Paul Boddie's Free Software-related blog
Paul's activities and perspectives around Free Software
The Atomisation of Society
April 26th, 2026
Just as it always was, and just as it also was with the Bitcoin and Blockchain fads, artificial intelligence is back in vogue, and now we must suffer hearing about “AI” all the time, shoehorned into everything technological and plenty of other things besides. I can hardly be in a minority in finding it all tiresome and even somewhat disheartening.
Of course, artificial intelligence is a broad discipline, and there are useful technologies doing useful work that may have been reported with varying levels of hype over the course of recent history. Over the last decade or so, machine learning has received a degree of media attention, often doing things related to mundane topics like pattern recognition, supporting applications in worthy domains such as medicine. Interestingly, activities like machine translation and visual object recognition are increasingly taken for granted by wider society, despite being problems that were once considered difficult to solve or tackle reliably.
If worthy domains are not your thing, and your phone is the centre of your life, you might be able to point it at some foreign language text and see it appear, magically translated, in a language you might understand. But this mostly isn’t what the current wave of “AI” hype is all about, even if such relatively useful applications are used to greenwash that hype.
Has your Internet search experience degraded to the point of near uselessness? Worry not: you can now be distracted by something pretending to be intelligent feeding you some misinformation instead. Never mind that an improved search experience, yielding useful, informative results was well within the technological grasp of the well-resourced corporations involved. Boring old part-of-speech tagging, maybe some semantic networks, and a bit of traditional information retrieval technology could go a long way. But, of course, that wouldn’t perpetuate the predatory advertising-fuelled surveillance economy or attract billions of speculative investment dollars.
In Britain, it isn’t enough to saddle the National Health Service with market economics, layers of bureaucracy, and numerous consultants and consultancies siphoning off considerable sums at the taxpayer’s expense, all as the fundamental challenges of the service’s information systems – and core activities – remain undiminished. Now, “AI” will drift in, touted by commercial opportunists and predators, new and old, alongside “data science” practitioners aiming to exploit private health information for their own benefit.
And as if by magic, new “efficiencies” will supposedly result. Never mind that without fixing the bread-and-butter issues, no amount of smoke and mirrors can deliver the magic envisaged. But, of course, it is far easier to wish away one’s problems than to confront them, especially if there are commercial interests with products and services to sell. Why not delegate hard problems to some supposedly all-knowing, all-understanding entity that will magically understand all those things for which the impatient politician or manager simply has no time (or intellectual stamina)?
It is also apparently not enough to saddle educators with extra responsibilities that in a well-organised society would be the task of social and healthcare workers and, in some situations, that of police outreach workers and the police service itself, all as funding is perennially slashed in the education sector. Instead, policy-makers sing tunelessly from the “AI” cult’s songsheet, fuelling yet another corrosive societal problem and, as always, dumping the consequences in the laps of educators for “careful consideration”. And, of course, the welfare of the students barely registers on the conscience of those policy-makers as they perform their victory lap.
As Winter Follows Summer
For the most part, the “AI” in the latest round of hype is that most easily understood by, or most relatable to, the average media commentator. It is the gadget that generates written or visual content as if it were some kind of creative being. For their managerial counterpart with the job title incorporating the dishonestly chosen words “customer satisfaction”, the hammer in their toolbox marked “chatbot” is thus the “go to” tool for every digital transformation job, just as it was in the early 2000s for organisations looking to somehow “deepen” the level of interaction with their customers.
Amusingly, many of today’s corporate chatbots are largely the same kind of keyword-scanning “choose an option” counterparts to the classic phone menu as their predecessors were. The most likely reason for this is that the much-hyped large language models, exposed to querying from random people on the Internet, risk incurring reputational damage to any given hapless organisation as they go off-script and start to parrot “poorly sourced” training data, to put it charitably, of which there may be quite a bit.
And it is the matter of what is used to feed the “AI” monster that should concern those of us in Free Software and every other industry that creates content. It is here that we find out who are allies are, who is really committed to a free and fair society, and who it is that instead chooses to betray us. Unsurprisingly, those who betray us are largely the same group as those who, once employed by a “rich uncle” in the form of some corporate behemoth dangling incentives and a comfortable lifestyle, try to explain away the problematic behaviour of that rich uncle. Worse still, they tend to demand the silencing of any uncomfortable criticism of either the behemoth or themselves in their sordid pact.
You will find these people regularly trolling others in any venue where comments may be left to supposedly discuss the headline content, basking in their privilege and telling everybody else what little everybody on the outside really knows. As layoffs roll in across the technology sector once again, it remains to be seen whether the enthusiasm for defending some corporation’s questionable ethical record remains buoyant or whether there might be some buyer’s remorse amongst those who took the easy money. But of course, these people will glide through another gilded door, ushered in by some other member of the old boys’ network. After all, some of them have been trying to undermine Free Software for years.
This time round, the layoffs are justified by management using the very thing that the corporate apologists seek to defend. Perhaps the most enthusiastic apologists for “AI” have not been shown the door just yet, but plenty of their colleagues have. Then again, there are plenty of people who see a harmful phenomenon and think: “That could never happen to me!” After all, they are the special ones. They might concede that something has come along to “shake up” the industry, but as the special ones, they are the ones who will adapt, who will turn this disruptive force into their “competitive advantage”.
In any online discussion related to “AI” and the software industry, you can expect to read the same old guff. Some self-proclaimed top-flight developer will tell everyone how much “more productive” they are by getting “AI” tooling to generate all those unit tests that they previously had to write by hand. Never mind that their claimed “insane level of productivity” is tempered by their own admitted need to review the slop created for them, a result of them describing their needs in “plain English” when it has been known for decades that the definition of a functional specification for a piece of software, especially when done in a natural language, is one of the harder tasks in systems development.
Many of these people will claim that this lets them “spend more time on the creative part” of their job, never mind that the kind of person who writes such drivel is usually the kind of person that most observers would struggle to categorise as creative. But their advocacy for systems that systematically trawl other people’s work, undergo “training” on it, and transform it for eventual regurgitation in a hopefully distinct and thus plausibly “original” form, and their sudden enthusiasm for the creative side of their work, will find its reward in the end. After all, creative jobs have been amongst the first to be eliminated in this new wave of “AI”, as managers (aping their tech idols) declare that graphic designers are no longer needed, just as I learned in one enlightening, spontaneous conversation a year and a half or so ago, or as anyone can discover just by following the news.
Your manager will surely not care how much more quickly all those unit tests are getting written – not that they cared before, exactly – nor will they value your “creativity” when the latest toy is dangled in front of them promising to do your job. Your peers will not care about any kind of epiphany you have, either. They will still be the special ones and you, like the rest of us, just jealous of their success. You will have had your chance to change the world for the better, and you will have blown that chance.
The Hoarding of Privilege
One might think that technologists might be attuned to the perils of technology for themselves and society, but one should never underestimate the lure of selfishness and self-interest, of not wishing to know about any negative consequences of their work or their interests. As one might expect, solidarity is the first casualty.
One sees talented developers who have spent their entire career writing their own code, tinkering with “AI” coding tools and enthusing about the output, wasting other people’s time pontificating about why the assembly language generated for some 8-bit microprocessor isn’t as plausible as a Python script for a task solved independently hundreds of times and published to the Internet every single time. One sees talented developers make nice new applications, only then to go off and use “AI” for the artwork or for other “creative” elements of the work.
They might say that they aren’t talented enough to do those tasks themselves, so they can justify delegating them to a machine. Maybe they just want something that fills the gap, or maybe they don’t want to pay for such work. But even if everyone is doing of all this for fun and for free, why do they not involve others in their creative exercise, people who might be able to draw pictures or write prose?
It sounds to me that they just do not value such creative endeavours or the role of those in society who are talented enough pursue those endeavours. And as they hit up “AI” to conjure up some art, featuring a particular subject, done in a particular style, they perhaps purposefully neglect the creators of the works that fed the “AI” in the first place: those very same people they breeze past as they go and hit all the buttons.
It must be so wonderful to be in a position of having made plenty of money in a profession that was once valued, maybe even lucrative, to now be able to check out for the rest of one’s career. To pull up the ladder on the next generation, eliminate their opportunities, and to indulge in that time-old practice of berating them for being lazy and not good enough. To indulge in “vibe coding” personally, maybe even promote it educationally, but then to label as decadent all recent practitioners in one’s own profession, simply not made of the same stuff as folk were in the “good old days”.
One encounters people who say that they are glad that they are retired or will soon be retiring. For some of them, this may be a legitimate reaction to an increasingly tiresome and possibly even hostile workplace culture, looking forward to some well-deserved relief tinged with remorse for a vocation that no longer delivers the satisfaction it once did. For others, it just sounds like they are content to leave the world in a worse state than it was, and to abandon the job of reversing this damage to subsequent generations: hardly an isolated occurrence in the modern era.
It can be all too easy for people to downplay the effects of new technologies, often with claims that appeal to ideas about “human nature”. As children go through their entire childhood exposed to technologies that are inadequately supervised and often exploitatively designed, some might claim that schoolchildren or students seeking to cheat on their assignments “isn’t a real issue”. And with this, we are presumably supposed to move on. But anyone who knows any teachers will also know that plagiarism is very much “a real issue”, both for students and teachers.
With ready access to online tools, even encouragement to use them, the temptation is too strong for many students, particularly those who have been struggling throughout their education. With a diminishing incentive to learn, and besieged by social pressures amplified by technology, plagiarism starts to look like all they have left in their arsenal. When we hear stories about disengaged young people and their apathy, imagine being the person who has to try and motivate these young people, especially when it seems like every last person with influence over this situation has abandoned everyone affected.
And plagiarism is, in fact, such an issue that Microsoft, having flooded the zone with “AI” toys, offers other toys to detect plagiarism. There is good money to be made by escalating a situation into a conflict and equipping both sides, as those in certain other professions and industries know all too well. I have read tales of educational institutions being infatuated with “AI” to the point of rolling it out, often excused in numerous ways, but mostly amounting to someone in a position of power wanting to try all the toys.
(And given that school administrations are routinely surrendering their classrooms to gambling industry practices and data surveillance predators, “AI” probably does seem like just another fun toy to play with.)
I have heard tales of decision-makers and executives trying to mitigate the harmful effects of their decisions, related to “AI” and otherwise, by leaning into the consumerisation of education and seeking to wave through students who may have resorted to plagiarism. Students who just want the piece of paper, so that they can get on all those celebrated ladders of society – good employment, decent housing – before they are pulled up and out of reach entirely.
But what will become of such students when they move on to the next stage of their education or development, increasingly out of their depth, feeling less and less adequate, confident, fulfilled or secure in their own existence? At what point do we justifiably label the abdication of responsibility, by those in authority and those who seek to profit from such misery, the abuse that it arguably is?
When society fails to protect its members as they grow up, how can those in privileged positions criticise people, overwhelmed and desensitised by torrents of increasingly harmful content, for not participating in or engaging with society? Maybe those elected and appointed to protect our interests could do exactly that, instead of looking out only for themselves and the vested interests who have been lining their party’s pockets.
Quality Uncontrolled
One potentially common element in the workplace and the classroom is how each group perceives the materials they encounter, along with their attitudes towards the cultural works of their own society. For children growing up in earlier times, one might expect the consumption of books, magazines, newspapers, television series, films, popular music and other such works to have played a defining role in their perception of culture and its value.
But after years of relentless and cynical commercialisation, children have increasingly been growing up in an environment of relentlessly derivative entertainment content. Instead of new and original stories, endless comic book franchise reboots and the like, largely to keep trademarks and other “intellectual property” warm and out of the public domain, may have habituated people to expect less and less from culture and to place a lower value on it.
Instead of being engaged by cultural works, those works become mere wallpaper, something to have on in the background while other, more harmful, forms of engagement steal the attention of the viewer or listener. And with their perspectives and beliefs unengaged and unchallenged by mainstream culture, people risk being sucked into a bubble all of their own, all too readily and easily fed by “AI”, reinforcing their flawed views and pandering to their prejudices.
Why would you want “AI” to generate content for your own consumption? Habituated to having one’s favourite superhero meet and/or fight one’s other favourite superhero in endless re-runs of generic, commercial filler, it isn’t such a big step to go on and have one’s tummy rubbed all the time by unchallenging and probably inaccurate content that happens to appeal to one’s existing biases, now readily produced in bulk and on demand by “AI”.
For some of us, the process of creating something new is part of the eventual reward, and the process of researching, understanding and communicating something is engaging all by itself. But the degradation of culture to a mere consumable risks the marginalisation or even eradication of the creative process, the investigative process, of historical and critical enquiry, all so that people can be soothed and entertained.
There is a relatively well-known quote about AI being supposed to free up a person’s time for pursuing their art by taking care of the cleaning and the laundry, but instead “AI” has made them and their art redundant and leaves them with the cleaning and the laundry. What might this have to do with the workplace? Well, to answer that, we have to address the phenomenon of the software product and its gradual erosion.
Angst or Realism?
When the well-known technologist Tim Bray raised the issue of “AI Angst“, alongside broader issues, the accompanying off-site discussion of the article predictably featured the usual consumerist “works for me” and aspirational “more productive” tropes. But it also exposed the sentiment that “AI” is also quite able to take the joy and the motivation out of doing work and being in a profession. Amongst those who had the most enthusiasm for vibe coding were claims that only “5% to 20% of the work is interesting” in a modern programming job. So, what does that say about the state of the industry?
One factor might be that industry is subject to a continual inundation of fads and trends often imposed on the profession from outside, facilitated by opportunists who can persuade management and executives of productivity boosts and reductions in expenditure. But another thing is that enthusiasm for “AI” is evidently higher amongst those whose development has a high level of “donkey work”. This leads to a pertinent question: have technologists failed their profession by perpetuating cumbersome, inadequate technologies?
If you have ever had to work with certain widely available, well-resourced software available today, you will be familiar with the sensation of having to seek advice or guidance on how some aspect of the software works or is to be used, only to discover that there is no documentation or that the standard of documentation is so dismal, that one can only wonder how people have allowed such software to be used so widely and in such critical applications in the first place. Not that wondering about it is in any way helpful.
Over the years, various remedies have been thrust onto the scene, from plain old Internet search hoping to dig up some gems of wisdom, discussion forums aspiring to provide relief to adherents of particular technologies, and the now-familiar question-and-answer site concept popularised by the likes of Stack Overflow and its affiliates. But alongside the frustration that inadequate documentation may bring is the frustration and general disillusionment of having to continually ask questions, sometimes relying on vain, petulant and uncooperative individuals, that should have been definitively answered long ago, with those answers recorded coherently for posterity in actual documentation.
We might then understand why some people could be tempted to use “AI” chatbots, desperately trying to get insight into things that should have been made clear by actual human beings in the first place. The chatbot might be misleading or counterfactual, but it is probably going to act somewhat cooperatively, not shame the user about their lack of knowledge, or withhold information to coerce a form of deference. Well, at least not yet, anyway.
This sorry situation is a consequence of the way the software industry has been heading over the last few decades. Under the banner of agility, competitiveness, and that crucial “time to market”, forever to be optimised and minimised, things like documentation are critically undervalued. “Read the code!” exhorts one techbro to the other, advocating the complete elimination of any commentary, deemed unnecessary because “the code is the documentation” and because what they coded was obvious to them when they were “in the zone”.
Never mind that the commentary would have revealed the intended behaviour of the code, along with the deficiencies of the code that was actually written. But, of course, no-one had any time for that, let alone any time for writing a coherent guide to the software, its architecture, and how other people might interact with it in various ways as users of different kinds and developers needing to fix and extend that code. All of that stuff was low-end work according to the techbro, as are other kinds of programming that they do not personally value. (Still, the collision of the butch “rewrite everything in Rust” brigade and “AI” can still provide some entertainment and maybe an occasional reality check.)
It also does not help that documentation has joined the other facets of development in being subjected to various technological and methodological fads that do more to create opportunities for certain industry players, as opposed to improving the quality and breadth of material available. Just as one’s heart sinks as the primary source of guidance for a project turns out to be a GitHub repository page, so it does when one encounters a documentation site that was produced by Sphinx, with plenty of hastily scribbled sections littered with “admonishments” and caveats.
Tim’s use of the term “angst” rightfully received a strongly worded response from one commenter, not least because labelling people’s reactions as if they were those people’s weaknesses in having to respond to seemingly overwhelming pressures is what Tim might himself regard as victim blaming. Tim seems like a generally good guy with a great deal of self-awareness, but I imagine that his position in the industry, along with that of elements of his readership, some probably having done very nicely indeed from their tenure at various West Coast behemoths, makes the general demographic less than reflective when they lament the shocking lack of alternatives to their favourite cloud services.
To an extent, it is a bit like former politicians who take on moral causes after their positions in power are over and as their influence steadily diminishes. Where were they when other people needed their help in furthering those causes? When adjustments to policy, so easily done, might have made a significant difference. Similarly, with Free Software and the provision of sustainable, ethical technology more broadly, the dominant ideology promoted vigorously by West Coast capitalism often seems to involve discretionary support to worthy causes by wealthy people, many of whom did just fine while those worthy causes were kept marginalised, and when various structural causes of inequality, noted by Tim himself, were conveniently ignored because that would involve wealthy people paying a bit more tax.
The Idiocracy
There is always some idiot who pipes up in online discussions about how they asked some chatbot about some topic, “and it said this”. It is almost like they want a prize for having done something that anyone else could have done. And what does this kind of “idle wondering” usage of chatbots, indulged by the consumption of colossal amounts of electricity, actually serve? If anyone were really interested in a topic, and were to have the knowledge and understanding to actually assess chatbot output, then they probably wouldn’t be using one in the first place.
That leaves the most likely kind of user as the sort of middle manager who doesn’t understand anything, who just pushes the paper on to someone who is supposed to “action” the information they were given. At what point is the human, relaying information they don’t understand to impress people about “what they know”, just a conduit for the activities of machines? And are they not then just a puppet participating in the game of assessing whether the machines are intelligent or not, abdicating their own genuine intelligence in the process?
To be fair to those wishing to put questions to machines and expecting some kind of summarised response, questions and other naturally constructed prose could conceivably help formulate more effective queries than simple combinations of keywords. The grammatical roles of words and the relationships between those words can disambiguate between the different meanings of some words and constrain the context of any particular search for information. Returning a summary that paraphrases the materials that were found might help in determining whether those materials happen to cover the right topics.
But what I discovered recently when being offered an “AI” search summary for a particular, highly specific, search term was the kind of thing people describe as hallucination. More accurately, though, it was more reminiscent of when a lazy student of a certain age, or someone who is “hustling” to impress their equally superficial superiors, states something as a fact, references a bunch of supposed supporting material, only for none of that material to actually confirm the fact or quote the term in question, let alone define that term as the thing confidently stated in their opening sentence.
Once upon a time, when machines were meant to be doing things that were described as “reasoning”, researchers were expected to show how the machine had worked through to its conclusion, revealing things like “facts” and “inferences”, and thus providing insights into the state of the machine’s encoded “knowledge base”. One would then be able to verify for oneself whether such a conclusion was sound or not. But now, it would seem, nobody really cares about accuracy or correctness, but only whether the damned machine has the right kind of “swagger” that would convince a room full of imbeciles with something that might sound credible enough to them.
And we are entering a time when we should be concerned about how people might readily check the correctness of “AI” queries. It was always bad enough when a search engine would produce results where the search terms didn’t appear in many of the results, even in a derived form, meaning that some “search engine optimisation” vulture had deceived the search engine with a bucket of false keywords stuffed somewhere into a page or site, but now the search providers have an excuse to push “AI search”.
Having trained their models on the bulk of the Web, they can then push out arbitrary “summaries” while deliberately obscuring the content that those models consumed. Thus, they can deny plagiarism by making source material difficult to find, while also omitting or excluding content that contradicts or refutes any dubious assertions or conclusions presented as fact by their services. They arguably don’t even have to try very hard to degrade the experience, giving the whole exercise the air of plausible deniability.
As with predatory social media, the training of “AI” also has considerable emotional costs for the people who are largely exploited in their work of having to train it. Not only are they not encouraged to properly correct disinformation, but they may not be suitably qualified to do so. After all, everyone can only be knowledgeable about so much. Having seen behind the curtain, their advice is not to trust it. For “AI” companies, hyping up their products, and to the idiocracy, the illusion of the perfect, shiny, all-knowing android has to be upheld at all costs, for the former so that the money can keep rolling in, and for the latter so that they can presumably look cleverer than they actually are.
The tiresome industry insider will criticise anyone suggesting that the average chatbot exhibits only superficial characteristics of intelligence, hand-waving towards mysterious models while playing the “you don’t know what I know” card, but it isn’t unreasonable to suggest that the whole phenomenon is barely above the level of a parlour trick. Does the chatbot really understand anything or do people just read meaning into what is effectively just banter? Is it merely a new Eliza for the disinformation age?
The Apologists
There are always plenty of people willing to pipe up when something that amuses or delights them is criticised in some way. One will undoubtedly encounter people who cosplay their fantasies of living in the future by infuriatingly using the term “an AI” in an unsarcastic and completely sincere way to refer to a system supposedly employing AI. In doing so, they effectively attribute general intelligence and even sentience to those systems. Criticise such sloppiness and you’ll get something like this in return:
“Nobody had any problem calling it artificial intelligence back when it was far less capable than it is now.”
Once again, such people fail to appreciate the distinction between artificial intelligence as a discipline and the promotion of the discipline in broader society, where despite the buzz in superficial media circles, applications of AI were often met with much skepticism. It was frequently obvious that the systems involved might have been exhibiting traits of ostensibly “intelligent” behaviour, but these systems could not be regarded as being intelligent in their own right or in a general sense.
Even with huge amounts of data and computing power brought to bear on such matters, chatbot output still has the smoke-and-mirrors character familiar from earlier demonstrations of the capabilities of AI. Sadly, popular culture is now configured to amplify the hype as opposed to deconstruct it. So, even pointing this out has people believing that researchers in earlier times would have been awestruck by today’s “AI” chatbots, when in fact they would almost immediately recognise the phenomenon. Indeed, they would be disturbed by the way society has embraced such technologies unquestioningly, perhaps observing that earlier demonstrations were mere laboratory experiments, potentially dangerous if they escaped and proliferated.
What has changed since those earlier times is the broader availability of computing power that delivers a more convincing “demo effect” of the technology. This makes decision-makers think they can dispense with humans and roll out the chatbots. Couple this with the way that the populace has been conditioned and manipulated in terms of expecting and accepting less from public services, private companies, their employers, in their careers, and in their lives more generally, and it is not surprising that people are consuming such technologies. Those who believe that they are only doing so recreationally are predictably dismissive about the negative effects on vulnerable people who might end up using such services because all of the responsible, humane options have been eliminated for the sake of “convenience”.
There is also the arrogance that people seek to exude of being more comfortable with technological change than the average person, even as they reveal their own insecurity about the nature of intelligence. To me, the idea that other creatures possess a range of intelligence is indisputable, and we are regularly presented with observations made about intelligence in the natural world, animal behaviour and cognition, that should merely confirm that we as humans are not quite as special as we might think. Many people engage constructively with such observations and show that they can readily accept notions of more pervasive intelligence in nature.
Meanwhile, the insecure but outwardly confident technophile presumably scoffs at the notion that, say, animals might employ forms of reasoning or possess forms of cognition or information processing that could rival those of humans. They would exhort others to not attribute “human” traits to other species, even as they readily ascribe fanciful characteristics to machines running mystery payloads of software, presumably because humans were involved in their creation.
Some apologists play the inevitability card, that this is simply another change following on from many that society has already absorbed and survived, and that this will somehow be digested, too, seeing society adapt and life go on as before. But here, even those who appreciate the challenges these technologies pose do not seem to understand the cultural and societal calculations that accompanied earlier forms of technological change. There are long-enduring cultures on this planet that have had social rules about the depiction of the human form for thousands, maybe tens of thousands of years, and yet our arrogant “modern” societies think we have nothing to learn from such cultures.
Again, the apologists might reveal their ignorance by scoffing at pigments, paints and dyes as technology, but they gave humans the ability to choose how they might be portrayed. We live in an age where the application of computational technologies may seek to eliminate any distinction between observed reality and precisely concocted fantasy in a way that is still scarcely believable even now. Fake pictures, video and audio can be presented as genuine representations and recordings of reality, leaving their audiences deceived.
Maybe older cultures did not need to see the emergence of such technology before they understood some fundamental social lessons that still remain unabsorbed by our supposedly “advanced” societies today. And while it might be said that perhaps those older cultures needed thousands of years to reach their own conclusions, we might also observe that our own societies do not have the luxury of thousands of years to tackle the effects of this corrosive fakery. This might even remind you of another pressing, existential threat to humanity.
One notable incident in this regard involved content creator Jeff Geerling, whose voice was cloned by a supplier of technology products to use in advertisements. Fortunately, the company in question backed down when challenged over the unlikely similarity of its synthesised voice to that of Geerling’s, and the incident was resolved relatively amicably and with incredible grace by Geerling himself. The incident highlighted the proliferation of such tools and their widespread availability for all kinds of applications.
Naturally, there are apologists for such tools, too, of the same school that presumably insists that nuclear weapons are not inherently bad, just how they might be used. Our societies show little sign of resilience in the face of such threats. Instead of robust legislation, regulation and education, we are left with the usual predictable media commentary about “scams” with various workarounds to “stay safe”. And, those same media outlets still promote the social media lifestyle, exhorting everyone to share their lives online and to feed the predatory social media monster.
The apologists might regard “AI” as harmless fun or empowering (to them), but there is an arms race in progress and an industry dealing in what might be described as information weaponry, building on the delivery mechanisms of predatory social media, to further degrade society’s resilience, making it impossible to trust voices, images, video and content. We might like to believe that we are the sophisticated ones, living in a “modern” society, in contrast to cultures where images of the human form are forbidden. One might wonder whether such rules are less about “taboos” – a culturally loaded term – and more about such societies having a fundamental realisation that our own societies fail to appreciate or understand, dismissing it with arrogant talk of our own “progress”.
Media coverage of “deepfake this” or “deepfake that” predictably circles around sensationalism, involving deceased celebrities if the audience risks being unmoved. But on a more ordinary level, is it progress to no longer be sure that the person sounding like or looking like a member of your family on the other end of a voice or video call really is that person? Is it progress to need a codeword to be somewhat sure?
And is it progress to only be sure if you are standing there in the same room as them, until the day when some ghoul, possibly one who has grown tired of monetising deceased celebrities, eventually introduces lifelike androids to impersonate random people? Even before that miserable day arrives, is it progress if some other ghoul decides to “deepfake” deceased relatives to torment those who are in mourning?
One of the more interesting contributions to the discussion about “AI angst” was that giving the Vatican’s view on “AI”, eliciting some considered responses. Naturally, the Catholic church is hardly the most popular institution for a variety of reasons, but one has to concede that on matters of theology and philosophy, on issues that shape humanity’s view of itself and its relationship with the natural world, the institution can hardly be considered to be staffed with lightweights, even if we might disagree – sometimes strongly – with its position on certain social issues.
Paying for Other People’s Privilege
As with many of society’s ills, one can always choose to metaphorically put one’s head in the sand and ignore those problems that mostly seem to only affect somebody else. Regardless of whether one does so, however, such problems have an annoying habit of landing in one’s lap, anyway. A few months ago, I got a mail from my hosting provider telling me that a “lot of traffic” visiting one of my sites was “causing excessive CPU usage and disruptive service for other customers”. Of course, this was due to a multitude of client addresses hammering my site – a repository browser – and crawling all over every last published resource.
It was suggested that I put my site “behind Cloudflare” since they offer various services to mitigate the effects of “bot” traffic, with my only guidance being a link to a blog about a service that Cloudflare offers. There was no guidance about what obligations towards Cloudflare I might have as a result, whether there might be payment involved, or whether Cloudflare might want or get something else from me, were I to sign up. In the end, I just put authentication in front of my site and re-enabled it, hoping that the bots would eventually give up if all they saw was the appropriate HTTP “authentication required” response.
Consumerists would point out that I’ve been doing all of this wrong, of course. Firstly, they would tell me that I should have moved my repositories to GitHub for the convenience of having Microsoft do the hosting and me paying nothing for the privilege. They would tell me that having GitHub suck all of my content into its “AI” consumption engine, for regurgitation to other users through their copyright laundering “AI” tools, is “no big deal” and that I should be happy to see my code used in so many other places. They would presumably purr about GitHub’s cumbersome and overworked user interface and its “collaborative tools” that, in classic Microsoft style, try and insert the service into everybody’s workflow.
But the end result of me not “going with the flow” and instead paying for the privilege of offering a service on my own terms, contributing to an independent hosting provider and keeping their business viable, allowing other interested parties access to my software, and generally trying to uphold my own privacy and those who wish to interact with me and my content, is that I and others who try and uphold our autonomy and defend our own interests are punished by the Internet equivalent of looters and pilferers. And the consumerist response involves an outcome that is not entirely unintended on the part of the Internet’s dominant corporate interests.
Just as it is rather convenient for the likes of Microsoft to promote “AI” tools in education, only to also offer “AI” plagiarism detection tools in their ubiquitous services, it also seems rather convenient that the degraded Internet environment, increasingly subverted to feed “AI” products, just happens to drive people towards services and platforms run by the Internet’s behemoths that offer “AI” products and services as part of their headline feature sets.
Naturally, such corporations would claim innocence of any random botnet involvement, rather like how conventional suppliers of physical products routinely claim ignorance of bad things in their supply chains, but ultimately the finger-pointing is of diminishing significance. If someone cried “gold” and now an entire landscape has been obliterated, does it matter who was driving which excavator as everyone piled in to make their fortune?
The coercion used by software companies and service providers to “opt in” customers and users is, of course, entirely deliberate. Their goal is to make everyone complicit in mass copyright infringement and, amplifying classic right-wing hypocrisy that appeals to “personal responsibility” yet weakens regulation and enforcement, normalise sentiments that “everybody is doing it” and so rule-makers should “not bother” trying to curtail antisocial behaviour.
Such collective antisocial behaviour affects Free Software in other ways. It causes a degradation of software quality and Free Software contributions, potentially for malicious purposes, grinding down contributors. All of this effectively conspires against independent, modestly-resourced Free Software projects, at the very least inhibiting or shutting down open collaboration, and at worst entirely eliminating such projects as alternatives to well-resourced corporate projects.
People may claim to be applying “AI” tools with the best of intentions, but those using the tools seem to be happy for them to blatantly plagiarise other works and then effectively mark their own exam, denying what is obvious to any moderately competent observer. Or in the ominous words of one such practitioner:
And, as we have seen before, the result is a degradation in Free Software offerings, of impaired desktop experiences, of inscrutable technologies promoted by vested interests and proliferated unquestioningly, and the continuing need for all of us who advocate Free Software adoption to apologise for the state of the software we recommend, as proprietary software companies cash in on the perpetual “lack of polish” or other deficiencies, perceived or real, of that software. Fewer and fewer viable choices remain, driving the average person into the arms of the monopolists, just as they always intended.
If nothing else, Free Software advocates should be pushing back hard against “AI” proliferation, but many of them won’t. I know to my personal cost what adhering to a set of principles entails, but many people are rather more flexible when it comes to following through on what they supposedly believe in. Free Software advocacy typically sits at the intersection of at least two professions: software development and legal practice. As software developers, plenty of people claim to understand the nuances of AI, readily telling you that you have it all wrong in your criticism of the technology.
And software practitioners are often frustrated by law practitioners and their inability to correctly perceive and interpret the nature of technology. Yet, if the legal profession has concerns about AI, why should other professions accept its use so unconditionally? But that is what people do: people who should know better, who claim expertise and the right to lecture others, and then somehow wave away any concerns because it suits them. When legal cases collapse due to “vibe lawyering”, justice may be denied and crimes may go unpunished. When software fails due to vibe coding, the effects risk being just as serious and, in some cases, even worse.
Practitioners, institutions and policy-makers seem to have, for their own reasons, an inability to confront awkward problems and the grind of getting the job done. Consider the case of a catastrophic data leak which imperiled thousands of people due to inappropriate tool usage and a lazy office culture where people couldn’t even be bothered to add two words to an e-mail subject line as the only, almost laughable, technical safeguard against data breaches.
When that becomes just another opportunity to peddle and to apply “AI”, it not only demonstrates that everyone responsible has effectively “checked out” and cannot be bothered to think very hard about the basics, despite the eager software practitioner’s tiresome refrain of “security!” in every technical forum they dignify with their presence. It also shows the ethical deficit these people have with the rest of the society and the people whose lives depend on their diligence. Because we know that “AI” will be just another scapegoat when things go wrong, excuses will be made, and the “vibe” will go on.
Lawmakers, meanwhile, seem infatuated with their new toy, as they also were with predatory social media, delighted to merely rub shoulders with indulged foreign oligarchs, potentially eyeing the possibilities of lucrative sidelines or post-political positions, instead of developing and furthering the interests of those that elected them to office. As has been the case with other topics of concern, notably software patenting, it seems that lawmakers can be very happy to listen to selfish commercial interests from beyond their electoral boundaries instead of the people they are supposed to represent. (Hint: “the south-west of England” is not the region one such lawmaker was elected to represent.)
Thus, blatant plagiarism, pilfering and infringement under the pretense of a “creative” act seems entirely reasonable to distracted lawmakers, never mind that letting some of the highest valued corporations on the planet have free and unencumbered access to the lucrative output of a nation’s supposedly prized creative industries is likely to plunge those industries into economic ruin. In the case of the United Kingdom, this would be only another chapter of the nation’s leadership stupidly squandering what remains of the cultural “soft power” that the nation once had, only instead of doing so to pander to the bigoted, the ignorant and the deceived, it would be to the kind of people who gladly facilitated that earlier deception.
Some might claim that “expanding copyright” to prevent “AI” misuse of content is wrong, noting that training activities are perfectly legal and justifiable (obviously ignoring the costs incurred by those of us who pay for our Web hosting), and likening the publication of a model to “publishing facts about copyrighted works”. But what about the publication of “AI”-generated works? The suggested “simple way” to “protect artists from AI predation” involves withholding the application of copyright to such works, preventing Big Content from monetising such works, and thus deterring Big Content from adopting “AI” and firing its creative workers.
While that sounds like a great economic “hack”, it doesn’t confront the broader phenomenon of the cheapening of content at all. Big Content has arguably already pivoted to technology, streaming, and the like, but even if they might suffer from such policies, it does not mean that creators will gain. There are plenty of “slop” creators out there today whose business models do not rely on asserting copyright for their works. Will manufacturers of weird jigsaw puzzles care? They just want a stream of free stuff to slap on their products, and what if someone clones them? Well, that was last season’s product.
Allowing the “AI” peddlers to consume and regurgitate copyrighted works without constraint, allowing them to circumvent copyright under the pretense of “creativity”, is still harmful even if the peddlers cannot “protect” those regurgitated works. If someone consumes a Free Software application or library, waves the magic wand of “AI”, and then publishes it, the mere availability of this dubious derivative cheapens the original software, undermines its licensing by steering potential users to a “public domain” clone, reduces incentives to continue developing the original software, and thereby reduces its viability. Flooding the zone with such slop may benefit corporations wanting to circumvent Free Software licensing, but it does not benefit Free Software.
The Atomisation
There are numerous social and economic threats from the introduction of technology under the banner of “AI” that might justifiably elicit a negative reaction from a lot of people. When such reactions are articulated, the response from “AI’s” cheerleaders tend to involve labelling them as “emotional”, “touchy” and “irrational”. Of course, this is just a cynical way of avoiding any kind of constructive discussion about the impact of the accompanying harmful economic agenda, reminiscent of all of the other shifts in industrial policy that left people disadvantaged and impoverished.
In previous transitions involving something that could be described as automation, there was always the chance that those whose manual work was eliminated by the introduction of machines might still benefit from the exercise. When the production of textiles or clothing was to be automated, for instance, there might conceivably have been work to be had in applying one’s expertise to the design of the machines themselves. And there might also have been a limit to the automation, preserving opportunities for those particularly skilled in those tasks beyond the capabilities of the machines.
But today’s enthusiasm for “AI” suggests that whole categories of jobs will be eliminated, that no-one will write code any more, or write prose, draw, paint, make music, and so on. And the intention of those setting this agenda is that there will not be any possibility of somehow migrating to either the automation side of this transition, especially since coding in “AI” companies is meant to be left to the “AI”, or to more specialised forms of paid labour.
Previous transitions were handled very poorly indeed. In Britain, the phrase “on your bike” was largely the economic strategy of the Thatcher government as it gutted various industries, effectively condemning regions of the country to underdevelopment, unemployment and hardship, exacerbating inequalities within the country and divisions that persist to this day. Those too young to know or to remember might recognise some of the cultural phenomena from that earlier time because we see them again now in similarly potent forms, not that they ever really went away.
The practice of “divide and rule” is used to pit disadvantaged and marginalised groups against each other, steadily degrading other sections of society to make them poorer, weaker and too concerned with their own survival to question the general direction of society. Foreigners, immigrants, those with health problems, those not blessed with wealth, those who have otherwise experienced misfortune that blights their lives, and others are conditioned to expect less from their own lives, to feel guilty about their own situation and for needing or expecting help, or even asking for it.
Accompanying this is the promotion of “charity” and demonisation of taxation. How can anyone argue against charity, one might ask, if it is to do good in the world? One can argue against charity being a phenomenon that, instead of being a way of helping others, is used to diminish the help dispensed by society and to make such help entirely discretionary, conditional on the whims of the supposedly generous donor. Such a phenomenon serves only the wealthy who then get to choose where society’s money is spent, instead of paying their taxes and allowing broader society to make such decisions for itself.
Thatcher’s Britain was famous for the pursuit of selfishness, but our societies today face what might be called the “atomisation” of society where everyone is encouraged to pursue their own particular agenda and reward their own selfishness. Every time someone pipes up with the idiotic remark “nah, I’m good”, especially when concern is expressed for the weak or defenceless in society, it is merely another expression of the more culturally established (and derided) “I’m alright, Jack”.
But what such selfish remarks effectively signal is “more for me” from someone who already has plenty. And it obviously signals “less for everyone else” regardless of whether everyone else can manage with less or not. It is where people are encouraged to look out for their own personal interests at the expense of society, not realising that society makes their Amazon Prime deliveries possible in the first place.
Those impressed (or maybe bamboozled) by “AI” may remain unconvinced that the phenomenon might be an unsustainable and unprofitable bubble, one that consumes more investment than it can ever pay back, and that its most “disruptive” form has no genuine or necessary applications. After all, it is very popular and, for some, a nice little component in their plump investment portfolio featuring Nvidia and the other technological horsemen of the apocalypse. Why on Earth would anyone question its viability? Or in other phrasing:
“What are the millions of people using GPT for, if it’s a solution looking for a problem?”
The answer to such a question is this: it is for hollowing out forms of work that are fulfilling or professional, leaving the tedious, hard-to-automate stuff to human beings who will end up doing commoditised work, with all the “hustle” for that work and the driving down of salaries that it entails. All so that people whose livelihoods and lifestyles have been ringfenced one way or another can be entertained for a few seconds at a time with their “AI” videos and other “slop”.
The Degradation of Expectations
As neoliberalism took hold, with the privatisation of public services and the deregulation of various markets, consumerism was the shiny trinket that was used to distract from any hardship that was experienced or from the structural weaknesses being introduced. Having more choice in the shops may have been welcome, and if you couldn’t afford to buy anything, there was plenty of credit sloshing around to let you join the party. As for those public services, there were shares you could buy to join that party, too.
Decades of neoliberalism has given us consumerism as a solution for everything, seeing the replacement of basic, universal services with market-driven “consumer choice” involving a bunch of different “providers” who may or may not offer the same quality of products or levels of service that the customer would have a right to expect. Exciting as it may be for some to be able to choose between different flavours of utility provider, postal service, train or bus company, and so on, it all rewards the people with plenty of time, money and a propensity for getting bored easily to “shop around for the best deals”, leaving everyone else disadvantaged by unscrupulous businesses who, according to neoliberalism, merely occupy a place in the market appropriate for the “value to the customer” that they deliver.
Even where public services are maintained, consumerism and the attraction of new toys amongst ostensibly bored or ideologically fixated politicians can easily start to corrupt those services for the benefit of private operators whose only interest and instinct is to make money while they can. Having new toys to play with supposedly makes life more exciting for similarly bored and easily distracted members of the general population, never mind that they burden other public services with the consequences of indulging antisocial behaviour and make the lives of other individuals miserable.
When such companies have, for example, a record of perpetuating their abuse of healthcare professionals overwhelmed during a pandemic, what right do they have to make demands of anyone so that they can keep going with business as usual? But compliant politicians will continue to pander to them. After all, the religion of neoliberalism elevates those companies and their greedy founders to objects of worship.
And if those companies can damage publicly run services to the point of sufficient public dissatisfaction, those politicians can claim that the state always fails at everything and should leave such “business” to business. Naturally, those politicians do not offer to resign from their own jobs, although they are, I suppose, already doing the bidding of private enterprise, just not being willing to forego their publicly funded salary.
In both the public and private realms, many of us are presumably familiar with certain trends. When interacting with companies to obtain help or support with their products and services, or when attempting to navigate the public bureaucracy, one might recognise what I call the notion of “penalty laps” to compensate for cheapened and hollowed-out services, making the customer or the user spend time doing unnecessary and pointless work to prove that they deserve actual support.
One cannot simply communicate with another human being, but must instead interact with a chatbot first, which merely parrots information that is readily available and often of little help to anyone actually requiring support. Or maybe a long sequence of questions, deployed on a Web site or over the telephone, must be carefully navigated before a human can be summoned to communicate. Such inconvenience is used to herd the increasingly unhappy customer or user into other channels, framed as being more “convenient” and almost certainly in the form of an “app”.
The easily amused or distracted customer or user may think that they are getting better service for free, but they are in fact subsidising the operating costs of the institution concerned. And so, businesses and institutions continue their externalisation of operating expenses, insisting that customers or users provide their own equipment to interact with a business or service, paying the advertised costs as well as the hidden costs of acquiring a nice phone, insuring it, replacing it when those institutions decide that it is “too old”. You pay to work for them now, in case you didn’t realise.
Proof of “work” may have been the selling point of ruinous, dubious and entirely unnecessary cryptocurrency schemes, but making people continually prove that they are somehow worthy is an established trait of an exploitative society. Given that the neoliberal society will continue to eliminate decent, fulfilling work, one might expect efficient mechanisms to help people find other opportunities. But instead of making opportunities for people who seek help, such a society and its institutions has such people effectively doing useless busy work applying for non-existent jobs in a largely fictional “market”.
And with no economic strategy or vision, but with a worldview that involves pulling the public purse strings as tightly as possible to close the purse, they perversely create plenty of jobs in the bureaucracy for people to administer penalties and to deliver judgement on other people’s personal situations. Didn’t apply for enough meaningless non-jobs or unsuitable, informal, casual work? Then the entitled people in the bureaucracy aspiring to be like their managers and political leaders, cultivating a belief that they “deserve” their opportunities unlike those lazy people on their books, will deny the help that people seek just to be able to turn their lives around.
Because the attitude in the neoliberal economies is that looking for a job should actually be a job. So, the branch of the state administering work-related benefits is mostly there to coerce people into looking for jobs that they aren’t suitable for, causing huge volumes of speculative applications that even the applicants know are senseless, making it harder for genuine recruitment to occur.
And then there are all the fake job adverts, either posted to cover up nepotism or corrupt practices, or to puff up some company’s image, or to give functionaries something to do. And people wonder why it is that there’s no real economic growth, allowing our glorious leaders to claim that there is no money to spend on building up society, that improving the quality of life for those who need it will just have to wait.
“We can’t afford it” is the perpetual excuse for a lack of public services and crumbling infrastructure. Can’t get to see a doctor or another healthcare specialist? With the zone flooded with “AI”, desperate people turn to desperate solutions with disastrous results. We should, of course, expect better support for the people who need it in our societies, from actual human professionals, but that requires investment and commitment. Expect to be fobbed off with technological toys that cosplay the experience of interacting with professionals instead. Unless you are wealthy or well-connected, because then only the best will do.
“AI” is just the latest escalation in the practice of “divide and rule”, facilitating the targeting of individuals to such a degree that the powerful can go beyond merely targeting minorities and smaller groups while having to indulge the majority to keep them passive and broadly supportive of such cruelty. With “AI”, the powerful can potentially pull each person apart from those closest to them, corrupting their communications and poisoning their relationships, to a degree not even achieved through the manipulation of people’s lives by predatory social media. Populists and the affluent will gladly embrace “AI” for all the amusement it offers and for as long as it lasts, unaware that there may no longer be a “safe” majority for them to hide within any more.
It is not exactly an exaggeration to consider “AI” as an existential threat requiring collective action, not least because of its ruinous power and resource consumption, coupled with the ineffective measures to tackle climate change that are formulated by those politicians always encouraging us to wait for better times. Such times will never arrive if the barons of “AI” and others who prioritise their own wealth are setting the agenda, of course.
There seem to be plenty of people who think that by enthusing about ruinous practices like “AI”, parroting the rhetoric of the oligarchs, and otherwise only caring about things that benefit them personally, that they will somehow get to join that club of the wealthy, that they too will get to go on the spaceship.
To those people, I can only say this: instead of joining the club, even you will find yourself alone, having been torn from the fabric of the society you helped to obliterate, but instead of living your best life, you will be miserable and there will be nobody left to defend you.
And by the way, there is no spaceship.
The Scandisplaining of Digital Freedoms
April 6th, 2026
Recently, the Norwegian Consumer Council has been enjoying a degree of publicity for a campaign they have been running about the “enshittification” of the Internet, riffing on the overused term coined by Cory Doctorow to describe the deliberate degradation of products and services given an absence of real choice and competition in the marketplace. Naturally, international news organisations have lapped this up as another example of supposedly progressive Scandinavian social and political priorities. That plucky Norway could show the rest of the world how to deal with predatory Big Tech.
As always, the story is rather more nuanced if one is more familiar with how things typically go in Norway and, I can well imagine, the rest of Scandinavia. First of all, one can justifiably wonder where these people have been living for the past quarter century. Time and again, Free Software advocates have pointed out that a reliance on proprietary software and platforms ultimately harms individuals, institutions and societies. Over ten years ago now, I myself sought to prevent the introduction of a proprietary groupware platform in a public institution that had been my employer. By the time I was meeting the hostile and dismissive leadership of that institution, I wasn’t even working there any more. The meeting ended with the overpromoted head of the institution, flanked by his privileged and/or hectoring enforcers, insisting that “Microsoft would never do anything that wasn’t in their customers’ best interests”. In the sitcom version of events, cue the laughter track.
I ended up doing some legwork in my own time to dig into the nature of the commercial arrangements between the institution and its supplier, but all the “commercially sensitive” bits involving actual monetary amounts were redacted. My own motivation to pursue the matter was rather tempered by the fact that some of those who felt that this commercial arrangement impeded various workplace freedoms of theirs would not pursue the matter themselves. After all, they didn’t want their nice salary and other bespoke workplace arrangements in their permanent employment position endangered by any kind of actual activism. Evidently, this was the job of the guy whose temporary contract had ended. Having presented my findings, nothing further happened and those precious freedoms were not generally upheld. But technical workarounds let various people pretend that business could proceed as usual. Their nests remained fully feathered. Screw the plebs: they would have to get used to Exchange, anyway.
I wish I could claim prescience in the whole affair, but it was pretty obvious how things would end up going. I remarked that at some point, “on-premises” Exchange would be phased out in favour of a cloud-based solution, likely to be what I tend to call Office 360. Fast-forward to recent times, and of course that is exactly what has been happening, with the institution presumably pleading poverty. Why not just make your employees customers of a foreign corporation, regardless of the wrapping of the institutional package? They have to take that deal whether they like it or not. Now, there may have been some chatter about these new arrangements. Right now, I cannot consult my own archives to check, but I would have been right to say “I told you so”. Some of the supposed champions of freedom may be more concerned that with a full-on migration to the cloud, all those neat workarounds of theirs might finally become obsolete. Maybe it will finally become time for them to face up to everybody else’s reality.
Once Upon a Time
For a time, Norway had a public agency that was meant to promote Free Software and interoperability in the public sector. Lobbied by the usual proprietary software vultures, the incoming right-wing government happily shut it down in a wave of the usual austerity that such governments love to inflict on public institutions, public infrastructure, and the wider population, just as they slash taxes for the wealthy in the name of “wealth creation”. Precisely these kinds of political choices, familiar from countries with more obvious records of punitive austerity, like Britain under the likes of Margaret Thatcher, John Major, David Cameron, and the subsequent clown car parade of prime ministers in the last Conservative administration, degrade societal resilience and undermine things like digital and technological sovereignty that are now suddenly in vogue.
An international audience might be surprised that supposedly egalitarian and progressive Norway might exhibit such traits. Comparable political shifts in Sweden and Denmark, undoubtedly inspired by the cruelty-enabling culture of “personal aspiration” (selfishness, in other words) promoted by British Conservatism, have similarly gone unnoticed or have been gradually forgotten. That a bunch of people in Norway haven’t managed to follow along rather suggests that the tradition of navel-gazing is alive and surprisingly well. After all, if the gravy train kept running from your station, then what was the problem again, exactly?
This latest initiative’s open letter to the Norwegian government notes that the French public sector made concerted efforts to introduce Free Software from 2012 onwards. How quickly people forget that back in 2012, that soon-to-be-culled Norwegian public agency was trying to bring the Norwegian public sector round to undertaking similar kinds of endeavour, doing it the celebrated Scandinavian way of not treading on too many toes. Naturally, such an approach was never going to be resistant to the kind of predatory corporate interests who routinely siphon billions of crowns, pounds, euros and dollars from the public sector locally and internationally for supplying their mediocre and often blatantly deficient products and services, subjecting governments and thus taxpayers to coercive, ruinous and yet seemingly perpetual contracts.
Those previous efforts might have been envisaged as a viable means to a righteous end, but they may have ended up being regarded simply as a nice supplement for those already engaging in the kind of advocacy that makes people feel like they’re “doing something”. It was another voice in the chorus of righteousness, and with an accompanying annual conference, it was yet another venue to talk about things and congratulate each other, rather than do those things necessary to actually advance the cause. It was even held in Svalbard on one occasion, if I remember correctly, because nothing says more about a commitment to sustainability than having a bunch of people jet off to the realm of polar bears and those melting ice floes.
So, what things would have advanced the cause, then? Well, the first thing would have been to actually fund Free Software at scale and to make sure that when people tout solutions for widespread use, they are actually fit for the job. And no, gathering up a bunch of existing projects and promoting them is absolutely not the same thing. When I investigated Free Software groupware solutions, the popular wisdom was that Kolab had “solved” groupware many years earlier. It turned out that Kolab had been rewritten as version 3 and was inadequate in a number of ways: a half-finished solution. Efforts to try and engage with the developers became futile. Despite pitching the software as a collaboratively developed Free Software project, all they really cared about was whether the software would support the operations of a now-liquidated Swiss company riding the privacy bandwagon and largely targeting the Jason Bourne brigade.
Such experiences made me suspect that Kolabs 1 and 2 might not have been adequate all along, either, possibly pitched as a good-enough solution to a problem that hadn’t been fully understood, all to serve various big-fish, small-pond commercial interests. Later on, I discovered Zarafa, which became Kopano, and wished I had found it earlier. It may have been a better choice, not least because the dopes insisting on Microsoft Everything would have seen the Web interface and thought that it was straight out of Redmond, unlike Microsoft’s own Web-based Outlook solution, perversely. Sadly, as a sign of our depressing times, Kopano is now becoming (or has become) a cloud-only product.
It may seem obvious, but it still needs saying: general advocacy and encouragement isn’t sufficient; people need working solutions. And experience also shows that one cannot leave it to “the market”, whatever that is in Free Software. For many years, I have used KMail to read and send e-mail. It remains surprisingly usable today, “surprisingly” because its developers decided at one point to adopt some weird middleware layer called Akonadi, entranced by the promises made by Microsoft and/or Apple to deliver pervasive “desktop search” capabilities in their own products. Whether Microsoft or Apple actually delivered or, more likely, abandoned or scaled back those promises, I am now compelled to run the command “akonadictl restart” almost every day to “unwedge” my mail client and get to see newly arrived mail.
(It also didn’t help that the developers introduced MySQL – now MariaDB – into the mix, and that in the maintenance of that product, which throughout its existence under its various names could uncharitably be described as Monty Widenius’ Flying Shitshow, someone decided to bump a version number in a minor (or actually a patch-level) release that caused the whole stack of software to refuse to access the arguably unnecessary database underpinning KMail, making my mail inaccessible. Fortunately, my case was heard within Debian, and remedies were eventually applied. Before that, I had to recompile the package with an appropriate workaround. A victory for Free Software pragmatism, but good luck to the average user suddenly staring down a potentially indefinite e-mail outage.)
Free Software groupware applications, like the overall desktop experience, stopped showing year-on-year progress in functionality some time ago. Already degraded in various ways when the developers of such technology became distracted by what the big players said they would be doing, the arrival of social media seemed to make some developers believe that the era of the mail program had ended altogether. It apparently became more important to some of those developers to add “share on Facebook” menu items to random applications than to ensure that their applications were still usefully serving their loyal users.
(Observations that technologies like ActivityPub and applications like Mastodon can supplant boring old e-mail and that they have shown considerable growth, and yet remain in a niche, rather overlook – indeed, neglect – the fundamental variety in groupware and collaborative technologies. A strategy of “ActivityPub everywhere” is like keeping the big hammer and throwing away all the other tools in the toolbox. One might suspect that it is only now gaining traction because there are people who want a similar kind of buzz to the one they get from their favourite doomscrolling services but feel bad going back to the same, increasingly disreputable dealer.)
The lesson here is that someone firstly needs to develop functional software, but then to check and double-check that functionality, as well as continuously verifying whether the software meets people’s needs. This cannot be left to random developers or to companies. The big Linux distributions never really cared enough about the average user to finish the job, merely bundling stuff and maybe hiring developers to either dabble with their projects or to make them only good enough for narrow corporate advantage. As far as Red Hat’s bottom line was concerned, all that ever really mattered was a placeholder desktop good enough to do a bit of point-and-click system administration for a bunch of file and print servers propping up a bunch of Windows desktops, or for software development most likely involving Java and targeting “the enterprise”. Such companies happily make their own employees use proprietary software and services for the kinds of tasks that the average user does, regardless of whether they might be using Free Software office and groupware suites instead.
The right approach would have been a concerted government initiative resistant to lobbying and corruption, not mere advocacy, nudging and cajoling. Genuine standards and interoperability could have been mandated and corrupted pseudo-standards like Microsoft’s fast-tracked office formats rejected. Agencies like Statistics Norway should have been taken to task for stipulating “.doc” as their chosen “interoperable” format, with those responsible sent back to finish, or maybe even begin, their education. One might have learned from experiences in other countries, like that of the public key encryption software Gpg4win in Germany, where a genuine governmental need transformed the financial viability of the GnuPG software project from one which had been chronically underfunded and practically relying on the charity of its principal developer to a thriving, viable enterprise.
Proprietary software lobbyists had criticised Norway’s earlier soft-touch efforts, claiming that the public agency concerned was subsidising uncompetitive software that was presumably the work of hippies and communists. There was one case of a public institution wanting to give money to a Free Software project in the realm of PDF generation, if I recall correctly. Upon discovering that it was Free Software, decision-makers refused to make the donation: after all, if those people were giving their code away, why pay after the fact? Such paper-pushing idiots evidently failed to understand that such windfalls may only happen once. Some of them would undoubtedly and routinely use the Norwegian word for “farmers” in the pejorative way for people they might consider ignorant, and yet farmers manage to understand that harvests do not magically occur and re-occur without cultivation and sustenance.
The right approach would also have involved mandating Free Software for publicly funded projects and for public infrastructure, as advocated by the FSFE’s Public Money Public Code campaign. Proprietary software interests would undoubtedly howl at such stipulations, claiming that their secret sauce software, supposedly written by Top Men, would be unfairly excluded from such markets. But just as even some ostensibly left-wing politicians have forgotten, “markets” only exist at the indulgence of governments and regulators, and they only operate in the public interest if properly framed and regulated. Don’t want to give your customers the freedom to maintain the code they are paying for? Feel free to seek opportunities elsewhere, then. Cushy lock-in deals for the locally well-connected should have gone the way of Norsk Data when that company fell to Earth.
Planet Norway
Attitudes to societal threats seem to be remarkably relaxed in our supposedly enlightened democracies and their institutions. The casual, pervasive use of predatory social media platforms continues, propped up by state institutions claiming that they need to have a presence in all the different channels, but where one suspects that a few managers and their appointees just want to play with some toys and puff up their public profiles. Instead of leveraging the resources of the state and providing reliable channels of communication, such bodies post announcements, updates and nonsense via foreign-owned hate speech venues. Norwegian political party leaders even decided at one point that they had to promote themselves on Snapchat, egged on by one of the national broadcasters. Now, we see the unquestioning adoption and promotion of “AI” and chatbots by institutions that risk being obliterated by such technologies.
At the individual level, concerns about “screen time” and the use of tablets and other devices in places like primary schools have been aired and may well be justified, given the likely developmental impact on children of such devices, but it all comes across as pearl-clutching when one suspects that the lifestyle of the vocal parents probably revolves around their phone, “apps”, streaming services, and rather too much screen time of their own. And some of those concerned about screen time would probably drop their objections if a study conveniently came along to assuage their worries. It is just like those very Scandinavian traits of stuffing tobacco products into one’s mouth or spending time at the tanning studio, neither of which are actually healthy. Over the years, various pseudo-academic figures and findings have occasionally floated up into public prominence, insisting that such things are perfectly fine. Why wouldn’t that happen with technology? The companies involved could certainly afford to pay for a bit of fake research and a few willing advocates.
One gets the impression that many of the different factions that might coalesce around a campaign about “enshittification” aren’t really trying to achieve systemic change: they merely want to negotiate a better deal. Such people knew what they were getting into by using free-of-charge services and often explicitly rejecting genuinely free alternatives which cost only modest sums to run. Such people were also aware that their data might wander off into the cloud and away to places where it would be mined and exploited for all it is worth, but caring about it was just too much bother. In institutions, all it takes is for Microsoft to “pinky swear” that it complies with data protection regulations. Institutional capabilities are then run down and alternatives abandoned, just so the toys can be unpacked, sending non-trivial sums overseas instead of cultivating knowledge, opportunities and wealth locally.
One wonders how seriously people really want to take such matters, or whether they just want a hobby and to feel good about a bit of casual activism. I am reminded of the climate litigation brought against the Norwegian state for its continuing policy of fossil fuel extraction, noting that climate change presents an existential threat reaching far beyond the confines of the nation, affecting the population of the entire planet, but where the country’s constitution at least worries about the state of the nation for future generations. The outcome – a defeat for the litigants – might not merely be described as positioning Norway as having “first world problems”: that would be business as usual. Instead, it might reasonably be described as situating Norway on a planet of its very own. One where the mere accumulation of money protects and even “benefits future generations“, evidently.
Hobby activism is typical of places where the stakes remain relatively low for those doing the campaigning, but on Planet Norway it arguably reaches another level, where hardship along any given dimension is often perceived to be a problem that only foreigners in poorer countries experience (or poorer planets, maybe). Or it is marginalised and framed as something that only affects a vanishingly small number of people, conveniently aided by policies and attitudes that seek to hide those who are struggling and blame them for their own predicament. But a reckoning is surely overdue even in matters of preference as opposed to need. After all, what good is it to advocate that children learn to code if nothing is done about the way “AI” is devastating Free Software and undermining paid work?
Unlike outsider perceptions of the money flowing freely in Norway thanks to the oil fund, the purse strings are generally not loosened for those whose professions have been gutted. And for younger people, they are more likely to be told to take shifts at Ikea than get the help they need. Yes, this is actually a thing. It also explains why on one local recruitment site, when filling out one’s employment history, the default value in the employer field reads (or read when I last checked) “Ikea Furuset”: one of the two full-scale Ikea stores serving the Oslo area. Not that there’s anything wrong with working at Ikea, but I doubt that the kind of aspirational parents hoping to give their little darlings a head start in the world, funding their higher education and other ambitions, would see it as a fitting venue for their offspring’s many talents.
Yet Another Elephant in the Room
This latest campaign recommends Free Software and open protocols in public procurement, which is what previous efforts pretty much did, too. The accompanying report even suggests funding alternatives, but then delegates this to discretionary funds and foundations, conveniently avoiding the structural issues. But the very reason why “dominant big tech companies have deep pockets” is through a perversion of economic incentives. Firstly, they have cultivated an “expectation of zero” where individual and institutional customers expect software and services to cost nothing. Thus, any investment in software is regarded as unnecessary because those nice corporations are giving away shiny free stuff. They also front-run various standards to make any kind of competition ruinously expensive to pursue.
And yet software cannot be developed without expenditure, and certainly not with the latest instrument being used to sustain those cultivated consumer expectations. “AI”, which is hyped to make it seem like software can be whipped up at a moment’s notice at no cost, relies on industrial scale plagiarism, colossal data centre and hardware investments, and ruinous levels of power consumption. What has funded these scorched earth tactics is a corrosive business model that inflicts highly lucrative but consequence-free, unpoliced advertising channels on billions of people. Developers at predominantly American technology company aren’t expected to work for free, after all. We are apparently meant to feel sorry for them. Some of them have to pay gentrification-level prices for their homes in places gentrified by themselves and their colleagues. Their bosses expect huge bonuses, their own yacht, island, spaceship…
Claiming the juvenile right of unrestricted free speech to drive engagement, Big Tech has largely allowed unregulated commerce to proceed, undermining traditional safeguards, endangering individuals, and threatening and even shuttering viable, responsible businesses. Any efforts that ignore such structural issues will fail to find the money required to make a difference. I, or my Web publisher, may be held to account for what I write, but anything goes on the predatory Big Tech platforms, whether it is the puerile variant of “free speech” cultivated by the increasingly fragile American dream, or whether it is fraudulent or outright illegal advertising promoting dishonest and criminal enterprises. Allowing such business to continue as usual simply enriches these predators while impoverishing ourselves.
The operators of those platforms are getting a free ride at a severe cost to us and our societies. It may not seem like it to the random punter getting “a great deal”, but we all pay for that deal in the end. And even little Norway has its own commerce platforms that look the other way, especially where anything related to the property bubble is concerned. Why not advertise your rental property using the fancy sales prospectus from a few years ago when you or a previous owner bought the property from the developers? Oh, “caveat emptor“, of course. How about advertising a property with a non-existent address? How much money is laundered even in little Norway, or is that kind of thing only done by foreign people in less enlightened countries? Maybe even the same people whose oil is “dirty” while Norway’s is “clean”.
Anything short of changing the flawed terms under which those companies operate, which one can barely believe are legal in the first place, is nothing more than consumerist tinkering. Naturally, there will be howling from entitled consumers, happy to have random people scurrying around with their urgent shopping deliveries, just as established, essential services like postal mail risk being degraded to the point of near uselessness or even eliminated altogether (which is something that might blow the minds of media people in countries like the UK where postal services still largely hold up and where deliveries still happen six days a week). But society cannot pander to people’s elevated levels of personal entitlement forever, despite the best efforts of populist politicians living in their own bubble of affluence.
I suppose I could be accused of being a simple “outsider” who still doesn’t understand Norway after all these years. Recently, I read a ridiculous piece claiming that Norwegian culture and society does not tend to focus on personalities. That would be news to readers of gossip magazines, newspapers, and even the finance magazine I would read in a medical specialist’s waiting room, keeping us all up to date on which members of the Norwegian financial and legal elites were suing which other members of those elites, all while name-dropping and generally cultivating individuals as movers and shakers.
But instead of cherry picking parts of the nation’s broader, pan-Scandinavian heritage – Janteloven in that particular case – and perpetuating all the other familiar tropes, so often featured in selective, favourable cultural projection delivered through credulous or lazy journalistic coverage, maybe lessons could be learned from one of Hans Christian Andersen’s more famous tales. It really doesn’t take very much to point out that notions of Scandinavian preparedness in the face of digital exploitation and its accompanying threats are somewhat overstated. Anyone caring to take a closer look at the emperor’s reputation as a fully clothed, well-tailored individual can do it, if they actually care to.
I just wouldn’t recommend anyone holding their breath for too long in anticipation of decisive, credible Scandinavian action that might show the wider world the way forward. After that sharp intake of breath witnessing the emperor in the buff, please exhale or you might eventually expire. Just like in other countries, there would have to be a cultural shift away from shopping for “big brand” software, wheeling in the consultants, having retreats and “away days” learning about the next set of goodies on the proprietary software treadmill, and treating predatory social media platforms as merely a harmless guilty pleasure. Maybe local commerce wouldn’t have to be mediated by “apps” and trillion dollar corporations, either. And there would have to be more than tame, hobbyist lobbying and performative activism: quite the challenge when rocking the boat in countries like Norway is simply never done.
But it all made for a good story about Scandinavia leading the way, as usual, so “job done”, I guess.
The End of the Minicomputing Era
March 11th, 2026
Previously, I described the glory and the turmoil of the 1980s for Norsk Data and its competitors in minicomputing, the rise of the workstation and Unix, and Norsk Data’s attempts to maintain a claimed performance advantage over Digital’s VAX and over RISC workstations from a variety of manufacturers. An unconvincing Unix implementation had marginalised its minicomputers, and the workstation phenomenon had eroded sales of minicomputers more generally. This combination had taken revenue from Norsk Data in venues like CERN, where the company had once presumably expected continued growth amidst an appetite for its capable and relatively well-priced machines.
Norsk Data’s attempts to introduce workstations had seen specialised products targeting specific disciplines or activities, such as artificial intelligence (AI) or computer-aided design and manufacturing (CAD/CAM), that in some respects appeared more to pander to the workstation phenomenon as if it were a passing fad, as opposed to engaging with it substantially. Its AI workstation was a rebadged minicomputer that appears to have persisted with the familiar terminal-based paradigm, merely adjusted to use graphical terminals instead of character-based ones. Its CAD workstations seem to have been developed in an organisational silo, taking the minicomputer hardware and, with the addition of graphical output and various input devices, producing what would have been called a “suite” or dedicated workspace for its users.
As competition intensified, capitalising on the weaknesses in certain areas of performance of established minicomputer products and Digital’s VAX in particular, some manufacturers sought to move upmarket with more affordable systems that would, only a few years earlier, have been considered well within supercomputing territory. And so, their target shifted from the likes of Digital to established supercomputer companies, attempting to take low-end sales away from them. Norsk Data’s performance record had been at least respectable, and so such a move upmarket would have seemed entirely natural to contemplate.
Of Superminis, Minisupers and Microelectronics
Evidently, Norsk Data did aspire to enter this minisupercomputer market, following the lead of various other companies who sought to undercut the likes of Cray with high-performance machines at somewhat lower, but still rather robust, prices. The principal route to doing this was to offer vector processing support, introducing hardware support to perform operations on collections of inputs in a more efficient fashion than in a conventional machine. Thus, computationally intensive tasks of the appropriate kind could be accelerated to a considerable degree.
Established companies such as Amdahl, Digital, ICL and IBM had all brought vector processing units to market to complement the capabilities of their machines. Floating-point processor vendors moved upmarket into the category, looking for new opportunities as conventional machines became more powerful. Other vendors such as Ardent Computer, Alliant Computer Systems, Convex Computer and Stellar Computer focused on complete systems as opposed to accelerators for other machines. Other avenues for minisupercomputing existed, too, notably massively parallel systems made by companies like Meiko Scientific, nCUBE and Thinking Machines.
Norsk Data’s effort seemed to centre on its collaboration with Matra, but few results seem to have emerged. One such result may have been dedicated microcode for array processing, available for its ND-500 systems, offering speed-ups of around four or five times on various operations. Although this testified to the versatility of the processor architecture, one might wonder how work on the ND-5000 affected considerations by introducing pipelining and potentially squeezing out some of the redundancy that perhaps permitted such speed-ups in the first place. Matra was a company whose eyes were bigger than its stomach, undertaking ambitious levels of diversification from missiles to cars, watches, semiconductors, home computers, and then scientific and engineering computers. Spinning up numerous collaborations including one with Sun Microsystems, it even developed its own Unix-based “artificial intelligence server”, only to suddenly pull out of computing altogether.
To otherwise increase system performance further, Norsk Data’s approach was to couple several processors together, sharing memory and offering a form of symmetric multiprocessing. Thus, the ND-500 and ND-5000 ranges had models that effectively replicated the processing unit of the top-end single-processor model, providing two, three or four processors. This could potentially increase the throughput of a system, although the company’s odd benchmarking practices had them quoting multiples of the Whetstone benchmark scores reportedly achieved by the core single-processor system. Given that Whetstone does not attempt to measure multiprocessing performance, this was optimistic opportunism at best, a cynical marketing ploy at worst.
Regardless of whether a top-end ND-5900/4 (claiming 26 MWIPS) or ND-5950 ES L14 (claiming 120 MWIPS) might have rivalled well-known minisupercomputer models, there will have been one sticking point: those models all ran one form or other of Unix. In some cases, their vendors had grown out of the floating-point accelerator market, seeing the opportunity to pitch complete systems to compete more directly with the unfortunate Digital whose VAX models remained the baseline for comparison. For instance, Floating Point Systems had acquired Celerity Computing which had itself attempted this transition but found itself confronted with a downturn in the market.
One might think that once a company has been absorbed by another, its story is effectively over, but Celerity Computing’s expertise gave Floating Point Systems new products, and the combined company was later acquired by Cray. When Cray was itself acquired by Silicon Graphics, the division originating in those operations from Celerity and FPS was considered surplus to requirements, perhaps even a liability, utilising SPARC-based technologies in multiprocessor “superservers” aimed at data processing applications. SGI divested itself of the division, selling it to Sun, where this superserver technology became a hit product in the form of the Ultra Enterprise 10000, just at the right time to profit substantially from all the spending on Internet and enterprise servers during the dot-com bubble.
Another “minisuper” vendor, Convex Computer, produced some very ambitious systems, utilising vector processing and techniques previously seen on supercomputers from Cray. Producing respectable performance with its initial single-processor products, having invested in vectorising compilers that it licensed to other companies, the company was forced to adopt multiprocessing to prevent being outflanked by competitors employing more general parallelism in their designs. Like Norsk Data, Convex relied on CMOS gate array technology to implement its processor architecture, and the company apparently introduced ECL technology in its C2 range.
It continued introducing systems based on gate array technology, employing chips based on gallium arsenide transistor logic in 1991, but ultimately had to accept that mainstream processors were outcompeting such low volume designs, and after plans to use the MIPS R4000 were dropped, the company adopted Hewlett-Packard’s PA-RISC processors in subsequent models. Eventually, HP acquired Convex, integrating some of its products, which by then were running HP’s own Unix, into its own range. Once again, a pioneer in this realm would leave a technological legacy through an act of corporate consolidation.
Even if the pressures of the market had been different, one has to wonder about the economic model involved with Norsk Data’s own hardware efforts and the accompanying technological choices. Companies like ICL stuck with ECL and CMOS gate arrays instead of aiming for large volume VLSI products, but ICL sold expensive mainframe systems in relatively low volumes, and the costs accompanying the use of racks of boards packed with gate arrays and other chips, and the meticulous process of assembling each system, could be absorbed in the purchase price. Even then, ICL eventually transitioned its mainframe products to commodity Intel-based hardware, running its platforms under emulation.
For a vendor like Norsk Data, the general progress of technology coupled with the company’s positioning in the market – neither a low-end, high-volume supplier, nor a premium, top-end supplier – meant that it had to evolve to remain competitive. ICL could justify being leisurely in its own predicament, having the substantial backing of Fujitsu and an entrenched position in the UK public sector. And if relatively small companies like Acorn could enter the processor space with VLSI chipsets, one really has to wonder why Norsk Data, with all its expertise, never sought to do the same. Such considerations impacted other companies. Sun Microsystems first introduced the SPARC processor implemented in a Fujitsu CMOS gate array product, engaging various fabrication partners to produce follow-up VLSI products.
Apollo Computer, as a leading workstation manufacturer, was perhaps a nemesis that Norsk Data never really accepted that it had. As other workstation companies jumped ship from Motorola’s popular but lagging 68000 family, Apollo developed its own credible RISC architecture, delivering it in the DN10000 workstation. However, the PRISM processor was a multiple chip implementation, and just as Hewlett-Packard had delivered the first PA-RISC processor in a similar fashion, only to rationalise the implementation in subsequent products, Apollo needed to take a similar route. Difficulties in doing so eventually contributed to Apollo being acquired by HP and its technologies absorbed by the larger company, helping make PA-RISC usable in multiprocessing systems.
It could have been argued that Norsk Data’s ND-500 and ND-5000 processors were simply too complicated to be squeezed into small VLSI chips. Such excuses would hardly hold up in the face of Digital’s MicroVAX 78032 processor, introduced in 1985, implementing a subset of the VAX instruction set architecture which, in conjunction with software support, could provide full VAX software compatibility in the form of the MicroVAX II system. With Norsk Data facing financial hardship and the disintegration of the company, pursuing the further consolidation of the ND-5000 chipset was perhaps too costly a business. Furthermore, the ND-500 instruction set architecture was arguably unattractive and undeniably marginalised in the marketplace. Rare third-party support could be found in the proprietary compilers made by ACE Amsterdam Computer Experts, known for its associations with industry legend Andrew S. Tanenbaum, one of the originators of the Amsterdam Compiler Kit and principal developer of MINIX.
Plenty more promising RISC architectures, such as AMD’s Am29000, were discontinued as their creators prioritised other products, acknowledging that the industry would coalesce around the most popular and widely supported architectures. Thus, facing market realities, Norsk Data and its spin-off, Dolphin Server Technology, pivoted to Motorola’s 88000 architecture, only to find themselves backing the wrong horse in that particular race. Experiencing fabrication difficulties, Motorola itself dropped the 88000 architecture in favour of IBM’s POWER and the PowerPC initiative, leaving an array of supporters who were left to rework their strategies all over again.
A project known as ORION was the claimed motivation for establishing Dolphin as a separate company in the first place, but the sequence of events that led this project to its own cancellation, separate from the fate of Motorola’s own 88000 efforts and the architecture in general, remains unclear. ORION was reportedly a 88000-based superscalar processor with throughput claims of four instructions per cycle. It was presumably not a conventional “very long instruction word” design, since the superscalar characteristics of the design were said to be “invisible to the programmer and operating system” and applicable to other instruction set architectures.
Perhaps the designers sought to adopt techniques similar to, or beyond, those employed by IBM’s POWER architecture, noted for its superscalar characteristics and having somewhat stronger floating-point performance than its competitors. Indeed, the stronger performance of vector floating-point operations on early RS/6000 systems led to suggestions that headline benchmark scores were potentially misleading given the lack of prevalence of such operations in most kinds of software. In any case, ORION never proceeded beyond simulation to allow its own real-world performance to be assessed.
Meanwhile, one apparently successful research project that Norsk Data reportedly had the opportunity to commercialise was the CESAR systolic array processor, designed to process radar data and initially deployed with Norsk Data minicomputers as front-end systems. Perhaps due to timing, the company may have been insufficiently resourced to pursue such opportunities, having to focus on the fundamental aspects of the business. Later models of CESAR employed various workstations and other RISC-based front-end systems.
CESAR seems to have followed in the footsteps of the Goodyear Massively Parallel Processor (MPP), developed for satellite image analysis but also deployed for radar data processing. Work at Digital on an enhanced MPP that was then not pursued further by the company apparently led to the founding of MasPar Computer Corporation and the development of the MP-1 and MP-2 systems, coupled with VAXstation front-end workstations in a deal with Digital. Interestingly, one of the purchasers of the MP-1 was the University of Bergen. Digital would later rebadge MasPar systems in its own line-up.
Such talk of CESAR’s commercialisation in 1989 came rather late in the day. By 1990, the SIMD market was already vibrant, with one player, Active Memory Technology, having been selling and refining systems based on ICL’s Distributed Array Processor systems since 1986. ICL first demonstrated the DAP with 1024 processors in 1975 and apparently delivered the first DAP product in 1979.
As with CESAR, other traditional users of Norsk Data systems for scientific data analysis also switched to workstation-based alternatives in the early 1990s. The Cyclotron Laboratory at the University of Oslo began the process of retiring its ND-5800 system in favour of a Sun SPARCstation 10 in 1992. In other areas of Norwegian academia where Norsk Data machines might once have been considered for their high performance, even reluctantly, clusters of workstations had made their entrance. In one report, the authors went as far as to blame Norsk Data’s domestic dominance and Digital’s “growing influence” for policies that, until the mid-1980s, had excluded “real supercomputers” from Norwegian institutions.
An Accumulation of Consequences
Although it had apparently been the intention to run Digital’s proprietary VMS operating system on its MIPS-based DECstation and DECserver families, Digital never followed through, and the company resumed its efforts to develop its own proprietary architecture to run both Unix and VMS, which had been an aim for its abandoned PRISM architecture (not to be confused with Apollo’s PRISM). The MIPS-based DECstations were seemingly well received, and the range was steadily upgraded as new MIPS processors became available, but Digital itself did not fully engage with the architecture.
Evidently, the focus shifted to the company’s own architecture in development, Alpha, and the DECstation line was discontinued, leaving customers with an inconvenient migration path that probably saw many of them simply switch to other vendors. By the time products based on Alpha were ready and running VMS, one might argue that the appetite for Digital’s proprietary operating system was waning. Alpha did lead the pack in performance for a while, but its reputation perhaps exaggerates that lead. Soon enough, HP’s PA-RISC, IBM’S POWER, along with MIPS and SPARC processors were challenging that lead.
Digital’s well-understood limitations and self-inflicted difficulties seem relatively minor compared to those of Norsk Data as the latter company’s growth stalled, profits turned to losses, and customers voted with their feet in favour of interoperability and widely used technologies. Digital’s restructuring, involving redundancy plans and job losses, was very costly for the company and its effects very possibly contributed to the general weakened position of the company, leading to its eventual acquisition by Compaq, but it was not an immediate existential crisis. For Norsk Data, having grown so fast to accommodate potential sales that never arrived, hiring employees and building fancy new offices and facilities, the need to restructure and reduce spending more or less broke the company altogether.
The promising ND-5000 range, notionally competitive with similar products on the market, was supposedly still being developed by the spin-off development operation, Dolphin, alongside the new 88000-based product line-up. But within the division of Norsk Data responsible for procuring new systems, ND ServiceTeam, the ND-5000 range was described as a “milk-cow” product, the term being an amusing direct translation from Norwegian, “melkeku“, instead of the more familiar “cash cow“. Without a long-term commitment from those selling systems to deliver competitive ND-5000 products, and thus a long-term product strategy to drive further development of the architecture, it would have been difficult to justify continued investment in it, particularly as Norsk Data’s competitors were managing to achieve the kind of high sales volumes that could justify larger scale integration.
Thus, the ND-5000 range was positioned in the kind of server role that it had always largely occupied, but now having to coexist with workstations and personal computers rather than terminals, its supposed high performance lending itself to file and database serving duties. Oracle was apparently persuaded to release its products for the ND-5000 systems, as Norsk Data tried to push them into the “transaction processing” market. For such systems to thrive in such a role, however, they would have needed to fit in with the technological choices of their customers, running a convincing form of Unix and not sneaking Norsk Data’s proprietary SINTRAN operating system in through the back door.
Mixing Unix servers and workstations from different vendors would have been justifiable. Relying on, say, a Network File System implementation running on some traditional operating system with “open systems” credentials, like DEC’s OpenVMS or ICL’s VME, might have suited some customers. But it remains doubtful that many customers would have sought out Norsk Data’s products to do such duties for their collection of Unix workstations sourced elsewhere. Norsk Data systems quickly became legacy technology and a liability for those customers still operating them.
Interestingly, Dolphin announced an agreement with NeXT to offer NeXT’s workstations alongside its own 88000-based servers running Unix. NeXT was expected to adopt the 88000 as the basis of its next generation RISC-based workstation, but the discontinuation of the 88000 largely turned that company into a software-only operation. Here, the threads of history cross once more. The NeXTcube is known as the machine on which Tim Berners-Lee developed the first software for the World Wide Web. His earlier information management concept, ENQUIRE, had been developed on a Norsk Data Nord-10 system.
The rapid descent from the Norsk Data’s days of impending glory came as a shock to its decision-makers and strategists. Having spent most of the 1980s resolutely ignoring or dismissing open systems trends, personal computing and Unix, in 1989 the company attempted to pivot to embracing all of those things, its representatives finding themselves having to roll back all of the negative rhetoric that they once used against the very essence of their new strategy. A company that had been dismissive about standards and interoperability now sought to appoint itself as the guardian of those very same things.
Despite showing the enthusiasm of the newly converted, certain elements of the rhetoric suggest a level of sincerity not unlike an oil company conceding the existence of climate change but positioning itself as instrumental to any “transition” away from fossil fuels, unable to refrain from the occasional jibe against those things that have forced it into its humbled position. For Norsk Data, this meant insisting that customers were not really asking for Unix as such, that the operating system was irrelevant, which might only be true for operating systems of comparable capabilities and with true interoperability, that SINTRAN was somehow still better, anyway, and that customers really wanted proprietary systems. Such sentiments would have made the broader message unconvincing to anyone evaluating the company as an information systems provider.
Commentaries about Norsk Data tend to emphasise the fairytale aspects, along with the predictable “little Norway” tropes and the tedious journalistic style familiar from long-established, self-satisfied newspapers and periodicals. Per Øyvind Heradstveit’s book “Norsk Data – a success story” was published in 1985 and paints a typical heroic picture, including the usual, tiresome, and inappropriate cultural references to “vikings” that, like the original Vikings, do not travel and translate well to other countries and cultures. Written at a point in time to celebrate the progress of the company, Heradstveit had to end the tale before it all went wrong.
Personal reflections from leadership figures may recognise the company’s shortcomings, but they also make virtues out of dubious corporate behaviour. Such behaviour may have involved standard industry practices, but are nevertheless practices that those of us in the Free Software movement justifiably reject. The use of the company’s NOTIS office software product as a vehicle to indoctrinate users in large organisations, particularly public sector institutions, training them up for that specific product and making it costly to adopt other systems and applications, might be familiar to anyone observing the method of operation of Microsoft and the promotion of its Office suite and online products amongst institutional users.
Protesting that nobody could foresee the industry’s transition to open standards and to technologies like Unix, and that nobody really knew what would become a standard, a glimpse into the mindset is revealed by accompanying observations that any serious effort to adopt standards would have risked undermining the bumper profits in Norsk Data’s best years in 1985, 1986 and part of 1987. When the going appears to be good, why bother changing anything? Such an outlook tends also to be shared by certain flavours of politician, leaving society vulnerable to adversity. Of course, the leadership chose not to see the mounting evidence in the form of customer requests and then requirements for various technologies. It certainly did not help to believe that SINTRAN is a better operating system than Unix when one’s own customers do not even believe it.
Wondering what might have been done differently, one sees that the imagination of the company’s leadership was clearly limited when considering other possibilities of doing business, at least where the outcome might involve sharing the opportunities in a market with other participants. And enviously looking at other industries and other markets, the notion of patenting technologies evidently arose, with the hope that this would tilt the playing field and make the technology business obscenely lucrative once again. Of course, we all know how destructive patents can be, granting unethical and arbitrary monopolies, so that “inventors” can claim areas of endeavour as their own, eliminate competition, and stifle the innovation that the patent lobby claims to encourage.
Although the narratives of Norsk Data’s leadership and associated commentators may leave us without reasonable explanations for various aspects of the company’s strategy and the attitudes of certain key figures, a newsgroup discussion from several years ago provides a gold mine of insight from one of the veterans of Norwegian academic computing, Gisle Hannemyr. Recounting various interactions with the company over the course of a decade or thereabouts, he noted that while collaboration with academia and research institutions had led to the company’s initial success, the corporate culture had gradually started to exclude academia and emphasise the company’s own role in that earlier success at the expense of its collaborators.
At the start of the 1980s, academics in computing had become alerted to developments in networked, graphical, personal workstations. Niklaus Wirth had famously wanted to acquire a Xerox Alto workstation after a sabbatical at Xerox PARC, but unable to do so, he developed his own Lilith workstation. Other academics spent time in environments being exposed to workstation computing and returned convinced of its benefits. Seeking to persuade Norsk Data of the importance of this trend as early as 1982, Hannemyr’s arguments were dismissed by Norsk Data’s leadership who regarded a NOTIS terminal as the same kind of product as these workstations. Even in 1984, as Sun Microsystems delivered workstations to the market, Norsk Data’s leadership persisted with their belief that a character terminal connected to a minicomputer was the equivalent of such a workstation. (Oddly, in archived photographs from Norsk Data, it seems that at least someone in the company was at least using an Apple Lisa.)
Relations between academia and Norsk Data evidently soured significantly when the academics, various programming language and paradigm pioneers amongst them, sought to acquire Lisp machines and secured a potential collaboration with one of the most significant producers of such machines, Symbolics. Such a collaboration allegedly displeased Norsk Data’s management to the extent that lobbying was employed in the sphere of governmental politics to prevent it from going ahead, and the researchers were instead obliged to take delivery of the ultimately unsuccessful KPS-10 system from Norsk Data, the one whose delivery had been forgotten by one of the company’s chroniclers but whose backplane had caught fire in a university computer room.
Consequently, efforts to establish a Lisp community in Norway had been undermined by the redirection of public funds to serve the interests of a single company. Such self-serving practices were perceived as being entirely routine and part of Norsk Data’s methods to remain entrenched in the public sector, and this merely diminished the reputation of the company in academia still further. Indeed, beyond very specific applications, Norsk Data’s products seem to have been rejected in certain Norwegian academic institutions. Naturally, Norsk Data failed to learn anything from this collapse in the relationship, choosing not to cater to the demands of the academics, whose business would go, along with plenty of revenue, to the workstation vendors and their Norwegian distributors.
Hannemyr recalled that in 1990, with the company humbled by market conditions, an attempt was made to reconcile with academia with a presentation of the company’s plans for the 88000, ostensibly ORION, which he describes as a liquid-cooled, ECL-based variant of the 88000 and labels using a term that might only be adequately translated as “nonsense”. The mood for reconciliation descended into recriminations when the academics restated their interest in graphical workstations, seeing little value for their own work in what they were being shown.
Such perspectives perhaps illuminate a persistent deficiency in the company’s strategy, although it still seems bizarre that with a chorus of critics highlighting a phenomenon that the company could no longer sensibly ignore or deny, the company doggedly continued its denial of what workstations had become. When introducing its range of 88000-based models, all but one of them were Norsk Data or Dolphin designs. The exception was the workstation: a rebadged Data General model. And as the ORION project was pitched in the industry as part of the spun-off Dolphin subsidiary, it was the head of workstations writing the pitch for the ORION-based “super-server” product.
The Legacy
Treatments of Norsk Data’s history often focus on the company’s beginnings and its successes, glossing over the company’s demise because a definitive ending is hard to pick out amidst the mess of its disintegration. At first, in efforts to restructure the business, bits of the company were sold off or spun out. Siemens Nixdorf picked up a division to strengthen its hand in the Norwegian public sector, with Nixdorf once having been a possible merger or acquisition target for Norsk Data itself. Intergraph picked up the Technovision CAD/CAM operation, perhaps as a way of acquiring and further developing its customer base. Dolphin Server Technology, spun out as a hardware company to develop products for Norsk Data and others, almost closed altogether but was picked up by a company owned by the Norwegian state telecoms operator soon to be known as Telenor.
Eventually, the rump of the business, having taken another name, followed Dolphin into Telenor’s hands, but not before dissatisfied former investors attempted to contest the acquisition and formulate a rival bid. It appears that Dolphin was largely run down by Telenor, but not before it was able to spin out another company, Dolphin Interconnect Solutions, that was making progress in developing Scalable Coherent Interface chipsets for shared memory multiprocessor machines. Another company in a similar vein, Numascale, also claims roots back to Norsk Data via Dolphin. Both these companies are still around today having thankfully escaped the bloated telecoms incumbent where new operations appear to come and go, like mere playthings of its executives and decadent, indulged management.
Similar remarks could be made about other companies when it comes to a lack of obvious finality. Smoke and mirrors around the closing months at Acorn Computers involved a renaming of the company followed by the sale of certain newly incubated activities to another company that would also acquire Acorn’s new name. That may have led some to believe that Acorn kept going, only to be acquired by one of the more notorious technology giants of today. In fact, the principal assets associated with Acorn were either sold off to interested parties or otherwise managed by holding companies until they were no longer lucrative or useful to the bank that did actually acquire Acorn. Of course, ARM is often touted as Acorn’s main legacy.
Interestingly, there is a slight crossover between Acorn’s later history and Norsk Data in the form of one of its founders. Lars Monrad-Krohn had been there at Norsk Data from the very beginning before pursuing enterprises more in the realm of microcomputing, establishing Mycron in the mid-1970s and delivering machines that mostly ran CP/M or MP/M. He then co-founded Tiki Data to produce an educational microcomputer, along the same lines as the BBC Micro, launching the Tiki-100 and various successors that struggled to compete against the increasingly ubiquitous IBM PC and compatibles. After that adventure, he turned to network computing and apparently secured distribution rights to Acorn’s NetStation in Norway, operating Norske Network Computing (NCNOR) as the vehicle for aspirations in this promising but ultimately unsuccessful offshoot of personal computing.
It might be said that microelectronics has been fertile ground for various Norwegian companies over the years. Nordic Semiconductor emerged from the academic environment in Trondheim, as did Falanx Microsystems which was acquired by ARM to give the chipmaker access to graphics acceleration technologies. Meanwhile, Chipcon and Energy Micro were founded in Oslo with various individuals being involved in both companies, both since sold to larger competitors and now all apparently consolidated within Texas Instruments. So, it is perhaps not surprising that those companies that do claim heritage from Norsk Data happen to operate in this part of the industry.
Of course, Norsk Data made more than processors and associated hardware technology. It was a complete systems manufacturer, developing the physical system units themselves along with the software that ran on them. An entire ecosystem from the microcode of the processors, up through the boot firmware and operating system, and beyond into the realm of compilers, tools and applications, had to be developed to deliver a product that customers could use. Evidently, much effort was applied, and much talent must have resided in the company, to put together a portfolio that included some sophisticated products. And regardless of one’s opinion of those products, the company must also have been a useful venue for those educated in computer science and engineering, along with other disciplines, to pursue their careers.
Indeed, one might say that Norsk Data, along with other companies and institutions of that time, was a channel for a kind of aspiration or ambition that might seem mundane to some today, but which had a seriousness that many of today’s technology “innovators” can only dream of projecting. The 1990s and 2000s did see notable software companies emerge from the technological scene in Norway, but following the “innovation” bandwagon now, much of it seems to revolve around hype, fuelled by an inbred culture promoting “innovation” in its own right (as opposed to supporting anyone making anything new), surveyed by commercial property vultures wanting a steady stream of clients for their office and co-working spaces.
There is “fintech” (financial technology, nothing to do with Norway’s unsustainable, ecologically harmful aquaculture industry), “proptech” (monetising property assets, because as in many other countries, wealth creation has become stuck on property investments and “passive income” rather than building productive industry), “medtech” (medical technology, often involving therapies, treatments or processes that promise a big payout if everything lines up just right), “edtech” (educational technology, often being more about shiny toys to distract children, burdensome systems to impose on educators, and probably a strong dose of data mining for questionable commercial exploitation), along with the ubiquitous, tiresome and ethically compromised “crypto” and “AI”.
In “developed” societies like Norway, and especially one that is not really short of money, one might imagine that ambitious, even noble, goals might be targeted by those looking to invest in technological endeavours. For a time, it would seem that plenty of opportunities were available for those looking to put their education to good use, trying to achieve and to build something meaningful and useful to wider society. Today, it seems that a lot of commerce is just chasing the latest fad or enabling dubious and even ruinous forms of economic activity. Governments pander to big technology corporations and promise to build power stations to effectively subsidise data centres that will inevitably churn out “slop” to further undermine society and democracy.
Search for Norsk Data now and you may stumble across a corporate entity with the name claiming expertise in data centres, “land and property management”, and “green power and energy solutions”, coining it from the demand for rackspace. Maybe it really is aiming for sustainable computing infrastructure, mentions of blockchain notwithstanding. Amongst its “innovations”, “drying of biofuel” sounds rather familiar from an article I read a while back, involving a cryptocurrency “mining” company that touted the very same thing, as if needlessly consuming colossal amounts of power is somehow excused by “a local lumberjack” getting some logs dried out. With such feeble greenwashing making the headline, leaning into the usual uncritical praise of all things Scandinavian, I think The Guardian’s editorial staff should be ashamed of themselves for having published such garbage.
The practical consequences to society of its leaders lack of vision, or even lack of effort, can be severe. Young people may not see an education as worthwhile if there are no viable opportunities to use that education. Others may see their own livelihoods undermined as investment is directed towards fads or the “guaranteed returns” associated with lazy asset-based speculation, whether that involves property or the latest fraudcoin. Meanwhile, decision-makers plead poverty when structural investments are required in society, claiming that the money isn’t there as they slash taxes for the wealthy (who constantly harp on about leaving the country, such patriots that they are), incentivise even more money pouring into property speculation, and then announce costly vanity projects in the hope that a big bridge, tunnel, property development, or a locally hosted Olympic games will be their legacy.
We have been here before, of course. When microelectronics started to transform industries, governments and other institutions made sincere attempts to determine the consequences, recommend measures, and undertake initiatives. Soon enough, rapid growth in the range of available commercial products led politicians to defer to the market, abandon many initiatives, and let the market dictate the direction technological adoption might take. Some might claim that Norsk Data was a victim of political abandonment and that the company should have been bailed out. One might more credibly claim that its management failed to respect the need that its customers had for interoperability and open standards, particularly in the public sector, and that its talent could have been more productively employed in other businesses instead.
But regardless of the fate of one company, it seems that we are currently experiencing yet another opportunity to be reminded that society, particularly through the government it elects, needs to create and sustain opportunities and industries to give individuals something useful and rewarding to do with their lives. It needs to cultivate viable enterprises that develop and maintain indigenous technology and expertise, to provide a form of technological sovereignty.
And through the cultivation of decently paid, meaningful work, society as a whole becomes wealthier, more resilient, and gives everyone a stake in the whole project, not just a few employees at an anointed company constantly watching the share price and contemplating the prospect of becoming rich. The project, of course, is to deliver a safe, stable and secure place to live and pursue one’s life, with the realisation that we all become poorer if people – particularly those who are wealthy through luck or privilege – are allowed to cash out and degrade the quality of society once they feel they no longer have a need for it. Ultimately, a strong society with meaningful opportunities and a pervasive, irrepressible sense of purpose should be every generation’s legacy.
Unix, the Minicomputer, and the Workstation
February 9th, 2026
Previously, I described the rise of Norsk Data in the minicomputer market and the challenges it faced, shared with other minicomputer manufacturers like Digital, but also mainframe companies like ICL and IBM, along with other technology companies like Xerox. Norsk Data may have got its commercial start in shipboard computers, understandable given Norway’s maritime heritage, but its growth was boosted by a lucrative contract with CERN to supply the company’s 16-bit minicomputers for use in accelerator control systems. Branching out into other industries and introducing 32-bit processors raised the company’s level of ambition, and soon enough Norsk Data’s management started seeing the company as a credible rival to Digital and other established companies.
Had the minicomputing paradigm remained ascendant, itself disrupting the mainframe paradigm, then all might have gone well, but just as Digital and others had to confront the emergence of personal computing, so did Norsk Data. Various traditional suppliers including Digital were perceived as tackling the threat from personal computers rather ineffectively, but they could not be accused of not having a personal computing strategy of their own. The strategists at Norsk Data largely stuck to their guns, however, insisting that minicomputers and terminals were the best approach to institutional computing.
Adamant that their NOTIS productivity suite and other applications were compelling enough reasons to invest in their systems, they tried to buy their way into new markets, ignoring the dynamics that were leading customers in other directions and towards other suppliers. Even otherwise satisfied customers were becoming impatient with the shortcomings of Norsk Data’s products and its refusal to engage substantially with emerging trends like graphical user interfaces, demonstrated by the Macintosh, a variety of products available for IBM-compatible personal computers, and the personal graphical workstation.
Worse is not Better
With Norsk Data’s products under scrutiny for their suitability for office applications, other deficiencies in their technologies were identified. The company’s proprietary SINTRAN III operating system still only offered a non-hierarchical filesystem as standard, with a conservative limit on the number of files each user could have. By late 1984, the Acorn Electron, my chosen microcomputer from the era, could support a hierarchical filesystem on floppy disks. And yet, here we have a “superminicomputer” belatedly expanding its file allowance in a simple, flat, user storage area from 256 files to an intoxicating 4096 on a comparatively huge and costly storage volume.
As one report noted, “a fundamental need with OA systems is for a hierarchical system”, which Norsk Data had chosen to provide via a separate NOTIS-DS (Data Storage) product, utilising a storage database that was generally opaque to the operating system’s own tools. A genuine hierarchical filesystem was apparently under development for SINTRAN IV, distinct from efforts to provide the hierarchical filesystem demanded by the company’s Unix implementation, NDIX.
SINTRAN’s advocates seem to have had the same quaint ideas about commands and command languages as advocates of other systems from the era, bemoaning “terse” Unix commands and its “powerful but obscure” shell. Some of them have evidently wanted to have it both ways, trotting out how the command to list files, being one that prompted the user in various ways, could be made to operate in a more concise and less interactive fashion if written in an abbreviated form. Commands and filenames could generally be abbreviated and still be located if the abbreviation could be unambiguously expanded to the original name concerned.
Of course, such “magic” was just a form of implicitly applying wildcard characters in the places where hyphens were present in an abbreviated name, and this could presumably have been problematic in certain situations. It comes across as a weak selling point indeed, at least if one is trying to highlight the powerful features of an operating system, rather than any given command shell. Especially when the humble Acorn Electron also supported things like abbreviated commands and abbreviated BASIC keywords, the latter often being a source of complaint by reviewers appalled at the effects on program readability.
For real-time purposes, SINTRAN III seemingly stacked up well against Digital’s RSX-11M, and offered a degree of consistency between Norsk Data’s 16- and 32-bit environments. Nevertheless, its largely satisfied users saw the benefits in what Unix could provide and hoped for an environment where SINTRAN and Unix could coexist on the same system, with the former supporting real-time applications.
Perhaps taking such remarks into account, Norsk Data commissioned Logica to port 4.2BSD to the ND-500 family. Due to the architecture of such systems, its Unix implementation, NDIX, would run on the ND-500 processor but lean on the ND-100 front-end processor running SINTRAN for peripheral input/output and other support, such as handling interrupts occurring on the ND-500 processor itself, introducing the notion of “shadow programs”, “shadow processes”, or “twin processes” running on the ND-100 to support the handling of page faults.
Burdening the 16-bit component of the system with the activity of its more powerful 32-bit companion processor seems to have led to some dissatisfaction with the performance of the resulting system. Claims of such problems, particularly in connection with NDIX, being resolved and delivering a better experience than a VAX-11/785 seem rather fragile given the generally poor adoption of NDIX and the company’s unwillingness to promote it. Indeed, in 1988, amidst turbulent times and the need to adapt to market realities, Unix at Norsk Data was something apparently confined to Intel-based systems running SCO Unix and merely labelled up to look like models in the ND-5000 range that had succeeded the ND-500.
Half-hearted adoption of Unix was hardly confined to Norsk Data. Unix had been developed on Digital hardware and that company had offered a variant for its PDP-11 systems, but it only belatedly brought its VAX-based product, Ultrix, to that system in 1984, seven years after the machine’s introduction. Even then, certain models in various ranges would not support Ultrix, or at least not initially. Mitigating this situation was the early and continuing availability of the Berkeley Software Distribution (BSD) for the platform, this having been the basis for Ultrix itself.
Mainframe incumbents like IBM and ICL were also less than enthusiastic about Unix, at least as far as those mainframes were concerned. ICL developed a Unix environment for its mainframe operating system before going round again on the concept and eventually delivering its VME/X product to a market that, after earlier signals, perhaps needed to be convinced that the company was truly serious about Unix and open systems.
IBM had also come across as uncommitted to Unix, in contrast to its direct competitor in the mainframe market, Amdahl, whose implementation, UTS, had resulted from an early interest in efforts outside the company to port Unix to IBM-compatible mainframe hardware. IBM had contracted Interactive Systems Corporation to do a Unix port for the PC XT in the form of PC/IX, and as a response to UTS, ISC also did a port called IX/370 to IBM’s System/370 mainframes. Thereafter, IBM would partner with Locus Computing Corporation to make AIX PS/2 for its personal computers and, eventually in 1990, AIX/370 to update its mainframe implementation.
IBM’s Unix efforts coincided with its own attempts to enter the Unix workstation market, initially seeing limited success with the RT PC in 1985, and later seeing much greater success with the RS/6000 series in 1990. ICL seemed more inclined to steer customers favouring Unix towards its DRS “departmental” systems, some of which might have qualified as workstations. Both companies increasingly found themselves needing to convince such customers that Unix was not just an afterthought or a cynical opportunity to sell a few systems, but a genuine fixture in their strategies, provided across their entire ranges. Nevertheless, ICL maintained its DRS range and eventually delivered its DRS 6000 series, allegedly renamed from DRS 600 to match IBM’s model numbering, based on the SPARC architecture and System V Unix.
A lack of enthusiasm for Unix amongst minicomputer and mainframe vendors contrasted strongly with the aspirations of some microcomputer manufacturers. Acorn’s founder Chris Curry articulated such enthusiasm early in the 1980s, promising an expansion to augment the BBC Micro and possibly other models that would incorporate the National Semiconductor 32016 processor and run a Unix variant. Acorn’s approach to computer architecture in the BBC Micro was to provide an expandable core that would be relegated to handling more mundane tasks as the machine was upgraded to newer and better processors, somewhat like the way a microcontroller may be retained in various systems to handle input and output, interrupts and so on.
(Meanwhile, another microcomputer, the Dimension 68000, took the concept of combining different processors to an extreme, but unlike Acorn’s more modest approach of augmenting a 6502-based system with potentially more expensive processor cards, the Dimension offered a 68000 as its main processor to be augmented with optional processor cards for a 6502 variant, Z80 and 8086, these providing “emulation” capabilities for Apple, Kaypro and IBM PC systems respectively. Reviewers were impressed by the emulation support but unsure as to the demand for such a product in the market. Such hybrid systems seem to have always been somewhat challenging to sell.)
Acorn reportedly engaged Logica to port Xenix to the 32016, despite other Unix variants already existing, including Genix from National itself along with more regular BSD variants seen on the Whitechapel MG-1. Financial and technical difficulties appear to have curtailed Acorn’s plans, some of the latter involving the struggle for National to deliver working silicon, but another significant reason involves Acorn’s architectural approach, the pitfalls of which were explored and demonstrated by another company with connections to Acorn from the early 1980s, Torch Computers.
Tasked with covering the business angle of the BBC Micro, Torch delivered the first Z80 processor expansion for the system. The company then explored Acorn’s architectural approach by releasing second processor expansions that featured the Motorola 68000, intended to run a selection of operating systems including Unix. Although products were brought to market, and some reports even suggested that Torch had become one of the principal Unix suppliers in the UK in selling its Unicorn-branded expansions, it became evident that connecting a more powerful processor to an 8-bit system and relying on that 8-bit system to be responsible for input and output processing rather impeded the performance of the resulting system.
While servicing things like keyboards and printers were presumably within the capabilities of the “host” 8-bit system, storage needed higher bandwidth, particularly if hard drives were to be employed, and especially if increasingly desirable features such as demand paging were to be available in any Unix implementation. Torch realised that to remedy such issues, they would need to design a system from scratch, with the main processor and supporting chips having direct access to storage peripherals, leaving pretty much all of the 8-bit heritage behind. Their Triple-X workstation utilised the 68010 and offered a graphical Unix environment, elements of which would be licensed by NeXT for its own workstations.
Out of Acorn’s abandoned plans for a range of business machines, the company’s Cambridge Workstation, consisting of a BBC Micro with the 32016 expansion plus display, storage and keyboard, ran a proprietary operating system that largely offered the same kind of microcomputing paradigm as the BBC Micro, boosted by high-level language compilers and tools that were far more viable on the 32016 than the 6502. Nevertheless, Unix would remain unsupported, the memory management unit omitted from delivered forms of the Cambridge Workstation and related 32016 expansion. Eventually, Acorn would bring a more viable product to market in the form of its R-series workstations: entirely 32-bit machines based on the ARM architecture, albeit with their own shortcomings.
Norsk Data had also contracted out its Unix porting efforts to Logica, but unlike IBM, who had grasped the nettle with both hands to at least give the impression of taking Unix support seriously, Norsk Data took on the development of NDIX and seemingly proceeded with it begrudgingly, only belatedly supporting the models that were introduced. Even in captive markets where opportunities could be engineered, such as in the case of one initiative where Norsk Data systems were procured by the Norwegian state under a dubious scheme that effectively subsidised the company through sales of systems and services to regional computing centres, the models able to run NDIX were not necessarily the expensive flagship models that were sold in. With limited support for open systems and an emphasis on the increasingly archaic terminal-based model of providing computing services, that initiative was a costly failure.
Had NDIX been a compelling product, Norsk Data would have had a substantial incentive to promote it. From various documents, it seems that a certain amount of the NDIX development work was carried out at Norsk Data’s UK subsidiary, perhaps suffering in the midst of Wordplex-related intrigues towards the end of the 1980s. But at CERN, where demand might have been more easily generated, NDIX was regarded as “not being entirely satisfactory” after two years of effort trying to deliver it on the ND-500 series. The 16-bit ND-100 front-end processor was responsible for input and output, including to storage media, and the overheads imposed by this slower, more constrained system, undermined the performance of Unix on the ND-500.
Norsk Data, in conjunction with its partners and customers, had rediscovered what Torch had presumably identified in maybe 1984 or 1985 before that company swiftly pivoted to a new systems architecture to more properly enter the Unix workstation business at the start of 1986. One could argue that the ND-5000 series and later refinements, arriving from 1987 onwards, would change this situation somewhat for Norsk Data, but time and patience were perhaps running out even in the most receptive of environments to these newer developments.
The Spectre of the Workstation
The workstation looms large in the fate of Norsk Data, both as the instrument of its demise as well as a concept the company’s leadership never really seemed to fathom. Already in the late 1970s, the industry was being influenced by work done at Xerox on systems such as the Alto. Companies like Three Rivers Computer Corporation and Apollo Computer were being founded, and it was understandable that others, even in Norway, might be inspired and want a piece of the action.
To illustrate how the fate of many of these companies is intertwined, ICL had passed up on the opportunity of partnering with Apollo, choosing Three Rivers and adopting their PERQ workstation instead. At the time, towards the end of the 1970s, this seemed like the more prudent strategy, Three Rivers having the more mature product and being more willing to commit to Unix. But Apollo rapidly embraced the Motorola 68000 family, while the PERQ remained a discrete logic design throughout its commercial lifetime, eventually being described as providing “poor performance” as ICL switched to reselling Sun workstations instead.
Within Norsk Data, several engineers formulated a next-generation machine known as Nord-X, later deciding to leave the company and establish a new enterprise, Sim-X, to make computers with graphical displays based on bitslice technology, rather like machines such as the Alto and PERQ. One must wonder whether even at this early stage, a discussion was had about the workstation concept, only for the engineers to be told that this was not an area Norsk Data would prioritise.
Sim-X barely gets a mention in Steine’s account of the corporate history (“Fenomenet Norsk Data”, “The Norsk Data Phenomenon”), but it probably involves a treatment all by itself. The company apparently developed the S-2000 for graphical applications, initially for newspaper page layout, but also for other kinds of image processing. Later, it formed the basis of an attempt to make a Simula machine, in the same vein as the once-fashionable Lisp machine concept. Although Sim-X failed after a few years, one of its founders pursued the image processing system concept in the US with a company known as Lightspeed. Frustratingly minimal advertising for, and other coverage of, the Lightspeed Qolor can be found in appropriate industry publications of the era.
Since certain industry trends appear to have infiltrated the thinking at Norsk Data and motivated certain strategic decisions, it was not surprising that its early workstation efforts were focused on specific markets. It was not unusual for many computer companies in the early 1980s to become enthusiastic about computer-aided design (CAD) and computer-aided manufacturing (CAM). Even microcomputer companies like Acorn and Commodore aspired to have their own CAD workstation, focused on electronic design automation (EDA) and preferably based on Unix, largely having to defer its realisation until a point in time when they had the technical capabilities to deliver something credible.
Norsk Data had identified a vehicle for such aspirations in the form of Dietz Computer Systems, producer of the Technovision CAD system for mechanical design automation. This acquisition seemed to work well for the combined company, allowing the CAD operation to take advantage of Norsk Data’s hardware and base complete CAD systems on it. Such special-purpose workstations were arguably justifiable in an era where particular display technologies were superior for certain applications and where computing resources needed to be focused on particular tasks. However, more versatile machines, again inspired by the Alto and PERQ, drove technological development and gradually eliminated the need to compromise in the utilisation of various technologies. For instance, screens could be high-resolution, multicolour and support vector and bitmap graphics at acceptable resolutions, even accelerating the vector graphics on a raster display to cater to traditional vector display applications.
In its key scientific and engineering markets, Norsk Data had to respond to industry trends and the activities of its competitors. Hewlett-Packard may have embraced Unix and introduced PA-RISC to its product ranges in 1986, largely to Norsk Data’s apparent disdain, but it had also introduced an AI workstation. Language system workstations had emerged in the early 1980s, initially emphasising Pascal as the PERQ had done. Lisp machines had for a time been all the rage, emphasising Lisp as a language for artificial intelligence, knowledge base development, and for application to numerous other buzzword technologies of the era, empowering individual users with interactive, graphical environments that were meant to confer substantial productivity benefits.
Thus, Norsk Data attempted to jump on the Lisp machine bandwagon with Racal, the company that would produce the telecoms giant Vodafone, hoping to leverage the ability to microcode the ND-500 series to produce a faster, more powerful system than the average Lisp machine vendor. Predictably, claims were made about this Knowledge Processing System being “10 to 20 times more powerful than a VAX” for the intended applications. Reportedly, the company delivered some systems, although Steine contradicts this, claiming that the only system that was sold – to the University of Oslo – was never delivered. This is not entirely true, either, judging from an account of a “a burned-up backplane” in the KPS-10 delivered to the Institute for Informatics. Intriguingly, hardware from one delivered system has since surfaced on the Internet.
One potentially insightful article describes the memory-mapped display capabilities of the KPS-10, supporting up to 36 bitmapped monochrome screens or bitplanes, with the hardware supposedly supporting communications with graphical terminals at distances of 100 metres, suggesting that, once again, the company’s dogged adherence to the terminal computing paradigm had overridden any customer demand for autonomous networked workstations. It had been noted alongside the ambitious performance claims that increased integration using gate arrays would make a “single-user work station” possible, but such refinements would only arrive later with the ND-5000 series. In the research community, Racal’s brief presence in the AI workstation market, aiming to support Lisp and Prolog on the ND-500 hardware, left users turning to existing products and, undoubtedly, conventional workstations once Racal and Norsk Data pulled out.
With Norsk Data having announced a broader collaboration with Matra in France, the two companies announced a planned “desktop minisupercomputer” emphasising vector processing, which is another area where competing vendors had introduced products in venues like CERN, threatening the adoption of Norsk Data’s products. Although the “minisupercomputer” aspect of such an effort might have positioned the product alongside other products in the category, the “desktop” label is a curious one coming from Norsk Data. Perhaps the company had been made aware of systems like the Silicon Graphics IRIS 4D and had hoped to capture some of the growing interest in such higher-performance workstations, redirecting that interest towards their own products and advocating for solutions similar to that of the KPS-10. In any case, nothing came of the effort, and so the company had nothing to show.
The intrusion of categories like “desktop” and “workstation” into Norsk Data’s marketing will have been the result of shifting procurement trends in venues like CERN. From being a core vendor to CERN, contracted to provide hardware under non-competitive arrangements, conditions in the organisation had started to change, and with efforts ramping up on the Large Electron-Positron collider (LEP), procurement directed towards workstations also started to ramp up. Initially, Apollo featured prominently, gaining from their “first mover” advantage, but they were later joined by Sun Microsystems. Even IBM’s PC RT had appealed to some in the organisation. And despite Digital being perceived as a minicomputer company, it was still managing to sell VAXstations into CERN.
One has to wonder what Norsk Data’s sales representatives in France must have made of it all. Hundreds of workstations from other companies being bought in, millions of Swiss francs being left on the table, and yet the models being brought to market for them to sell were based on the Butterfly workstation concept, featuring Technostation models for CAD and Teamstation models for NOTIS, neither of them likely to appeal to people looking beyond the personal computer and wanting workstation capabilities on their desk. A Butterfly workstation based on the 80286 running NOTIS on a 16-bit minicomputer expansion card must have seemed particularly absurd and feeble.
Increased integration brought the possibilities of smaller deskside systems from Norsk Data, with the ND-5800 and later models perhaps being more amenable to smaller workloads and workstation applications. But it seems that the mindset persisted of such systems being powerful minicomputers to be shared, rather than powerful workstations for individuals. Graphics cards embedding Motorola 68000 family processors augmented Technovision models targeting the CAD market, but as the end of the 1980s beckoned, such augmentations fell rather short of the kind of hardware companies like Sun and Silicon Graphics were offering. Meanwhile, only the company’s lower-end models could sell at around the kind of prices set by the mainstream workstation vendors, but with low-end performance to match.
In a retrospective of the company, chief executive Rolf Skår remarked that the workstation vendors had deliberately cut margins instead of charging what was considered to be the value of a computer for a particular customer, which is perhaps another way of describing a form of pricing where what the market will bear determines how high the price will be set, squeezing the customer as much as possible. The article, featuring an erroneous figure for the price of a typical Norsk Data computer (100,000 Norwegian crowns, being broadly equivalent to $10,000) misleads the reader into thinking that the company’s machines were not that expensive after all and even competitive on price with a typical Sun workstation.
Evidently, there was confusion from Skår or the writer about the currencies involved, and such a computer would tend to cost more like 1 million crowns or $100,000: ten times that of the most affordable workstations. Norsk Data’s top-end machines ballooned in price in the mid-1980s, costing up to $500,000 for some single-processor models, and potentially $1.5 million for the very top-end four-processor configurations. Even with Sun introducing its first SPARC-based model at around $40,000, it could still outperform such “peak minicomputer” VAX and Norsk Data models and sell at a tenth of the price.
Norsk Data’s opportunistic pricing presumably tracked that of its big rival, Digital, and its own pricing of VAX models, sensing that if promoted as faster or better than the VAX, then potential customers would choose the Norsk Data machine, pricing and other characteristics being generally similar. When companies might have bought into a system with a big investment in information technology, this might have been a viable strategy, but as such technology became cheaper and available from numerous other providers, it became harder even for Digital to demand such a premium.
One can almost sense a sort of accusation that the workstation manufacturers ruined it for everyone, cheapening an otherwise lucrative market, but workstations were, of course, just another facet of the personal computing phenomenon and the gradual democratisation of computing itself. In the end, customers were always going to choose systems that delivered the computing power and user experience they desired, and it was simply a matter of those companies identifying and addressing such desires and needs, making such systems available at steadily more affordable prices, eventually coming to dominate the market. That Norsk Data’s management failed to appreciate such emerging trends, even when spelled out in black and white in procurement plans involving considerable sums of money, suggests that the blame for the company’s growth bonanza eventually coming to an end lay rather closer to home.
The Performance Game
With the ND-500 series, Norsk Data had been able to deliver floating-point performance that was largely competitive within the price bracket of its machines, and favourable comparisons were made between various ND-500 models and those in the VAX line-up, not entirely unjustifiably. Manufacturers who had not emphasised this kind of computation in their products found some kind of salvation in the form of floating-point processors or accelerators, made available by specialists like Mercury Computer Systems and Floating Point Systems, aided by the emergence of floating-point arithmetic chips from AMD and Weitek.
Presumably to fill a gap in its portfolio, Digital offered the Floating Point Systems accelerators in combination with some models. Meanwhile, the company had improved the performance of its VAX 8000 series to ostensibly eliminate many of Norsk Data’s performance claims. And curiously, Matra, who were supposed to be collaborating with Norsk Data on a vector computer, even offered the FPS products with the Norsk Data systems it had been selling, presumably to remedy a deficiency in its portfolio, but it is difficult to really know with a company like Matra.
Prior to the introduction of the ND-5000 series in 1987, Norsk Data had largely kept pace with their perceived competitors, alongside a range of other companies emphasising floating-point computation, but the company now needed to re-establish a lead over those competitors, particularly Digital. The ND-5000 series, employing CMOS gate array technology, was labelled as a “vaxkiller” in aggressive publicity but initially fell short of Norsk Data’s claims of better performance than the two-processor VAX 8800.
Using the only figures available to us, the top-end single-processor ND-5800 managed only 6.5 MWIPS and thus around 5 times the performance of the original VAX-11/780. In contrast, the dual-processor VAX 8800 was rated at around 9 times faster than its ancestor, with the single-processor VAX 8700 (later renamed to 8810) rated at around 6 times faster. All of these machines cost around half a million dollars. And yet, 1987 had seen some of the more potent first-generation RISC systems arrive in the marketplace from Hewlett-Packard and Silicon Graphics, both effectively betting their companies on the effectiveness of this technological phenomenon.
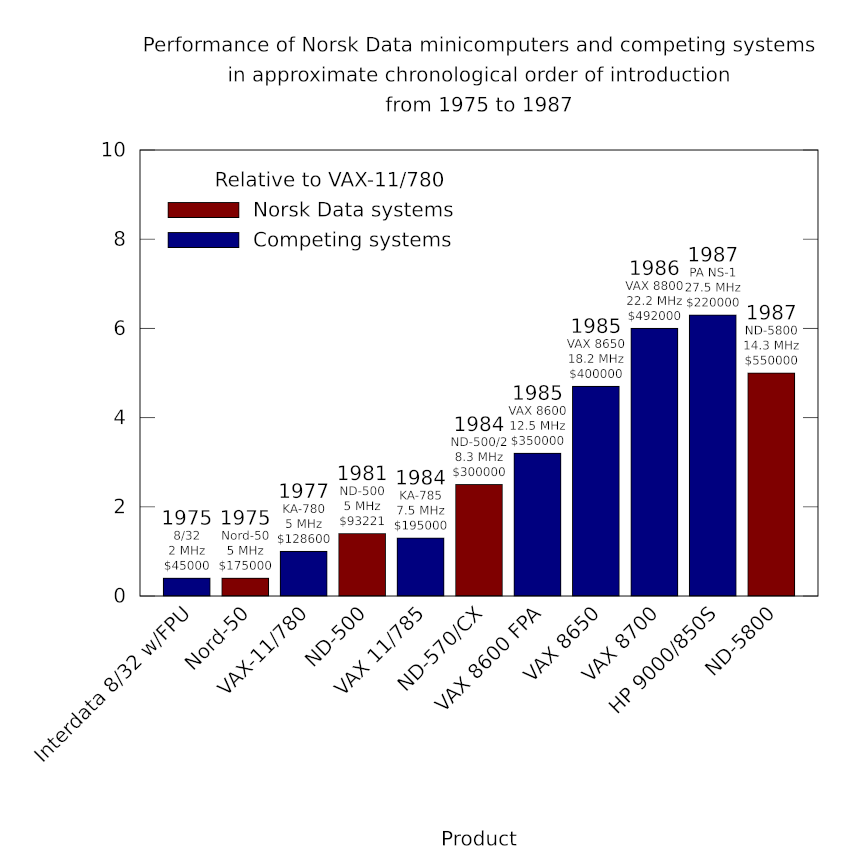
The performance of Norsk Data minicomputers and their competitors from 1975 to 1987. Although the ND-500 models were occasionally faster than the VAX machines at floating-point arithmetic, according to Whetstone benchmark results, Digital steadily improved its models, with the VAX 8700 of 1986 introducing similar architectural improvements to those introduced in the ND-5000 processors. Note how one of Hewlett-Packard’s first PA-RISC systems makes its mark alongside these established architectures.
Just as Digital’s management had kept RISC efforts firmly parked in the realm of “research”, even with completed RISC systems running Unix and feeding into more advanced research, Norsk Data’s technical leadership publicly dismissed RISC as a fad and their RISC competitors as unimpressive, even though the biggest names in computing – IBM, HP and Motorola – were at that very moment, formulating, developing and even delivering RISC products that threatened Norsk Data’s own products. RISC processors influenced and transformed the industry, and as the 1990s progressed, further performance gains were enabled by RISC architectural design principles.
To be fair to the designers at both Digital and Norsk Data, they also incorporated techniques often associated with RISC, just as Motorola had done while still downplaying the RISC phenomenon. The VAX 8800 and ND-5800 thus incorporated architectural improvements over their predecessors, such as pipelining, that provided at least a doubling of performance. The ND-5000 ES range, announced in 1988 and apparently available from 1989, were claimed to deliver another doubling in performance, seemingly through increasing the operating frequency. This, however, would merely put such server products alongside relatively low-cost RISC workstations using the somewhat established MIPS R2000 processor.
With Digital’s VAX 9000 project stalling, it was left to the CVAX, Rigel and NVAX processors to progressively follow through with the enhancements made in the VAX 8800, propagating them to more highly integrated processors and producing considerably faster and cheaper machines towards the end of the 1980s and into the early 1990s. But this consolidation, starting with the VAX 6000 series, and the accompanying modest gains in performance led to customer unease about the trailing performance of VAX systems, particularly amongst those customers interested in running Unix.
Thus, Digital introduced workstations and servers based on the MIPS architecture, delivering a performance boost almost immediately to those customers. A VAX 6000 processor could deliver around 7 times the performance of the original VAX-11/780, whereas a MIPS R2000-based DECstation 3100 could deliver around 11 times the performance. Crucially, such systems did not cost hundreds of thousands of dollars, but mere tens of thousands, with the lowest-end workstations costing barely ten thousand dollars.
To keep pace with these threats, it seems that Norsk Data’s final push involved a ramping up of the ND-5830 “Rallar” processor from an operating frequency of 25MHz to 45MHz in 1990 or so, just as the MIPS R3000 was proliferating in products from several vendors at more modest 25MHz and 33MHz frequencies but still nipping at the heels of this final, accelerated ND-5850 product. MIPS would suffer delays and limited availability of faster products like the R6000, also bringing consequences to the timely delivery of its 64-bit R4000 architecture. Nevertheless, products from IBM in its emerging RS/6000 range would arrive in the same year and demonstrate comprehensively superior performance to Norsk Data’s entire range.
Whetstone benchmark figures, particularly for the latter ND-5830 and ND-5850, are impressive. However, there may be caveats to claims of competitive performance. In one case, a ND-5800 system was reported as running a computational model in around 5 minutes with one set of parameters and 70 minutes with another. Meanwhile, the same inputs required respective running times of around 9 minutes and 78 minutes on a VAXstation 3500. The VAXstation 3500 was a 3 MWIPS system, whereas the ND-5800 was rated at around 6.5 MWIPS, and yet for a larger workload, it seems that any floating-point processing advantage of the ND-5800 was largely eliminated.
As for the integer or general performance of the ND-500 and ND-5000 families, Norsk Data appear to have been evasive. The company used “MIPS” to mean Whetstone MIPS, measuring floating-point performance, which was perhaps excusable for “number crunchers” but less applicable to other applications and a narrow measure that gave way to others over time, anyway. Otherwise, “relative performance” measures and numbers of users were often given, leaving us to wonder how the systems actually stacked up. LINPACK benchmark figures are few and far between, which is odd given the emphasis Norsk Data made on numerical computation when promoting the systems.
Another benchmark employed by Norsk Data concerned the company’s pivot to the “transaction processing” market with their high-end systems. Introducing the tpServer series based on its final ND-5000 range, the company stated a TP1 benchmark score of 10 transactions per second for its single-processor ND-5700 model, with a relative performance factor suggesting around 30 transactions per second for its single-processor ND-5850 model. Interestingly, its Uniline 88 range, introduced as the company also pivoted to more mainstream technology, was based on the Motorola 88000 architecture and also appears to have offered around 30 transactions per second, with similar scalability options involving up to four processors as with its tpServer and other traditional products.
The MC88100 used in the Uniline 88 showed similar general performance to competitors using the MIPS R3000 and SPARC processors, so we might conclude that the ND-5850 may have been comparable to and competitive with the mainstream at the turn of the 1990s. But this would mean that the ND-5000 series no longer offered any hope of differentiating itself from the mainstream in terms of performance. With Unix not being prioritised for the series, either, further development of the platform must have started to look like a futile and costly exercise, appealing to steadily fewer niche customers and gradually losing the revenue necessary for the substantial ongoing investment needed to keep it competitive. Switching to the 88000 family would give comparable performance, established and accepted Unix implementations, and broader industry support.
The ND-5850 arrived at a time when the MIPS R6000 and products from other industry players were experiencing difficulties in what might be considered a detour into emitter-coupled logic (ECL) fabrication, motivated by the purported benefits of the technology, somewhat replaying events from earlier times. Back in 1987, Norsk Data, had reportedly resisted the temptation to adopt ECL, sticking with the supposedly “ignored” (but actually ubiquitous) CMOS technology, and advertising this wisdom in the press. MIPS and Control Data Corporation would eventually bring the R6000 to market, but with far less success than hoped.
History would run full circle, however, and with the ND-5000 architecture having been consigned to maintenance status, and with Norsk Data having adopted the Motorola 88000 architecture for future high-end products, the engineering department of Norsk Data, spun-out into a separate company, would describe its plans of developing a superscalar variant of the 88000 to be fabricated in ECL and known as ORION. Perhaps not unsurprisingly, such plans met insurmountable but unspecified technical obstacles, and the product effectively evaporated, ending all further transformative aspirations in the processor business. Meanwhile, MIPS would, from 1992 onwards, at least have the consolation of delivering the 64-bit R4000 to market, aided by its CMOS fabrication partners.
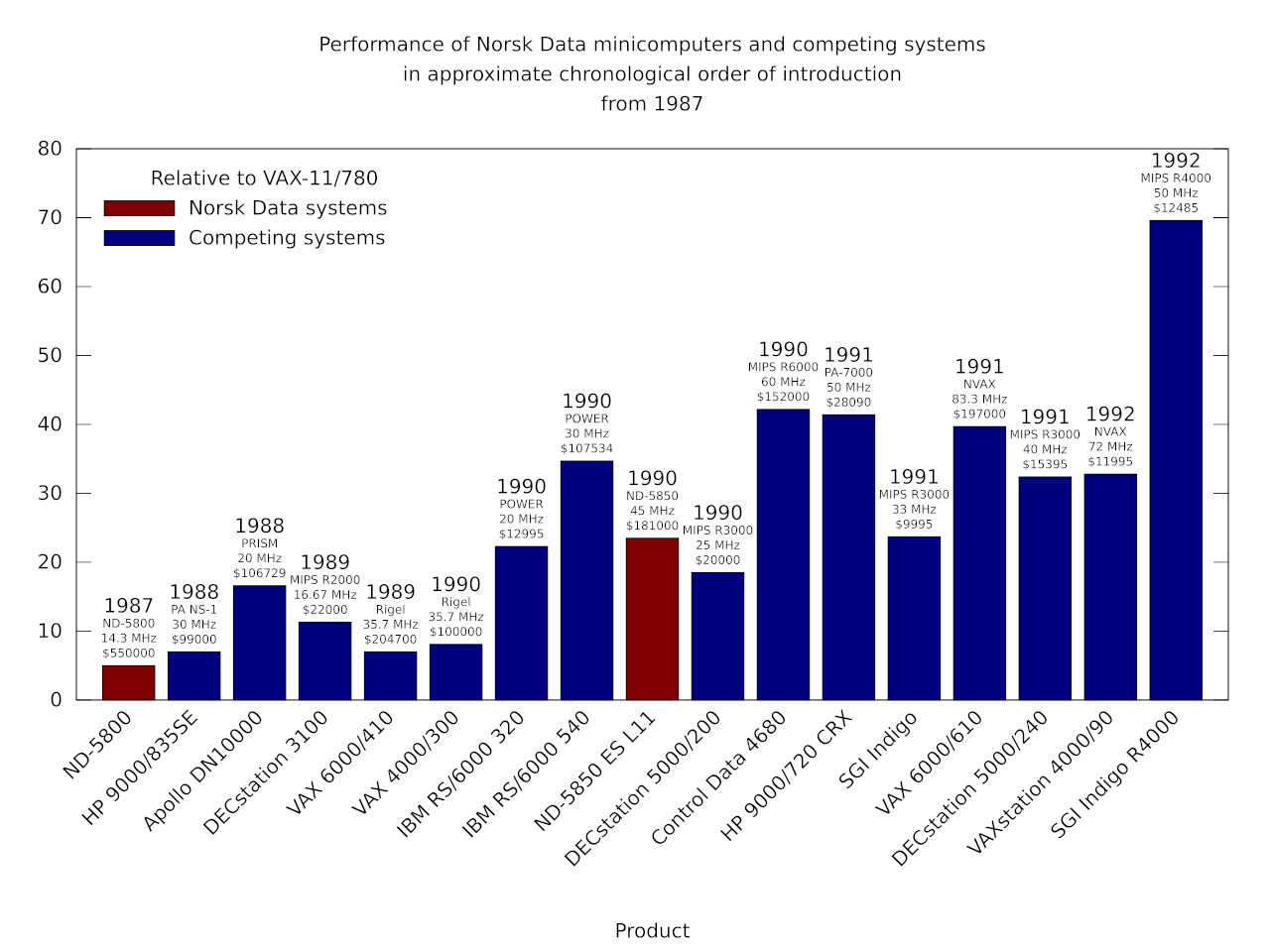
The performance of Norsk Data minicomputers and their competitors from 1987 onwards. The steady introduction of RISC products from Hewlett-Packard, Apollo Computer, Digital, IBM and others made the competitive landscape difficult for a low-volume manufacturer like Norsk Data. The company was soon having to contend with far cheaper workstation products from its competitors delivering comparable or superior performance (typically measured using SPECmark or SPECfp92 benchmarks here). Digital’s VAX products were also steadily improved and cost-reduced, but were eventually phased out in favour of Digital’s Alpha systems. In 1992, somewhat delayed, the MIPS R4000 appeared in systems like the SGI Indigo, offering a doubling of performance and maintaining the relentless pace of mainstream processor development.
Regardless, of whether specific Norsk Data products were better than specific products from its competitors, one is left wondering about that idea of Norsk Data making floating-point accelerators for other systems. After all, the ND-500 and ND-5000 processors were effectively accelerators for Norsk Data’s own 16-bit systems. And with that path having been taken, one might wonder whether the company would be the one having its offerings bundled by the likes of Digital. That a focus on such a market might have driven development at a faster tempo, pushing the company into the territory of floating-point specialists, minisupercomputers, and a lucrative market that would last until general-purpose products remedied their floating-point deficiencies, coupled with the rise of the RISC architectures.
Splitting off the floating-point expertise and coupling it with a variety of architectures in the form of a floating-point unit could have been an option. Indeed, Weitek, who had made such products the focus of their business apparently fabricated some of Norsk Data’s floating-point hardware for its later machines. Maybe there was good money in VLSI-fabricated Norsk Data accelerators for personal computers and workstations without great numeric processing options.
One might also wonder whether Norsk Data could have coupled its expertise in floating-point processing with an attractive instruction set architecture. Sadly, the company seemed wedded to the ND-500 architecture for compatibility reasons, involving an operating system that was not attractive to most potential customers, along with software that should have been portable and may not have been as desirable as perceived, anyway. Protecting the mirage of competitive advantage locked one form of expertise and potential commercial exploitation into others that were impeding commercial success.
The designers of the ND-5000 may have insisted that they could still match RISC designs even with their “complex instructions”, but Digital’s engineers had already concluded that their own comparable efforts to streamline VAX performance, achieving four- or five-fold gains within a couple of years, would remain inherently disadvantaged by the need to manage architectural complexity:
“So while VAX may “catch up” to current single-instruction-issue RISC performance, RISC designs will push on with earlier adoption of advanced implementation techniques, achieving still higher performance. The VAX architectural disadvantage might thus be viewed as a time lag of some number of years.”
In jettisoning the architectural baggage of the ND-500 architecture, Norsk Data’s intention was presumably to be able to more freely apply its expertise to the 88000 architecture, but all of this happened far too late in the day. To add insult to injury, it also involved the choice of what proved to be another doomed processor architecture.
Common Threads of Minicomputing History
January 9th, 2026
In the past few years, in my exploration of computing history, the case of the Norwegian computing manufacturer Norsk Data has been a particular fascination. Growing up in 1980s Britain, it is entirely possible that the name will have appeared in newspapers and magazines I may have seen or read, although I cannot remember any particular occurrences. It is also easy to mix it up with Nokia Data: a company that was eventually acquired by the United Kingdom’s own computing behemoth, ICL.
Looking back, however, and it turns out that Norsk Data even managed to get systems into institutions not too many miles from where I grew up, and the company did have a firm commercial presence in the UK, finding niches in various industries and forms of endeavour. Having now lived in Norway for a considerable amount of time, it is perhaps more surprising that Norsk Data is almost as forgotten, and leaves almost as few traces, in its home country.
When I arrived in Norway, I gave no thought whatsoever to Norsk Data, even though I had been working at an organisation that had been one of the company’s most prominent customers and the foundation for its explosive growth during the 1970s and 1980s. But my own path through the Norwegian computing sector may well have crossed those of the company’s many previous employees, and in fact, one former employer of mine was part of a larger group that had acquired parts of the disintegrating Norsk Data empire.
It might come as a surprise that a company with over 4000 employees at its peak, many of them presumably in Oslo, and with annual revenues of almost 3 billion Norwegian crowns (around $450 million), would crumble within years and leave so little behind to show for itself. Admittedly, some of the locations of the company’s facilities have been completely redeveloped in recent years. But one might have expected an enduring cultural or social legacy.
In looking back, we might make some observations about a phenomenon that shares certain elements with events in other countries and other companies, along with more general observations about technological aspiration, contrasting the aspirations of that earlier era with today’s “innovation” culture, where companies arguably have much more mundane goals.
Big Claims by Small People
One of my motivations for looking into the history of Norsk Data arose from studying some of the rhetoric about its achievements and its influences on mainstream technology and wider society, these intersecting with CERN and the World Wide Web. There are some that have dared to claim that the Web was practically invented on Norsk Data systems, and with that, imaginations run riot and other bold claims are made. I personally strongly dislike such behaviour.
When Apple devotees, for example, insist that Apple invented a range of technologies, the obligation is then put on others to correct the ignorant statements concerned and to act to prevent the historical record from being corrupted. So, no, Apple did not “invent” overlapping windows. And when corrected, one finds oneself obliged to chase down all the usual caveats and qualifications in response that are so often condensed into “but really they did”. So, no, Apple were not the first to demonstrate systems where the background windows remained “live” and updated, either.
Why can’t people be satisfied with the achievements that were made by their favourite companies? Is it not enough to respect the work actually done, instead of extrapolating and maximising a claim that then extends to a claim of “invention” and thus dominance? Such behaviour is not only disrespectful to the others who also did such work and made such discoveries, potentially at an earlier time, but it is disrespectful to the collaborative environment of the era, many of whose participants would not have seen themselves as adversaries. It is even disrespectful to the idols of the devotees making their exaggerated claims.
And if people revisited history, instead of being so intent on rewriting it, they might learn that such claims were litigated – literally – in decades past. Attempts to exclude other companies from delivering common technologies left Apple with little more than a trashcan. Maybe the company’s lawyers had wished that the perverse gesture of dragging a disk icon to a dustbin icon to eject a floppy disk might, for once, have just erased the company’s opportunistic, wasteful and flimsy lawsuit.
Questions of Heritage
What intrigued me most were some of the claims by Norsk Data itself. The company started out in the late 1960s, introducing the Nord-1, a 16-bit minicomputer, for industrial control applications. Numerous claims of “firsts” are made for that model in the context of minicomputing (virtual memory, built-in floating-point arithmetic support), perhaps contentious and subject to verification themselves, but it was the introduction of its successor where such claims start to tread on more delicate territory.
The Nord-5, introduced in 1972, has occasionally been claimed as the first 32-bit minicomputer. In fact, it could only operate in conjunction with a Nord-1, with the combination potentially being regarded as a minicomputing system. At the time, and for the handful of customers involved, this combination was described as the NORDIC system: a name that was apparently not used much if ever again. In practice, this was one or more 16-bit minicomputers with an attached 32-bit arithmetic processor.
Such clarifications might seem pedantic, but people do have strong opinions on such matters. Whereas Digital Equipment Corporation’s VAX, introduced in 1977, might be regarded as an influential machine in the proliferation of 32-bit minicomputing, occasionally and incorrectly cited as the first system of its kind, it is generally conceded that the Interdata 7/32 and 8/32, introduced in 1973, have a more substantial claim on any such title. Certainly, these may well have been the first minicomputers priced at $10,000 or below. Meanwhile, the NORDIC system cost over $600,000 for the Norwegian Meteorological Institute to acquire.
One might argue that NORDIC was not a typical minicomputing system, nor priced accordingly. And it does raise the observation that if one is to attach a component with certain superior characteristics to an existing component, as much as this attached component complements the capabilities of the existing component, the combination is not necessarily equivalent to a coherent system built entirely with such superior characteristics in the first place. We may return to this topic later, not least because certain phenomena have a habit of recurring in the computing industry.
As much as one might say in categorising the Nord-5, it was an interesting machine. Thanks to those who took an interest in archiving Norsk Data’s heritage, we are able to look at descriptions of the machine’s architecture, its instruction set, and so on. For those who have encountered systems from an earlier time and found them constraining and austere, the Nord-5 is surprising in a few ways. Most prominently, it has 64 general-purpose registers of 32 bits in size, pairs of which may be grouped to form 64-bit floating-point registers where required.
The Nord-5 has only a small number of instruction formats, although some of them seem rather haphazardly organised. It turns out that this is where the machine’s implementation, based heavily on discrete logic integrated circuits and the SN74181 arithmetic logic unit in particular, dictates the organisation of the machine. One might have thought that the limitations of the technology would have restrained the designers, making them focus on a limited feature set so as to minimise chip count and system cost, but exotic functionality exists that is difficult to satisfactorily explain or rationalise at first glance.
For instance, indirect addressing, familiar from various processor architectures, tends to involve an instruction accessing a particular memory location (or pair of locations), reading the contents of that location (or those locations), and then treating this value (or those values) as a memory address. Normally, one would then operate on the contents of this final address. However, in the Nord-5 architecture, such indirection can be done over and over again, so that instead of just one value being loaded and interpreted as an address, the value found at this address may be interpreted as an address, and its value may be interpreted as an address. And so on, for a maximum of sixteen levels, all traversed upon executing a single instruction over a number of clock cycles!
I must admit that I am not particularly familiar with mainframe and minicomputer architectures, but certain characteristics do seem similar to other machines. For example, the PDP-10 or DECsystem-10, a 36-bit mainframe from Digital introduced in 1966, has sixteen general-purpose registers and only two instruction formats. It also has floating-point arithmetic support using pairs of registers. Later, Digital would discontinue this line of computers in favour of its increasingly popular and profitable VAX range of computers: a development that would parallel Norsk Data’s own technological strategy in some ways.
The Nord-5 and its successor, the largely similar Nord-50, were regarded as commercially unsuccessful, although one might argue that the former gave the company access to funding at a crucial point in its history. They also delivered respectable floating-point arithmetic performance, bringing about considerations of making them available for minicomputers from other manufacturers. Described in some reporting as “a cheaper smaller scale version of the CDC Cyber 76 or Cray-1“, even if we ignore the hype, one can consider how pursuing this floating-point accelerator business might have influenced the eventual fate of the company.
Role Models and Rivals
In potentially lucrative sales environments like CERN, where Norsk Data gained a lucrative foothold during the 1970s, the company would have seen a lot of business going the way of companies like Digital, IBM and Hewlett-Packard. Such companies would have been almost like role models, indicating areas in which Norsk Data might operate, and providing recipes for winning business and keeping it.
Indeed, when discussing Norsk Data, it is almost impossible to avoid introducing Digital Equipment Corporation into the discussion, not least because Norsk Data constantly made comparisons of itself with Digital, favourably compared its products to those of Digital, and quite clearly aspired to be like Digital to the point of seemingly trying to emulate the more established company. However, it might be said that this approach rather depended on what Digital’s own strategy was perceived to be, and whether the people at Norsk Data actually understood Digital’s business and products.
Much has been written about Digital’s own fall from grace, being a company with sought-after products that helped define an industry, only to approach the end of the 1980s in a state of near crisis, with its products being outperformed by the insurgent Unix system vendors and with its own customers wanting a more convincing Unix story from their supplier. In certain respects, Norsk Data’s fortunes followed a similar path, and we might then be left wondering if in trying to be like Digital, the company inadvertently copied its larger rival’s flaws and replicated its mistakes.
One apparent perception of Digital was that of a complete provider of technology, and it is certainly apparent that Digital was the kind of supplier who would gladly provide everything from hardware and the operating system, through compilers, tools and productivity applications, all the way to removal services for computing facilities. Certainly, computing investments at the minicomputing and mainframe level were considerable, and having a capable vendor was essential.
It was apparently often remarked that “nobody ever got fired for buying IBM”, but it could also be said that buying IBM meant that a whole category of worries could be placed on the supplier. Indeed, Digital was perceived as only offering potential solutions through their technology, as opposed to the kind of complete, working solutions that IBM would be selling. Nevertheless, opportunities were identified in various areas where the bulk of such solutions were ready to deploy. Digital sought to enter the office automation market with its ALL-IN-1 software, competing with IBM’s established products. Naturally, Norsk Data wanted a piece of this action, too.
The business model was not the only way that Norsk Data seemed obsessed with Digital. Company financial reports highlighted the superior growth figures in comparison to Digital and other computer companies. The introduction of the VAX in 1977 demanded a response, and the company set to work on a genuine 32-bit “superminicomputer” as a result. This effort dragged out, however, only eventually delivering the ND-500 series in 1981.
The ND-500 introduced a new architecture incompatible with that of the Nord-5 and Nord-50, trading the large, general-purpose register set with a smaller set of registers partitioned into specialised groups acting as accumulators, index registers, extension registers, base registers, stack and frame registers, and so on. Although resembling an extended form of Norsk Data’s 16-bit architecture, no effort had been made to introduce instruction set compatibility between the ND-500 and that existing architecture.
The instruction set itself aimed for the orthogonality for which the VAX had become famous, implemented using microcode and supported by a variable-length instruction encoding. Instructions, consisting of instruction code and operand specifier units, could be a single byte or “several thousand bytes” in length. A variety of addressing modes and data types were supported in the large array of instructions and their variants.
And yet each ND-500 “processor” in any given configuration was still coupled with a 16-bit ND-100 “front-end”, this being an updated Nord-10 used for input/output and running much of the operating system, thus perpetuating the architectural relationship between the 16- and 32-bit components previously seen in the NORDIC system from several years earlier. In effect, the ND-500 still favoured computational workloads, and without the front-end unit, it could not be considered a minicomputing system in its own right.
Going Vertical
One distinct difference between the apparent strategy of Norsk Data and that of Digital, perhaps based on misconceptions of Digital’s approach or maybe founded on simple opportunism, was the way that the Norsk Data sought to be a complete, “vertically integrated” supplier in various specialised markets, whereas Digital could more accurately be described as a platform company. In one commentary I discovered while browsing, I found these pertinent remarks:
“In the old “Vertical” business model a major supplier would develop everything in house from basic silicon chips right through to … financial applications software packages. This model was clearly absurd. A company may be good at developing or providing several of the technologies and services in the value chain but it is inconceivable that any single company could be the best at doing everything.”
They originate from a representative of ICL, describing that company’s adoption of open standards and Unix as “a strategic platform”. Companies like ICL had their origins in earlier times when computer companies were almost expected to do everything for a customer, in part due to a lack of interoperability between systems, in part due to a traditional coupling of hardware and software, and in part due to a lack of expertise in information systems in the broader economy, making it a requirement for those companies to apply their proprietary technologies to the customer’s situation and to tackle each case as it came along.
Gradually, software became seen as an independent technology and product in its own right, interoperability materialised, and opportunities emerged for autonomous “third parties” in the industry. The “horizontal” model, where customers could choose and combine the technologies that were most appropriate for them, was resisted by various established companies, but in a dynamic market, they were eventually made to confront their own limitations.
In historical reviews of Norsk Data and its business, such as Tor Olav Steine’s “Fenomenet Norsk Data” (“The Norsk Data Phenomenon”), there is surprisingly little use of the word “solution” in the sense of an information technology system taken into practical use, which is a word that is used a lot in certain areas of the computer business. In those areas, like consultancy, the nature of the business may revolve entirely around the provision and augmentation of existing products to provide something a customer can use: what we call a “solution”. Such businesses simply could not exist without software and hardware platforms to deliver such solutions.
Where “solution” is used in such a way in Steine’s account, it is in the context of a company like Norsk Data choosing not to sell “solutions into specific markets” like the banking sector, identifying this a critical weakness of the company’s strategy. Certainly, a company like Norsk Data had to be adaptable and to accommodate initiatives to supply such sectors, but the mindset exhibited is that the company had to back up the salesforce with a “massive effort” to solve all of the customer’s problems. This was precisely the kind of “vertical” supplier that ICL and IBM had been out of historical necessity, entrusted with such endeavours, but also burdened by society’s continuing expectations of such companies.
Indeed, it says a great deal that IBM was the principal competition in the sector used to illustrate this alleged weakness of Norsk Data. IBM’s own crisis arrived in the early 1990s with a then-record financial loss and waves of reorganisations, somewhat decoupling the product divisions of the company from its growing services and solutions divisions, also gradually causing the company to adopt open systems and technologies. Its British counterpart in such traditional sectors, ICL, dabbled in open systems and Unix, largely keeping them away from its mainframe business, but pivoted strongly at the start of the 1990s, perhaps influenced by Fujitsu – its partner, investor and, eventually, owner – to adopt the SPARC architecture and System V Unix.
Norsk Data, however, stuck with vertical integration to its initial benefit and then its later detriment. The company had done some good business on the back of acquisitions in certain sectors – typesetting systems, computer-aided design/manufacturing – where opportunities were identified to migrate existing products to Norsk Data’s hardware and to ostensibly boost the performance that may have been lacking in the existing offerings, but the company found itself struggling to repeat such successes. In markets like the UK, it encountered indifference from software companies, who apparently perceived the company to be “too small”, and tried to invest in and cultivate smaller companies as vehicles for its technology.
Here, there may have been a possible lack of awareness or acceptance that instead of being “too small”, Norsk Data was perhaps too niche or too non-standard, in an era of emerging standards. After all, such standards increasingly defined software and hardware platforms on which other companies would build. The fixation on vertical market opportunities, having something that competitors did not, and “striking a knockout” in competitive situations, seems rather incompatible with cultivating an ecosystem around one’s products.
Another trait is apparent from discussion of the company, that being the tendency of selling in one set of products to a customer so as to be able to try and sell the customer another set of products. Thus, a customer buying one of the vertical market products might be coaxed into adopting various other strategic Norsk Data products, like the celebrated NOTIS suite of productivity applications. And with the potential for niche products to create opportunities for further sales and the proliferation of the company’s core technologies, Norsk Data got itself into trouble.
Personal Computing the Hard Way
Despite the increasing prominence of personal computing in the late 1970s and early 1980s, Norsk Data had remained largely dismissive of the trend, as many traditional vendors had also been initially. Minicomputer vendors sold multi-user machines that ran applications for each of the users, communicating output, usually character-based, to simple display terminals whose users would respond with keystrokes that would be communicated back to the “host”, thus providing an interactive computing environment. With shared storage, applications could provide a degree of collaboration absent from the average, standalone microcomputer. What exactly could a standalone microcomputer do that a terminal attached to a minicomputer could not?
Alongside this, applications that would become familiar to microcomputer users had emerged in minicomputer environments. For instance, word processing systems had demonstrated productivity benefits to organisations, providing far more flexibility and efficiency over typewriters and secretarial pools (also known as typing pools, so no, nothing to do with splashing around). Minicomputer environments could provide shared resources for still-expensive devices like printers, particularly high-end ones, and the shared storage permitted a library of materials to be accessed and curated.
From such easy triumphs in computerisation, much was anticipated from the nebulous practice of office automation. But perhaps because of the fragmented needs and demands of organisations, all-conquering big office systems could not hold off the gradual erosion of minicomputing dominance by the intrusion of microcomputers. Introduced at a relatable, personal level, one might argue that a personal computer as a simple product or commodity, along with software that was similarly packaged, may have been more obviously adaptable to some kinds of organisations, particularly small ones without strong expectations of what computer systems should do and how they might behave.
Indeed, where traditional suppliers of computers were perceived by newcomers as unapproachable or intimidating, microcomputers offered a potentially gentler introduction, as amusingly noted in one Norwegian article featuring IBM, Digital, HP and Norsk Data. For example, correspondence, documentation and other written records may have been cumbersome to prepare even with electronic typewriters – these providing only crude editing functions – and depending on the levels of enthusiasm for alternatives and frustration with the current situation, it would have been natural to acquire a personal computer with accessories, and to try out word processing and other applications to see what worked best for any given person, office, department, or organisation.
(A mixture of personal computing systems might have eventually generated interoperability problems, amongst others, but the agility that personal computers afforded organisations would potentially inform larger and more ambitious attempts to introduce technology later on.)
Personal computers began to shape user expectations of what computers of all kinds could do. Indeed, it is revealing that in treatments of the office automation market from the early 1980s, microcomputers keep recurring, and personal workstations – particularly the Xerox Star – set the tone for whatever office automation was meant to be. This was undoubtedly due to the unavoidable focus on the user interface that microcomputing and personal computing demanded. After all, personal computing cannot really be personal without considering the user!
Crucially, however, Xerox appeared to understand that one product could not be right for everyone, thus pitching a range of systems for a variety of users. The Xerox 860 focused largely on traditional word processing applications. The Xerox 8010 (or Star) was a networked workstation for sophisticated users. The company realised, particularly with IBM poised to move into personal computing, that a need existed for a more affordable product, leading to the much cheaper Xerox 820 running the established CP/M operating system. Although the Xerox 820 appears to have been considered a disappointment by commentators, who were perhaps expecting something more revolutionary, it did appear to signal that Xerox took affordable personal computing seriously, and the company was not alone in formulating such a product.
Digital tried a few different approaches to personal computing, two of which involved applications of their minicomputer architectures: the PDP-8-based DECmate, and the PDP-11-based DEC Professional. But it was their third and perhaps least proprietary approach, the DEC Rainbow, that perhaps stood the best chance of success, following a similar path to the Xerox 820, but taking the Zilog Z80-based core of such a machine and extending it with a companion Intel 8088 processor for increased versatility.
Such hybrid systems were not uncommon for a brief period at the start of the 1980s: established CP/M users would need Z80 compatibility, whereas new users and new software would have benefited from the 8088 running CP/M-86 or MS-DOS. The Rainbow was not a success, hampered by Digital’s proprietary instincts. Personally, I found it surprising to learn that the machine had a monochrome display as standard. Even with the RGB colour option, it would have rendered its own logo relatively unsatisfactorily!
What was Norsk Data’s response to the personal computing bandwagon? A telling quote can be found in an article from a 1985 newsletter:
“We do not believe in “the universal workstation” that can solve all problems for all user categories. Alternative hardware and software combinations seem to be the right answer. The functionality requirements for the personal workstations are definitely not satisfied by the “traditional PC”. For the majority of users today, the NOTIS terminal is the best alternative for a personal workstation that is integrated with the rest of the organization.”
The first two sentences seem reasonable enough, and the third could certainly have seemed reasonable at the time. But then comes the absurd, self-serving conclusion: a proprietary character terminal is the “best alternative” to something like the Xerox Star or its successor, the Xerox 6085 “Daybreak”, introduced in 1985, or other actual workstation products arriving on the market.
Evidently, decision-makers at the company remained fixated on what they considered their blockbuster products. But the personal computing trend was not about to disappear. The company’s first attempt at a product was initiated in 1983 and released in 1984, involving a rebadged IBM-PC-compatible from Columbia Computers, sold “half-heartedly” and was perhaps more influential within the company than outside.
Then, in 1986, came the product that only Norsk Data could make: the Butterfly workstation, featuring an Intel 80286 processor and running MS-DOS and contemporary Windows, but also featuring two expansion cards that implemented the ND-110 minicomputer processor to run the proprietary SINTRAN operating system. Naturally, such a workstation, with its built-in minicomputer, was intended to run the cherished NOTIS software, and a variant known as the Teamstation permitted the connection of four terminals to share in such goodness.
One can almost understand the thinking behind such products. There was an increasing clamour for approachable computing, with relatively low starting costs, and with buyers starting out with a single machine and seeing whether they liked the experience. Providing something whose experience for a single user could be expanded to cover another four users might have seemed like a reasonable idea. But to make sense to customers, those extra terminals would need to be inexpensive and offer something that another four personal computers might not, and the software involved would have to be better than the kinds of programs that ran natively on personal computers at the time. Here, the beliefs of those at Norsk Data and those of potential customers could easily have been rather different.

“Norsk Data didn’t buy Wordplex for nothing.” Norsk Data perhaps inadvertently played into 1980s stereotypes when boasting about having loads of money. Wordplex was a struggling word processing systems vendor, and the acquisition did not lead to the happy marriage of convenience – or otherwise – that was promised.
Turning Something into Nothing
Against the industry tide, it seems that the company did what came most naturally, seeking growth for its own applications amongst a captive customer audience. Thus, amidst a refinancing exercise at word processing supplier Wordplex, that turned into a takeover opportunity for Apricot Computers, Norsk Data barged in with a more valuable offer, leaving Apricot to withdraw from the contest, presumably with some relief. Wordplex, one of the success stories in an earlier phase of office automation, was struggling financially but had an enviable customer base in a market where Norsk Data had wanted a greater presence than it had previously managed to attain.
What the exact plan was for Wordplex is not entirely clear. The company had its own product roadmap, centred on its Zilog Z8000-based Series 8000 systems, initially running Wordplex’s proprietary operating system. Wordplex evidently acknowledged the emergence of Unix and sought to introduce Xenix for its systems, chosen perhaps for its continued support for the aging Z8000 architecture. Norsk Data’s contribution seems to have been to sell their own machines to “stand beside or stack vertically” on the Series 8000 machines, offering what looked suspiciously like the NOTIS suite. One could easily imagine that Wordplex’s product range was unlikely to receive much further development after that.
Commentators associated with Norsk Data seem to regard Wordplex as something of a misadventure. Steine goes as far as to accuse the Wordplex management of subverting the organisation and pursuing their own agenda, as opposed to getting on with their new duties of selling Norsk Data’s systems to those valuable customers. Yet he does seem to accept that by pushing new systems onto Wordplex’s customers, computing departments pushed back on the additional complexity these new, proprietary systems would introduce, although Steine seems to attribute such pushback more on an unwillingness to tolerate new vendors in their computer rooms.
Perhaps Wordplex’s management stuck to what they knew because they just weren’t given better tools for the job. Existing customers would want to see some continuity, even if their users would eventually see themselves migrated onto other technology. In the end, Norsk Data’s perceived opportunities never materialised, and Wordplex customers presumably saw the writing on the wall and migrated to other systems. The dedicated word processing business was being disrupted by low-cost personal computers either dressed up like word processors, in the case of the Amstrad PCW, or providing more general functionality, maybe even in a networked configuration.
It is telling that in the documentary covering the takeover, a remark is made about how Norsk Data seemed inexperienced at acquisitions and the task of integrating distinct corporate cultures, and yet the company had, in fact, acquired other companies to fuel its rapid growth. But still, it is apparent that entities like Comtec and Technovision remained distinct silos within the larger organisation. I have personal familiarity with one institutional customer of Comtec, although it may have been a faint memory by the time I interacted with its users.
That customer was CERN’s publishing section, responsible for the weekly Bulletin and other output, who had adopted the NORTEXT typesetting system with some success. In 1985, these users were gradually trying to adopt various NOTIS applications, expressing a form of cautious optimism. By 1986, with an audit of CERN’s information systems in progress, these users were facing an upgrade of NORTEXT that required terminals designed for NOTIS, as well as enhancements for NOTIS that stressed their older, 16-bit ND-100 series hardware, having been developed primarily for the newer, 32-bit, ND-500 systems.
More investment was requested to take advantage of newer hardware, increased storage, and to provide more terminals. Indeed, the introduction of ND-500 models would help to rationalise the hardware situation, reduce maintenance costs and demands, and provide better services to those users. But at the same time, amidst a “lively discussion”, the shortcomings of NOTIS were noted, that Norsk Data were “unlikely to satisfy the needs of the administration in terms of fully automated office functions such as agenda, calendars, conference scheduling”, and that better integration was needed with the growing Macintosh community inside CERN.
Indeed, the influence of the graphical user interface, and the success of the Macintosh in delivering a coherent platform for developers and users, put companies wedded to character-based terminal applications on the back foot. Graphical applications were the natural medium of such platforms, whereas companies like Norsk Data struggled to accommodate such applications within their paradigm, suggesting upgrades to more costly graphical terminals. At best, the result added around $1,000 to the cost of the terminal and merely offered an “experimental” and narrow attempt at being “Macintosh like”, in a world where potential users were more likely to opt for the real thing instead.
Despite the mythology around the Mac, the platform was, like many others, still finding its feet and lacking numerous desirable capabilities. The mid-1980s was a fluid era for the graphical personal computer, and although a similar mythology developed around the Amiga, which was more capable than the Mac in several respects, success for a platform demanded a combination of technology, applications, the convenience of making such applications, and a demand for them.
On the dominant IBM-compatible platform, it took a while for a dominant graphical layer to assert itself, leaving observers attempting to track the winner from candidates such as VisiOn, GEM, Windows, OS/2 and NewWave. It is perhaps unsurprising that Norsk Data had no ready answer, and that even as it introduced its own personal computers running DOS and early Windows software, it was merely waiting for an industry consensus to shake out. Other strategies could have been followed, however: vendors in Norsk Data’s situation chose to enter the workstation market, which is a topic to be considered in its own right.
Another company that struggled with personal computing was ICL. Having acquired some interesting products, such as those made by Singer Business Machines – a division of the Singer Corporation, perhaps most famous for its sewing machines – the same division, then operating as part as ICL, made a system that formed the basis of ICL’s Distributed Resource System product family. In the initial DRS 20 range, computers with 8085 processors running CP/M would run applications and access other machines acting as file servers over ICL’s proprietary Macrolan network.
Such solutions were not always well received by the personal computing media. Expectations that ICL would bring its market position to bear on the rapidly developing industry led to disappointment when the company introduced the first DRS models, drawing suggestions that the diskless “workstations” would make rather competitive personal computers, if only ICL were to remove the “nearly £1000” network card and replace it with a disk controller. Later models would upgrade the processor to the 8086 family and run Concurrent DOS. Low-end models did indeed get disk drives, but did not break out into the standalone personal computer market.
Instead, ICL also decided to sell a different set of products, licensed from a company called Rair, as its own Personal Computer series, and these even utilised similar technologies to its initial DRS line-up, such as the 8085, CP/M, and MP/M, but offered eight serial ports for connected terminals instead of network connectivity. Rair’s rise to prominence perhaps occurred through the introduction of the Rair Black Box, to which a terminal had to be attached in order to use the system. A repackaged version formed the basis of the first ICL PC.
ICL appear to have been rather more agile than Norsk Data at introducing upgrades to their PC and DRS families. The PC range evolved to include models like the exotic-sounding Quattro, still trying to cater to office environments wanting to serve applications to terminals in a relatively inexpensive way that was, nevertheless, seen as less than persuasive in an era where personal computing had now established itself. Eventually, ICL reconciled itself to producing IBM-compatible PCs. In the early 1990s, I encountered some of these in a brief school-era “work shadowing” stay at a municipal computing department which predictably operated an ICL mainframe and some serious Xerox printing hardware.
Meanwhile, the DRS range gained a colour graphical workstation running the GEM desktop software on Concurrent DOS. GEM was a viable product adopted by a variety of companies including Atari, Amstrad and Acorn, despite Apple attempting to assert ownership of various aspects of the desktop paradigm. It would have been interesting to see Apple try and shake ICL down over such claims, given all the prior art in ICL’s PERQ that helped sink Apple’s litigation against Microsoft and Hewlett-Packard later in the decade. But it is how part of the DRS range evolved that perhaps illustrates how the likes of Norsk Data might have acted more decisively.
Adding Multicore Support for a MIPS Board to the Fiasco Microkernel
December 1st, 2025
I thought that before I forget, I should try and write down some of the different things I have tackled recently with regard to L4Re and the different frameworks and libraries I have been developing. There have been many pauses in this work this year, and it just hasn’t been a priority to record various achievements, particularly since the effort is generally ongoing.
Multicore MIPS
As established members of my readership may recall, my entry point into L4Re was initially focused on establishing support for MIPS-based single-board computers and devices. Despite developing support for many of the peripherals in the Ingenic JZ4780 used by the MIPS Creator CI20, one thing I never did was to enable dual-core processing in L4Re and the Fiasco microkernel in particular. I may have thought that such support was already present, but, well, that was an unreasonable belief.
This year, I was indulged with a board based on a later SoC that also has two processing cores. It supposedly has two threads per core as well, but I don’t actually believe it based on the way the unit in the chip responsible for core management behaves. In the almost illicit documentation I have, there is also no real mention of scheduling threads in hardware, so then I am left to guess whether these threads behave like cores. And whatever hardware interface is provided does not seem to be the MIPS MT implementation, either, since it is reported as not being present.
These days, one has to rely on archived copies of MIPS documentation after MIPS Technologies threw all of that overboard to bet the farm on RISC-V, which is admittedly a reasonable bet. Former owner, Imagination Technologies, disowned the architecture and purged any documentation they might have had from their Web site, although I think that any links to toolchains might still work, but that is perhaps prudent on the basis of upholding any Free Software licence obligations that remain.
(Weirdly, MIPS Technologies recently got themselves acquired by GlobalFoundries, meaning that they are now owned by the part of AMD that was sold off when AMD decided it was too costly to fabricate their own chips, becoming “fabless” instead, just as MIPS had always been.)
I also wonder what the benefit of simultaneous multithreading (SMT) is on MIPS over plain old symmetic multiprocessing (SMP) using multiple cores. Conceptually, SMT is meant to use fewer resources than SMP by sharing common resources between execution units, eliminating much of the costly functionality needed by dedicated cores. But MIPS is different from other architectures in that it does not, for example, maintain page tables in hardware for processes/tasks, which are the sort of costly things that one might want to see eliminated.
Instead, MIPS employs a translation lookaside buffer (TLB) to handle virtual memory mappings, and each “virtual processing element” (VPE) is apparently provided with an independent TLB in the MIPS MT implementation. It seems we can think about a VPE more or less as a conventional processor or core given the general description of it. However, each “thread context” (TC) with a VPE may share a TLB with other TCs, although they will have their own address space identifier (ASID), meaning that their own memory mappings may differ from that of other threads in the same process or task. Given that the ASID would typically be used to define independent address spaces at a process or task level, this seems like an odd decision. One can be forgiven for being confused!
In any case, I needed to familiarise myself with the documentation and with work previously done in the Linux kernel. That kernel work, it turned out, was a work of bravery seemingly based on the incomplete knowledge that we still rely on today. Unfortunately, it seems that certain details are incorrect, these pertaining to the interrupt request management and the arrangement of the appropriate hardware registers. The Linux support appeared to use a bank of registers that, instead of applying to interrupts directed at the second core in particular, seems to be some kind of global control for interrupts on both cores. Sadly, the contributor of this code is no longer communicative, and I just hope that he is well and finding satisfaction in whatever he does now.
Into Fiasco
The very first thing I had to do in Fiasco, however, was to get it working on this SoC. This was rather frustrating, and in the end, the problem was in some cache initialisation code. Because of course it was. Then, my efforts within Fiasco to support multiple cores were informed by existing support in the microkernel for initialising additional processors. Reacquainting myself with the kernel bootstrap process, I found that the architecture-specific entry point is the bootstrap_arch method, provided by the kernel thread implementation. This invokes the boot_all_secondary_cpus method, provided by the platform control abstraction.
Although there is support for the MIPS Concurrency Manager (CM) present in Fiasco, it is not useful for this particular SoC, so a certain amount of dedicated support code was going to be required. Indeed, the existing mechanisms were defined to use the MIPS CM to initialise these “secondary CPUs” in the generic platform control implementation. Fortunately, the C++ framework employed by Fiasco permits the overriding of operations, and I was able to fairly cleanly provide my own board/product-specific implementation that would use the appropriate functionality to be written by myself.
That additional functionality was support for the SoC’s own Core Control Unit (CCU), which is something that appears to be thankfully much simpler than the MIPS CM. The CCU provides facilities to start cores, to monitor and control interrupts, and to support inter-core communication using mailboxes. Of particular interest was the ability to start cores, to permit the cores to communicate via the mailboxes, and for such communication to generate mailbox interrupts. For the most part, the abstraction supporting the CCU is fairly simple, however.
Interrupt Handling
Perhaps the most challenging part of the exercise was that of describing the interrupt handling configuration. Although I was familiar with the code that connects the processor-level interrupts to the different peripheral interrupt handlers, it was not clear to me how these handlers would be allocated for, and assigned to, each processor or core. Indeed, it was not even clear how the interrupts behaved in the hardware.
I suppose I could have a long rant about the hardware documentation. Having already needed to dig up an address for the CCU, I noticed that the addresses for the interrupt controller in the manual for the chip were simply fictitious and very possibly originating in a copy-paste operation, given that the register banks conflicted with the clock and power management unit. More digging eventually revealed the actual location of these banks. One helpful aspect of the manual, however, was the information implicitly given about the spacing of these register banks, even though I think the number of banks is also a fiction, bound up with the issue of how many cores and/or threads the chip actually has.
The way that the chip appears to work is that each core can enable and mask (ignore) individual interrupts. It does so using its own coprocessor registers at the MIPS architecture level, but to identify and control the individual interrupt sources, it uses registers provided in the appropriate bank by the interrupt controller. In a single-core processor, there is only one set of registers, and the single core can switch them on and off for its own benefit. But with multiple cores, each core can apparently choose to receive or ignore interrupts, leaving the others to decide for themselves. And if we ignore the top-level control, we might even allow one core to set the preferences for itself and other cores, since it can access all of the register banks for the different cores in the interrupt controller.
Now, the fundamental interrupt handling for this family of chips has been consistent throughout my exposure to L4Re and Fiasco, with a specialisation of Irq_chip_gen providing access to the interrupt controller registers. Since this abstraction for the interrupt controller unit works and is still applicable, instead of trying to make it juggle multiple register banks, I decided to wrap it in another abstraction that would allow interrupts to be associated with a specific core or with all cores, replicating the same fundamental interface, and that would redirect operations to the individual core-specific units according to the association made for a given interrupt.
IPIs
In my exploration of the interrupt handling code, I repeatedly encountered the acronym IPI, which turns out to mean inter-processor interrupt, where one core may raise an interrupt in another core. Although it was apparent that the CCU’s mailbox facilities would be the vehicle to support such interrupts, it was not immediately obvious how these interrupts might be used within Fiasco. In fact, it was while trying to operate the kernel debugger, JDB, that I discovered one of their applications: the debugger needs to halt secondary cores or processors to be able to safely inspect the system.
Thus, I attempted to provide an IPI implementation by following the general pattern of implementations for other platforms, such as the RISC-V support within Fiasco, relying on that architecture’s closer heritage than, say, ARM or x86(-64), and generally hoping that the supporting code would provide more helpful clues. Sadly, there is not much formal guidance on such matters in the form of documentation or other explanatory materials for Fiasco, at least as far as I have discovered.
One aspect of my implementation that I suspect could be improved involves the representation of the different IPI conditions, along with usage of the atomic_reset operation in the generic MIPS IPI support. This employs an array to hold the different interrupt conditions occurring for a core, rather like a big status register occupying numerous words instead of bits, with atomic_reset obtaining the appropriate interrupt status and clearing any signalled condition.
Given that the CCU is able to maintain core-specific state in the mailbox registers, one might envisage a core setting bits in such registers to signal IPI conditions, with the interrupted core clearing these individually, doing so safely by using the locking mechanism provided by the CCU. However, since my augmentation of the existing IPI status management seemed to result in a functioning system, merely augmenting the existing code with the interrupt delivery and signalling mechanisms of the CCU, I did not feel particularly motivated to continue.
Bad Bits
It should be mentioned that throughout all of this effort, I encountered rather severe problems with the UART on the development board concerned. These would manifest themselves as garbled output from the board along with a lack of responsiveness or faulty interpretation of input. Characters in the usual ASCII range would be punctuated and eventually overrrun by “special” characters, some non-printable, and efforts to continue the session would typically need to be abandoned. This obviously did not help troubleshooting of either my boot payloads or the kernel debugger.
Some analysis of the problem was required, and in an attempt to understand why certain wholly normal characters would be transformed to abnormal ones, I wrote out some character values in their transmitted forms, also incorporating extra elements of the transmission:
0x0d is 00001101 - repeated: 0000110100001101 - stop bit exposed: 000011011000011011000011011000011011 0xc3 is 11000011 -------- -------- --------
In trying to reproduce the observed character values, I looked for ways in which the bitstream would be misinterpreted and yield these erroneous characters. This exercise would repeatedly succeed, suggesting some kind of slippage in the acquisition of characters. It turned out that this was an anticipated problem, and the omission of appropriate level shifters for the UART pins meant that the signalling was effectively unreliable. A fix was introduced on subsequent board revisions, and in fact, the board was more generally refined and completed, since I had been using what was effectively a prototype.
General Remarks
A degree of familiarisation was required with the mechanisms in Fiasco for some common activities. Certain constructs exist such as per-CPU allocators that need to be used where resources are to be allocated for, and assigned to, individual CPUs. These allocator constructs provide a convenience operation allowing the “current” CPU, being the one running the code, to obtain its own resource. Although the details now elude me, there were some frustrations in deploying these constructs under certain circumstances, but I seemed to figure something out that got me to where I wanted to be in the end.
I also wanted to avoid changing existing Fiasco code, instead augmenting it with the necessary specialisations for this hardware. Apart from the existing cache initialisation routines, this was largely successful. In principle, I now have some largely clean patches that I could potentially submit upstream, especially since they have now stopped insisting on contributor licence agreements. I do wonder if they are still interested in this family of SoCs, however.
I might also stick my neck out at this point and note that if anyone is interested in development boards with MIPS-based processors and a degree of compatibility with Raspberry Pi HATs, they might get in contact with me, so that their interest can be recorded and the likelihood increased of such boards being produced for purchase.
Common Threads of Computer Company History
August 5th, 2025
When descending into the vaults of computing history, as I have found myself doing in recent years, and with the volume of historical material now available for online perusal, it has largely become possible to finally have the chance of re-evaluating some of the mythology cultivated by certain technological communities, some of it dating from around the time when such history was still being played out. History, it is said, is written by the winners, and this is true to a large extent. How often have we seen Apple being given the credit for many technological developments that were actually pioneered elsewhere?
But the losers, if they may be considered that, also have their own narratives about the failure of their own favourites. In “A Tall Tale of Denied Glory”, I explored some myths about Commodore’s Amiga Unix workstation and how it was claimed that this supposedly revolutionary product was destined for success, cheered on by the big names in workstation computing, only to be defeated by Commodore’s own management. The story turned out to be far more complicated than that, but it illustrates that in an earlier age where there was more limited awareness of an industry with broader horizons than many could contemplate, everyone could get round a simplistic tale and vent their frustration at the outcome.
Although different technological communities, typically aligned with certain manufacturers, did interact with each other in earlier eras, even if the interactions mostly focused on advocacy and argument about who had chosen the best system, there was always the chance of learning something from each other. However, few people probably had the opportunity to immerse themselves in the culture and folklore of many such communities at once. Today, we have the luxury of going back and learning about what we might have missed, reading people’s views, and even watching television programmes and videos made about the systems and platforms we just didn’t care for at the time.
It was actually while searching for something else, as most great discoveries seem to happen, that I encountered some more mentions of the Amiga Unix rumours, these being relatively unremarkable in their familiarity, although some of them were qualified by a claim by the person airing these rumours (for the nth time) that they had, in fact, worked for Sun. Of course, they could have been the mailboy for all I know, and my threshold for authority in potential source material for this matter is now set so high that it would probably have to be Scott McNealy for me to go along with these fanciful claims. However, a respondent claimed that a notorious video documenting the final days of Commodore covered the matter.
I will not link to this video for a number of reasons, the most trivial of which is that it just drags on for far too long. And, of course, one thing it does not substantially cover is the matter under discussion. A single screen of text just parrots the claims seen elsewhere about Sun planning to “OEM” the Amiga 3000UX without providing any additional context or verification. Maybe the most interesting thing for me was to see that Commodore were using Apollo workstations running the Mentor Graphics CAD suite, but then so were many other companies at one point in time or other.
In the video, we are confronted with the demise of a company, the accompanying desolation, cameraderie under adversity, and plenty of negative, angry, aggressive emotion coupled with regressive attitudes that cannot simply be explained away or excused, try as some commentators might. I found myself exploring yet another rabbit hole with a few amusing anecdotes and a glimpse into an era for which many people now have considerable nostalgia, but one that yielded few new insights.
Now, many of us may have been in similar workplace situations ourselves: hopeless, perhaps even deluded, management; a failing company shedding its workforce; the closure of the business altogether. Often, those involved may have sustained a belief in the merits of the enterprise and in its products and people, usually out of the necessity to keep going, whether or not the management might have bungled the company’s strategy and led it down a potentially irreversible path towards failure.
Such beliefs in the company may have been forged in earlier, more successful times, as a company grows and its products are favoured over those of the competition. A belief that one is offering something better than the competition can be highly motivating. Uncalibrated against the changing situation, however, it can lead to complacency and the experience of helplessly watching as the competition recover and recapture the market. Trapped in the moment, the sequence of events leading to such eventualities can be hard to unravel, and objectivity is usually left as a matter for future observers.
Thus, the belief often emerges that particular companies faced unique challenges, particularly by the adherents of those companies, simply because everything was so overwhelming and inexplicable when it all happened, like a perfect storm making an unexpected landfall. But, being aware of what various companies experienced, and in peeking over the fence or around the curtain at what yet another company may have experienced, it turns out that the stories of many of these companies all have some familiar, common themes. This should hardly surprise us: all of these companies will have operated largely within the same markets and faced common challenges in doing so.
A Tale of Two Companies
The successful microcomputer vendors of the 1980s, which were mostly those that actually survived the decade, all had to transition from one product generation to the next. Acorn, Apple and Commodore all managed to do so, moving up from 8-bit systems to more sophisticated systems using 32-bit architectures. But these transitions only got them so far, both in terms of hardware capabilities and the general sophistication of their systems, and by the early 1990s, another update to their technological platforms was due.
Acorn had created the ARM processor architecture, and this had mostly kept the company competitive in terms of hardware performance in its traditional markets. But it had chosen a compromised software platform, RISC OS, on which to base its Archimedes systems. It had also introduced a couple of Unix workstation products, themselves based on the Archimedes hardware, but these were trailing the pace in a much more competitive market. Acorn needed the newly independent ARM company to make faster, more capable chips, or it would need embrace other processor architectures. Without such a boost forthcoming, it dropped Unix and sought to expand in “longshot” markets like set-top boxes for video-on-demand and network computing.
Commodore had a somewhat easier time of it, at least as far as processors were concerned, riding on the back of what Motorola had to offer, which had been good enough during much of the 1980s. Like Acorn, Commodore made their own graphics chips and had enjoyed a degree of technical superiority over mainstream products as a result, but as Acorn had experienced, the industry had started to catch up, leading to a scramble to either deliver something better or to go with the mainstream. Unlike Acorn, Commodore did do a certain amount of business actually going with the mainstream and selling IBM-compatible PCs, although the increasing commoditisation of that business led the company to disengage and to focus on its own technologies.
Commodore had its own distractions, too. While Acorn pursued set-top boxes for high-bandwidth video-on-demand and interactive applications on metropolitan area networks, Commodore tried to leverage its own portfolio rather more directly, trading on its strengths in gaming and multimedia, hoping to be the one who might unite these things coherently and lucratively. In the late 1980s and early 1990s, Japanese games console manufacturers had embraced the Compact Disc format, but NEC’s PC Engine CD-ROM² and Sega’s Mega-CD largely bolted CD technology onto existing consoles. Philips and Sony, particularly the former, had avoided direct competition with games consoles, pitching their CD-i technology more at the rather more sedate “edutainment” market.
With CDTV, Commodore attempted to enter the same market at Philips, downplaying the device’s Amiga 500 foundations and fast-tracking the product to market, only belatedly offering the missing CD-ROM drive option for its best-selling Amiga 500 system that would allow existing customers to largely recreate the same configuration themselves. Both CD-i and CDTV were considered failures, but Commodore wouldn’t let go, eventually following up with one of the company’s final products, the CD32, aiming more directly at the console market. Although a relative success against the lacklustre competition, it came too late to save the company which had entered a steep decline only to be driven to bankruptcy by a patent aggressor.
Whether plucky little Commodore would have made a comeback without financial headwinds and patent industry predators is another matter. Early multimedia consoles had unconvincing video playback capabilities without full-motion video hardware add-ons, but systems like the 3DO Interactive Multiplayer sought to strengthen the core graphical and gaming capabilities of such products, introducing hardware-accelerated 3D graphics and high-quality audio. Within only a year or so of the CD32’s launch, more complete systems such as the Sega Saturn and, crucially, the Sony PlayStation would be available. Commodore’s game may well have been over, anyway.
Back in Cambridge, a few months after Commodore’s demise, Acorn entered into a collaboration with an array of other local technology, infrastructure and media companies to deliver network services offering “interactive television“, video-on-demand, and many of the amenities (shopping, education, collaboration) we take for granted on the Internet today, including access to the Web of that era. Although Acorn’s core technologies were amenable to such applications, they did need strengthening in some respects: like multimedia consoles, video decoding hardware was a prerequisite for Acorn’s set-top boxes, and although Acorn had developed its own competent software-based video decoding technology, the market was coalescing around the MPEG standard. Fortunately for Acorn, MPEG decoder hardware was gradually becoming a commodity.
Despite this interactive services trial being somewhat informative about the application of the technologies involved, the video-on-demand boom fizzled out, perhaps demonstrating to Acorn once again that deploying fancy technologies in a relatively affluent region of the country for motivated, well-served early adopters generally does not translate into broader market adoption. Particularly if that adoption depended on entrenched utility providers having to break open their corporate wallets and spend millions, if not billions, on infrastructure investments that would not repay themselves for years or even decades. The experience forced Acorn to refocus its efforts on the emerging network computer trend, leading the company down another path leading mostly nowhere.
Such distractions arguably served both companies poorly, causing them to neglect their core product lines and to either ignore or to downplay the increasing uncompetitiveness of those products. Commodore’s efforts to go upmarket and enter the potentially lucrative Unix market had begun too late and proceeded too slowly, starting with efforts around Motorola 68020-based systems that could have opened a small window of opportunity at the low end of the market if done rather earlier. Unix on the 68000 family was a tried and tested affair, delivered by numerous companies, and supplied by established Unix porting houses. All Commodore needed to do was to bring its legendary differentiation to the table.
Indeed, Acorn’s one-time stablemate, Torch Computers, pioneered low-end graphical Unix computing around the earlier 68010 processor with its Triple X workstation, seeking to upgrade to the 68020 with its Quad X workstation, but it had been hampered by a general lack of financing and an owner increasingly unwilling to continue such financing. Coincidentally, at more or less the same time that the assets of Torch were finally being dispersed, their 68030-based workstation having been under development, Commodore demonstrated the 68030-based Amiga 3000 for its impending release. By the time its Unix variant arrived, Commodore was needing to bring far more to the table than what it could reasonably offer.
Acorn themselves also struggled in their own moves upmarket. While the ARM had arrived with a reputation of superior performance against machines costing far more, the march of progress had eroded that lead. The designers of the ARM had made a virtue of a processor being able to make efficient use of its memory bandwidth, as opposed to letting the memory sit around idle as the processor digested each instruction. This facilitated cheaper systems where, in line with the design of Acorn’s 8-bit computers, the processor would take on numerous roles within the system including that of performing data transfers on behalf of hardware peripherals, doing so quite effectively and obviating the need for costly interfacing circuitry that would let hardware peripherals directly access the memory themselves.
But for more powerful systems, the architectural constraints can be rather different. A processor that is supposedly inefficient in its dealings with memory may at least benefit from peripherals directly accessing memory independently, raising the general utilisation of the memory in the system. And even a processor that is highly effective at keeping itself busy and highly efficient at utilising the memory might be better off untroubled by interrupts from hardware devices needing it to do work for them. There is also the matter of how closely coupled the processor and memory should be. When 8-bit processors ran at around the same speed as their memory devices, it made sense to maximise the use of that memory, but as processors increased in speed and memory struggled to keep pace, it made sense to decouple the two.
Other RISC processors such as those from MIPS arrived on the market making deliberate use of faster memory caches to satisfy those processors’ efficient memory utilisation while acknowledging the increasing disparity between processor and memory speeds. When upgrading the ARM, Acorn had to introduce a cache in its ARM3 to try and keep pace, doing so with acclaim amongst its customers as they saw a huge jump in performance. But such a jump was long overdue, coming after Acorn’s first Unix workstation had shipped and been largely overlooked by the wider industry.
Acorn’s second generation of workstations, being two configurations of the same basic model, utilised the ARM3 but lacked a hardware floating-point unit. Commodore could rely on the good old 68881 from Motorola, but Acorn’s FPA10 (floating-point accelerator) arrived so late that only days after its announcement, three years or so after those ARM3-based systems had been launched and two years later than expected, Acorn discontinued its Unix workstation effort altogether.
It is claimed that Commodore might have skipped the 68030 and gone straight for the 68040 in its Unix workstation, but indications are that the 68040 was probably scarce and expensive at first, and soon only Apple would be left as a major volume customer for the product. All of the other big Motorola 68000 family customers had migrated to other architectures or were still planning to, and this was what Commodore themselves resolved to do, formulating an ambitious new chipset called Hombre based around Hewlett-Packard’s PA-RISC architecture that was never realised.
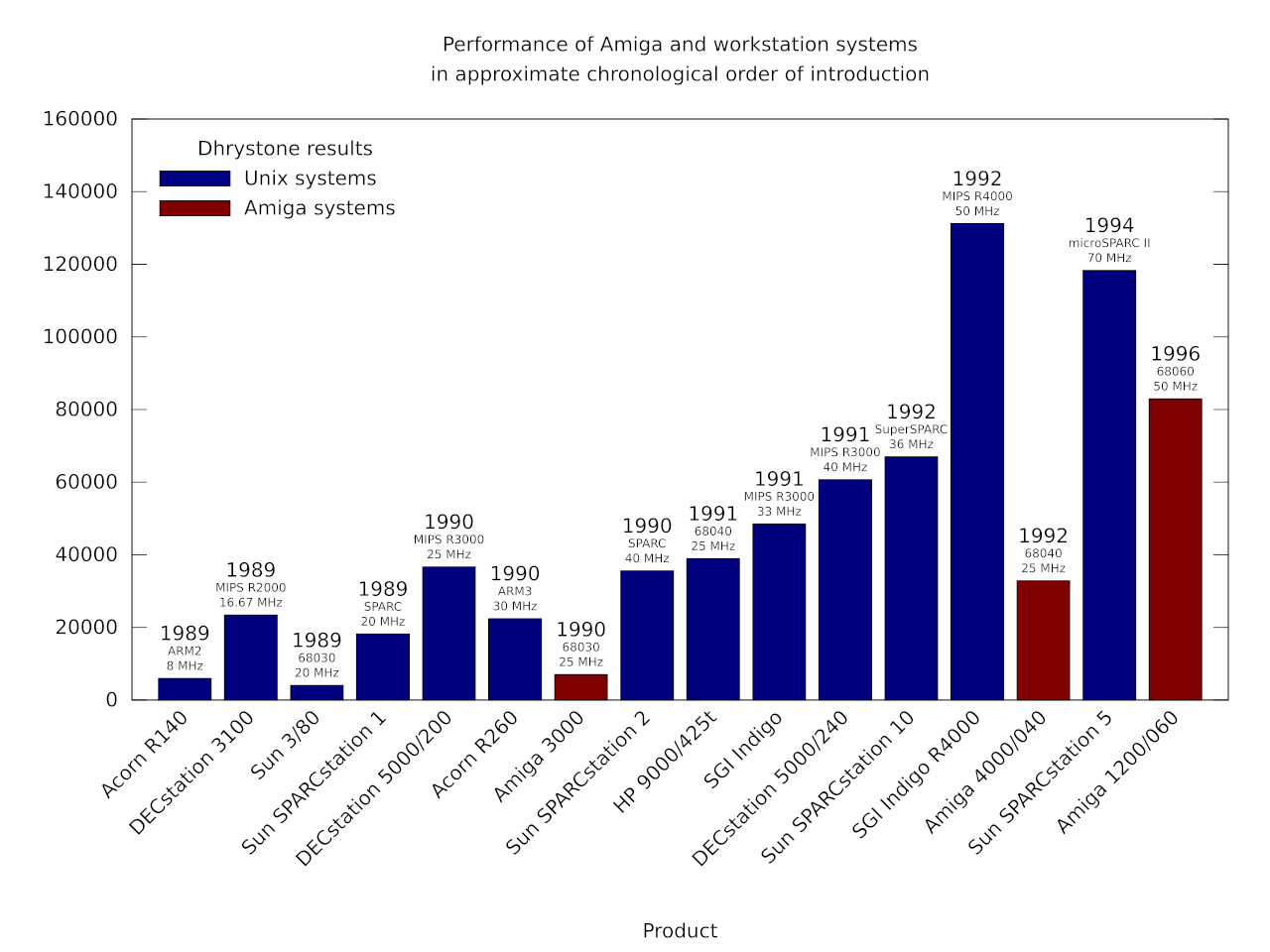
A chart showing how Unix workstation performance steadily improved, largely through the introduction of steadily faster RISC processors.
Acorn, meanwhile, finally got a chip upgrade from ARM in the form of the rather modest ARM6 series, choosing to develop new systems around the ARM600 and ARM610 variants, along with systems using upgraded sound and video hardware. One additional benefit of the newer ARM chips was an integrated memory management unit more suitable for Unix implementations than the one originally developed for the ARM. For followers of the company, such incoming enhancements provided a measure of hope that the company’s products would remain broadly competitive in hardware terms with mainstream personal computers.
Perhaps most important to most Acorn users at the time, given the modest gains they might see from the ARM600/610, was the prospect of better graphical capabilities, but Acorn chose not to release their intermediate designs along the way to their grand new system. And so, along came the Risc PC: a machine with two processor sockets and logic to allow one of the processors to be an x86-compatible processor that could run PC software. Once again, Acorn gave the whole hardware-based PC accelerator card concept another largely futile outing, failing to learn that while existing users may enjoy dabbling with software from another platform, it hardly ever attracts new customers in any serious numbers. Even Commodore had probably learned that lesson by then.
Nevertheless, Acorn’s Risc PC was a somewhat credible platform for Unix, if only Acorn hadn’t cancelled their own efforts in that realm. Prominent commentators and enthusiastic developers seized the moment, and with Free Software Unix implementations such as NetBSD and FreeBSD emerging from the shadow of litigation cast upon them, a community effort could be credibly pursued. Linux was also ported to ARM, but such work was actually begun on Acorn’s older A5000 model.
Acorn never seized this opportunity properly, however. Despite entering the network computer market in pursuit of some of Larry Ellison’s billions, expectations of the software in network computers had also increased. After all, networked computers have many of the responsibilities of those sophisticated minicomputers and workstations. But Acorn was still wedded to RISC OS and, for the most part, to ARM. And it ultimately proved that while RISC OS might present quite a nice graphical interface, it was actually NetBSD that could provide the necessary versatility and reliability being sought for such endeavours.
And as the 1990s got underway, the mundane personal computer started needing some of those workstation capabilities, too, eventually erasing the distinction between these two product categories. Tooling up for Unix might have seemed like a luxury, but it had been an exercise in technological necessity. Acorn’s RISC OS had its attractions, notably various user interface paradigms that really should have become more commonplace, together with a scalable vector font system that rendered anti-aliased characters on screen years before Apple or Microsoft managed to, one that permitted the accurate reproduction of those fonts on a dot-matrix printer, a laser printer, and everything in-between.
But the foundations of RISC OS were a legacy from Acorn’s 8-bit era, laid down hastily in an arguably cynical fashion to get the Archimedes out of the door and to postpone the consequences. Commodore inevitably had similar problems with its own legacy software technology, ostensibly more modern than Acorn’s when it was introduced in the Amiga, even having some heritage from another Cambridge endeavour. Acorn might have ported its differentiating technologies to Unix, following the path taken by Torch and its close relative, IXI, also using the opportunity to diversify its hardware options.
In all of this consideration given to Acorn and Commodore, it might seem that Apple, mentioned many paragraphs earlier, has been forgotten. In fact, Apple went through many of the same trials and ordeals as its smaller rivals. Indeed, having made so much money from the Macintosh, Apple’s own attempts to modernise itself and its products involve such a catalogue of projects and initiatives that even summarising them would expand this article considerably.
Only Apple would buy a supercomputer to attempt to devise its own processor architecture – Aquarius – only not to follow through and eventually be rescued by the pair of IBM and Motorola, humbled by an unanticipated decline in their financial and market circumstances. Or have several operating system projects – Opus, Pink, Star Trek, NuKernel, Copland – that were all started but never really finished. Or to get into personal digital assistants with the unfairly maligned Newton, or to consider redesigning the office entirely with its Workspace 2000 collaboration. And yet end up acquiring NeXT, revamping its technologies along that company’s lines, and still barely make it to the end of the decade.
The Final Chapters
Commodore got almost half-way through the 1990s before bankruptcy beckoned. Motorola’s 68060, informed by the work on the chip manufacturer’s abandoned 88000 RISC architecture, provided a considerable performance boost to its more established architecture, even if it now trailed the pack, perhaps only matching previous generations of SPARC and MIPS processors, and now played second fiddle to PowerPC in Motorola’s own line-up.
Acorn’s customers would be slightly luckier. Digital’s StrongARM almost entirely eclipsed ARM’s rather sedate ARM7-based offerings, except in floating-point performance in comparison to a single system-on-chip product, the ARM7500FE. This infusion of new technology was a blessing and a curse for Acorn and its devotees. The Risc PC could not make full use of this performance, and a new machine would be needed to truly make the most of it, also getting a long-overdue update in a range of core industry technologies.
Commodore’s devotees tend to make much of the company’s mismanagement. Deserved or otherwise, one may now be allowed to judge whether the company was truly unique in this regard. As Acorn’s network computer ambitions were curtailed, market conditions became more unfavourable to its increasingly marginalised platform, and the lack of investment in that core platform started to weigh heavily on the company and its customers. A shift in management resulted in a shift in business and yet another endeavour being initiated.
Acorn’s traditional business units were run down, the company’s next generation of personal computer hardware cancelled, and yet a somewhat tangential silicon design business was effectively being incubated elsewhere within the organisation. Meanwhile, Acorn, sitting on a substantial number of shares in ARM, supposedly presented a vulnerability for the latter and its corporate stability. So, a plan was hatched that saw Acorn sold off to a division of an investment bank based in a tax haven, the liberation of its shares in ARM, and the dispersal of Acorn’s assets at rather low prices. That, of course, included the newly incubated silicon design operation, bought by various figures in Acorn’s “senior management”.
Just as Commodore’s demise left customers and distributors seemingly abandoned, so did Acorn’s. While Commodore went through the indignity of rescues and relaunches, Acorn itself disappeared into the realms of anonymous holding companies, surfacing only occasionally in reports of product servicing agreements and other unglamorous matters. Acorn’s product lines were kept going for as long as could be feasible by distributors who had paid for the privilege, but without the decades of institutional experience of an organisation terminated almost overnight, there was never likely to be a glorious resurgence of its computer systems. Its software platform was developed further, primarily for set-top box applications, and survives today more as a curiosity than a contender.
In recent days, efforts have been made by Commodore devotees to secure the rights to trademarks associated with the company, these having apparently been licensed by various holding companies over the years. Various Acorn trademarks were also offloaded to licensors, leading to at least one opportunistic but ill-conceived and largely unwelcome attempt to trade on nostalgia and to cosplay the brand. Whether such attempts might occur in future remains uncertain: Acorn’s legacy intersects with that of the BBC, ARM and other institutions, and there is perhaps more sensitivity about how its trademarks might be used.
In all of this, I don’t want to downplay all of the reasons often given for these companies’ demise, Commodore’s in particular. In reading accounts of people who worked for the company, it is clear that it was not a well-run workplace, with exploitative and abusive behaviour featuring disturbingly regularly. Instead, I wish to highlight the lack of understanding in the communities around these companies and the attribution of success or failure to explanations that do not really hold up.
For instance, the Acorn Electron may have consumed many resources in its development and delivery, but it did not lead to Acorn’s “downfall”, as was claimed by one absurd comment I read recently. Acorn’s rescue by Olivetti was the consequence of several other things, too, including an ill-advised excursion into the US market, an attempt to move upmarket with an inadequate product range, some curious procurement and logistics practices, and a lack of capital from previous stock market flotations. And if there had been such a “downfall”, such people would not be piping up constantly about ARM being “the chip in everyone’s phone”, which is tiresomely fashionable these days. ARM may well have been just a short footnote in some dry text about processor architectures.
In these companies, some management decisions may have made sense, while others were clearly ill-considered. Similarly, those building the products could only do so much given the technological choices that had already been made. But more intriguing than the actual intrigues of business is to consider what these companies might have learned from each other, what the product developers might have borrowed from each other had they been able to, and what they might have achieved had they been able to collaborate somehow. Instead, both companies went into decline and ultimately fell, divided by the barriers of competition.
Update: It seems that the chart did not have the correct value for the Amiga 4000/040, due to a missing conversion from VAX MIPS to something resembling the original Dhrystone score. Thus, in integer performance as measured by this benchmark, the 68040 at 25MHz was broadly comparable to the R3000 at 25MHz, but was also already slipping behind faster R3000 parts even before the SuperSPARC and R4000 emerged.
On a tale of two pull requests
June 15th, 2025
I was going to leave a comment on “A tale of two pull requests”, but would need to authenticate myself via one of the West Coast behemoths. So, for the benefit of readers of the FSFE Community Planet, here is my irritable comment in a more prominent form.
I don’t think I appreciate either the silent treatment or the aggression typically associated with various Free Software projects. Both communicate in some way that contributions are not really welcome: that the need for such contributions isn’t genuine, perhaps, or that the contributor somehow isn’t working hard enough or isn’t good enough to have their work integrated. Never mind that the contributor will, in many cases, be doing it in their own time and possibly even to fix something that was supposed to work in the first place.
All these projects complain about taking on the maintenance burden from contributions, yet they constantly churn up their own code and make work for themselves and any contributors still hanging on for the ride. There are projects that I used to care about that I just don’t care about any more. Primarily, for me, this would be Python: a technology I still use in my own conservative way, but where the drama and performance of Python’s own development can just shake itself out to its own disastrous conclusion as far as I am concerned. I am simply beyond caring.
Too bad that all the scurrying around trying to appeal to perceived market needs while ignoring actual needs, along with a stubborn determination to ignore instructive prior art in the various areas they are trying to improve, needlessly or otherwise, all fails to appreciate the frustrating experience for many of Python’s users today. Amongst other things, a parade of increasingly incoherent packaging tools just drives users away, heaping regret on those who chose the technology in the first place. Perhaps someone’s corporate benefactor should have invested in properly addressing these challenges, but that patronage was purely opportunism, as some are sadly now discovering.
Let the core developers of these technologies do end-user support and fix up their own software for a change. If it doesn’t happen, why should I care? It isn’t my role to sustain whatever lifestyle these people feel that they’re entitled to.
Consumerists Never Really Learn
May 15th, 2025
Via an article about a Free Software initiative hoping to capitalise on the discontinuation of Microsoft Windows 10, I saw that the consumerists at Which? had published their own advice. Predictably, it mostly emphasises workarounds that merely perpetuate the kind of bad choices Which? has promoted over the years along with yet more shopping opportunities.
Those workarounds involve either continuing to delegate control to the same company whose abandonment of its users is the very topic of the article, or to switch to another surveillance economy supplier who will inevitably do the same when they deem it convenient. Meanwhile, the shopping opportunities involve buying a new computer – as one would entirely expect from Which? – or upgrading your existing computer, but only “if you’re using a desktop”. I guess adding more memory to a laptop or switching to solid-state media, both things that have rejuvenated a laptop from over a decade ago that continues to happily runs Linux, is beyond comprehension at Which? headquarters.
Only eventually do they suggest Ubuntu, presumably because it is the only Linux distribution they have heard of. I personally suggest Debian. That laptop happily running Linux was running Ubuntu, since that is what it was shipped with, but then Ubuntu first broke upgrades in an unhelpful way, hawking commercial support in the update interface to the confusion of the laptop’s principal user (and, by extension, to my confusion as I attempted to troubleshoot this anomalous behaviour), and also managed to put out a minor release of Dippy Dragon, or whatever it was, that was broken and rendered the machine unbootable without appropriate boot media.
Despite this being a known issue, they left this broken image around for people to download and use instead of fixing their mess and issuing a further update. That this also happened during the lockdown years when I wasn’t able to personally go and fix the problem in person, and when the laptop was also needed for things like interacting with public health services, merely reinforced my already dim view of some of Ubuntu’s release practices. Fortunately, some Debian installation media rescued the situation, and a switch to Debian was the natural outcome. It isn’t as if Ubuntu actually has any real benefits over Debian any more, anyway. If anything, the dubious custodianship of Ubuntu has made Debian the more sensible choice.
As for Which? and their advice, had the organisation actually used its special powers to shake up the corrupt computing industry, instead of offering little more than consumerist hints and tips, all the while neglecting the fundamental issues of trust, control, information systems architecture, sustainability and the kind of fair competition that the organisation is supposed to promote, then their readers wouldn’t be facing down an October deadline to fix a computer that Which? probably recommended in the first place, loaded up with anti-virus nonsense and other workarounds for the ecosystem they have lazily promoted over the years.
And maybe the British technology sector would be more than just the odd “local computer repair shop” scratching a living at one end of the scale, a bunch of revenue collectors for the US technology industry pulling down fat public sector contracts and soaking up unlimited amounts of taxpayer money at the other, and relatively little to mention in between. But that would entail more than casual shopping advice and fist-shaking at the consequences of a consumerist culture that the organisation did little to moderate, at least while it could consider itself both watchdog and top dog.
Replaying the Microcomputing Revolution
January 6th, 2025
Since microcomputing and computing history are particular topics of interest of mine, I was naturally engaged by a recent article about the Raspberry Pi and its educational ambitions. Perhaps obscured by its subsequent success in numerous realms, the aspirations that originally drove the development of the Pi had their roots in the effects of the introduction of microcomputers in British homes and schools during the 1980s, a phenomenon that supposedly precipitated a golden age of hands-on learning, initiating numerous celebrated and otherwise successful careers in computing and technology.
Such mythology has the tendency to greaten expectations and deepen nostalgia, and when society enters a malaise in one area or another, it often leads to efforts to bring back the magic through new initiatives. Enter the Raspberry Pi! But, as always, we owe it to ourselves to step through the sequence of historical events, as opposed to simply accepting the narratives peddled by those with an agenda or those looking for comforting reminders of their own particular perspectives from an earlier time.
The Raspberry Pi and other products, such as the BBC Micro Bit, associated with relatively recent educational initiatives, were launched with the intention of restoring the focus of learning about computing to that of computing and computation itself. Once upon a time, computers were largely confined to large organisations and particular kinds of endeavour, generally interacting only indirectly with wider society. Thus, for most people, what computers were remained an abstract notion, often coupled with talk of the binary numeral system as the “language” of these mysterious and often uncompromising machines.
However, as microcomputers emerged both in the hobbyist realm – frequently emphasised in microcomputing history coverage – and in commercial environments such as shops and businesses, governments and educators identified a need for “computer literacy”. This entailed practical experience with computers and their applications, informed by suitable educational material, enabling the broader public to understand the limitations and the possibilities of these machines.
Although computers had already been in use for decades, microcomputing diminished the cost of accessible computing systems and thereby dramatically expanded their reach. And when technology is adopted by a much larger group, there is usually a corresponding explosion in applications of that technology as its users make their own discoveries about what the technology might be good for. The limitations of microcomputers relative to their more sophisticated predecessors – mainframes and minicomputers – also meant that existing, well-understood applications were yet to be successfully transferred from those more powerful and capable systems, leaving the door open for nimble, if somewhat less capable, alternatives to be brought to market.
The Capable User
All of these factors pointed towards a strategy where users of computers would not only need to be comfortable interacting with these systems, but where they would also need to have a broad range of skills and expertise, allowing them to go beyond simply using programs that other people had made. Instead, they would need to be empowered to modify existing programs and even write their own. With microcomputers only having a limited amount of memory and often less than convenient storage solutions (cassette tapes being a memorable example), and with few available programs for typically brand new machines, the emphasis of the manufacturer was often on giving the user the tools to write their own software.
Computer literacy efforts sensibly and necessarily went along with such trends, and from the late 1970s and early 1980s, after broader educational programmes seeking to inform the public about microelectronics and computing, these efforts targeted existing models of computer with learning materials like “30 Hour BASIC”. Traditional publishers became involved as the market opportunities grew for producing and selling such materials, and publications like Usbourne’s extensive range of computer programming titles were incredibly popular.
Numerous microcomputer manufacturers were founded, some rather more successful and long-lasting than others. An industry was born, around which was a vibrant community – or many vibrant communities – consuming software and hardware for their computers, but crucially also seeking to learn more about their machines and exchanging their knowledge, usually through the specialist print media of the day: magazines, newsletters, bulletins and books. This, then, was that golden age, of computer studies lessons at school, learning BASIC, and of late night coders at home, learning machine code (or, more likely, assembly language) and gradually putting together that game they always wanted to write.
One can certainly question the accuracy of the stereotypical depiction of that era, given that individual perspectives may vary considerably. My own experiences involved limited exposure to educational software at primary school, and the anticipated computer studies classes at secondary school never materialising. What is largely beyond dispute is that after the exciting early years of microcomputing, the educational curriculum changed focus from learning about computers to using them to run whichever applications happened to be popular or attractive to potential employers.
The Vocational Era
Thus, microcomputers became mere tools to do other work, and in that visionless era of Thatcherism, such other work was always likely to be clerical: writing letters and doing calculations in simple spreadsheets, sowing the seeds of dysfunction and setting public expectations of information systems correspondingly low. “Computer studies” became “information technology” in the curriculum, usually involving systems feigning a level of compatibility with the emerging IBM PC “standard”. Naturally, better-off schools will have had nicer equipment, perhaps for audio and video recording and digitising, plus the accompanying multimedia authoring tools, along with a somewhat more engaging curriculum.
At some point, the Internet will have reached schools, bringing e-mail and Web access (with all the complications that entails), and introducing another range of practical topics. Web authoring and Web site development may, if pursued to a significant extent, reveal such things as scripts and services, but one must then wonder what someone encountering the languages involved for the first time might be able to make of them. A generation or two may have grown up seeing computers doing things but with no real exposure to how the magic was done.
And then, there is the matter of how receptive someone who is largely unexposed to programming might be to more involved computing topics, lower-level languages, data structures and algorithms, of the workings of the machine itself. The mythology would have us believe that capable software developers needed the kind of broad exposure provided by the raw, unfiltered microcomputing experience of the 1980s to be truly comfortable and supremely effective at any level of a computing system, having sniffed out every last trick from their favourite microcomputer back in the day.
Those whose careers were built in those early years of microcomputing may now be seeing their retirement approaching, at least if they have not already made their millions and transitioned into some kind of role advising the next generation of similarly minded entrepreneurs. They may lament the scarcity of local companies in the technology sector, look at their formative years, and conclude that the system just doesn’t make them like they used to.
(Never mind that the system never made them like that in the first place: all those game-writing kids who may or may not have gone on to become capable, professional developers were clearly ignoring all the high-minded educational stuff that other people wanted them to study. Chess computers and robot mice immediately spring to mind.)
A Topic for Another Time
What we probably need to establish, then, is whether such views truly incorporate the wealth of experience present in society, or whether they merely reflect a narrow perspective where the obvious explanation may apply to some people’s experience but fails to explain the entire phenomenon. Here, we could examine teaching at a higher educational level than the compulsory school system, particularly because academic institutions were already performing and teaching computing for decades before controversies about the school computing curriculum arose.
We might contrast the casual, self-taught, experimental approach to learning about programming and computers with the structured approach favoured in universities, of starting out with high-level languages, logic, mathematics, and of learning about how the big systems achieved their goals. I encountered people during my studies who had clearly enjoyed their formative experiences with microcomputers becoming impatient with the course of these studies, presumably wondering what value it provided to them.
Some of them quit after maybe only a year, whereas others gained an ordinary degree as opposed to graduating with honours, but hopefully they all went on to lucrative and successful careers, unconstrained and uncurtailed by their choice. But I feel that I might have missed some useful insights and experiences had I done the same. But for now, let us go along with the idea that constructive exposure to technology throughout the formative education of the average person enhances their understanding of that technology, leading to a more sophisticated and creative population.
A Complete Experience
Backtracking to the article that started this article off, we then encounter one educational ambition that has seemingly remained unaddressed by the Raspberry Pi. In microcomputing’s golden age, the motivated learner was ostensibly confronted with the full power of the machine from the point of switching on. They could supposedly study the lowest levels and interact with them using their own software, comfortable with their newly acquired knowledge of how the hardware works.
Disregarding the weird firmware situation with the Pi, it may be said that most Pi users will not be in quite the same position when running the Linux-based distribution deployed on most units as someone back in the 1980s with their BBC Micro, one of the inspirations for the Pi. This is actually a consequence of how something even cheaper than a microcomputer of an earlier era has gained sophistication to such an extent that it is architecturally one of those “big systems” that stuffy university courses covered.
In one regard, the difference in nature between the microcomputers that supposedly conferred developer prowess on a previous generation and the computers that became widespread subsequently, including single-board computers like the Pi, undermines the convenient narrative that microcomputers gave the earlier generation their perfect start. Systems built on processors like the 6502 and the Z80 did not have different privilege levels or memory management capabilities, leaving their users blissfully unaware of such concepts, even if the curious will have investigated the possibilities of interrupt handling and been exposed to any related processor modes, or even if some kind of bank switching or simple memory paging had been used by some machines.
Indeed, topics relevant to microcomputers from the second half of the 1980s are surprisingly absent from retrocomputing initiatives promoting themselves as educational aids. While the Commander X16 is mostly aimed at those seeking a modern equivalent of their own microcomputer learning environment, and many of its users may also end up mostly playing games, the Agon Light and related products are more aggressively pitched as being educational in nature. And yet, these projects cling to 8-bit processors, some inviting categorisation as being more like microcontrollers than microprocessors, as if the constraints of those processor architectures conferred simplicity. In fact, moving up from the 6502 to the 68000 or ARM made life easier in many ways for the learner.
When pitching a retrocomputing product at an audience with the intention of educating them about computing, also adding some glamour and period accuracy to the exercise, it would arguably be better to start with something from the mid-1980s like the Atari ST, providing a more scalable processor architecture and sensible instruction set, but also coupling the processor with memory management hardware. The Atari ST and Commodore Amiga didn’t have a memory management unit in their earliest models, only introducing one later to attempt a move upmarket.
Certainly, primary school children might not need to learn the details of all of this power – just learning programming would be sufficient for them – but as they progress into the later stages of their education, it would be handy to give them new challenges and goals, to understand how a system works where each program has its own resources and cannot readily interfere with other programs. Indeed, something with a RISC processor and memory management capabilities would be just as credible.
How “authentic” a product with a RISC processor and “big machine” capabilities would be, in terms of nostalgia and following on from earlier generations of products, might depend on how strict one decides to be about the whole exercise. But there is nothing inauthentic about a product with such a feature set. In fact, one came along as the de-facto successor to the BBC Micro, and yet relatively little attention seems to be given to how it addressed some of the issues faced by the likes of the Pi.
Under The Hood
In assessing the extent of the Pi’s educational scope, the aforementioned article has this to say:
“Encouraging naive users to go under the hood is always going to be a bad idea on systems with other jobs to do.”
For most people, the Pi is indeed running many jobs and performing many tasks, just as any Linux system might do. And as with any “big machine”, the user is typically and deliberately forbidden from going “under the hood” and interfering with the normal functioning of the system. Even if a Pi is only hosting a single user, unlike the big systems of the past with their obligations to provide a service to many users.
Of course, for most purposes, such a system has traditionally been more than adequate for people to learn about programming. But traditionally, low-level systems programming and going under the hood generally meant downtime, which on expensive systems was largely discouraged, confined to inconvenient times of day, and potentially undertaken at one’s peril. Things have changed somewhat since the old days, however, and we will return to that shortly. But satisfying the expectations of those wanting a responsive but powerful learning environment was a challenge encountered even as the 1980s played out.
With early 1980s microcomputers like the BBC Micro, several traits comprised the desirable package that people now seek to reproduce. The immediacy of such systems allowed users to switch on and interact with the computer in only a few seconds, as opposed to a lengthy boot sequence that possibly also involved inserting disks, never mind the experiences of the batch computing era that earlier computing students encountered. Such interactivity lent such systems a degree of transparency, letting the user interact with the system and rapidly see the effects. Interactions were not necessarily constrained to certain facets of the system, allowing users to engage with the mechanisms “under the hood” with both positive and negative effects.
The Machine Operating System (MOS) of the BBC Micro and related machines such as the Acorn Electron and BBC Master series, provided well-defined interfaces to extend the operating system, introduce event or interrupt handlers, to deliver utilities in the form of commands, and to deliver languages and applications. Such capabilities allowed users to explore the provided functionality and the framework within which it operated. Users could also ignore the operating system’s facilities and more or less take full control of the machine, slipping out of one set of imposed constraints only to be bound by another, potentially more onerous set of constraints.
Earlier Experiences
Much is made of the educational impact of systems like the BBC Micro by those wishing to recapture some of the magic on more capable systems, but relatively few people seem to be curious about how such matters were tackled by the successor to the BBC Micro and BBC Master ranges: Acorn’s Archimedes series. As a step away from earlier machines, the Archimedes offers an insight into how simplicity and immediacy can still be accommodated on more powerful systems, through native support for familiar technology such as BASIC, compatibility layers for old applications, and system emulators for those who need to exercise some of the new hardware in precisely the way that worked on the older hardware.
When the Archimedes was delivered, the original Arthur operating system largely provided the recognisable BBC Micro experience. Starting up showed a familiar welcome message, and even if it may have dropped the user at a “supervisor” prompt as opposed to BASIC, something which did also happen occasionally on earlier machines, typing “BASIC” got the user the rest of the way to the environment they had come to expect. This conferred the ability to write programs exercising the graphical and audio capabilities of the machine to a substantial degree, including access to assembly language, albeit of a different and rather superior kind to that of the earlier machines. Even writing directly to screen memory worked, albeit at a different location and with a more sensible layout.
Under Arthur, users could write programs largely as before, with differences attributable to the change in capabilities provided by the new machines. Even though errant pokes to exotic memory locations might have been trapped and handled by the system’s enhanced architecture, it was still possible to write software that ran in a privileged mode, installed interrupt handlers, and produced clever results, at the risk of freezing or crashing the system. When Arthur was superseded by RISC OS, the desktop interface became the default experience, hiding the immediacy and the power of the command prompt and BASIC, but such facilities remained only a keypress away and could be configured as the default with perhaps only a single command.
RISC OS exposed the tensions between the need for a more usable and generally accessible interface, potentially doing many things at once, and the desire to be able to get under the hood and poke around. It was possible to write desktop applications in BASIC, but this was not really done in a particularly interactive way, and programs needed to make system calls to interact with the rest of the desktop environment, even though the contents of windows were painted using the classic BASIC graphics primitives otherwise available to programs outside the desktop. Desktop programs were also expected to cooperate properly with each other, potentially hanging the system if not written correctly.
The Maestro music player in RISC OS, written in BASIC. Note that the !RunImage file is a BASIC program, with the somewhat compacted code shown in the text editor.
A safer option for those wanting the classic experience and to leverage their hard-earned knowledge, was to forget about the desktop and most of the newer capabilities of the Archimedes and to enter the BBC Micro emulator, 65Host, available on one of the supplied application disks, writing software just as before, and then running that software or any other legacy software of choice. Apart from providing file storage to the emulator and bearing all the work of the emulator itself, this did not really exercise the newer machine, but it still provided a largely authentic, traditional experience. One could presumably crash the emulated machine, but this should merely have terminated the emulator.
An intermediate form of legacy application support was also provided. 65Tube, with “Tube” referencing an interfacing paradigm used by the BBC Micro, allowed applications written against documented interfaces to run under emulation but accessing facilities in the native environment. This mostly accommodated things like programming language environments and productivity applications and might have seemed superfluous alongside the provision of a more comprehensive emulator, but it potentially allowed such applications to access capabilities that were not provided on earlier systems, such as display modes with greater resolutions and more colours, or more advanced filesystems of different kinds. Importantly, from an educational perspective, these emulators offered experiences that could be translated to the native environment.
65Tube running in MODE 15, utilising many more colours than normally available on earlier Acorn machines.
Although the Archimedes drifted away from the apparent simplicity of the BBC Micro and related machines, most users did not fully understand the software stack on such earlier systems, anyway. However, despite the apparent sophistication of the BBC Micro’s successors, various aspects of the software architecture were, in fact, preserved. Even the graphical user interface on the Archimedes was built upon many familiar concepts and abstractions. The difficulty for users moving up to the newer system arose upon finding that much of their programming expertise and effort had to be channelled into a software framework that confined the activities of their code, particularly in the desktop environment. One kind of framework for more advanced programs had merely been replaced by others.
Finding Lessons for Today
The way the Archimedes attempted to accommodate the expectations cultivated by earlier machines does not necessarily offer a convenient recipe to follow today. However, the solutions it offered should draw our attention to some other considerations. One is the level of safety in the environment being offered: it should be possible to interact with the system without bringing it down or causing havoc.
In that respect, the Archimedes provided a sandboxed environment like an emulator, but this was only really viable for running old software, as indeed was the intention. It also did not multitask, although other emulators eventually did. The more integrated 65Tube emulator also did not multitask, although later enhancements to RISC OS such as task windows did allow it to multitask to a degree.
65Tube running in a task window. This relies on the text editing application and unfortunately does not support fancy output.
Otherwise, the native environment offered all the familiar tools and the desired level of power, but along with them plenty of risks for mayhem. Thus, a choice between safety and concurrency was forced upon the user. (Aside from Arthur and RISC OS, there was also Acorn’s own Unix port, RISC iX, which had similar characteristics to the kind of Linux-based operating system typically run on the Pi. You could, in principle, run a BBC Micro emulator under RISC iX, just as people run emulators on the Pi today.)
Today, we could actually settle for the same software stack on some Raspberry Pi models, with all its advantages and disadvantages, by running an updated version of RISC OS on such hardware. The bundled emulator support might be missing, however, but for those wanting to go under the hood and also take advantage of the hardware, it is unlikely that they would be so interested in replicating the original BBC Micro experience with perfect accuracy, instead merely seeking to replicate the same kind of experience.
Another consideration the Archimedes raises is the extent to which an environment may take advantage of the host system, and it is this consideration that potentially has the most to offer in formulating modern solutions. We may normally be completely happy running a programming tool in our familiar computing environments, where graphical output, for example, may be confined to a window or occasionally shown in full-screen mode. Indeed, something like a Raspberry Pi need not have any rigid notion of what its “native” graphical capabilities are, and the way a framebuffer is transferred to an actual display is normally not of any real interest.
The learning and practice of high-level programming can be adequately performed in such a modern environment, with the user safely confined by the operating system and mostly unable to bring the system down. However, it might not adequately expose the user to those low-level “under the hood” concepts that they seem to be missing out on. For example, we may wish to introduce the framebuffer transfer mechanism as some kind of educational exercise, letting the user appreciate how the text and graphics plotting facilities they use lead to pixels appearing on their screen. On the BBC Micro, this would have involved learning about how the MOS configures the 6845 display controller and the video ULA to produce a usable display.
The configuration of such a mechanism typically resides at a fairly low level in the software stack, out of the direct reach of the user, but allowing a user to reconfigure such a mechanism would risk introducing disruption to the normal functioning of the system. Therefore, a way is needed to either expose the mechanism safely or to simulate it. Here, technology’s steady progression does provide some possibilities that were either inconvenient or impossible on an early ARM system like the Archimedes, notably virtualisation support, allowing us to effectively run a simulation of the hardware efficiently on the hardware itself.
Thus, we might develop our own framebuffer driver and fire up a virtual machine running our operating system of choice, deploying the driver and assessing the consequences provided by a simulation of that aspect of the hardware. Of course, this would require support in the virtual environment for that emulated element of the hardware. Alternatively, we might allow some kind of restrictive access to that part of the hardware, risking the failure of the graphical interface if misconfiguration occurred, but hopefully providing some kind of fallback control mechanism, like a serial console or remote login, to restore that interface and allow the errant code to be refined.
A less low-level component that might invite experimentation could be a filesystem. The MOS in the BBC Micro and related machines provided filesystem (or filing system) support in the form of service ROMs, and in RISC OS on the Archimedes such support resides in the conceptually similar relocatable modules. Given the ability of normal users to load such modules, it was entirely possible for a skilled user to develop and deploy their own filesystem support, with the associated risks of bringing down the system. Linux does have arguably “glued-on” support for unprivileged filesystem deployment, but there might be other components in the system worthy of modification or replacement, and thus the virtual machine might need to come into play again to allow the desired degree of experimentation.
A Framework for Experimentation
One can, however, envisage a configurable software system where a user session might involve a number of components providing the features and services of interest, and where a session might be configured to exclude or include certain typical or useful components, to replace others, and to allow users to deploy their own components in a safe fashion. Alongside such activities, a normal system could be running, providing access to modern conveniences at a keypress or the touch of a button.
We might want the flexibility to offer something resembling 65Host, albeit without the emulation of an older system and its instruction set, for a highly constrained learning environment where many aspects of the system can be changed for better or worse. Or we might want something closer to 65Tube, again without the emulation, acting mostly as a “native” program but permitting experimentation on a few elements of the experience. An entire continuum of possibilities could be supported by a configurable framework, allowing users to progress from a comfortable environment with all of the expected modern conveniences, gradually seeing each element removed and then replaced with their own implementation, until arriving in an environment where they have the responsibility at almost every level of the system.
In principle, a modern system aiming to provide an “under the hood” experience merely needs to simulate that experience. As long as the user experiences the same general effects from their interactions, the environment providing the experience can still isolate a user session from the underlying system and avoid unfortunate consequences from that misbehaving session. Purists might claim that as long as any kind of simulation is involved, the user is not actually touching the hardware and is therefore not engaging in low-level development, even if the code they are writing would be exactly the code that would be deployed on the hardware.
Systems programming can always be done by just writing programs and deploying them on the hardware or in a virtual machine to see if they work, resetting the system and correcting any mistakes, which is probably how most programming of this kind is done even today. However, a suitably configurable system would allow a user to iteratively and progressively deploy a customised system, and to work towards deploying a complete system of their own. With the final pieces in place, the user really would be exercising the hardware directly, finally silencing the purists.
Naturally, given my interest in microkernel-based systems, the above concept would probably rest on the use of a microkernel, with much more of a blank canvas available to define the kind of system we might like, as opposed to more prescriptive systems with monolithic kernels and much more of the basic functionality squirrelled away in privileged kernel code. Perhaps the only difficult elements of a system to open up to user modification, those that cannot also be easily delegated or modelled by unprivileged components, would be those few elements confined to the microkernel and performing fundamental operations such as directly handling interrupts, switching execution contexts (threads), writing memory mappings to the appropriate registers, and handling system calls and interprocess communications.
Even so, many aspects of these low-level activities are exposed to user-level components in microkernel-based operating systems, leaving few mysteries remaining. For those advanced enough to progress to kernel development, traditional systems programming practices would surely be applicable. But long before that point, motivated learners will have had plenty of opportunities to get “under the hood” and to acquire a reasonable understanding of how their systems work.
A Conclusion of Sorts
As for why people are not widely using the Raspberry Pi to explore low-level computing, the challenge of facilitating such exploration when the system has “other jobs to do” certainly seems like a reasonable excuse, especially given the choice of operating system deployed on most Pi devices. One could remove those “other jobs” and run RISC OS, of course, putting the learner in an unfamiliar and more challenging environment, perhaps giving them another computer to use at the same time to look things up on the Internet. Or one could adopt a different software architecture, but that would involve an investment in software that few organisations can be bothered to make.
I don’t know whether the University of Cambridge has seen better-educated applicants in recent years as a result of Pi proliferation, or whether today’s applicants are as similarly perplexed by low-level concepts as those from the pre-Pi era. But then, there might be a lesson to be learned about applying some rigour to technological interventions in society. After all, there were some who justifiably questioned the effectiveness of rolling out microcomputers in schools, particularly when teachers have never really been supported in their work, as more and more is asked of them by their political overlords. Investment in people and their well-being is another thing that few organisations can be bothered to make, too.