer alternative facilities for user interaction, and it is possible that console-style operations go completely unnoticed by both the user and such tools. Thus, there is a need to make setup-kolab aware of the facility known as debconf (which is not to be confused with the DebConf series of conferences that may well appear in any searches made to try and discover documentation about the debconf system).
It would appear that debconf is used primarily within shell scripts, as the packaging scripts most commonly use the shell command language, but a goal of this work is surely to avoid replicating the activities of setup-kolab in other programs: it is not particularly desirable to have to rewrite the component-specific parts of pykolab in shell command language just to be able to use debconf to talk to users. Fortunately, the debconf package provides a Python wrapper for the debconf system, and although the documentation and examples are not particularly substantial or enlightening, a bit of experimentation and some consultation of the debconf specification has led to a workable level of interaction between setup-kolab and debconf so that the latter can prompt the user and supply the user’s input to the former without too much complaint.
What Next?
As previously stated, the aim now is to try and get the pykolab changes upstream – regardless of the Debian-related modifications, pykolab has been enhanced in other ways – and to try and reach consensus about whether this way of structuring the Debian dependencies is sensible or not. A substantial number of iterations involving pykolab adjustments, packaging improvements, pbuilder sessions and eventual deployment of the new packages in a virtual machine seem to indicate that the approach is not completely impractical, but it is possible that there are better ways of doing some of this work.
But certainly, my confidence in the Debian packaging situation for Kolab is significantly higher than it was before. I can now see a time when the matter of installing and configuring Kolab (at least for common deployment situations) will be seen as entirely uninteresting and a largely solved problem. Then, people will be able to concentrate on more interesting matters instead.