Paul Boddie's Free Software-related blog
Paul's activities and perspectives around Free Software
Porting L4Re and Fiasco.OC to the Ben NanoNote (Part 9)
March 29th, 2018
After all my effort modifying the Fiasco.OC kernel, adapting driver code for the Ben NanoNote to work in the L4 Runtime Environment (L4Re), I had managed to demonstrate programs that could access the framebuffer and thus show things on the screen. But my stated goal is to demonstrate the functioning of existing code and a range of different components, specifically the “spectrum” example, GUI multiplexer (Mag), and framebuffer driver (fb-drv), supported by additional driver functionality I have added myself.
Still to do were the tasks of getting the framebuffer driver to access my LCD driver, getting Mag to work on top of that, and then getting the “spectrum” example to work as it had done with Fiasco.OC-UX. Looking back at this exercise now, I can see that it is largely a case of wiring up the components just as we saw earlier when I showed how to get access to the hardware through the Io server. But this didn’t prevent excursions into the code for some debugging operations or a few, more lasting, modifications.
Making a Splash
I had sought to test the entire stack consisting of the example, GUI multiplexer, framebuffer driver, and the rest of the software using a configuration derived from both the UX “spectrum” demonstration (found in l4/conf/examples/x86-fb.cfg) and the corresponding demonstration for ARM-based devices (found in l4/conf/examples/arm-rv-lcd.cfg). Unsurprisingly, this did not work, and so I started out stripping down my own example configuration in order to test the components individually.
On the way, I learned a few things that I wished I’d realised earlier. The first one is pretty mundane but very important. In order to strip down the configuration, I had tried to comment out various components and had done so using the hash symbol (#), which vim had helped to make me believe was a valid comment symbol. In fact, in Lua, if the hash symbol can be used for “program metadata”, perhaps for the usual Unix scripting declaration, then its use may be restricted to such narrow purposes and no others (as far as I could tell from quickly looking through the documentation). Broader use of the symbol appears to involve it acting as the length operator.
By making an assumption almost instinctively, due to the prevalence of the hash character as a comment symbol in Unix scripting, I was now being confronted with “Starting kernel …” and nothing more, making me think that I had really broken something. I had to take several steps back, consider what might really be happening, that the Ned task responsible for executing the configuration had somehow failed, and then come to the realisation that were I able to read the serial console output, I would be staring at a Lua syntax error!
So, removing the configuration details that I didn’t want to test straight away, I set about testing the framebuffer driver all by itself. Here is the configuration file involved (edited slightly):
local io_buses =
{
fbdrv = l:new_channel();
};
l:start({
caps = {
fbdrv = io_buses.fbdrv:svr(),
icu = L4.Env.icu,
sigma0 = L4.cast(L4.Proto.Factory, L4.Env.sigma0):create(L4.Proto.Sigma0),
},
},
"rom/io -vvvv rom/hw_devices.io rom/mips-qi_lb60-fbdrv.io");
local fbdrv_fb = l:new_channel();
l:startv({
caps = {
vbus = io_buses.fbdrv,
fb = fbdrv_fb:svr(),
},
},
"rom/fb-drv", "-c", "nanonote"); -- configuration passed to the LCD driver
It was around this time that I discovered the importance of the naming of certain things, noted previously, and so in the accompanying Io configuration, the devices are added to a vbus called “fbdrv”. What this example should do is to run just the framebuffer driver (fb-drv) and the Io server.
Now, you might be wondering what the point of running just the driver, without any client programs, might be. Well, I had noticed that the driver should show a “splash screen”, and so I eagerly anticipated seeing whatever the L4Re developers had decided to show to us upon the driver starting up. Unfortunately, all I got was a blank screen. That made me think some bad things about what might be happening in the code. Fortunately, it didn’t take me long to realise what the problem was, discovering the following (in l4/pkg/fb-drv/server/src/splash.cc):
if (fb_info->width < SPLASHNAME.width) return; if (fb_info->height < SPLASHNAME.height) return;
Meanwhile, in the source file providing the screen data (l4/pkg/fb-drv/server/data/splash1.c), I saw that the width and height of the image were given as being 480 pixels and 65 pixels respectively. The Ben’s screen is 320 pixels wide and 240 pixels high, thus preventing the supplied image from being shown.
It seemed worthwhile trying to replace this image just to reassure myself that the driver was actually working. The supplied image was exported from GIMP and so I attempted to reproduce this by loading one of my own images into GIMP, cropping to 320×240, and saving as a C source file with run-length encoding, 3 bytes per pixel, just as the supplied image had been created. I then copied it into the appropriate package subdirectory (l4/pkg/fb-drv/server/data) and modified the Makefile (l4/pkg/fb-drv/server/src/Makefile), changing it to reference my image instead of the supplied one.
I also needed to change a few other things in the Makefile, as it turned out, such as the definitions of the sources and libraries used by MIPS architecture devices. It was odd to encounter architecture-specific artefacts at this level in the system, but I suppose that different architectures tend to employ different kinds of display mechanisms: the x86 architecture and derivatives have their “legacy” devices; other architectures used in system-on-a-chip products have other peripherals and devices. Anyway, building the payload and booting the Ben gave me this:

The Ben NanoNote showing my L4Re framebuffer driver splash screen: rainbow lorikeets on a suburban lawn
So, the framebuffer driver will happily run, showing its splash screen until something connects to it and gets something else onto the screen. Here, we just let it run by itself until it is time to switch off!
Missing Inputs
There was still one component to be tested before arriving at the “spectrum” example: the GUI multiplexer, Mag. But testing it alone did not necessarily seem to make sense, because unlike the framebuffer driver, Mag’s role is merely to arbitrate between different framebuffer clients. So testing it and some kind of example together seemed like the only workable strategy.
I tried to test it with the “spectrum” example, but I only ever saw the framebuffer splash screen, so it seemed that either the example or Mag wasn’t working. But if it were Mag that wasn’t working, how would I be able to find my way to the problem? I briefly considered whether Mag had a problem with the display configuration, given that I had already seen such a problem, albeit a minor one, in the framebuffer driver.
I chased references around the source code until I established that Mag was populating a fixed-length array of “factory” objects defined in one place (l4/pkg/mag-gfx/include/factory) whose members were statically defined in another place (l4/pkg/mag/server/src/screen.cc), each one indicating how to deal with a particular pixel format. Such objects being of type Mag_gfx::Mem::Factory are returned in the Mag main program (in pkg/mag/server/src/main.cc) when the following code is executed:
Screen_factory *f = dynamic_cast<Screen_factory*>(Screen_factory::set.find(view_i.pixel_info));
I had wondered whether f was being presented with a null value and thus stopping Mag right there, but since there was a suitable factory object being created for the Ben’s pixel format, it seemed rather unlikely. So, the only approach I had considered at this point was not a particularly convenient one: I would have to replicate Mag piece by piece until discovering which part of it caused it to fail.
I set out with a simple example borrowing code from Mag that requests a memory region via a capability or channel, displaying some data on the screen. This managed to work. I then expanded the example, adding various data structures, copying functionality into the example directory from Mag, slowly reassembling what Mag had been all along. Things kept working, right until the point where I needed to set the example going as a server rather than have it wait in an infinite loop doing nothing. Then, the screen would very briefly show the splash image, then the bit patterns, and then go blank.
But maybe Mag was going to clear the framebuffer anyway and thus the server loop was working? Perhaps this was what success actually looked like under these circumstances, which is to say that it did not involve seeing two brightly-coloured birds on a lawn. At this point, out of laziness, I had avoided integrating the plugins into my example, and that was the only remaining difference between it and Mag.
I started to realise that maybe it was a matter of removing things from Mag and seeing if I could get it to work, and the obvious candidates for removal were the plugins. So I removed all the plugins as defined in the Makefile (found at pkg/mag/server/src/Makefile) and tested to see if it changed Mag’s behaviour. Sure enough, the screen went blank. I then added plugins back one by one, knowing by now that the mag-client_fb plugin was going to be required to get the example working.
Well, it turned out that there was one plugin causing all the problems: mag-input-libinput. Removing that got the “spectrum” example to work:

The Ben NanoNote showing the "spectrum" framebuffer example
Given that I haven’t addressed the matter of supporting input devices, which for the Ben would mostly concern the keyboard, disabling this errant plugin seemed like a reasonable compromise for now.
Update: a description of a remedy for the problem with the plugin is described in the summary article.
A Door Opens?
There isn’t much left to be said, which perhaps makes the ending something of an anticlimax. But perhaps this is part of the point of the exercise, that the L4Re/Fiasco.OC combination now just seems to work on the Ben NanoNote, and that it could potentially in future be just another thing that this software supports. Of course, the Ben is such a relatively rare device that it isn’t likely to have many potential users, but the SoC family of which the JZ4720 is a part is employed by a number of different devices.
If there haven’t been any privately-maintained ports of this software to those other devices, then this work potentially opens the door to its use on other handheld devices like the GCW Zero or any number of randomly-sourced pocket games consoles, portable media players, and even smartwatches and wearable devices, all of which have been vehicles for the SoC vendor’s products. The Letux 400 could probably be supported given the similarity of its own SoC, the JZ4730, to that used in the Ben.
When the Ben was released, work had been done, first by the SoC vendor, then by the Qi Hardware people, to provide a functioning GNU/Linux system for the device. Clearly, there isn’t an overwhelming need for another kind of system if the intention is to just use the device with existing Free Software. But perhaps this is another component in this exercise: to make other technological solutions possible and to explore avenues that get ignored as everyone follows the mainstream. The Ben is hardly a mainstream product itself; why not use it to make other alternative choices?
It seems interesting to consider writing other drivers for the Ben and to gain experience with microkernel-based systems design. The Genode framework might also be worth investigating, given its focus on becoming a system suitable for deployment to end-users. The Hurd was also ported in an exploratory fashion to one of the L4 implementations some time ago, and revisiting this might be possible, even simplifying the effort thanks to the evolution in features provided by implementations like Fiasco.OC.
In any case, I hope that this account has been vaguely interesting and entertaining. If you managed to read it all, you deserve my sincere thanks for spending the time to do so. A summary of the work will probably follow, and the patches themselves are available on a page dedicated to the effort. Good luck with your own investigations into alternative Free Software operating systems!
Porting L4Re and Fiasco.OC to the Ben NanoNote (Part 8)
March 27th, 2018
With some confidence that the effort put in previously had resulted in a working Fiasco.OC kernel, I now found myself where I had expected to be at the start of this adventure: in the position of trying to get an example program working that could take advantage of the framebuffer on the Ben NanoNote. In fact, there is already an example program called “spectrum” that I had managed to get working with the UX variant of Fiasco.OC (this being a kind of “User Mode Fiasco” which runs as a normal process, or maybe a few processes, on top of a normal GNU/Linux system).
However, if this exercise had taught me nothing else, it had taught me not to try out huge chunks of untested functionality and then expect everything to work. It would instead be a far better idea to incrementally add small chunks of functionality whose correctness (or incorrectness) would be easier to see. Thus, I decided to start with a minimal example, adding pieces of tested functionality from my CI20 experiments that obtain access to various memory regions. In the first instance, I wanted to see if I could exercise control over the LCD panel via the general-purpose input/output (GPIO) memory region.
Wiring Up
At this point, I should make a brief detour into the matter of making peripherals available to programs. Unlike the debugging code employed previously, it isn’t possible to just access some interesting part of memory by taking an address and reading from it or writing to it. Not only are user space programs working with virtual memory, whose addresses need not correspond to the actual physical locations employed by the underlying hardware, but as a matter of protecting the system against program misbehaviour, access to memory regions is strictly controlled.
In L4Re, a component called Io is responsible for granting access to predefined memory regions that describe hardware peripherals or devices. My example needed to have the following resources defined:
- A configuration description (placed in l4/conf/examples/mips-qi_lb60-lcd.cfg)
- The Io peripheral bus description (placed in l4/conf/examples/mips-qi_lb60-lcd.io)
- A list of modules needing deployment (added as an entry to l4/conf/modules.list, described separately in l4/conf/examples/mips-qi_lb60-lcd.list)
It is perhaps clearer to start with the Io-related resource, which is short enough to reproduce here:
local hw = Io.system_bus()
local bus = Io.Vi.System_bus
{
CPM = wrap(hw:match("jz4740-cpm"));
GPIO = wrap(hw:match("jz4740-gpio"));
LCD = wrap(hw:match("jz4740-lcd"));
}
Io.add_vbus("devices", bus)
This is Lua source code, with Lua having been adopted as a scripting language in L4Re. Here, the important things are those appearing within the hw:match function call brackets: each of these values refers to a device defined in the Ben’s hardware description (found in l4/pkg/io/io/config/plat-qi_lb60/hw_devices.io), identified using the “hid” property. The “jz4740-gpio” value is used to locate the GPIO device or peripheral, for instance.
Also important is the name used for the bus, “devices”, in the add_vbus function call at the bottom, as we shall see in a moment. Moving on from this, the configuration description for the example itself contains the following slightly-edited details:
local io_buses =
{
devices = l:new_channel();
};
l:start({
caps = {
devices = io_buses.devices:svr(),
icu = L4.Env.icu,
sigma0 = L4.cast(L4.Proto.Factory, L4.Env.sigma0):create(L4.Proto.Sigma0),
},
},
"rom/io -vvvv rom/hw_devices.io rom/mips-qi_lb60-lcd.io");
l:start({
caps = {
icu = L4.Env.icu,
vbus = io_buses.devices,
},
},
"rom/ex_qi_lb60_lcd");
Here, the “devices” name seemingly needs to be consistent with the name used in the caps mapping for the Io server, set up in the first l:start invocation. The name used for the io_buses mapping can be something else, but then the references to io_buses.devices must obviously be changed to follow suit. I am sure you get the idea.
The consequence of this wiring up is that the example program, set up at the end, accesses peripherals using the vbus capability or channel, communicating with Io and requesting access to devices, whose memory regions are described in the Ben’s hardware description. Io acts as the server on this channel whereas the example program acts as the client.
Is This Thing On?
There were a few good reasons for trying GPIO access first. The most significant one is related to the framebuffer. As you may recall, as the kernel finished starting up, sigma0 started, and we could then no longer be sure that the framebuffer configuration initialised by the bootloader had been preserved. So, I could no longer rely on any shortcuts in getting information onto the screen.
Another reason for trying GPIO operations was that I had written code for the CI20 that accessed input and output pins, and I had some confidence in the GPIO driver code that I had included in the L4Re package hierarchy actually working as intended. Indeed, when working with the CI20, I had implemented some driver code for both the GPIO and CPM (clock/power management) functionality as provided by the CI20’s SoC, the JZ4780. As part of my preparation for this effort, I had adapted this code for the Ben’s SoC, the JZ4720. It was arguably worthwhile to give this code some exercise.
One drawback with using general-purpose input/output, however, is that the Ben doesn’t really have any conveniently-accessed output pins or indicators, whereas the CI20 is a development board with lots of connectors and some LEDs that can be used to give simple feedback on what a program might be doing. Manipulating the LCD panel, in contrast, offers a very awkward way of communicating program status.
Experiments proved somewhat successful, however. Obtaining access to device memory was as straightforward as it had been in my CI20 examples, providing me with a virtual address corresponding to the GPIO memory region. Inserting some driver code employing GPIO operations directly into the principal source file for the example, in order to keep things particularly simple and avoid linking problems, I was able to tell the panel to switch itself off. This involves bit-banging SPI commands using a number of output pins. The consequence of doing this is that the screen fades to white.
I gradually gained confidence and decided to reserve memory for the framebuffer and descriptors. Instead of attempting to use the LCD driver code that I had prepared, I attempted to set up the descriptors manually by writing values to the structure that I knew would be compatible with the state of the peripheral as it had been configured previously. But once again, I found myself making no progress. No image would appear on screen, and I started to wonder whether I needed to do more work to reinitialise the framebuffer or maybe even the panel itself.
But the screen was at least switched on, indicating that the Ben had not completely hung and might still be doing something. One odd thing was that the screen would often turn a certain colour. Indeed, it was turning purple fairly consistently when I realised my mistake: my program was terminating! And this was, of course, as intended. The program would start, access memory, set up the framebuffer, fill it with a pattern, and then finish. I suspected something was happening and when I started to think about it, I had noticed a transient bit pattern before the screen went blank, but I suppose I had put this down to some kind of ghosting or memory effect, at least instinctively.
When a program terminates, it is most likely that the memory it used gets erased so as to prevent other programs from inheriting data that they should not see. And naturally, this will result in the framebuffer being cleared, maybe even the descriptors getting trashed again. So the trivial solution to my problem was to just stop my program from terminating:
while (1);
That did the trick!
The Build-Up
Accessing the LCD peripheral directly from my example is all very well, but I had always intended to provide a display driver for the Ben within L4Re. Attempting to compile the driver as part of the general build process had already identified some errors that had been present in what effectively had been untested code, migrated from my earlier work and modified for the L4Re APIs. But I wasn’t about to try and get the driver to work in one go!
Instead, I copied more functionality into my example program, giving things like the clock management functionality some exercise, using my newly-enabled framebuffer output to test the results from various enquiries about clock frequencies, also setting various frequencies and seeing if this stopped the program from working. This did lead me on another needlessly-distracting diversion, however. When looking at the clock configuration values, something seemed wrong: they were shifted one bit to the left and therefore provided values twice as large as they should have been.
I emitted some other values and saw that they too were shifted to the left. For a while, I wondered whether the panel configuration was wrong and started adjusting all sorts of timing-related values (front and back porches, sync pulses, video-related things), reading up about how the panel was configured using the SPI communications described above. It occurred to me that I should investigate how the display output was shifted or wrapped, and I used the value 0x80000001 to put bit values at the extreme left and right of the screen. Something was causing the output to be wrapped, apparently displaced by 9 pixels or 36 bytes to the left.
You can probably guess where this is heading! The panel configuration had not changed and there was no reason to believe that it was wrong. Similarly, the framebuffer was being set up correctly and was not somehow moved slightly in memory, not that there is really any mechanism in L4Re or the hardware that would cause such a bizarre displacement. I looked again at my debugging code and saw my mistake; in concise terms, it took this form:
for (i = 0; i < fb_size / 4; i++)
{
fb[i] = value & mask ? onpix : offpix; // write a pixel
if ((i % 10) == 0) // move to the next bit?
...
}
For some reason, I had taken some perfectly acceptable code and changed one aspect of it. Here is what it had looked like on the many occasions I had used it in the past:
i = 0;
while (i < fb_size / 4)
{
fb[i] = value & mask ? onpix : offpix; // write a pixel
i++;
if ((i % 10) == 0) // move to the next bit?
...
}
That’s right: I had accidentally reordered the increment and “next bit” tests, causing the first bit in the value to occupy only one pixel, prematurely skipping to the next bit; at the end of the value, the mask would wrap around and show the remaining nine pixels of the first bit. Again, I was debugging the debugging and wasting my own time!
But despite such distractions, over time, it became interesting to copy the complete source file that does most of the work configuring the hardware from my driver into the example directory and to use its functions directly, these functions normally being accessed by more general driver code. In effect, I was replicating the driver within an environment that was being incrementally enhanced, up until the point where I might assume that the driver itself could work.
With no obvious problems having occurred, I then created another example without all the memory lookup operations, copied-in functions, and other “instrumentation”: one that merely called the driver API, relying on the general mechanisms to find and activate the hardware…
struct arm_lcd_ops *ops = arm_lcd_probe("nanonote");
…obtaining a framebuffer address and size…
fb_vaddr = ops->get_fb(); fb_size = ops->get_video_mem_size();
…and then writing data to the screen just as I had done before. Indeed, this worked just like the previous example, indicating that I had managed to implement the driver’s side of the mechanisms correctly. I had a working LCD driver!
Adopting Abstractions
If the final objective had been to just get Fiasco.OC running and to have a program accessing the framebuffer, then this would probably be the end of this adventure. But, in fact, my aim is to demonstrate that the Ben NanoNote can take advantage of the various advertised capabilities of L4Re and Fiasco.OC. This means supporting facilities like the framebuffer driver, GUI multiplexer, and potentially other things. And such facilities are precisely those demonstrated by the “spectrum” example which I had promised myself (and my readership) that I would get working.
At this point, I shouldn’t need to write any more of my own code: the framebuffer driver, GUI multiplexer, and “spectrum” example are all existing pieces of L4Re code. But what I did need to figure out was whether my recipe for wiring these things up was still correct and functional, and whether my porting exercise had preserved the functionality of these things or mysteriously broken them!
Porting L4Re and Fiasco.OC to the Ben NanoNote (Part 7)
March 27th, 2018
Having tracked down lots of places in the Fiasco.OC kernel that needed changing to run on the Ben NanoNote, including some places I had already visited, changed, and then changed again to fix my earlier mistakes, I was on the “home straight”, needing only to activate the sigma0 thread and the boot thread before the kernel would enter its normal operational state. But the sigma0 thread was proving problematic: control was apparently passed to it, but the kernel would never get control back.
Could this be something peculiar to sigma0, I wondered? I decided to swap the order of the activation, putting the boot thread first and seeing if the kernel “kept going”. Indeed, it did seem to, showing an indication on screen that I had inserted into the code to test whether the kernel regained control after activating the boot thread. So this indeed meant that something about sigma0 was causing the problem. I decided to trace execution through various method calls to see what might be going wrong.
The Big Switch
The process of activating a thread is rather interesting, involving the following methods:
- Context::activate (in kernel/fiasco/src/kern/context.cpp)
- Context::switch_to_locked
- Context::schedule_switch_to_locked
- Context::switch_exec_locked
- Context::switch_cpu (in kernel/fiasco/src/kern/mips/context-mips.cpp)
This final, architecture-specific method saves a few registers on the stack belonging to the current thread, doing so because we are now going to switch away from that thread. One of these registers ($31 or $ra) holds the return address which, by convention, is the address the processor jumps to after returning from a subroutine, function, method or something of that sort. Here, the return address, before it is stored, is set to a label just after a jump (or branch) instruction that is coming up. The flow of the code is such that we are to imagine that this jump will occur and then the processor will return to the label immediately following the jump:
- Set return address register to refer to the instruction after the impending jump
- Store registers on the stack
- Take the jump…
- Continue after the jump
However, there is a twist. Just before the jump is taken, the stack pointer is switched to one belonging to another thread. On top of this, as the jump is taken, the return address is also replaced by loading a value from this other thread’s stack. The processor then jumps to the Context::switchin_context method. When the processor encounters the end of the generated code for this method, it encounters an instruction that makes it jump to the address in the return address register. Here is a more accurate summary:
- Set return address register to refer to the instruction after the impending jump
- Store registers on the stack
- Switch the stack pointer, referencing another thread’s stack
- Switch the return address to the other thread’s value
- Take the jump…
Let us consider what might happen if this other thread was, in fact, the one we started with: the original kernel thread. Then the return address register would now hold the address of the label after the jump. Control would now pass back into the Context::switch_cpu method, and back out of that stack of invocations shown above, going from bottom to top.
But this is not what happens at the moment: the return address is something that was conjured up for a new thread and execution will instead proceed in the place indicated by that address. A switch occurs, leaving the old thread dormant while a new thread starts its life somewhere else. The problem I now faced was figuring out where the processor was “returning” to at the end of Context::switchin_context and what was happening next.
Following the Threads
I already had some idea of where the processor would end up, but inserting some debugging code in Context::switchin_context and reading the return address from the $ra register allowed me to see what had been used without chasing down how the value had got there in the first place. Then, there is a useful tool that can help people like me find out the significance of a program address. Indeed, I had already used it a few times by this stage: the sibling of objdump known as addr2line. Here is an example of its use:
mipsel-linux-gnu-addr2line -e mybuild/fiasco.debug 814165f0
This indicated that the processor was “returning” to the Thread::user_invoke method (in kernel/fiasco/src/kern/mips/thread-mips.cpp). In fact, looking at the Thread::Thread constructor function, it becomes apparent that this information is specified using the Context::prepare_switch_to method, setting this particular destination up for the above activation “switch” operation. And here we encounter some more architecture-specific tricks.
One thing that happens of importance in user_invoke is the disabling of interrupts. But if sigma0 is to be activated, they have to be enabled again so that sigma0 is then interrupted when a timer interrupt occurs. And I couldn’t find how this was going to be achieved in the code: nothing was actually setting the interrupt enable (IE) flag in the status register.
The exact mechanism escaped me for a while, and it was only after some intensive debugging interventions that I realised that the status register is also set up way back in the Thread::Thread constructor function. There, using the result of the Cp0_status::status_eret_to_user_ei method (found in kernel/fiasco/src/kern/mips/cp0_status.cpp), the stored status register is set for future deployment. The status_eret_to_user_ei method initially looks like it might do things directly with the status register, but it just provides a useful value for the point at which control is handed over to a “user space” program.
And, indeed, in the routine called ret_from_user_invoke (found in kernel/fiasco/src/kern/mips/exception.S), implemented by a pile of macros, there is a macro called restore_cp0_status that finally sets the status register to this useful value. A few instructions later, the “return from exception” instruction called eret appears and, with that, control passes to user space and hopefully some valid program code.
Finding the Fault
I now wondered whether the eret instruction was “returning” to a valid address. This caused me to take a closer look at the data structure, Entry_frame (found in kernel/fiasco/src/kern/mips/entry_frame-mips.cpp), used to hold the details of thread execution states. Debugging in user_invoke, by invoking the ip method on the current context (itself obtained from the stored stack information) yielded an address of 0x2000e0. I double-checked this by doing some debugging in the different macros implementing the routine returning control to user space.
Looking around, the Makefile for sigma0 (found as l4/pkg/l4re-core/sigma0/server/src/Makefile) provided this important clue as to its potential use of this address:
DEFAULT_RELOC_mips := 0x00200000
Using our old friend objdump on the sigma0 binary (found as mybuild/bin/mips_32/l4f/sigma0), it was confirmed that 0x2000e0 is the address of the _start routine for sigma0. So we could at least suppose that the eret instruction was passing control to the start of sigma0.
I had a suspicion that some instruction was causing an exception but not getting handled. But I had checked the generated code already and found no new unsupported instructions. This now meant the need to debug an unhandled exception condition. This can be done with care, as always, in the assembly language file containing the various “bare metal” handlers (exception.S, mentioned above), and such an intervention was enough to discover that the cause of the exception was an invalid memory access: an address exception.
Now, the handling of such exceptions can be traced from the handlers into the kernel. There is what is known as a “vector table” which lists the different exception causes and the corresponding actions to be taken when they occur. One of the entries in the table looks like this:
ENTRY_ADDR(slowtrap) # AdEL
This indicates that for an address exception upon load or instruction fetch, the slowtrap routine will be used. And this slowtrap routine itself employs a jump to a function in the kernel called thread_handle_trap (found in kernel/fiasco/src/kern/mips/thread-mips.cpp). Here, unsurprisingly, I found that attempts to handle the exception would fail and that the kernel would enter the Thread::halt method (in kernel/fiasco/src/kern/thread.cpp). This was a natural place for my next debugging intervention!
I now emitted bit patterns for several saved registers associated with the thread/context. One looked particularly interesting: the stored exception program counter which contained the value 0x2092ac. I had a look at the code for sigma0 using objdump and saw the following (with some extra annotations added for explanatory purposes):
209290: 3c02fff3 lui v0,0xfff3 209294: 24422000 addiu v0,v0,8192 // 0xfff32000 209298: afc2011c sw v0,284(s8) 20929c: 7c02e83b 0x7c02e83b // rdhwr v0, $29 (ULR) 2092a0: afc20118 sw v0,280(s8) 2092a4: 8fc20118 lw v0,280(s8) 2092a8: 8fc30158 lw v1,344(s8) 2092ac: 8c508ff4 lw s0,-28684(v0) // 0xfff2aff4
Of particular interest was the instruction at 0x20929c, which I annotated above as corresponding to our old favourite, rdhwr, along with some other key values. Now, the final instruction above is where the error occurs, and it is clear that the cause is the access to an address that is completely invalid (as annotated). The origin of this address information occurs in the second instruction above. You may have realised by now that the rdhwr instruction was failing to set the v0 (or $v0) register with the value retrieved from the indicated hardware register.
How could this be possible?! Support for this rdhwr variant was already present in Fiasco.OC, so could it be something I had done to break it? Perhaps the first rule of debugging is not to assume your own innocence for any fault, particularly if you have touched the code in the recent past. So I invoked my first strategy once again and started to look in the “reserved instruction” handler for likely causes of problems. Sure enough, I found this:
ASM_INS $at, zero, 0, THREAD_BLOCK_SHIFT, k1 # TCB addr in $at
I had introduced a macro for the ins instruction that needed a temporary register to do its work, it being specified by the last argument. But k1 (or $k1) still holds the instruction that is being inspected, and it gets used later in the routine. By accidentally overwriting it, the wrong target register gets selected, and then the hardware register value is transferred to the wrong register, leaving the correct register unaffected. This is exactly what we saw above!
What I meant to write was this:
ASM_INS $at, zero, 0, THREAD_BLOCK_SHIFT, k0 # TCB addr in $at
We can afford to overwrite k0 (or $k0) since it gets overwritten shortly after, anyway. And sure enough, with this modification, sigma0 started working, with control being returned to the kernel after its activation.
Returning to User Space
Verifying that the kernel boot process completed was slightly tricky in that further debugging interventions seemed to be unreliable. Although I didn’t investigate this thoroughly, I suspect that with sigma0 initialised, memory may have been cleared, and this clearing activity erases the descriptor structure used by the LCD peripheral. So it then becomes necessary to reinitialise the peripheral by choosing somewhere for the descriptor, writing the appropriate members, and enabling the peripheral again. Since we might now be overwriting other things critical for the system’s proper functioning, we cannot then expect execution to continue after we have written something informative to the framebuffer, so an infinite loop deliberately hangs the kernel and lets us see our debugging output on the screen.
I felt confident that the kernel was now booting and going about its normal business of switching between threads, handling interrupts and exceptions, and so on. For testing purposes, I had chosen the “hello” example as a user space program to accompany the kernel in the deployed payload, but this example is useless on the Ben without connecting up the serial console connection, which I hadn’t done. So now, I needed to start preparing examples that would actually show something on the screen, working towards running the “spectrum” example provided in the L4Re distribution.
Porting L4Re and Fiasco.OC to the Ben NanoNote (Part 6)
March 26th, 2018
With all the previous effort adjusting Fiasco.OC and the L4Re bootstrap code, I had managed to get the Ben NanoNote to run some code, but I had encountered a problem entering the kernel. When an instruction was encountered that attempted to clear the status register, it would seem that the boot process would not get any further. The status register controls things like which mode the processor is operating in, and certain modes offer safety guarantees about how much else can go wrong, which is useful when they are typically entered when something has already gone wrong.
When starting up, a MIPS-based processor typically has the “error level” (ERL) flag set in the status register, meaning that normal operations are suspended until the processor can be configured. The processor will be in kernel mode and it will bypass the memory mapping mechanisms when reading from and writing to memory addresses. As I found out in my earlier experiments with the Ben, running in kernel mode with ERL set can mask problems that may then emerge when unsetting it, and clearing the status register does precisely that.
With the kernel’s _start routine having unset ERL, accesses to lower memory addresses will now need to go through a memory mapping even though kernel mode still applies, and if a memory mapping hasn’t been set up then exceptions will start to occur. This tripped me up for quite some time in my previous experiments until I figured out that a routine accessing some memory in an apparently safe way was in fact using lower memory addresses. This wasn’t a problem with ERL set – the processor wouldn’t care and just translate them directly to physical memory – but with ERL unset, the processor now wanted to know how those addresses should really be translated. And since I wasn’t handling the resulting exception, the Ben would just hang.
Debugging the Debugging
I had a long list of possible causes, some more exotic than others: improperly flushed caches, exception handlers in the wrong places, a bad memory mapping configuration. I must admit that it is difficult now, even looking at my notes, to fully review my decision-making when confronting this problem. I can apply my patches from this time and reproduce a situation where the Ben doesn’t seem to report any progress from within the kernel, but with hindsight and all the progress I have made since, it hardly seems like much of an obstacle at all.
Indeed, I have already given the game away in what I have already written. Taking over the framebuffer involves accessing some memory set up by the bootloader. In the bootstrap code, all of this memory should actually be mapped, but since ERL is set I now doubt that this mapping was even necessary for the duration of the bootstrap code’s execution. And I do wonder whether this mapping was preserved once the kernel was started. But what appeared to happen was that when my debugging code tried to load data from the framebuffer descriptor, it would cause an exception that would appear to cause a hang.
Since I wanted to make progress, I took the easy way out. Rather than try and figure out what kind of memory mapping would be needed to support my debugging activities, I simply wrapped the code accessing the framebuffer descriptor and the framebuffer itself with instructions that would set ERL and then unset it afterwards. This would hopefully ensure that even if things weren’t working, then at least my things weren’t making it all worse.
Lost in Translation
It now started to become possible to track the progress of the processor through the kernel. From the _start routine, the processor jumps to the kernel_main function (in kernel/fiasco/src/kern/mips/main.cpp) and starts setting things up. As I was quite sure that the kernel wasn’t functioning correctly, it made sense to drop my debugging code into various places and see if execution got that far. This is tedious work – almost a form of inefficient “single-stepping” – but it provides similar feedback about how the code is behaving.
Although I had tried to do a reasonable job translating certain operations to work on the JZ4720 used by the Ben, I was aware that I might have made one or two mistakes, also missing areas where work needed doing. One such area appeared in the Cpu class implementation (in kernel/fiasco/src/kern/mips/cpu-mips.cpp): a rich seam of rather frightening-looking processor-related initialisation activities. The Cpu::first_boot method contained this ominous-looking code:
require(c.r<0>().ar() > 0, "MIPS r1 CPUs are notsupported\n");
I hadn’t noticed this earlier, and its effect is to terminate the kernel if it detects an architecture revision just like the one provided by the JZ4720. There were a few other tests of the capabilities of the processor that needed to be either disabled or reworked, and I spent some time studying the documentation concerning configuration registers and what they can tell programs about the kind of processor they are running on. Amusingly, our old friend the rdhwr instruction is enabled for user programs in this code, but since the JZ4720 has no notion of that instruction, we actually disable the instruction that would switch rdhwr on in this way.
Another area that proved to be rather tricky was that of switching interrupts on and having the system timer do its work. Early on, when laying the groundwork for the Ben in the kernel, I had made a rough translation of the CI20 code for the Ben, and we saw some of these hardware details a few articles ago. Now it was time to start the timer, enable interrupts, and have interrupts delivered as the timer counter reaches its limit. The part of the kernel concerned is Kernel_thread::bootstrap (in kernel/fiasco/src/kern/kernel_thread.cpp), where things are switched on and then we wait in a delay loop for the interrupts to cause a variable to almost magically change by itself (in kernel/fiasco/src/drivers/delayloop.cpp):
Cpu_time t = k->clock; Timer::update_timer(t + 1000); // 1ms while (t == (t1 = k->clock)) Proc::pause();
But the processor just got stuck in this loop forever! Clearly, I hadn’t done everything right. Some investigation confirmed that various timer registers were being set up correctly, interrupts were enabled, but that they were being signalled using the “interrupt pending 2” (IP2) flag of the processor’s “cause” register which reports exception and interrupt conditions. Meanwhile, I had misunderstood the meaning of the number in the last statement of the following code (from kernel/fiasco/src/kern/mips/bsp/qi_lb60/mips_bsp_irqs-qi_lb60.cpp):
_ic[0] = new Boot_object<Irq_chip_ingenic>(0xb0001000); m->add_chip(_ic[0], 0); auto *c = new Boot_object<Cascade_irq>(nullptr, ingenic_cascade); Mips_cpu_irqs::chip->alloc(c, 1);
Here is how the CI20 had been set up (in kernel/fiasco/src/kern/mips/bsp/ci20/mips_bsp_irqs-ci20.cpp):
_ic[0] = new Boot_object<Irq_chip_ingenic>(0xb0001000); m->add_chip(_ic[0], 0); _ic[1] = new Boot_object<Irq_chip_ingenic>(0xb0001020); m->add_chip(_ic[1], 32); auto *c = new Boot_object<Cascade_irq>(nullptr, ingenic_cascade); Mips_cpu_irqs::chip->alloc(c, 2);
With virtually no knowledge of the details, and superficially transcribing the code, editing here and there, I had thought that the argument to the alloc method referred to the number of “chips” (actually the number of registers dedicated to interrupt signals). But in fact, it indicates an adjustment to what the kernel code calls a “pin”. In the Mips_cpu_irq_chip class (in kernel/fiasco/src/kern/mips/mips_cpu_irqs.cpp), we actually see that this number is used to indicate the IP flag that will need to be tested. So, the correct argument to the alloc method is 2, not 1, just as it is for the CI20:
Mips_cpu_irqs::chip->alloc(c, 2);
This fix led to another problem and the discovery of another area that I had missed: the “exception base” gets redefined in the kernel (in src/kern/mips/cpu-mips.cpp), and so I had to make sure it was consistent with the other places I had defined it by changing its value in the kernel (in src/kern/mips/mem_layout-mips32.cpp). I mentioned this adjustment previously, but it was at this stage that I realised that the exception base gets set in the kernel after all. (I had previously set it in the bootstrap code to override the typical default of 0x80000000.)
Leaving the Kernel
Although we are not quite finished with the kernel, the next significant obstacle involved starting programs that are not part of the kernel. Being a microkernel, Fiasco.OC needs various other things to offer the kind of environment that a “monolithic” operating system kernel might provide. One of these is the sigma0 program which has responsibilities related to “paging” or allocating memory. Attempting to start such programs exercises how the kernel behaves when it hands over control to these other programs. We should expect that timer interrupts should periodically deliver control back to the kernel for it to do work itself, this usually involving giving other programs a chance to run.
I was seeing the kernel in the “home straight” with regard to completing its boot activities. The Kernel_thread::init_workload method (in kernel/fiasco/src/kern/kernel_thread-std.cpp) was pretty much the last thing to be invoked in the Kernel_thread::run method (in kernel/fiasco/src/kern/kernel_thread.cpp) before normal service begins. But it was upon attempting to “activate” a thread to run sigma0 that a problem arose: the kernel never got control back! This would be my last major debugging exercise before embarking on a final excursion into “user space”.
Porting L4Re and Fiasco.OC to the Ben NanoNote (Part 5)
March 25th, 2018
We left off last time with the unenviable task of debugging a non-working system. In such a situation the outlook can seem bleak, but I mentioned a couple of strategies that can sometimes rescue the situation. The first of these is to rule out areas of likely problems, which in my case tends to involve reviewing what I have done and seeing if I have made some stupid mistakes. Naturally, it helps to have a certain amount of experience to inform this process; otherwise, practically everything might be a place where such mistakes may be lurking.
One thing that bothered me was the use of the memory map by Fiasco.OC on the Ben NanoNote. When deploying my previous experimental work to the Ben, I had become aware of limitations around where things might be stored, at least while any bootloader might be active. Care must be taken to load new code away from memory already being used, and it seems that the base of memory must also be avoided, at least at first. I wasn’t convinced that this avoidance was going to happen with the default configuration of the different components.
The Memory Map
Of particular concern were the exception vectors – where the processor jumps to if an exception or interrupt occurs – whose defaults in Fiasco.OC situate them at the base of kernel memory: 0x80000000. If the bootloader were to try and copy the code that handles exceptions to this region, I rather suspected that it would immediately cause problems.
I was also unsure whether the bootloader was able to load the payload from the MMC/MicroSD card into memory without overwriting itself or corrupting the payload as it copied things around in memory. According to the boot script that seems to apply to the Ben, it loads the payload into memory at 0x80600000:
#define CONFIG_BOOTCOMMANDFROMSD "mmc init; ext2load mmc 0 0x80600000 /boot/uImage; bootm"
Meanwhile, the default memory settings for L4Re has code loaded rather low in the kernel address space at 0x802d0000. Without really knowing what happens, I couldn’t be sure that something might get copied to that location, that the copied data might then run past 0x80600000, and this might overwrite some other thing – the kernel, perhaps – that hadn’t been copied yet. Maybe this was just paranoia, but it was at least something that could be dealt with. So I came up with some alternative arrangements:
0x81401000 exception handlers 0x81400000 kernel load address 0x80d00000 bootstrap start address 0x80600000 payload load address when copied by bootm
I wanted to rule out memory conflicts but try and not conjure up more exotic solutions than strictly necessary. So I made some adjustments to the location of the kernel, keeping the exception vectors in the same place relative to the kernel, but moving the vectors far away from the base of memory. It turns out that there are quite a few places that need changing if you do this:
- A configuration setting, CONFIG_KERNEL_LOAD_ADDR-32, in the kernel build scripts (in kernel/fiasco/src/Modules.mips)
- The exception base, EXC_BASE, in the kernel’s linker script (in kernel/fiasco/src/kernel.mips.ld)
- The exception base, Exception_base, in a description of the kernel memory layout (in kernel/fiasco/src/kern/mips/mem_layout-mips32.cpp)
- The exception base, if it is mentioned in the bootstrap initialisation (in l4/pkg/bootstrap/server/src/ARCH-mips/crt0.S)
The location of the rest of the payload seems to be configured by just changing DEFAULT_RELOC_mips32 in the bootstrap package’s build scripts (in l4/pkg/bootstrap/server/src/Make.rules).
With this done, I had hoped that I might have “moved the needle” a little and provoked a visible change when attempting to boot the system, but this was always going to be rather optimistic. Having pursued the first strategy, I now decided to pursue the second.
Update: it turns out that a more conventional memory arrangement can be used, and this is described in the summary article.
Getting in at the Start
The second strategy is to use every opportunity to get the device to show what it is doing. But how can we achieve this if we cannot boot the kernel and start some code that sets up the framebuffer? Here, there were two things on my side: the role of the bootstrap code, it being rather similar to code I have written before, and the state of the framebuffer when this code is run.
I had already discovered that provided that the code is loaded into a place that can be started by the bootloader, then the _start routine (in l4/pkg/bootstrap/server/src/ARCH-mips/crt0.S) will be called in kernel mode. And I had already looked at this code for the purposes of identifying instructions that needed rewriting as well as for setting the “exception base”. There were a few other precautions that were worth taking here before we might try and get the code to show its activity.
For instance, the code present that attempts to enable a floating point unit in the processor does not apply to the Ben, so this was disabled. I was also unconvinced that the memory mapping instructions would work on the Ben: the JZ4720 does not seem to support memory pages of 256MB, with the Ben only having 32MB anyway, so I changed this to use 16MB pages instead. This must be set up correctly because any wandering into unmapped memory – visiting bad addresses – cannot be rectified before the kernel is active, and the whole point of the bootstrap code is to get the kernel active!
Now, it wasn’t clear just how far the processor was getting through this code before failing somewhere, but this is where the state of the framebuffer comes in. On the Ben, the bootloader initialises the framebuffer in order to show the state of the device, indicate whether it found a payload to load and boot from, complain about error conditions, and so on. It occurred to me that instead of trying to initialise a framebuffer by programming the LCD peripheral in the JZ4720, set up various structures in memory, decide where these structures should even be situated, I could just read the details of the existing framebuffer from the LCD peripheral’s registers, then find out where the framebuffer resides, and then just write whatever data I liked to the framebuffer in order to communicate with the outside world.
So, I would just need to write a few lines of assembly language, slip it into the bootstrap code, and then see if the framebuffer was changed and the details of interest written to the Ben’s display. Here is a fragment of code in a form that would become rather familiar after a time:
li $8, 0xb3050040 /* LCD_DA0 */ lw $9, 0($8) /* &descriptor */ lw $10, 4($9) /* fsadr = descriptor[1] */ lw $11, 12($9) /* ldcmd = descriptor[3] */ li $8, 0x00ffffff and $11, $8, $11 /* size = ldcmd & LCD_CMD0_LEN */ li $9, 0xa5a5a5a5 1: sw $9, 0($10) /* *fsadr = ... */ addiu $11, $11, -1 /* size -= 1 */ addiu $10, $10, 4 /* fsadr += 4 */ bnez $11, 1b /* until size == 0 */ nop
To summarise, it loads the address of a “descriptor” from a configuration register provided by the LCD peripheral, this register having been set by the bootloader. It then examines some members of the structure provided by the descriptor, notably the framebuffer address (fsadr) and size (a subset of ldcmd). Just to show some sign of progress, the code loops and fills the screen with a specific value, in this case a shade of grey.
By moving this code around in the bootstrap initialisation routine, I could see whether the processor even managed to get as far as this little debugging fragment. Fortunately for me, it did get run, the screen did turn grey, and I could then start to make deductions about why it only got so far but no further. One enhancement to the above that I had to make after a while was to temporarily change the processor status to “error level” (ERL) when accessing things like the LCD configuration. Not doing so risks causing errors in itself, and there is nothing more frustrating than chasing down errors only to discover that the debugging code caused these errors and introduced them as distractions from the ones that really matter.
Enter the Kernel
The bootstrap code isn’t all assembly language, and at the end of the _start routine, the code attempts to jump to __main. Provided this works, the processor enters code that started out life as C++ source code (in l4/pkg/bootstrap/server/src/ARCH-mips/head.cc) and hopefully proceeds to the startup function (in l4/pkg/bootstrap/server/src/startup.cc) which undertakes a range of activities to prepare for the kernel.
Here, my debugging routine changed form slightly, minimising the assembly language portion and replacing the simple screen-clearing loop with something in C++ that could write bit patterns to the screen. It became interesting to know what address the bootstrap code thought it should be using for the kernel, and by emitting this address’s bit pattern I could check whether the code had understood the structure of the payload. It seemed that the kernel was being entered, but upon executing instructions in the _start routine (in kernel/fiasco/src/kern/mips/crt0.S), it would hang.

The Ben NanoNote showing a bit pattern on the screen with adjacent bits using slightly different colours to help resolve individual bit values; here, the framebuffer address is shown (0x01fb5000), but other kinds of values can be shown, potentially many at a time
This now led to a long and frustrating process of detective work. With a means of at least getting the code to report its status, I had a chance of figuring out what might be wrong, but I also needed to draw on experience and ideas about likely causes. I started to draw up a long list of candidates, suggesting and eliminating things that could have been problems that weren’t. Any relief that a given thing was not the cause of the problem was tempered by the realisation that something else, possibly something obscure or beyond the limit of my own experiences, might be to blame. It was only some consolation that the instruction provoking the failure involved my nemesis from my earlier experiments: the “error level” (ERL) flag in the processor’s status register.
Porting L4Re and Fiasco.OC to the Ben NanoNote (Part 4)
March 24th, 2018
As described previously, having hopefully done enough to modify the kernel – Fiasco.OC – for the Ben NanoNote, it then became necessary to investigate the bootstrap package that is responsible for setting up the hardware and starting the kernel. This package resides in the L4Re distribution, which is technically a separate thing, even though both L4Re and Fiasco.OC reside in the same published repository structure.
Before continuing into the details, it is worth noting which things need to be retrieved from the L4Re section of the repository in order to avoid frustration later on with package dependencies. I had previously discovered that the following package installation operation would be required (from inside the l4 directory):
svn update pkg/acpica pkg/bootstrap pkg/cxx_thread pkg/drivers pkg/drivers-frst pkg/examples \
pkg/fb-drv pkg/hello pkg/input pkg/io pkg/l4re-core pkg/libedid pkg/libevent \
pkg/libgomp pkg/libirq pkg/libvcpu pkg/loader pkg/log pkg/mag pkg/mag-gfx pkg/x86emu
With the listed packages available, it should be possible to build the examples that will eventually interest us. Some of these appear superfluous – x86emu, for instance – but some of the more obviously-essential packages have dependencies on these other packages, and so we cannot rely on our intuition alone!
Also needed when building a payload is some path definitions in the l4/conf/Makeconf.boot file. Here is what I used:
MODULE_SEARCH_PATH += $(L4DIR_ABS)/../kernel/fiasco/mybuild MODULE_SEARCH_PATH += $(L4DIR_ABS)/conf/examples MODULE_SEARCH_PATH += $(L4DIR_ABS)/pkg/io/io/config BOOTSTRAP_SEARCH_PATH = $(L4DIR_ABS)/conf/examples BOOTSTRAP_SEARCH_PATH += $(L4DIR_ABS)/../kernel/fiasco/mybuild BOOTSTRAP_SEARCH_PATH += $(L4DIR_ABS)/pkg/io/io/config BOOTSTRAP_MODULES_LIST = $(L4DIR_ABS)/conf/modules.list
This assumes that the build directory used when building the kernel is called mybuild. The Makefile will try and copy the kernel into the final image to be deployed and so needs to know where to find it.
Describing the Ben (Again)
Just as we saw with the kernel, there is a need to describe the Ben and to audit the code to make sure that it stands a chance of working on the Ben. This is done slightly differently in L4Re but the general form of the activity is similar, defining the following:
- An architecture version (MIPS32r1) for the JZ4720 (in l4/mk/arch/Kconfig.mips.inc)
- A platform configuration for the Ben (in l4/mk/platforms)
- Some platform details in the bootstrap package (in l4/pkg/bootstrap/server/src)
- Some hardware details related to memory and interrupts (in l4/pkg/io/io/config/plat-qi_lb60)
For the first of these, I introduced a configuration setting (CPU_MIPS_32R1) to allow us to distinguish between the Ben’s SoC (JZ4720) and other processors, just as I did in the kernel code. With this done, the familiar task of hunting down problematic assembly language instructions can begin, and these can be divided into the following categories:
- Those that can be rewritten using other instructions that are available to us
- Those that must be “trapped” and handled by the kernel
Candidates for the former category include all unprivileged instructions that the JZ4720 doesn’t support, such as ext and ins. Where privileged instructions or ones that “bridge” privileges in some way are used, we can still rewrite them if they appear in the bootstrap code, since this code is also running in privileged mode. Here is an example of such privileged instruction rewriting (from l4/pkg/bootstrap/server/src/ARCH-mips/crt0.S):
#if defined(CONFIG_CPU_MIPS_32R1) cache 0x01, 0($a0) # Index_Writeback_Inv_D nop cache 0x08, 0($a0) # Index_Store_Tag_I #else synci 0($a0) #endif
Candidates for the latter category include all awkward privileged or privilege-escalating instructions outside the bootstrap package. Fortunately, though, we don’t need to worry about them very much at all. Since the kernel will be obliged to trap them, we can just keep them where they are and concede that there is nothing else we can do with them.
However, there is one pitfall: these preserved-but-unsupported instructions will upset the compiler! Consider the use of the now overly-familiar rdhwr instruction. If it is mentioned in an assembly language statement, the compiler will notice that amongst its clean MIPS32r1-compliant output, something is inserting an unrecognised instruction, yielding that error we saw earlier:
Error: opcode not supported on this processor: mips32 (mips32)
But we do know what we’re doing! So how can we persuade the compiler? The solution is to override what the compiler (or assembler) thinks it should be producing by introducing a suitable directive as in the following example (from l4/pkg/l4re-core/l4sys/include/ARCH-mips/cache.h):
asm volatile ( ".set push\n" ".set mips32r2\n" "rdhwr %0, $1\n" ".set pop" : "=r"(step));
Here, with the .set directives, we switch this little region of code to MIPS32r2 compliance and emit our forbidden instruction into the output. Since the kernel will take care of it in the end, the compiler shouldn’t be made to feel that it has to defend us against it.
In L4Re, there are also issues experienced with the CI20 that will also affect the Ben, such as an awkward and seemingly compiler-related issue affecting the way programs are started. In this regard, I just kept my existing patches for these things applied.
My other platform-related adjustments for the Ben have mostly borrowed from support for the CI20 where it existed. For instance, the bootstrap package’s definition for the Ben (in l4/pkg/bootstrap/server/src/platform/qi_lb60.cc) just takes the CI20 equivalent, eliminates superfluous features, modifies details that are different between the SoCs, and changes identifiers. The general definition for the Ben (in l4/mk/platforms/qi_lb60.conf) merely acknowledges differences in some basic platform details.
The CI20 was not supported with a hardware definition describing memory regions and interrupts used by the io package. Taking other devices as inspiration, I consulted the device documentation and wrote a definition when experimenting with the CI20. For the Ben, the form of this definition (in l4/pkg/io/io/config/plat-qi_lb60/hw_devices.io) remains similar but is obviously adjusted for the SoC differences.
Device Drivers and Output
One topic that I have not really mentioned at all is that pertaining to device drivers. I would not have even started this work if I didn’t feel there was a chance of seeing some signs of success from the Ben. Although the Ben, like the CI20, has the capability of exposing a serial console to the outside world, meaning that it can emit messages via a cable to another computer and receive input from that computer, unlike the CI20, its serial console pins are not particularly convenient to use: they really require wires to be soldered to some tiny pads that are found in the battery compartment of the device.
Now, my soldering skills are not very good, and I also want to be able to put the battery back into the device in future. I did try and experiment by holding wires against the pads, this working once or twice by showing output when booting the Ben into its more typical Linux-based environment. But such experiments proved to be unsustainable and rather uncomfortable, needing some kind of “guitar grip” while juggling cables and holding down buttons. So I quickly knew that I would need to get output from the Ben in other ways.
Having deployed low-level payloads to the Ben before, I knew something about the framebuffer, so I had some confidence about initialising it and getting something on the screen that might tell me what has or hasn’t happened. And I adapted my code from this previous effort, itself being derived from driver code written by the people responsible for the Ben, wrapping it up for L4Re. I tried to keep this code minimally different from its previous incarnation, meaning that I could eliminate certain kinds of mistakes in case the code didn’t manage to do its job. With this in place, I felt that I could now consider trying out my efforts and seeing what, if anything, might happen.
Attempting to Bootstrap
Being in the now-familiar position of believing that enough has been done to make the software run, I now considered an attempt at actually bootstrapping the kernel. It may sound naive, but I almost expected to be able to compile everything – the kernel, L4Re, my drivers – and for them all to work together in harmony and produce at least something on the display. But instead, after “Starting kernel …”, nothing happened.
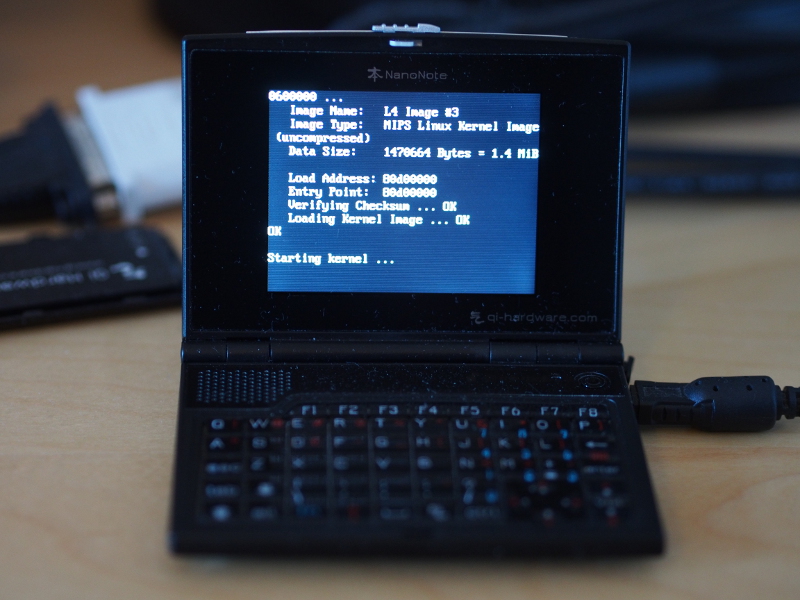
The Ben NanoNote trying to boot a payload from the memory card
It should be said that in these kinds of exercises, just one source of failure need present itself and the outcome is, of course, failure. And I can confirm that there were many sources of failure at this point. The challenges, then, are to identify all of these and then to eliminate them all. But how can you even know what all of these sources of failure actually are? It seemed disheartening, but then there are two kinds of strategy that can be employed: to investigate areas likely to be causing problems, and to take every opportunity to persuade the device to tell us what is happening. And with this, the debugging would begin.
Porting L4Re and Fiasco.OC to the Ben NanoNote (Part 3)
March 23rd, 2018
So far, in this exercise of porting L4Re and Fiasco.OC to the Ben NanoNote, we have toured certain parts of the kernel, made adjustments for the compiler to generate suitable code, and added some descriptions of the device itself. But, as we saw, the Ben needs some additional changes to be made to the software in places where certain instructions are used that it doesn’t support. Attempting to compile the kernel will most likely end with an error if we ignore such matters, because although the C and C++ code will produce acceptable instructions, upon encountering an assembly language statement containing an unacceptable instruction, the compiler will probably report something like this:
Error: opcode not supported on this processor: mips32 (mips32)
So, we find ourselves in a situation where the compiler is doing the right thing for the code it is generating, but it also notices when the programmer has chosen to do what is now the wrong thing. We must therefore track down these instructions and offer a supported alternative. Previously, we introduced a special configuration setting that might be used to indicate to the compiler when to choose these alternative sequences of instructions: CPU_MIPS32_R1. This gets expanded to CONFIG_CPU_MIPS32_R1 by the build system and it is this identifier that gets used in the program code.
Those Unsupported Instructions
I have put off giving out the details so far, but now is as good a time as any to provide some about the instructions that the JZ4720 (the SoC in the Ben NanoNote) doesn’t seem to support. Some of them are just conveniences, offering a single instruction where many would otherwise be needed. Others offer functionality that is not always trivially replicated.
| Instructions | Description | Privileges |
|---|---|---|
| di, ei | Disable, enable interrupts | Privileged |
| ext | Extract bits from register | Unprivileged |
| ins | Insert bits into register | Unprivileged |
| rdhwr | Read hardware register | Unprivileged, accesses privileged information |
| synci | Synchronise instruction cache | Unprivileged, performs privileged operations |
We have already mentioned rdhwr, and this is precisely the kind of instruction that can pose problems, these mostly being concerned with it offering access to some (supposedly) privileged information from an unprivileged processor mode. However, since the kernel runs in a privileged mode, typically referred to as “kernel mode”, we won’t see rdhwr when doing our modifications to the kernel. And since the need to provide rdhwr also applied to the JZ4780 (the SoC in the MIPS Creator CI20), it turned out that I didn’t need to do much in addition to what others had already done in supporting it.
Another instruction that requires a bridging of privilege levels is synci. If we discover synci being used in the kernel, it is possible to rewrite it in terms of the equivalent cache instructions. However, outside the kernel in unprivileged mode, those cache instructions cannot be used and we would not wish to support them either, because “user mode” programs are not meant to be playing around with such aspects of the hardware. The solution for such situations is to “trap” synci when it gets used in unprivileged code and to handle it using the same mechanism as that employed to handle rdhwr: to treat it as a “reserved instruction”.
Thus, some extra code is added in the kernel to support this “trap” mechanism, but where we can just replace the instructions, we do so as in this example (from kernel/fiasco/src/kern/mips/alternatives.cpp):
#ifdef CONFIG_CPU_MIPS32_R1
asm volatile ("cache 0x01, %0\n"
"nop\n"
"cache 0x08, %0"
: : "R"(orig_insn[i]));
#else
asm volatile ("synci %0" : : "R"(orig_insn[i]));
#endif
We could choose not to bother doing this even in the kernel, instead just trapping all usage of synci. But this would have a performance impact, and L4 is ostensibly very much about performance, and so the opportunity is taken to maximise it by going round and fixing up the code in all these places instead. (Note that I’ve used the nop instruction above, but maybe I should use ehb. It’s probably something to take another look at, perhaps more generally with regard to which instruction I use in these situations.)
The other unsupported instructions don’t create as many problems. The di (disable interrupts) and ei (enable interrupts) instructions are really shorthand for modifications to the processor’s status register, albeit performing those modifications “atomically”. In principle, in cases where I have written out the equivalent sequence of instructions but not done anything to “guard” these instructions from untimely interruptions or exceptions, something bad could happen that wouldn’t have happened with the di or ei instructions themselves.
Maybe I will revisit this, too, and see what the risks might actually be, but for the purposes of getting the kernel working – which is where these instructions appear – the minimal solution seemed reasonably adequate. Here is an extract from a statement employing the ei instruction (from kernel/fiasco/src/drivers/mips/processor-mips.cpp):
#ifdef CONFIG_CPU_MIPS32_R1 ASM_MFC0 " $t0, $12\n" "ehb\n" "or $t0, $t0, %[ie]\n" ASM_MTC0 " $t0, $12\n" #else "ei\n" #endif
Meanwhile, the ext (extract) and ins (insert) instructions have similar properties in that they too access parts of registers, replacing sequences of instructions that do the work piece by piece. One challenge that they pose is that they appear in potentially many different places, some with minimal register use, and the equivalent instruction sequence may end up needing an extra register to get the same work done. Fortunately, though, those equivalent instructions are all perfectly usable at whichever privilege level happens to be involved. Here is an extract from a statement employing the ins instruction (from kernel/fiasco/src/kern/mips/thread-mips.cpp):
#ifdef CONFIG_CPU_MIPS32_R1 " andi $t0, %[status], 0xff \n" " li $t1, 0xffffff00 \n" " and $t2, $t2, $t1 \n" " or $t2, $t2, $t0 \n" #else " ins $t2, %[status], 0, 8 \n" #endif
Note how temporary registers are employed to isolate the bits from the status register and to erase bits in the $t2 register before these two things are combined and stored in $t2.
Bridging the Privilege Gap
The rdhwr instruction has been mentioned quite a few times already. In the kernel, it is handled in the kernel/fiasco/src/kern/mips/exception.S file, specifically in the routine called “reserved_insn”. When the processor encounters an instruction it doesn’t understand, the kernel should have been configured to send it here. I will admit that I knew little to nothing about what to do to handle such situations, but the people who did the MIPS port of the kernel had laid the foundations by supporting one rdhwr variant, and I adapted their work to handle another.
In essence, what happens is that the processor “shows up” in the reserved_insn routine with the location of the bad instruction in its “exception program counter” register. By loading the value stored at that location, we obtain the instruction – or its value, at least – and can then inspect this value to see if we recognise it and can do anything with it. Here is the general representation of rdhwr with an example of its use:
| SPECIAL3 | _____ | t | s | _____ | RDHWR |
|---|---|---|---|---|---|
| 011111 | 00000 | 01000 | 00001 | 00000 | 111011 |
The first and last portions of the above representation identify the instruction in general, with the bits for the second and next-to-last portions being set to zero presumably because they are either not needed to encode an instruction in this category, or they encode two parameters that are not needed by this particular instruction. To be honest, I haven’t checked which explanation applies, but I suspect it is the latter.
This leaves the remaining portions to indicate specific registers: the target (t) and source (s). With t=8, the result is written to register $8, which is normally known as $t0 (or just t0) in MIPS assembly language. Meanwhile, with s=1, the source register has been given as $1, which is the SYNCI_Step hardware register. So, the above is equivalent to the following:
rdhwr $t0, $1
To reproduce this same realisation in code, we must isolate the parts of the value that identify the instruction. For rdhwr accessing the SYNCI_Step hardware register, this means using a mask that preserves the SPECIAL3, RDHWR, s and blank regions, ignoring the target register value t because it will change according to specific circumstances. Applying this mask to the instruction value and comparing it to an expected value is done rather like this:
li $k0, 0x7c00083b # $k0 = SPECIAL3, blank, s=1, blank, RDHWR li $at, 0xffe0ffff # $at = define a mask to mask out t and $at, $at, $k1 # $at = the mask applied to the instruction value
Now, if $at is equal to $k0, the instruction value is identified as encoding rdhwr accessing SYNCI_Step, with the target register being masked out so as not to confuse things. Later on, the target register is itself selected and some trickery is employed to get the appropriate data into that register before returning from this routine.
For the above case and for the synci instruction, the work that needs doing once such an instruction has been identified is equivalent to what would have happened had it been possible to just insert into the code the alternative sequence of instructions that achieves the same thing. So, for synci, the equivalent cache instructions are executed before control is returned to the instruction after synci in the program where it appeared. Thus, upon encountering an unsupported instruction, control is handed over from an unprivileged program to the kernel, the instruction is identified and handled using the necessary privileged instructions, and then control is handed back to the unprivileged program again.
In fact, most of my efforts in exception.S were not really directed towards these two awkward instructions. Instead I had to deal with the use of quite a number of ext and ins instructions. Although it seems tempting to just trap those as well and to provide handlers for them, that would add considerable overhead, and so I added some macros to provide the same functionality when building the kernel for the Ben.
Prepare for Launch
Looking at my patches for the kernel now, I can see that there isn’t much else to cover. One or two details are rather important in the context of the Ben and how it manages to boot, however, and the process of figuring out those details was, like much else in this exercise, time-consuming, slightly frustrating, and left surprisingly little trace once the solution was found. At this stage, not everything was perfectly transcribed or expressed, leaving a degree of debugging activity that would also need to be performed in the future.
So, with a kernel that might be runnable, I considered what it would take to actually launch that kernel. This led me into the L4 Runtime Environment (L4Re) code and specifically to the bootstrap package. It turns out that the kernel distribution delegates such concerns to other software, and the bootstrap package sits uneasily alongside other packages, it being perhaps the only one amongst them that can exercise as much privilege as the kernel because its code actually runs at boot time before the kernel is started up.
Porting L4Re and Fiasco.OC to the Ben NanoNote (Part 2)
March 22nd, 2018
Having undertaken some initial investigations into running L4Re and Fiasco.OC on the MIPS Creator CI20, I envisaged attempting to get this software running on the Ben NanoNote, too. For a while, I put this off, feeling confident that when I finally got round to it, it would probably be a matter of just choosing the right compiler options and then merely fixing all the mistakes I had made in my own driver code. Little did I know that even the most trivial activities would prove more complicated than anticipated.
As you may recall, I had noted that a potentially viable approach to porting the software would merely involve setting the appropriate compiler switches for “soft-float” code, thus avoiding the generation of floating point instructions that the JZ4720 – the SoC on the Ben NanoNote – would not be able to execute. A quick check of the GCC documentation indicated the availability of the -msoft-float switch. And since I have a working cross-compiler for MIPS as provided by Debian, there didn’t seem to be much more to it than that. Until I discovered that the compiler doesn’t seem to support soft-float output at all.
I had hoped to avoid building my own cross-compiler, and apart from enthusiastic (and occasionally successful) attempts to build the Debian ones before they became more generally available, the last time I really had anything to do with this was when I first developed software for the Ben. As part of the general support for the device an OpenWrt distribution had been made available. Part of that was the recipe for building the cross-compiler and other tools, needed for building a kernel and all the software one would deploy on a device. I am sure that this would still be a good place to look for a solution, but I had heard things about Buildroot and so set off to investigate that instead.
So although Buildroot, like OpenWrt, is promoted as a way of building an entire system, it too offers help in building just the toolchain if that is all you need. Getting it to build the appropriately-configured cross-compiler is a matter of the familiar “make menuconfig” seen from the Linux kernel source distribution, choosing things in a menu – for us, asking for a soft-float toolchain, also enabling C++ support – and then running “make toolchain”. As a result, I got a range of tools in the output/host/bin directory prefixed with mipsel-buildroot-linux-uclibc.
Some Assembly Required
Changing the compiler settings for Fiasco.OC (in kernel/fiasco/src/Makeconf.mips) and L4Re (in l4/mk/arch/Makeconf.mips), and making sure not to enable any floating point support in Fiasco.OC, and recompiling the code to produce soft-float output was straightforward enough. However, despite the portability of this software, it isn’t completely C and C++ code: lurking in various places (typically in mips or ARCH-mips directories) are assembly language source files with the .S prefix, and in some C and C++ files one can also find “asm” statements which embed assembly language instructions within higher-level code.
With the assumption that by specifying the right compiler switches, no floating point instructions will be produced from C or C++ source code, all that remains is to determine whether any of these other code sections mention such forbidden instructions. It was asserted that Fiasco.OC doesn’t use any floating point instructions at all. Meanwhile, I couldn’t find any floating point instructions in the generated code: “mipsel-linux-gnu-objdump -D some-output-file” (or, indeed, “mipsel-buildroot-linux-uclibc-objdump -D some-output-file”) now started to become a familiar acquaintance if not exactly a friend!
In fact, the assembly language files and statements would provide other challenges in the form of instructions unsupported by the JZ4720. Again, I had the choice of either trying to support MIPS32r2 instructions, like rdhwr, by providing “reserved instruction” handlers, or to rewrite these instructions in forms suitable for the JZ4720. At least within Fiasco.OC – the “kernel” – where the environment for executing instructions is generally privileged, it is possible to reformulate MIPS32r2 instructions in terms of others. I will return to the details of these instructions later on.
Where to Find Things
Having spent all this time looking around in the L4Re and Fiasco.OC code, it is perhaps worth briefly mentioning where certain things can be found. The heart of the action in the kernel is found in these places:
| Directory | Significance |
|---|---|
| kernel/fiasco/src | The top-level directory of the kernel sources, having some MIPS-specific files |
| kernel/fiasco/src/drivers/mips | Various hardware abstractions related to MIPS |
| kernel/fiasco/src/jdb/mips | MIPS-specific support code for the kernel debugger (which I don’t use) |
| kernel/fiasco/src/kern/mips | MIPS-specific support code for the kernel itself |
| kernel/fiasco/src/templates | Device configuration details |
As noted above, I don’t use the kernel debugger, but I still made some edits that might make it possible to use it later on. For the most part, the bulk of my time and effort was spent in the src/kern/mips hierarchy, occasionally discovering things in src/drivers/mips that also needed some attention.
Describing the Ben
So it started to make sense to consider how the Ben might be described in terms of a kernel configuration, and whether we might want to indicate a less sophisticated revision of the architecture so that we could test for it in the code and offer alternative sequences of instructions where possible. There are a few different places where hardware platforms are described within Fiasco.OC, and I ended up defining the following:
- An architecture version (MIPS32r1) for the JZ4720 (in kernel/fiasco/src/kern/mips/Kconfig)
- A definition for the Ben itself (in kernel/fiasco/src/templates/globalconfig.out.mips-qi_lb60)
- A board entry for the Ben (in kernel/fiasco/src/kern/mips/bsp/qi_lb60/Kconfig) as part of a board-specific collection of functionality
This is not by any means enough, even disregarding any code required to do things specific to the Ben. But with the additional configuration setting for the JZ4720, which I called CPU_MIPS32_R1, it becomes possible to go around inside the kernel code and start to mark up places which need different instruction sequences for the Ben, using CONFIG_CPU_MIPS32_R1 as the symbol corresponding to this setting in the code itself. There are places where this new setting will also change the compiler’s behaviour: in kernel/fiasco/src/Makeconf.mips, the -march=mips32 compiler switch is activated by the setting, preventing the compiler from generating instructions we do not want.
For the board-specific functionality (found in kernel/fiasco/src/kern/mips/bsp/qi_lb60), I took the CI20’s collection of files as a starting point. Fortunately for me, the Ben’s JZ4720 and the CI20’s JZ4780 are so similar that I could, with reference to Linux kernel code and other sources of documentation, make a first effort at support for the Ben by transcribing and editing these files. Some things I didn’t understand straight away, and I only later discovered what some parameters to certain methods really mean.
But generally, this work was simply a matter of seeing what peripheral registers were mentioned in the CI20 version, figuring out whether those registers were present in the earlier SoC, and determining whether their locations were the same or whether they had been moved around from one product to the next. Let us take a brief look at the registers associated with the timer/counter unit (TCU) in the JZ4720 and JZ4780 (with apologies for WordPress converting “x” into a multiplication symbol in some places):
| JZ4720 (Ben NanoNote) | JZ4780 (MIPS Creator CI20) | ||||
|---|---|---|---|---|---|
| Registers | Offsets | Size | Registers | Offsets | Size |
| TER, TESR, TECR (timer enable, set, clear) | 0x10, 0x14, 0x18 | 8-bit | TER, TESR, TECR (timer enable, set, clear) | 0x10, 0x14, 0x18 | 16-bit |
| TFR, TFSR, TFCR (timer flag, set, clear) | 0x20, 0x24, 0x28 | 32-bit | TFR, TFSR, TFCR (timer flags, set, clear) | 0x20, 0x24, 0x28 | 32-bit |
| TMR, TMSR, TMCR (timer mask, set, clear) | 0x30, 0x34, 0x38 | 32-bit | TMR, TMSR, TMCR (timer mask, set, clear) | 0x30, 0x34, 0x38 | 32-bit |
| TDFR0, TDHR0, TCNT0, TCSR0 (timer data full match, half match, counter, control) | 0x40, 0x44, 0x48, 0x4c | 16-bit | TDFR0, TDHR0, TCNT0, TCSR0 (timer data full match, half match, counter, control) | 0x40, 0x44, 0x48, 0x4c | 16-bit |
| TSR, TSSR, TSCR (timer stop, set, clear) | 0x1c, 0x2c, 0x3c | 8-bit | TSR, TSSR, TSCR (timer stop, set, clear) | 0x1c, 0x2c, 0x3c | 32-bit |
We can see how the later product (JZ4780) has evolved from the earlier one (JZ4720), with some registers supporting more bits, exposing control over an increased number of timers. A lot of the details are the same, which was fortunate for me! Even the oddly-located timer stop registers, separated by intervals of 16 bytes (0x10) instead of 4 bytes, have been preserved between the products.
One interesting difference is the absence of the “operating system timer” in the JZ4720. This is a 64-bit counter provided by the JZ4780, but for the Ben it seems that we have to make do with the standard 16-bit timers provided by both products. Otherwise, for this part of the hardware, it is a matter of making sure the fundamental operations look reasonable – whether the registers are initialised sensibly – and then seeing how this functionality is used elsewhere. A file called tcu_jz4740.cpp in the board-specific directory for the Ben preserves this information. (Note that the JZ4720 is largely the same as the JZ4740 which can be considered as a broader product category that includes the JZ4720 as a variant with slightly reduced functionality.)
In the same directory, there is a file covering timer functionality from the perspective of the kernel: timer-jz4740.cpp. Here, the above registers are manipulated to realise certain operations – enabling and disabling timers, reading them, indicating which interrupt they may cause – and the essence of this work again involves checking documentation sources, register layouts, and making sure that the intent of the code is preserved. It may be mundane work, but any little detail that is not correct may prevent the kernel from working.
Covering the Ground
At this point, the essential hardware has mostly been described, building on all the work done by others to port the kernel to the MIPS architecture and to the CI20, merely adding a description of the differences presented by the Ben. When I made these changes, I was slowly immersing myself in the code, writing things that I felt I mostly understood from having previously seen code accessing certain hardware features of the Ben. But I knew that there will still some way to go before being able to expect anything to actually work.
From this point, I would now need to confront the unimplemented instructions, deal with the memory layout, and figure out how the kernel actually gets launched in the first place. This would also mean that I could no longer keep just adding and changing code and feeling like progress was being made: I would actually have to try and get the Ben to run something. And as those of us who write software know very well, there can be nothing more punishing than being confronted with the behaviour of a program that is incorrect, with the computer caring not about intentions or aspirations but only about executing the logic whether it is correct or not.
Porting L4Re and Fiasco.OC to the Ben NanoNote (Part 1)
March 21st, 2018
For quite some time, I have been interested in alternative operating system technologies, particularly kernels beyond the likes of Linux. Things like the Hurd and technologies associated with it, such as Mach, seem like worthy initiatives, and contrary to largely ignorant and conveniently propagated myths, they are available and usable today for anyone bothered to take a look. Indeed, Mach has had quite an active life despite being denigrated for being an older-generation microkernel with questionable performance credentials.
But one technological branch that has intrigued me for a while has been the L4 family of microkernels. Starting out with the motivation to improve microkernel performance, particularly with regard to interprocess communication, different “flavours” of L4 have seen widespread use and, like Mach, have been ported to different hardware architectures. One of these L4 implementations, Fiasco.OC, appeared particularly interesting in this latter regard, in addition to various other features it offers over earlier L4 implementations.
Meanwhile, I have had some success with software and hardware experiments with the Ben NanoNote. As you may know or remember, the Ben NanoNote is a “palmtop” computer based on an existing design (apparently for a pocket dictionary product) that was intended to offer a portable computing experience supported entirely by Free Software, not needing any proprietary drivers or firmware whatsoever. Had the Free Software Foundation been certifying devices at the time of its introduction, I imagine that it would have received the “Respects Your Freedom” certification. So, it seems to me that it is a worthy candidate for a Free Software porting exercise.
{kind=link}
The Starting Point
Now, it so happened that Fiasco.OC received some attention with regards to being able to run on the MIPS architecture. The Ben NanoNote employs a system-on-a-chip (SoC) whose own architecture closely (and deliberately) resembles the MIPS architecture, but all information about the JZ4720 SoC specifies “XBurst” as the architecture name. In fact, one can regard XBurst as a clone of a particular version of the MIPS architecture with some additional instructions.
Indeed, the vendor, Ingenic, subsequently licensed the MIPS architecture, produced some SoCs that are officially MIPS-labelled, culminating in the production of the MIPS Creator CI20 product: a development board commissioned by the then-owners of the MIPS portfolio, Imagination Technologies, utilising the Ingenic JZ4780 SoC to presumably showcase the suitability of the MIPS architecture for various applications. It was apparently for this product that an effort was made to port Fiasco.OC to MIPS, and it was this effort that managed to attract my attention.

The MIPS Creator CI20 single-board computer
It was just as well others had done this hard work. Although I have been gradually immersing myself in the details of how MIPS-based CPUs function, having written some code that can boot the Ben, run a few things concurrently, map memory for different processes, read the keyboard and show things on the screen, I doubt that my knowledge is anywhere near comprehensive enough to tackle porting an existing operating system kernel. But knowing that not only had others done this work, but they had also targeted a rather similar system, gave me some confidence that I might be able to perform the relatively minor porting exercise to target the Ben.
But first I felt that I had to gain experience with Fiasco.OC on MIPS in a more convenient fashion. Although I had muddled through the development of code on the Ben, reusing existing framebuffer driver code and hacking away until I managed to get some output on the display, I felt that if I were to continue my experiments, a more efficient way of debugging my code would be required. With this in mind, I purchased a MIPS Creator CI20 and, after doing things with the pre-installed Debian image plus installing a newer version of Debian, I set out to try Fiasco.OC on the hardware.
The Missing Pieces
According to the Fiasco.OC features page, the “Ci20” is supported. Unfortunately, this assertion of support is not entirely true, as we will come to see. Previously, I mentioned that the JZ4720 in the Ben NanoNote largely implements the instructions of a certain version of the MIPS architecture. Although the JZ4780 in the CI20 introduces some new features over the JZ4720, such as a floating point arithmetic unit, it still lacks various instructions that are present in commonly-used MIPS versions that might be taken as the “baseline” for software support: MIPS32 Release 2 (MIPS32r2), for instance.
Upon trying to get Fiasco.OC to start up, I soon encountered one of these instructions, or at least a particular variant of it: rdhwr (read hardware register) accessing SYNCI_Step (the instruction cache line size). This sounds quite fearsome, but I had been somewhat exposed to cache management operations when conjuring up my own code to run on the Ben. In fact, all this instruction variant does is to ask how big the step size has to be in a loop that invalidates the instruction cache, instead of stuffing such a value into the program when compiling it and thus making an executable that will then be specific to a particular processor.
Fortunately, those hardworking people who had already ported the code to MIPS had previously encountered another rdhwr variant and had written code to “trap” it in the “reserved instruction” handler. That provided some essential familiarisation with the kernel code, saving me the effort of having to identify the right place to modify, as well as providing a template for how such handlers should operate. I feel fairly competent writing MIPS assembly language, although I would manage to make an easy mistake in this code that would impede progress much later on.
There were one or two other things that also needed fixing up, mentioned briefly in my review of the year article, generally involving position-independent code that was not called correctly and may have been related to me using a generic version of GCC instead of some vendor-modified version. But as I described in that article, I finally managed to boot Fiasco.OC and run a program on top of it, writing the output via the serial connection to my personal computer.
The End of the Very Beginning
I realised that compiling such code for the Ben would either require the complete avoidance of floating point instructions, due to the lack of that floating point unit in the JZ4720, or that I would need to provide implementations of those instructions in software. Fortunately, GCC provides a mode to compile “soft-float” versions of C and C++ programs, and so this looked like the next step. And so, apart from polishing support for features of the Ben like the framebuffer, input/output pins, the clock circuitry, it didn’t really seem that there would be so much to do.
As it so often turns out with technology, optimism can lead to unrealistic estimates of how much time and effort remains in a project. I now know that a description of all this effort would be just too much for a single article. So, I will wrap this article up with a promise that the next one will descend into the details of compilers, assembly language, the SoC, and before too long, we will get to see the inconvenience of debugging low-level software with nothing more than a framebuffer.
The Noble Volunteer (Again)
March 11th, 2018
I saw that the usual refrain of “we’re all volunteers here” had another outing on a recent LWN article about the Python 2 to 3 transition, specifically referring to who it is that supposedly does all the core development work on CPython (as well as constantly changing what the Python language is meant to be). There are a few different observations to be made here, so let me establish three main topics:
- The funding of Python implementation development.
- The hiring of various Python core development contributors.
- Python and Free Software as a hobby or spare time effort.
I have written about how the Python Software Foundation raises and spends money before. For the most part, nothing has changed since then: the PSF appears to raise and then spend hundreds of thousands of dollars every year (apparently down from over $300000 in 2016 to under $250000 in 2017, though), directing this money mostly towards events and promotion. In fact, the largest contribution to core-related Python software development in 2017 was actually from the Mozilla Open Source Support programme, with a $170000 grant to fix up the Python Package Index infrastructure. So the PSF is clearly comfortable leaving it to others to fund the P in PSF.
Lots of people depend on the Python Package Index, but like with Free Software in general, the people making good money while leaning on these common, volunteer-run resources never seem to pitch in significantly themselves. It is true that the maintainer of this resource was allowed to work on it as his day job, but then got “downsized”, and now works in a role where he can work on it again but only as part of his day job. But I imagine that the people at Mozilla, some of whom have connections to the world of Python packaging, quite possibly relying on the package infrastructure to get their own stuff done, were getting fed up with “volunteers” as being the usual excuse for nothing getting done.
Now there certainly are Python core developers who are employed in work that influences CPython development or that has some connection to Python, perhaps related to other implementations of Python. Notably, Pyston and Pyjion were both developed by core developers working at Dropbox and Microsoft respectively. Famously, Guido van Rossum, Python’s originator, was hired by Google and then Dropbox, seemingly being able to dedicate some of his time on Python topics as part of his day job at both places. After all, it was during Van Rossum’s time at Google, accompanied by other Google-employed Python core contributors, that Python 3 started to take shape.
So it seems that some very large companies recognise the value that Python brings, they even hire influential people in the Python core development community, but maybe this does not translate to proper corporate support for Python core development. It could very well be the case that most of these people really do have to write Python code in their day jobs but cannot direct much or any time towards developing Python – the implementations or the language – in their working hours. They would be volunteers in their own time, albeit volunteers facilitated by their employment, having the stability of a relatively well-paid job and the good fortune of having Python core development as a productive and hopefully rewarding hobby.
Maybe it suits everyone being paid as a result of their reputation in the Python community to indulge in core development as a hobby. But what about everyone else? All those other volunteers who are doing the donkey work of testing and fixing the code when it stops working for them, implementing things that others have deemed a good idea, making Python 3 a reality, or whatever? Well, I suppose they get “pizza and beer soda” paid for by the PSF at their sprints.
In certain circles, it seems that a lot of effort is spent promoting a lifestyle that involves feel-good “volunteerism” and getting your name known through selfless volunteering. If you are one of those “other” volunteers, maybe the ultimate goal is to have the senior hobbyists in the community recommending you to their employers, which would explain how Python core developers seem to cluster in various companies. Maybe this is the new “open source” dream: not actually being paid to work on Free Software but merely pursuing it as a hobby, dependent on an employer for the lifestyle but not influenced by them, at least not conspicuously, retaining the ability to play the volunteer card.
And this leads me to a more general observation that came to mind when reading a remark by someone trying to establish a viable enterprise, all for the benefit of Free Software and open hardware. It was about how he was on the ground, doing all the legwork, opening up new opportunities the hard way while people in their comfortable jobs let him get on with it, throwing pennies his way and waiting for their substantial but cheaply-acquired rewards. Now, in that particular instance my sympathy is muted, for various reasons that hopefully do not need a public airing, but I see the point being made and, once you are aware of it, it is an annoyingly familiar one.
You will often see people inviting others to contribute to their projects, writing things like “how about someone fix this, make this better, implement this, do this?” It sounds so constructive, so worthy, like you can make a difference. In Norwegian, there’s even a word for the spirit of this kind of thing – “dugnad” – which is awkward to translate to English, but it effectively denotes an event or general activity where everyone pitches in collectively to get something done in a way that is relatively painless for each participant. Being a cynic, I would often translate “dugnad” as to be too cheap to pay to get something done properly.
What can be even more galling is that people “howabouting” potential contributors are not only comfortable hobbyists, but some of them also solicit donations for their hobby, not because they need the money but because it might cover a few beers or pizzas, some entertainment, or whatever. And so, a notion is cultivated that everything can be done by voluntary effort, that the value of such work is effectively “beer money”, and with the likes of the PSF not willing to put its own money the way of its own technology, people start to think that if “pizza and beer soda” is enough to improve a Free Software product, why would anyone want to pay people real money to improve it?
And so the notion of the volunteer, so noble and selfless, actually cheapens the value of the work that has to be done. Why bother paying for Free Software or for anyone to work on it when the noble volunteers will get it done? The answer, of course, is that people typically don’t and so the important things typically don’t get done, either. Still, at least the hobbyists get to have some fun.
A Timely Example
In another comment on the referenced article, discussing the general Python 3 strategy and whether anyone who had criticised it might have been worth listening to, it was noted that such critics might be like a “broken clock”: wrong most of the time but coincidentally right on certain occasions. I guess that for those who don’t like to hear criticism of the Python 3 masterplan, I could be one of those broken clocks, having criticised the introduction of Python 3. But if as the saying goes “a broken clock is right twice a day”, maybe some of my other criticisms are also worth taking a look at: one of them is probably good.
Of course, it hardly requires special predictive powers to note that people with large investments in existing code might not like being told that it is “good for them” to have to rewrite it all. And it is hardly a surprise that people have been motivated to look at other languages partly as a consequence of that, partly because of Python’s lack of direction or progress on other fronts, as language evolution dominates over all other concerns.
Spare a thought for Guido van Rossum whose colleagues, no matter where he works, always seem to end up writing software in Go instead of in the language that presumably got him through the door. Perhaps things wouldn’t have played out that way if those benefiting from Python had also properly invested in it, instead of leaving it for the hobbyists or using “we’re all volunteers” as an excuse for not keeping Python competitive with other emerging languages and technologies.
Some Updates
I was recently contacted by Sumana Harihareswara who asked for me to clarify that the proposal for improving the Python packaging infrastructure was initiated within the PSF’s Packaging Working Group, not by Mozilla, at least as far as available information would suggest. As someone involved with this working group, Sumana appears to be in a position to make claims about this more authoritatively than I can.
Meanwhile, an invitation to a PSF-related sprint that I happened to see today advertises “an amazing evening of coding, pizza and beer”. Having read a gushing endorsement of “dugnad” culture only recently – a classic promotional piece for readers outside Norway – I cannot help but observe that putting the burden for things onto the voluntary sector, so that the state can save money (to give as tax cuts to the wealthy) and so that the private sector can get something for nothing (to maximise shareholder returns), is rather a pervasive and not-so-noble phenomenon that will readily document itself to anyone paying enough attention.