The End of the Minicomputing Era
Wednesday, March 11th, 2026Previously, I described the glory and the turmoil of the 1980s for Norsk Data and its competitors in minicomputing, the rise of the workstation and Unix, and Norsk Data’s attempts to maintain a claimed performance advantage over Digital’s VAX and over RISC workstations from a variety of manufacturers. An unconvincing Unix implementation had marginalised its minicomputers, and the workstation phenomenon had eroded sales of minicomputers more generally. This combination had taken revenue from Norsk Data in venues like CERN, where the company had once presumably expected continued growth amidst an appetite for its capable and relatively well-priced machines.
Norsk Data’s attempts to introduce workstations had seen specialised products targeting specific disciplines or activities, such as artificial intelligence (AI) or computer-aided design and manufacturing (CAD/CAM), that in some respects appeared more to pander to the workstation phenomenon as if it were a passing fad, as opposed to engaging with it substantially. Its AI workstation was a rebadged minicomputer that appears to have persisted with the familiar terminal-based paradigm, merely adjusted to use graphical terminals instead of character-based ones. Its CAD workstations seem to have been developed in an organisational silo, taking the minicomputer hardware and, with the addition of graphical output and various input devices, producing what would have been called a “suite” or dedicated workspace for its users.
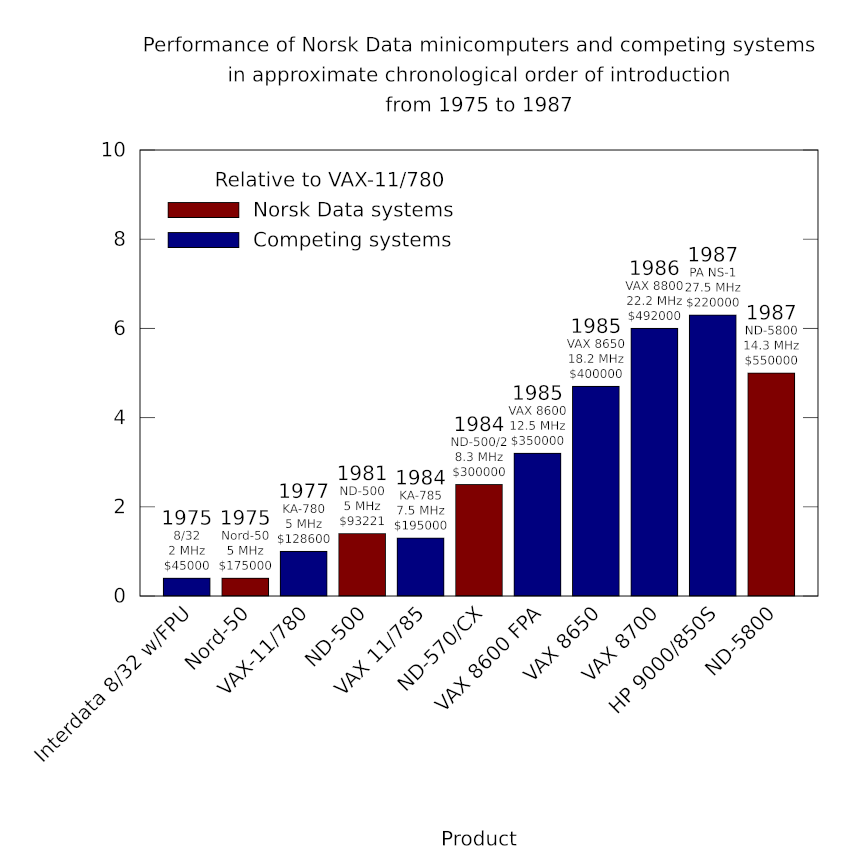
As competition intensified, capitalising on the weaknesses in certain areas of performance of established minicomputer products and Digital’s VAX in particular, some manufacturers sought to move upmarket with more affordable systems that would, only a few years earlier, have been considered well within supercomputing territory. And so, their target shifted from the likes of Digital to established supercomputer companies, attempting to take low-end sales away from them. Norsk Data’s performance record had been at least respectable, and so such a move upmarket would have seemed entirely natural to contemplate.
Of Superminis, Minisupers and Microelectronics
Evidently, Norsk Data did aspire to enter this minisupercomputer market, following the lead of various other companies who sought to undercut the likes of Cray with high-performance machines at somewhat lower, but still rather robust, prices. The principal route to doing this was to offer vector processing support, introducing hardware support to perform operations on collections of inputs in a more efficient fashion than in a conventional machine. Thus, computationally intensive tasks of the appropriate kind could be accelerated to a considerable degree.
Established companies such as Amdahl, Digital, ICL and IBM had all brought vector processing units to market to complement the capabilities of their machines. Floating-point processor vendors moved upmarket into the category, looking for new opportunities as conventional machines became more powerful. Other vendors such as Ardent Computer, Alliant Computer Systems, Convex Computer and Stellar Computer focused on complete systems as opposed to accelerators for other machines. Other avenues for minisupercomputing existed, too, notably massively parallel systems made by companies like Meiko Scientific, nCUBE and Thinking Machines.
Norsk Data’s effort seemed to centre on its collaboration with Matra, but few results seem to have emerged. One such result may have been dedicated microcode for array processing, available for its ND-500 systems, offering speed-ups of around four or five times on various operations. Although this testified to the versatility of the processor architecture, one might wonder how work on the ND-5000 affected considerations by introducing pipelining and potentially squeezing out some of the redundancy that perhaps permitted such speed-ups in the first place. Matra was a company whose eyes were bigger than its stomach, undertaking ambitious levels of diversification from missiles to cars, watches, semiconductors, home computers, and then scientific and engineering computers. Spinning up numerous collaborations including one with Sun Microsystems, it even developed its own Unix-based “artificial intelligence server”, only to suddenly pull out of computing altogether.
To otherwise increase system performance further, Norsk Data’s approach was to couple several processors together, sharing memory and offering a form of symmetric multiprocessing. Thus, the ND-500 and ND-5000 ranges had models that effectively replicated the processing unit of the top-end single-processor model, providing two, three or four processors. This could potentially increase the throughput of a system, although the company’s odd benchmarking practices had them quoting multiples of the Whetstone benchmark scores reportedly achieved by the core single-processor system. Given that Whetstone does not attempt to measure multiprocessing performance, this was optimistic opportunism at best, a cynical marketing ploy at worst.
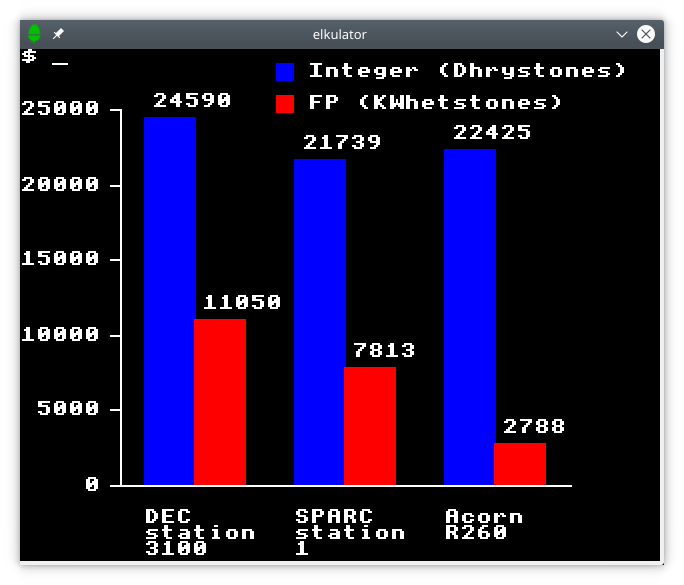
Regardless of whether a top-end ND-5900/4 (claiming 26 MWIPS) or ND-5950 ES L14 (claiming 120 MWIPS) might have rivalled well-known minisupercomputer models, there will have been one sticking point: those models all ran one form or other of Unix. In some cases, their vendors had grown out of the floating-point accelerator market, seeing the opportunity to pitch complete systems to compete more directly with the unfortunate Digital whose VAX models remained the baseline for comparison. For instance, Floating Point Systems had acquired Celerity Computing which had itself attempted this transition but found itself confronted with a downturn in the market.
One might think that once a company has been absorbed by another, its story is effectively over, but Celerity Computing’s expertise gave Floating Point Systems new products, and the combined company was later acquired by Cray. When Cray was itself acquired by Silicon Graphics, the division originating in those operations from Celerity and FPS was considered surplus to requirements, perhaps even a liability, utilising SPARC-based technologies in multiprocessor “superservers” aimed at data processing applications. SGI divested itself of the division, selling it to Sun, where this superserver technology became a hit product in the form of the Ultra Enterprise 10000, just at the right time to profit substantially from all the spending on Internet and enterprise servers during the dot-com bubble.
Another “minisuper” vendor, Convex Computer, produced some very ambitious systems, utilising vector processing and techniques previously seen on supercomputers from Cray. Producing respectable performance with its initial single-processor products, having invested in vectorising compilers that it licensed to other companies, the company was forced to adopt multiprocessing to prevent being outflanked by competitors employing more general parallelism in their designs. Like Norsk Data, Convex relied on CMOS gate array technology to implement its processor architecture, and the company apparently introduced ECL technology in its C2 range.
It continued introducing systems based on gate array technology, employing chips based on gallium arsenide transistor logic in 1991, but ultimately had to accept that mainstream processors were outcompeting such low volume designs, and after plans to use the MIPS R4000 were dropped, the company adopted Hewlett-Packard’s PA-RISC processors in subsequent models. Eventually, HP acquired Convex, integrating some of its products, which by then were running HP’s own Unix, into its own range. Once again, a pioneer in this realm would leave a technological legacy through an act of corporate consolidation.
Even if the pressures of the market had been different, one has to wonder about the economic model involved with Norsk Data’s own hardware efforts and the accompanying technological choices. Companies like ICL stuck with ECL and CMOS gate arrays instead of aiming for large volume VLSI products, but ICL sold expensive mainframe systems in relatively low volumes, and the costs accompanying the use of racks of boards packed with gate arrays and other chips, and the meticulous process of assembling each system, could be absorbed in the purchase price. Even then, ICL eventually transitioned its mainframe products to commodity Intel-based hardware, running its platforms under emulation.
For a vendor like Norsk Data, the general progress of technology coupled with the company’s positioning in the market – neither a low-end, high-volume supplier, nor a premium, top-end supplier – meant that it had to evolve to remain competitive. ICL could justify being leisurely in its own predicament, having the substantial backing of Fujitsu and an entrenched position in the UK public sector. And if relatively small companies like Acorn could enter the processor space with VLSI chipsets, one really has to wonder why Norsk Data, with all its expertise, never sought to do the same. Such considerations impacted other companies. Sun Microsystems first introduced the SPARC processor implemented in a Fujitsu CMOS gate array product, engaging various fabrication partners to produce follow-up VLSI products.
Apollo Computer, as a leading workstation manufacturer, was perhaps a nemesis that Norsk Data never really accepted that it had. As other workstation companies jumped ship from Motorola’s popular but lagging 68000 family, Apollo developed its own credible RISC architecture, delivering it in the DN10000 workstation. However, the PRISM processor was a multiple chip implementation, and just as Hewlett-Packard had delivered the first PA-RISC processor in a similar fashion, only to rationalise the implementation in subsequent products, Apollo needed to take a similar route. Difficulties in doing so eventually contributed to Apollo being acquired by HP and its technologies absorbed by the larger company, helping make PA-RISC usable in multiprocessing systems.
It could have been argued that Norsk Data’s ND-500 and ND-5000 processors were simply too complicated to be squeezed into small VLSI chips. Such excuses would hardly hold up in the face of Digital’s MicroVAX 78032 processor, introduced in 1985, implementing a subset of the VAX instruction set architecture which, in conjunction with software support, could provide full VAX software compatibility in the form of the MicroVAX II system. With Norsk Data facing financial hardship and the disintegration of the company, pursuing the further consolidation of the ND-5000 chipset was perhaps too costly a business. Furthermore, the ND-500 instruction set architecture was arguably unattractive and undeniably marginalised in the marketplace. Rare third-party support could be found in the proprietary compilers made by ACE Amsterdam Computer Experts, known for its associations with industry legend Andrew S. Tanenbaum, one of the originators of the Amsterdam Compiler Kit and principal developer of MINIX.
Plenty more promising RISC architectures, such as AMD’s Am29000, were discontinued as their creators prioritised other products, acknowledging that the industry would coalesce around the most popular and widely supported architectures. Thus, facing market realities, Norsk Data and its spin-off, Dolphin Server Technology, pivoted to Motorola’s 88000 architecture, only to find themselves backing the wrong horse in that particular race. Experiencing fabrication difficulties, Motorola itself dropped the 88000 architecture in favour of IBM’s POWER and the PowerPC initiative, leaving an array of supporters who were left to rework their strategies all over again.
A project known as ORION was the claimed motivation for establishing Dolphin as a separate company in the first place, but the sequence of events that led this project to its own cancellation, separate from the fate of Motorola’s own 88000 efforts and the architecture in general, remains unclear. ORION was reportedly a 88000-based superscalar processor with throughput claims of four instructions per cycle. It was presumably not a conventional “very long instruction word” design, since the superscalar characteristics of the design were said to be “invisible to the programmer and operating system” and applicable to other instruction set architectures.
Perhaps the designers sought to adopt techniques similar to, or beyond, those employed by IBM’s POWER architecture, noted for its superscalar characteristics and having somewhat stronger floating-point performance than its competitors. Indeed, the stronger performance of vector floating-point operations on early RS/6000 systems led to suggestions that headline benchmark scores were potentially misleading given the lack of prevalence of such operations in most kinds of software. In any case, ORION never proceeded beyond simulation to allow its own real-world performance to be assessed.
Meanwhile, one apparently successful research project that Norsk Data reportedly had the opportunity to commercialise was the CESAR systolic array processor, designed to process radar data and initially deployed with Norsk Data minicomputers as front-end systems. Perhaps due to timing, the company may have been insufficiently resourced to pursue such opportunities, having to focus on the fundamental aspects of the business. Later models of CESAR employed various workstations and other RISC-based front-end systems.
CESAR seems to have followed in the footsteps of the Goodyear Massively Parallel Processor (MPP), developed for satellite image analysis but also deployed for radar data processing. Work at Digital on an enhanced MPP that was then not pursued further by the company apparently led to the founding of MasPar Computer Corporation and the development of the MP-1 and MP-2 systems, coupled with VAXstation front-end workstations in a deal with Digital. Interestingly, one of the purchasers of the MP-1 was the University of Bergen. Digital would later rebadge MasPar systems in its own line-up.
Such talk of CESAR’s commercialisation in 1989 came rather late in the day. By 1990, the SIMD market was already vibrant, with one player, Active Memory Technology, having been selling and refining systems based on ICL’s Distributed Array Processor systems since 1986. ICL first demonstrated the DAP with 1024 processors in 1975 and apparently delivered the first DAP product in 1979.
As with CESAR, other traditional users of Norsk Data systems for scientific data analysis also switched to workstation-based alternatives in the early 1990s. The Cyclotron Laboratory at the University of Oslo began the process of retiring its ND-5800 system in favour of a Sun SPARCstation 10 in 1992. In other areas of Norwegian academia where Norsk Data machines might once have been considered for their high performance, even reluctantly, clusters of workstations had made their entrance. In one report, the authors went as far as to blame Norsk Data’s domestic dominance and Digital’s “growing influence” for policies that, until the mid-1980s, had excluded “real supercomputers” from Norwegian institutions.
An Accumulation of Consequences
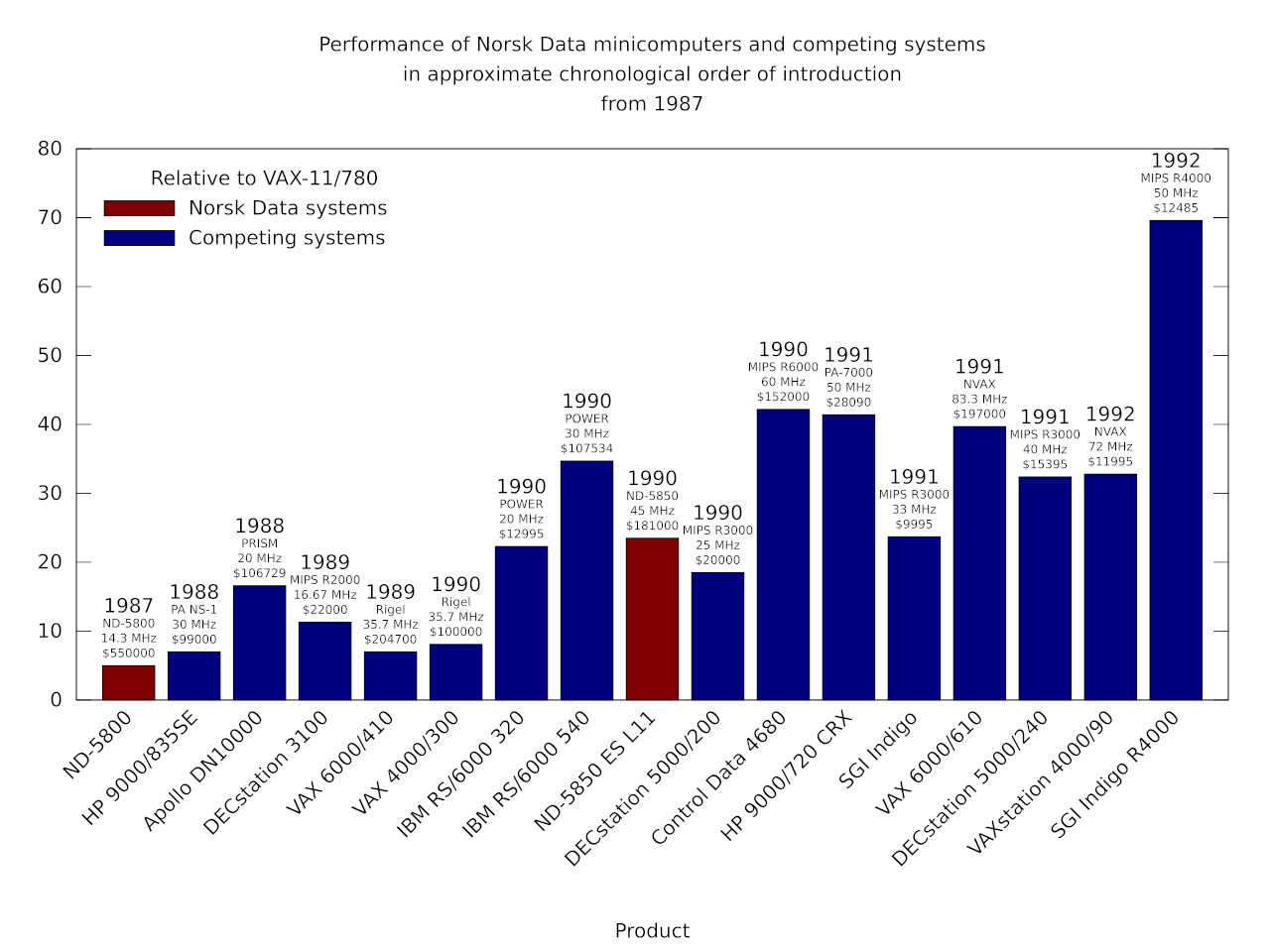
Although it had apparently been the intention to run Digital’s proprietary VMS operating system on its MIPS-based DECstation and DECserver families, Digital never followed through, and the company resumed its efforts to develop its own proprietary architecture to run both Unix and VMS, which had been an aim for its abandoned PRISM architecture (not to be confused with Apollo’s PRISM). The MIPS-based DECstations were seemingly well received, and the range was steadily upgraded as new MIPS processors became available, but Digital itself did not fully engage with the architecture.
Evidently, the focus shifted to the company’s own architecture in development, Alpha, and the DECstation line was discontinued, leaving customers with an inconvenient migration path that probably saw many of them simply switch to other vendors. By the time products based on Alpha were ready and running VMS, one might argue that the appetite for Digital’s proprietary operating system was waning. Alpha did lead the pack in performance for a while, but its reputation perhaps exaggerates that lead. Soon enough, HP’s PA-RISC, IBM’S POWER, along with MIPS and SPARC processors were challenging that lead.
Digital’s well-understood limitations and self-inflicted difficulties seem relatively minor compared to those of Norsk Data as the latter company’s growth stalled, profits turned to losses, and customers voted with their feet in favour of interoperability and widely used technologies. Digital’s restructuring, involving redundancy plans and job losses, was very costly for the company and its effects very possibly contributed to the general weakened position of the company, leading to its eventual acquisition by Compaq, but it was not an immediate existential crisis. For Norsk Data, having grown so fast to accommodate potential sales that never arrived, hiring employees and building fancy new offices and facilities, the need to restructure and reduce spending more or less broke the company altogether.
The promising ND-5000 range, notionally competitive with similar products on the market, was supposedly still being developed by the spin-off development operation, Dolphin, alongside the new 88000-based product line-up. But within the division of Norsk Data responsible for procuring new systems, ND ServiceTeam, the ND-5000 range was described as a “milk-cow” product, the term being an amusing direct translation from Norwegian, “melkeku“, instead of the more familiar “cash cow“. Without a long-term commitment from those selling systems to deliver competitive ND-5000 products, and thus a long-term product strategy to drive further development of the architecture, it would have been difficult to justify continued investment in it, particularly as Norsk Data’s competitors were managing to achieve the kind of high sales volumes that could justify larger scale integration.
Thus, the ND-5000 range was positioned in the kind of server role that it had always largely occupied, but now having to coexist with workstations and personal computers rather than terminals, its supposed high performance lending itself to file and database serving duties. Oracle was apparently persuaded to release its products for the ND-5000 systems, as Norsk Data tried to push them into the “transaction processing” market. For such systems to thrive in such a role, however, they would have needed to fit in with the technological choices of their customers, running a convincing form of Unix and not sneaking Norsk Data’s proprietary SINTRAN operating system in through the back door.
Mixing Unix servers and workstations from different vendors would have been justifiable. Relying on, say, a Network File System implementation running on some traditional operating system with “open systems” credentials, like DEC’s OpenVMS or ICL’s VME, might have suited some customers. But it remains doubtful that many customers would have sought out Norsk Data’s products to do such duties for their collection of Unix workstations sourced elsewhere. Norsk Data systems quickly became legacy technology and a liability for those customers still operating them.
Interestingly, Dolphin announced an agreement with NeXT to offer NeXT’s workstations alongside its own 88000-based servers running Unix. NeXT was expected to adopt the 88000 as the basis of its next generation RISC-based workstation, but the discontinuation of the 88000 largely turned that company into a software-only operation. Here, the threads of history cross once more. The NeXTcube is known as the machine on which Tim Berners-Lee developed the first software for the World Wide Web. His earlier information management concept, ENQUIRE, had been developed on a Norsk Data Nord-10 system.
The rapid descent from the Norsk Data’s days of impending glory came as a shock to its decision-makers and strategists. Having spent most of the 1980s resolutely ignoring or dismissing open systems trends, personal computing and Unix, in 1989 the company attempted to pivot to embracing all of those things, its representatives finding themselves having to roll back all of the negative rhetoric that they once used against the very essence of their new strategy. A company that had been dismissive about standards and interoperability now sought to appoint itself as the guardian of those very same things.
Despite showing the enthusiasm of the newly converted, certain elements of the rhetoric suggest a level of sincerity not unlike an oil company conceding the existence of climate change but positioning itself as instrumental to any “transition” away from fossil fuels, unable to refrain from the occasional jibe against those things that have forced it into its humbled position. For Norsk Data, this meant insisting that customers were not really asking for Unix as such, that the operating system was irrelevant, which might only be true for operating systems of comparable capabilities and with true interoperability, that SINTRAN was somehow still better, anyway, and that customers really wanted proprietary systems. Such sentiments would have made the broader message unconvincing to anyone evaluating the company as an information systems provider.
Commentaries about Norsk Data tend to emphasise the fairytale aspects, along with the predictable “little Norway” tropes and the tedious journalistic style familiar from long-established, self-satisfied newspapers and periodicals. Per Øyvind Heradstveit’s book “Norsk Data – a success story” was published in 1985 and paints a typical heroic picture, including the usual, tiresome, and inappropriate cultural references to “vikings” that, like the original Vikings, do not travel and translate well to other countries and cultures. Written at a point in time to celebrate the progress of the company, Heradstveit had to end the tale before it all went wrong.
Personal reflections from leadership figures may recognise the company’s shortcomings, but they also make virtues out of dubious corporate behaviour. Such behaviour may have involved standard industry practices, but are nevertheless practices that those of us in the Free Software movement justifiably reject. The use of the company’s NOTIS office software product as a vehicle to indoctrinate users in large organisations, particularly public sector institutions, training them up for that specific product and making it costly to adopt other systems and applications, might be familiar to anyone observing the method of operation of Microsoft and the promotion of its Office suite and online products amongst institutional users.
Protesting that nobody could foresee the industry’s transition to open standards and to technologies like Unix, and that nobody really knew what would become a standard, a glimpse into the mindset is revealed by accompanying observations that any serious effort to adopt standards would have risked undermining the bumper profits in Norsk Data’s best years in 1985, 1986 and part of 1987. When the going appears to be good, why bother changing anything? Such an outlook tends also to be shared by certain flavours of politician, leaving society vulnerable to adversity. Of course, the leadership chose not to see the mounting evidence in the form of customer requests and then requirements for various technologies. It certainly did not help to believe that SINTRAN is a better operating system than Unix when one’s own customers do not even believe it.
Wondering what might have been done differently, one sees that the imagination of the company’s leadership was clearly limited when considering other possibilities of doing business, at least where the outcome might involve sharing the opportunities in a market with other participants. And enviously looking at other industries and other markets, the notion of patenting technologies evidently arose, with the hope that this would tilt the playing field and make the technology business obscenely lucrative once again. Of course, we all know how destructive patents can be, granting unethical and arbitrary monopolies, so that “inventors” can claim areas of endeavour as their own, eliminate competition, and stifle the innovation that the patent lobby claims to encourage.
Although the narratives of Norsk Data’s leadership and associated commentators may leave us without reasonable explanations for various aspects of the company’s strategy and the attitudes of certain key figures, a newsgroup discussion from several years ago provides a gold mine of insight from one of the veterans of Norwegian academic computing, Gisle Hannemyr. Recounting various interactions with the company over the course of a decade or thereabouts, he noted that while collaboration with academia and research institutions had led to the company’s initial success, the corporate culture had gradually started to exclude academia and emphasise the company’s own role in that earlier success at the expense of its collaborators.
At the start of the 1980s, academics in computing had become alerted to developments in networked, graphical, personal workstations. Niklaus Wirth had famously wanted to acquire a Xerox Alto workstation after a sabbatical at Xerox PARC, but unable to do so, he developed his own Lilith workstation. Other academics spent time in environments being exposed to workstation computing and returned convinced of its benefits. Seeking to persuade Norsk Data of the importance of this trend as early as 1982, Hannemyr’s arguments were dismissed by Norsk Data’s leadership who regarded a NOTIS terminal as the same kind of product as these workstations. Even in 1984, as Sun Microsystems delivered workstations to the market, Norsk Data’s leadership persisted with their belief that a character terminal connected to a minicomputer was the equivalent of such a workstation. (Oddly, in archived photographs from Norsk Data, it seems that at least someone in the company was at least using an Apple Lisa.)
Relations between academia and Norsk Data evidently soured significantly when the academics, various programming language and paradigm pioneers amongst them, sought to acquire Lisp machines and secured a potential collaboration with one of the most significant producers of such machines, Symbolics. Such a collaboration allegedly displeased Norsk Data’s management to the extent that lobbying was employed in the sphere of governmental politics to prevent it from going ahead, and the researchers were instead obliged to take delivery of the ultimately unsuccessful KPS-10 system from Norsk Data, the one whose delivery had been forgotten by one of the company’s chroniclers but whose backplane had caught fire in a university computer room.
Consequently, efforts to establish a Lisp community in Norway had been undermined by the redirection of public funds to serve the interests of a single company. Such self-serving practices were perceived as being entirely routine and part of Norsk Data’s methods to remain entrenched in the public sector, and this merely diminished the reputation of the company in academia still further. Indeed, beyond very specific applications, Norsk Data’s products seem to have been rejected in certain Norwegian academic institutions. Naturally, Norsk Data failed to learn anything from this collapse in the relationship, choosing not to cater to the demands of the academics, whose business would go, along with plenty of revenue, to the workstation vendors and their Norwegian distributors.
Hannemyr recalled that in 1990, with the company humbled by market conditions, an attempt was made to reconcile with academia with a presentation of the company’s plans for the 88000, ostensibly ORION, which he describes as a liquid-cooled, ECL-based variant of the 88000 and labels using a term that might only be adequately translated as “nonsense”. The mood for reconciliation descended into recriminations when the academics restated their interest in graphical workstations, seeing little value for their own work in what they were being shown.
Such perspectives perhaps illuminate a persistent deficiency in the company’s strategy, although it still seems bizarre that with a chorus of critics highlighting a phenomenon that the company could no longer sensibly ignore or deny, the company doggedly continued its denial of what workstations had become. When introducing its range of 88000-based models, all but one of them were Norsk Data or Dolphin designs. The exception was the workstation: a rebadged Data General model. And as the ORION project was pitched in the industry as part of the spun-off Dolphin subsidiary, it was the head of workstations writing the pitch for the ORION-based “super-server” product.
The Legacy
Treatments of Norsk Data’s history often focus on the company’s beginnings and its successes, glossing over the company’s demise because a definitive ending is hard to pick out amidst the mess of its disintegration. At first, in efforts to restructure the business, bits of the company were sold off or spun out. Siemens Nixdorf picked up a division to strengthen its hand in the Norwegian public sector, with Nixdorf once having been a possible merger or acquisition target for Norsk Data itself. Intergraph picked up the Technovision CAD/CAM operation, perhaps as a way of acquiring and further developing its customer base. Dolphin Server Technology, spun out as a hardware company to develop products for Norsk Data and others, almost closed altogether but was picked up by a company owned by the Norwegian state telecoms operator soon to be known as Telenor.
Eventually, the rump of the business, having taken another name, followed Dolphin into Telenor’s hands, but not before dissatisfied former investors attempted to contest the acquisition and formulate a rival bid. It appears that Dolphin was largely run down by Telenor, but not before it was able to spin out another company, Dolphin Interconnect Solutions, that was making progress in developing Scalable Coherent Interface chipsets for shared memory multiprocessor machines. Another company in a similar vein, Numascale, also claims roots back to Norsk Data via Dolphin. Both these companies are still around today having thankfully escaped the bloated telecoms incumbent where new operations appear to come and go, like mere playthings of its executives and decadent, indulged management.
Similar remarks could be made about other companies when it comes to a lack of obvious finality. Smoke and mirrors around the closing months at Acorn Computers involved a renaming of the company followed by the sale of certain newly incubated activities to another company that would also acquire Acorn’s new name. That may have led some to believe that Acorn kept going, only to be acquired by one of the more notorious technology giants of today. In fact, the principal assets associated with Acorn were either sold off to interested parties or otherwise managed by holding companies until they were no longer lucrative or useful to the bank that did actually acquire Acorn. Of course, ARM is often touted as Acorn’s main legacy.
Interestingly, there is a slight crossover between Acorn’s later history and Norsk Data in the form of one of its founders. Lars Monrad-Krohn had been there at Norsk Data from the very beginning before pursuing enterprises more in the realm of microcomputing, establishing Mycron in the mid-1970s and delivering machines that mostly ran CP/M or MP/M. He then co-founded Tiki Data to produce an educational microcomputer, along the same lines as the BBC Micro, launching the Tiki-100 and various successors that struggled to compete against the increasingly ubiquitous IBM PC and compatibles. After that adventure, he turned to network computing and apparently secured distribution rights to Acorn’s NetStation in Norway, operating Norske Network Computing (NCNOR) as the vehicle for aspirations in this promising but ultimately unsuccessful offshoot of personal computing.
It might be said that microelectronics has been fertile ground for various Norwegian companies over the years. Nordic Semiconductor emerged from the academic environment in Trondheim, as did Falanx Microsystems which was acquired by ARM to give the chipmaker access to graphics acceleration technologies. Meanwhile, Chipcon and Energy Micro were founded in Oslo with various individuals being involved in both companies, both since sold to larger competitors and now all apparently consolidated within Texas Instruments. So, it is perhaps not surprising that those companies that do claim heritage from Norsk Data happen to operate in this part of the industry.
Of course, Norsk Data made more than processors and associated hardware technology. It was a complete systems manufacturer, developing the physical system units themselves along with the software that ran on them. An entire ecosystem from the microcode of the processors, up through the boot firmware and operating system, and beyond into the realm of compilers, tools and applications, had to be developed to deliver a product that customers could use. Evidently, much effort was applied, and much talent must have resided in the company, to put together a portfolio that included some sophisticated products. And regardless of one’s opinion of those products, the company must also have been a useful venue for those educated in computer science and engineering, along with other disciplines, to pursue their careers.
Indeed, one might say that Norsk Data, along with other companies and institutions of that time, was a channel for a kind of aspiration or ambition that might seem mundane to some today, but which had a seriousness that many of today’s technology “innovators” can only dream of projecting. The 1990s and 2000s did see notable software companies emerge from the technological scene in Norway, but following the “innovation” bandwagon now, much of it seems to revolve around hype, fuelled by an inbred culture promoting “innovation” in its own right (as opposed to supporting anyone making anything new), surveyed by commercial property vultures wanting a steady stream of clients for their office and co-working spaces.
There is “fintech” (financial technology, nothing to do with Norway’s unsustainable, ecologically harmful aquaculture industry), “proptech” (monetising property assets, because as in many other countries, wealth creation has become stuck on property investments and “passive income” rather than building productive industry), “medtech” (medical technology, often involving therapies, treatments or processes that promise a big payout if everything lines up just right), “edtech” (educational technology, often being more about shiny toys to distract children, burdensome systems to impose on educators, and probably a strong dose of data mining for questionable commercial exploitation), along with the ubiquitous, tiresome and ethically compromised “crypto” and “AI”.
In “developed” societies like Norway, and especially one that is not really short of money, one might imagine that ambitious, even noble, goals might be targeted by those looking to invest in technological endeavours. For a time, it would seem that plenty of opportunities were available for those looking to put their education to good use, trying to achieve and to build something meaningful and useful to wider society. Today, it seems that a lot of commerce is just chasing the latest fad or enabling dubious and even ruinous forms of economic activity. Governments pander to big technology corporations and promise to build power stations to effectively subsidise data centres that will inevitably churn out “slop” to further undermine society and democracy.
Search for Norsk Data now and you may stumble across a corporate entity with the name claiming expertise in data centres, “land and property management”, and “green power and energy solutions”, coining it from the demand for rackspace. Maybe it really is aiming for sustainable computing infrastructure, mentions of blockchain notwithstanding. Amongst its “innovations”, “drying of biofuel” sounds rather familiar from an article I read a while back, involving a cryptocurrency “mining” company that touted the very same thing, as if needlessly consuming colossal amounts of power is somehow excused by “a local lumberjack” getting some logs dried out. With such feeble greenwashing making the headline, leaning into the usual uncritical praise of all things Scandinavian, I think The Guardian’s editorial staff should be ashamed of themselves for having published such garbage.
The practical consequences to society of its leaders lack of vision, or even lack of effort, can be severe. Young people may not see an education as worthwhile if there are no viable opportunities to use that education. Others may see their own livelihoods undermined as investment is directed towards fads or the “guaranteed returns” associated with lazy asset-based speculation, whether that involves property or the latest fraudcoin. Meanwhile, decision-makers plead poverty when structural investments are required in society, claiming that the money isn’t there as they slash taxes for the wealthy (who constantly harp on about leaving the country, such patriots that they are), incentivise even more money pouring into property speculation, and then announce costly vanity projects in the hope that a big bridge, tunnel, property development, or a locally hosted Olympic games will be their legacy.
We have been here before, of course. When microelectronics started to transform industries, governments and other institutions made sincere attempts to determine the consequences, recommend measures, and undertake initiatives. Soon enough, rapid growth in the range of available commercial products led politicians to defer to the market, abandon many initiatives, and let the market dictate the direction technological adoption might take. Some might claim that Norsk Data was a victim of political abandonment and that the company should have been bailed out. One might more credibly claim that its management failed to respect the need that its customers had for interoperability and open standards, particularly in the public sector, and that its talent could have been more productively employed in other businesses instead.
But regardless of the fate of one company, it seems that we are currently experiencing yet another opportunity to be reminded that society, particularly through the government it elects, needs to create and sustain opportunities and industries to give individuals something useful and rewarding to do with their lives. It needs to cultivate viable enterprises that develop and maintain indigenous technology and expertise, to provide a form of technological sovereignty.
And through the cultivation of decently paid, meaningful work, society as a whole becomes wealthier, more resilient, and gives everyone a stake in the whole project, not just a few employees at an anointed company constantly watching the share price and contemplating the prospect of becoming rich. The project, of course, is to deliver a safe, stable and secure place to live and pursue one’s life, with the realisation that we all become poorer if people – particularly those who are wealthy through luck or privilege – are allowed to cash out and degrade the quality of society once they feel they no longer have a need for it. Ultimately, a strong society with meaningful opportunities and a pervasive, irrepressible sense of purpose should be every generation’s legacy.