Paul Boddie's Free Software-related blog
Paul's activities and perspectives around Free Software
On a tale of two pull requests
June 15th, 2025
I was going to leave a comment on “A tale of two pull requests”, but would need to authenticate myself via one of the West Coast behemoths. So, for the benefit of readers of the FSFE Community Planet, here is my irritable comment in a more prominent form.
I don’t think I appreciate either the silent treatment or the aggression typically associated with various Free Software projects. Both communicate in some way that contributions are not really welcome: that the need for such contributions isn’t genuine, perhaps, or that the contributor somehow isn’t working hard enough or isn’t good enough to have their work integrated. Never mind that the contributor will, in many cases, be doing it in their own time and possibly even to fix something that was supposed to work in the first place.
All these projects complain about taking on the maintenance burden from contributions, yet they constantly churn up their own code and make work for themselves and any contributors still hanging on for the ride. There are projects that I used to care about that I just don’t care about any more. Primarily, for me, this would be Python: a technology I still use in my own conservative way, but where the drama and performance of Python’s own development can just shake itself out to its own disastrous conclusion as far as I am concerned. I am simply beyond caring.
Too bad that all the scurrying around trying to appeal to perceived market needs while ignoring actual needs, along with a stubborn determination to ignore instructive prior art in the various areas they are trying to improve, needlessly or otherwise, all fails to appreciate the frustrating experience for many of Python’s users today. Amongst other things, a parade of increasingly incoherent packaging tools just drives users away, heaping regret on those who chose the technology in the first place. Perhaps someone’s corporate benefactor should have invested in properly addressing these challenges, but that patronage was purely opportunism, as some are sadly now discovering.
Let the core developers of these technologies do end-user support and fix up their own software for a change. If it doesn’t happen, why should I care? It isn’t my role to sustain whatever lifestyle these people feel that they’re entitled to.
Consumerists Never Really Learn
May 15th, 2025
Via an article about a Free Software initiative hoping to capitalise on the discontinuation of Microsoft Windows 10, I saw that the consumerists at Which? had published their own advice. Predictably, it mostly emphasises workarounds that merely perpetuate the kind of bad choices Which? has promoted over the years along with yet more shopping opportunities.
Those workarounds involve either continuing to delegate control to the same company whose abandonment of its users is the very topic of the article, or to switch to another surveillance economy supplier who will inevitably do the same when they deem it convenient. Meanwhile, the shopping opportunities involve buying a new computer – as one would entirely expect from Which? – or upgrading your existing computer, but only “if you’re using a desktop”. I guess adding more memory to a laptop or switching to solid-state media, both things that have rejuvenated a laptop from over a decade ago that continues to happily runs Linux, is beyond comprehension at Which? headquarters.
Only eventually do they suggest Ubuntu, presumably because it is the only Linux distribution they have heard of. I personally suggest Debian. That laptop happily running Linux was running Ubuntu, since that is what it was shipped with, but then Ubuntu first broke upgrades in an unhelpful way, hawking commercial support in the update interface to the confusion of the laptop’s principal user (and, by extension, to my confusion as I attempted to troubleshoot this anomalous behaviour), and also managed to put out a minor release of Dippy Dragon, or whatever it was, that was broken and rendered the machine unbootable without appropriate boot media.
Despite this being a known issue, they left this broken image around for people to download and use instead of fixing their mess and issuing a further update. That this also happened during the lockdown years when I wasn’t able to personally go and fix the problem in person, and when the laptop was also needed for things like interacting with public health services, merely reinforced my already dim view of some of Ubuntu’s release practices. Fortunately, some Debian installation media rescued the situation, and a switch to Debian was the natural outcome. It isn’t as if Ubuntu actually has any real benefits over Debian any more, anyway. If anything, the dubious custodianship of Ubuntu has made Debian the more sensible choice.
As for Which? and their advice, had the organisation actually used its special powers to shake up the corrupt computing industry, instead of offering little more than consumerist hints and tips, all the while neglecting the fundamental issues of trust, control, information systems architecture, sustainability and the kind of fair competition that the organisation is supposed to promote, then their readers wouldn’t be facing down an October deadline to fix a computer that Which? probably recommended in the first place, loaded up with anti-virus nonsense and other workarounds for the ecosystem they have lazily promoted over the years.
And maybe the British technology sector would be more than just the odd “local computer repair shop” scratching a living at one end of the scale, a bunch of revenue collectors for the US technology industry pulling down fat public sector contracts and soaking up unlimited amounts of taxpayer money at the other, and relatively little to mention in between. But that would entail more than casual shopping advice and fist-shaking at the consequences of a consumerist culture that the organisation did little to moderate, at least while it could consider itself both watchdog and top dog.
Replaying the Microcomputing Revolution
January 6th, 2025
Since microcomputing and computing history are particular topics of interest of mine, I was naturally engaged by a recent article about the Raspberry Pi and its educational ambitions. Perhaps obscured by its subsequent success in numerous realms, the aspirations that originally drove the development of the Pi had their roots in the effects of the introduction of microcomputers in British homes and schools during the 1980s, a phenomenon that supposedly precipitated a golden age of hands-on learning, initiating numerous celebrated and otherwise successful careers in computing and technology.
Such mythology has the tendency to greaten expectations and deepen nostalgia, and when society enters a malaise in one area or another, it often leads to efforts to bring back the magic through new initiatives. Enter the Raspberry Pi! But, as always, we owe it to ourselves to step through the sequence of historical events, as opposed to simply accepting the narratives peddled by those with an agenda or those looking for comforting reminders of their own particular perspectives from an earlier time.
The Raspberry Pi and other products, such as the BBC Micro Bit, associated with relatively recent educational initiatives, were launched with the intention of restoring the focus of learning about computing to that of computing and computation itself. Once upon a time, computers were largely confined to large organisations and particular kinds of endeavour, generally interacting only indirectly with wider society. Thus, for most people, what computers were remained an abstract notion, often coupled with talk of the binary numeral system as the “language” of these mysterious and often uncompromising machines.
However, as microcomputers emerged both in the hobbyist realm – frequently emphasised in microcomputing history coverage – and in commercial environments such as shops and businesses, governments and educators identified a need for “computer literacy”. This entailed practical experience with computers and their applications, informed by suitable educational material, enabling the broader public to understand the limitations and the possibilities of these machines.
Although computers had already been in use for decades, microcomputing diminished the cost of accessible computing systems and thereby dramatically expanded their reach. And when technology is adopted by a much larger group, there is usually a corresponding explosion in applications of that technology as its users make their own discoveries about what the technology might be good for. The limitations of microcomputers relative to their more sophisticated predecessors – mainframes and minicomputers – also meant that existing, well-understood applications were yet to be successfully transferred from those more powerful and capable systems, leaving the door open for nimble, if somewhat less capable, alternatives to be brought to market.
The Capable User
All of these factors pointed towards a strategy where users of computers would not only need to be comfortable interacting with these systems, but where they would also need to have a broad range of skills and expertise, allowing them to go beyond simply using programs that other people had made. Instead, they would need to be empowered to modify existing programs and even write their own. With microcomputers only having a limited amount of memory and often less than convenient storage solutions (cassette tapes being a memorable example), and with few available programs for typically brand new machines, the emphasis of the manufacturer was often on giving the user the tools to write their own software.
Computer literacy efforts sensibly and necessarily went along with such trends, and from the late 1970s and early 1980s, after broader educational programmes seeking to inform the public about microelectronics and computing, these efforts targeted existing models of computer with learning materials like “30 Hour BASIC”. Traditional publishers became involved as the market opportunities grew for producing and selling such materials, and publications like Usbourne’s extensive range of computer programming titles were incredibly popular.
Numerous microcomputer manufacturers were founded, some rather more successful and long-lasting than others. An industry was born, around which was a vibrant community – or many vibrant communities – consuming software and hardware for their computers, but crucially also seeking to learn more about their machines and exchanging their knowledge, usually through the specialist print media of the day: magazines, newsletters, bulletins and books. This, then, was that golden age, of computer studies lessons at school, learning BASIC, and of late night coders at home, learning machine code (or, more likely, assembly language) and gradually putting together that game they always wanted to write.
One can certainly question the accuracy of the stereotypical depiction of that era, given that individual perspectives may vary considerably. My own experiences involved limited exposure to educational software at primary school, and the anticipated computer studies classes at secondary school never materialising. What is largely beyond dispute is that after the exciting early years of microcomputing, the educational curriculum changed focus from learning about computers to using them to run whichever applications happened to be popular or attractive to potential employers.
The Vocational Era
Thus, microcomputers became mere tools to do other work, and in that visionless era of Thatcherism, such other work was always likely to be clerical: writing letters and doing calculations in simple spreadsheets, sowing the seeds of dysfunction and setting public expectations of information systems correspondingly low. “Computer studies” became “information technology” in the curriculum, usually involving systems feigning a level of compatibility with the emerging IBM PC “standard”. Naturally, better-off schools will have had nicer equipment, perhaps for audio and video recording and digitising, plus the accompanying multimedia authoring tools, along with a somewhat more engaging curriculum.
At some point, the Internet will have reached schools, bringing e-mail and Web access (with all the complications that entails), and introducing another range of practical topics. Web authoring and Web site development may, if pursued to a significant extent, reveal such things as scripts and services, but one must then wonder what someone encountering the languages involved for the first time might be able to make of them. A generation or two may have grown up seeing computers doing things but with no real exposure to how the magic was done.
And then, there is the matter of how receptive someone who is largely unexposed to programming might be to more involved computing topics, lower-level languages, data structures and algorithms, of the workings of the machine itself. The mythology would have us believe that capable software developers needed the kind of broad exposure provided by the raw, unfiltered microcomputing experience of the 1980s to be truly comfortable and supremely effective at any level of a computing system, having sniffed out every last trick from their favourite microcomputer back in the day.
Those whose careers were built in those early years of microcomputing may now be seeing their retirement approaching, at least if they have not already made their millions and transitioned into some kind of role advising the next generation of similarly minded entrepreneurs. They may lament the scarcity of local companies in the technology sector, look at their formative years, and conclude that the system just doesn’t make them like they used to.
(Never mind that the system never made them like that in the first place: all those game-writing kids who may or may not have gone on to become capable, professional developers were clearly ignoring all the high-minded educational stuff that other people wanted them to study. Chess computers and robot mice immediately spring to mind.)
A Topic for Another Time
What we probably need to establish, then, is whether such views truly incorporate the wealth of experience present in society, or whether they merely reflect a narrow perspective where the obvious explanation may apply to some people’s experience but fails to explain the entire phenomenon. Here, we could examine teaching at a higher educational level than the compulsory school system, particularly because academic institutions were already performing and teaching computing for decades before controversies about the school computing curriculum arose.
We might contrast the casual, self-taught, experimental approach to learning about programming and computers with the structured approach favoured in universities, of starting out with high-level languages, logic, mathematics, and of learning about how the big systems achieved their goals. I encountered people during my studies who had clearly enjoyed their formative experiences with microcomputers becoming impatient with the course of these studies, presumably wondering what value it provided to them.
Some of them quit after maybe only a year, whereas others gained an ordinary degree as opposed to graduating with honours, but hopefully they all went on to lucrative and successful careers, unconstrained and uncurtailed by their choice. But I feel that I might have missed some useful insights and experiences had I done the same. But for now, let us go along with the idea that constructive exposure to technology throughout the formative education of the average person enhances their understanding of that technology, leading to a more sophisticated and creative population.
A Complete Experience
Backtracking to the article that started this article off, we then encounter one educational ambition that has seemingly remained unaddressed by the Raspberry Pi. In microcomputing’s golden age, the motivated learner was ostensibly confronted with the full power of the machine from the point of switching on. They could supposedly study the lowest levels and interact with them using their own software, comfortable with their newly acquired knowledge of how the hardware works.
Disregarding the weird firmware situation with the Pi, it may be said that most Pi users will not be in quite the same position when running the Linux-based distribution deployed on most units as someone back in the 1980s with their BBC Micro, one of the inspirations for the Pi. This is actually a consequence of how something even cheaper than a microcomputer of an earlier era has gained sophistication to such an extent that it is architecturally one of those “big systems” that stuffy university courses covered.
In one regard, the difference in nature between the microcomputers that supposedly conferred developer prowess on a previous generation and the computers that became widespread subsequently, including single-board computers like the Pi, undermines the convenient narrative that microcomputers gave the earlier generation their perfect start. Systems built on processors like the 6502 and the Z80 did not have different privilege levels or memory management capabilities, leaving their users blissfully unaware of such concepts, even if the curious will have investigated the possibilities of interrupt handling and been exposed to any related processor modes, or even if some kind of bank switching or simple memory paging had been used by some machines.
Indeed, topics relevant to microcomputers from the second half of the 1980s are surprisingly absent from retrocomputing initiatives promoting themselves as educational aids. While the Commander X16 is mostly aimed at those seeking a modern equivalent of their own microcomputer learning environment, and many of its users may also end up mostly playing games, the Agon Light and related products are more aggressively pitched as being educational in nature. And yet, these projects cling to 8-bit processors, some inviting categorisation as being more like microcontrollers than microprocessors, as if the constraints of those processor architectures conferred simplicity. In fact, moving up from the 6502 to the 68000 or ARM made life easier in many ways for the learner.
When pitching a retrocomputing product at an audience with the intention of educating them about computing, also adding some glamour and period accuracy to the exercise, it would arguably be better to start with something from the mid-1980s like the Atari ST, providing a more scalable processor architecture and sensible instruction set, but also coupling the processor with memory management hardware. The Atari ST and Commodore Amiga didn’t have a memory management unit in their earliest models, only introducing one later to attempt a move upmarket.
Certainly, primary school children might not need to learn the details of all of this power – just learning programming would be sufficient for them – but as they progress into the later stages of their education, it would be handy to give them new challenges and goals, to understand how a system works where each program has its own resources and cannot readily interfere with other programs. Indeed, something with a RISC processor and memory management capabilities would be just as credible.
How “authentic” a product with a RISC processor and “big machine” capabilities would be, in terms of nostalgia and following on from earlier generations of products, might depend on how strict one decides to be about the whole exercise. But there is nothing inauthentic about a product with such a feature set. In fact, one came along as the de-facto successor to the BBC Micro, and yet relatively little attention seems to be given to how it addressed some of the issues faced by the likes of the Pi.
Under The Hood
In assessing the extent of the Pi’s educational scope, the aforementioned article has this to say:
“Encouraging naive users to go under the hood is always going to be a bad idea on systems with other jobs to do.”
For most people, the Pi is indeed running many jobs and performing many tasks, just as any Linux system might do. And as with any “big machine”, the user is typically and deliberately forbidden from going “under the hood” and interfering with the normal functioning of the system. Even if a Pi is only hosting a single user, unlike the big systems of the past with their obligations to provide a service to many users.
Of course, for most purposes, such a system has traditionally been more than adequate for people to learn about programming. But traditionally, low-level systems programming and going under the hood generally meant downtime, which on expensive systems was largely discouraged, confined to inconvenient times of day, and potentially undertaken at one’s peril. Things have changed somewhat since the old days, however, and we will return to that shortly. But satisfying the expectations of those wanting a responsive but powerful learning environment was a challenge encountered even as the 1980s played out.
With early 1980s microcomputers like the BBC Micro, several traits comprised the desirable package that people now seek to reproduce. The immediacy of such systems allowed users to switch on and interact with the computer in only a few seconds, as opposed to a lengthy boot sequence that possibly also involved inserting disks, never mind the experiences of the batch computing era that earlier computing students encountered. Such interactivity lent such systems a degree of transparency, letting the user interact with the system and rapidly see the effects. Interactions were not necessarily constrained to certain facets of the system, allowing users to engage with the mechanisms “under the hood” with both positive and negative effects.
The Machine Operating System (MOS) of the BBC Micro and related machines such as the Acorn Electron and BBC Master series, provided well-defined interfaces to extend the operating system, introduce event or interrupt handlers, to deliver utilities in the form of commands, and to deliver languages and applications. Such capabilities allowed users to explore the provided functionality and the framework within which it operated. Users could also ignore the operating system’s facilities and more or less take full control of the machine, slipping out of one set of imposed constraints only to be bound by another, potentially more onerous set of constraints.
Earlier Experiences
Much is made of the educational impact of systems like the BBC Micro by those wishing to recapture some of the magic on more capable systems, but relatively few people seem to be curious about how such matters were tackled by the successor to the BBC Micro and BBC Master ranges: Acorn’s Archimedes series. As a step away from earlier machines, the Archimedes offers an insight into how simplicity and immediacy can still be accommodated on more powerful systems, through native support for familiar technology such as BASIC, compatibility layers for old applications, and system emulators for those who need to exercise some of the new hardware in precisely the way that worked on the older hardware.
When the Archimedes was delivered, the original Arthur operating system largely provided the recognisable BBC Micro experience. Starting up showed a familiar welcome message, and even if it may have dropped the user at a “supervisor” prompt as opposed to BASIC, something which did also happen occasionally on earlier machines, typing “BASIC” got the user the rest of the way to the environment they had come to expect. This conferred the ability to write programs exercising the graphical and audio capabilities of the machine to a substantial degree, including access to assembly language, albeit of a different and rather superior kind to that of the earlier machines. Even writing directly to screen memory worked, albeit at a different location and with a more sensible layout.
Under Arthur, users could write programs largely as before, with differences attributable to the change in capabilities provided by the new machines. Even though errant pokes to exotic memory locations might have been trapped and handled by the system’s enhanced architecture, it was still possible to write software that ran in a privileged mode, installed interrupt handlers, and produced clever results, at the risk of freezing or crashing the system. When Arthur was superseded by RISC OS, the desktop interface became the default experience, hiding the immediacy and the power of the command prompt and BASIC, but such facilities remained only a keypress away and could be configured as the default with perhaps only a single command.
RISC OS exposed the tensions between the need for a more usable and generally accessible interface, potentially doing many things at once, and the desire to be able to get under the hood and poke around. It was possible to write desktop applications in BASIC, but this was not really done in a particularly interactive way, and programs needed to make system calls to interact with the rest of the desktop environment, even though the contents of windows were painted using the classic BASIC graphics primitives otherwise available to programs outside the desktop. Desktop programs were also expected to cooperate properly with each other, potentially hanging the system if not written correctly.
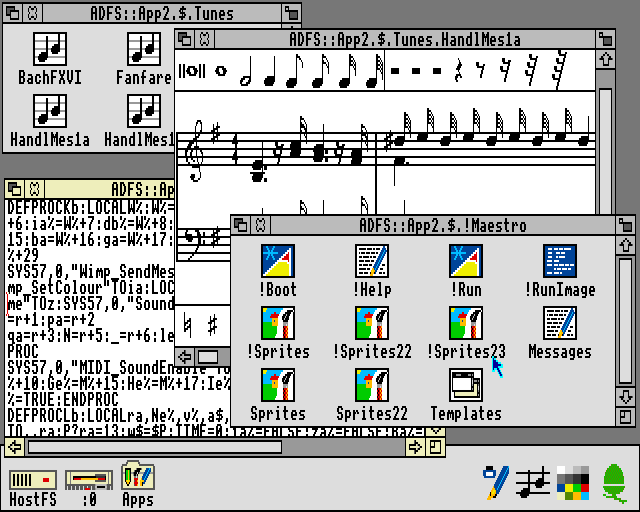
The Maestro music player in RISC OS, written in BASIC. Note that the !RunImage file is a BASIC program, with the somewhat compacted code shown in the text editor.
A safer option for those wanting the classic experience and to leverage their hard-earned knowledge, was to forget about the desktop and most of the newer capabilities of the Archimedes and to enter the BBC Micro emulator, 65Host, available on one of the supplied application disks, writing software just as before, and then running that software or any other legacy software of choice. Apart from providing file storage to the emulator and bearing all the work of the emulator itself, this did not really exercise the newer machine, but it still provided a largely authentic, traditional experience. One could presumably crash the emulated machine, but this should merely have terminated the emulator.
An intermediate form of legacy application support was also provided. 65Tube, with “Tube” referencing an interfacing paradigm used by the BBC Micro, allowed applications written against documented interfaces to run under emulation but accessing facilities in the native environment. This mostly accommodated things like programming language environments and productivity applications and might have seemed superfluous alongside the provision of a more comprehensive emulator, but it potentially allowed such applications to access capabilities that were not provided on earlier systems, such as display modes with greater resolutions and more colours, or more advanced filesystems of different kinds. Importantly, from an educational perspective, these emulators offered experiences that could be translated to the native environment.
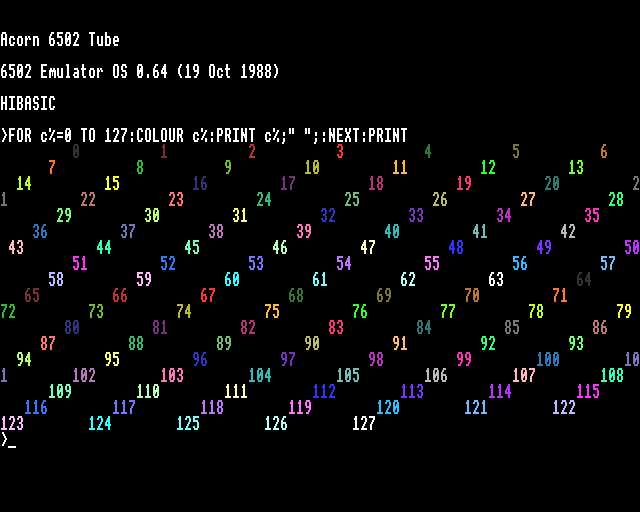
65Tube running in MODE 15, utilising many more colours than normally available on earlier Acorn machines.
Although the Archimedes drifted away from the apparent simplicity of the BBC Micro and related machines, most users did not fully understand the software stack on such earlier systems, anyway. However, despite the apparent sophistication of the BBC Micro’s successors, various aspects of the software architecture were, in fact, preserved. Even the graphical user interface on the Archimedes was built upon many familiar concepts and abstractions. The difficulty for users moving up to the newer system arose upon finding that much of their programming expertise and effort had to be channelled into a software framework that confined the activities of their code, particularly in the desktop environment. One kind of framework for more advanced programs had merely been replaced by others.
Finding Lessons for Today
The way the Archimedes attempted to accommodate the expectations cultivated by earlier machines does not necessarily offer a convenient recipe to follow today. However, the solutions it offered should draw our attention to some other considerations. One is the level of safety in the environment being offered: it should be possible to interact with the system without bringing it down or causing havoc.
In that respect, the Archimedes provided a sandboxed environment like an emulator, but this was only really viable for running old software, as indeed was the intention. It also did not multitask, although other emulators eventually did. The more integrated 65Tube emulator also did not multitask, although later enhancements to RISC OS such as task windows did allow it to multitask to a degree.
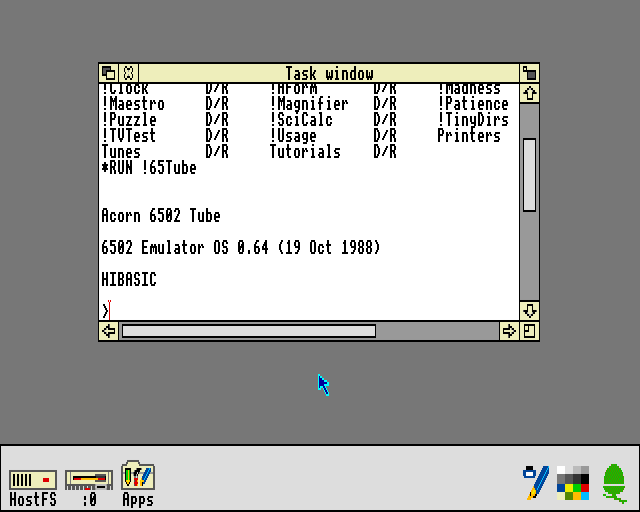
65Tube running in a task window. This relies on the text editing application and unfortunately does not support fancy output.
Otherwise, the native environment offered all the familiar tools and the desired level of power, but along with them plenty of risks for mayhem. Thus, a choice between safety and concurrency was forced upon the user. (Aside from Arthur and RISC OS, there was also Acorn’s own Unix port, RISC iX, which had similar characteristics to the kind of Linux-based operating system typically run on the Pi. You could, in principle, run a BBC Micro emulator under RISC iX, just as people run emulators on the Pi today.)
Today, we could actually settle for the same software stack on some Raspberry Pi models, with all its advantages and disadvantages, by running an updated version of RISC OS on such hardware. The bundled emulator support might be missing, however, but for those wanting to go under the hood and also take advantage of the hardware, it is unlikely that they would be so interested in replicating the original BBC Micro experience with perfect accuracy, instead merely seeking to replicate the same kind of experience.
Another consideration the Archimedes raises is the extent to which an environment may take advantage of the host system, and it is this consideration that potentially has the most to offer in formulating modern solutions. We may normally be completely happy running a programming tool in our familiar computing environments, where graphical output, for example, may be confined to a window or occasionally shown in full-screen mode. Indeed, something like a Raspberry Pi need not have any rigid notion of what its “native” graphical capabilities are, and the way a framebuffer is transferred to an actual display is normally not of any real interest.
The learning and practice of high-level programming can be adequately performed in such a modern environment, with the user safely confined by the operating system and mostly unable to bring the system down. However, it might not adequately expose the user to those low-level “under the hood” concepts that they seem to be missing out on. For example, we may wish to introduce the framebuffer transfer mechanism as some kind of educational exercise, letting the user appreciate how the text and graphics plotting facilities they use lead to pixels appearing on their screen. On the BBC Micro, this would have involved learning about how the MOS configures the 6845 display controller and the video ULA to produce a usable display.
The configuration of such a mechanism typically resides at a fairly low level in the software stack, out of the direct reach of the user, but allowing a user to reconfigure such a mechanism would risk introducing disruption to the normal functioning of the system. Therefore, a way is needed to either expose the mechanism safely or to simulate it. Here, technology’s steady progression does provide some possibilities that were either inconvenient or impossible on an early ARM system like the Archimedes, notably virtualisation support, allowing us to effectively run a simulation of the hardware efficiently on the hardware itself.
Thus, we might develop our own framebuffer driver and fire up a virtual machine running our operating system of choice, deploying the driver and assessing the consequences provided by a simulation of that aspect of the hardware. Of course, this would require support in the virtual environment for that emulated element of the hardware. Alternatively, we might allow some kind of restrictive access to that part of the hardware, risking the failure of the graphical interface if misconfiguration occurred, but hopefully providing some kind of fallback control mechanism, like a serial console or remote login, to restore that interface and allow the errant code to be refined.
A less low-level component that might invite experimentation could be a filesystem. The MOS in the BBC Micro and related machines provided filesystem (or filing system) support in the form of service ROMs, and in RISC OS on the Archimedes such support resides in the conceptually similar relocatable modules. Given the ability of normal users to load such modules, it was entirely possible for a skilled user to develop and deploy their own filesystem support, with the associated risks of bringing down the system. Linux does have arguably “glued-on” support for unprivileged filesystem deployment, but there might be other components in the system worthy of modification or replacement, and thus the virtual machine might need to come into play again to allow the desired degree of experimentation.
A Framework for Experimentation
One can, however, envisage a configurable software system where a user session might involve a number of components providing the features and services of interest, and where a session might be configured to exclude or include certain typical or useful components, to replace others, and to allow users to deploy their own components in a safe fashion. Alongside such activities, a normal system could be running, providing access to modern conveniences at a keypress or the touch of a button.
We might want the flexibility to offer something resembling 65Host, albeit without the emulation of an older system and its instruction set, for a highly constrained learning environment where many aspects of the system can be changed for better or worse. Or we might want something closer to 65Tube, again without the emulation, acting mostly as a “native” program but permitting experimentation on a few elements of the experience. An entire continuum of possibilities could be supported by a configurable framework, allowing users to progress from a comfortable environment with all of the expected modern conveniences, gradually seeing each element removed and then replaced with their own implementation, until arriving in an environment where they have the responsibility at almost every level of the system.
In principle, a modern system aiming to provide an “under the hood” experience merely needs to simulate that experience. As long as the user experiences the same general effects from their interactions, the environment providing the experience can still isolate a user session from the underlying system and avoid unfortunate consequences from that misbehaving session. Purists might claim that as long as any kind of simulation is involved, the user is not actually touching the hardware and is therefore not engaging in low-level development, even if the code they are writing would be exactly the code that would be deployed on the hardware.
Systems programming can always be done by just writing programs and deploying them on the hardware or in a virtual machine to see if they work, resetting the system and correcting any mistakes, which is probably how most programming of this kind is done even today. However, a suitably configurable system would allow a user to iteratively and progressively deploy a customised system, and to work towards deploying a complete system of their own. With the final pieces in place, the user really would be exercising the hardware directly, finally silencing the purists.
Naturally, given my interest in microkernel-based systems, the above concept would probably rest on the use of a microkernel, with much more of a blank canvas available to define the kind of system we might like, as opposed to more prescriptive systems with monolithic kernels and much more of the basic functionality squirrelled away in privileged kernel code. Perhaps the only difficult elements of a system to open up to user modification, those that cannot also be easily delegated or modelled by unprivileged components, would be those few elements confined to the microkernel and performing fundamental operations such as directly handling interrupts, switching execution contexts (threads), writing memory mappings to the appropriate registers, and handling system calls and interprocess communications.
Even so, many aspects of these low-level activities are exposed to user-level components in microkernel-based operating systems, leaving few mysteries remaining. For those advanced enough to progress to kernel development, traditional systems programming practices would surely be applicable. But long before that point, motivated learners will have had plenty of opportunities to get “under the hood” and to acquire a reasonable understanding of how their systems work.
A Conclusion of Sorts
As for why people are not widely using the Raspberry Pi to explore low-level computing, the challenge of facilitating such exploration when the system has “other jobs to do” certainly seems like a reasonable excuse, especially given the choice of operating system deployed on most Pi devices. One could remove those “other jobs” and run RISC OS, of course, putting the learner in an unfamiliar and more challenging environment, perhaps giving them another computer to use at the same time to look things up on the Internet. Or one could adopt a different software architecture, but that would involve an investment in software that few organisations can be bothered to make.
I don’t know whether the University of Cambridge has seen better-educated applicants in recent years as a result of Pi proliferation, or whether today’s applicants are as similarly perplexed by low-level concepts as those from the pre-Pi era. But then, there might be a lesson to be learned about applying some rigour to technological interventions in society. After all, there were some who justifiably questioned the effectiveness of rolling out microcomputers in schools, particularly when teachers have never really been supported in their work, as more and more is asked of them by their political overlords. Investment in people and their well-being is another thing that few organisations can be bothered to make, too.
Dual Screen CI20
December 15th, 2024
Following on from yesterday’s post, where a small display was driven over SPI from the MIPS Creator CI20, it made sense to exercise the HDMI output again. With a few small fixes to the configuration files, demonstrating that the HDMI output still worked, I suppose one thing just had to be done: to drive both displays at the same time.

The MIPS Creator CI20 driving an SPI display and a monitor via HDMI.
Thus, two separate instances of the spectrum example, each utilising their own framebuffer, potentially multiplexed with other programs (but not actually done here), are displayed on their own screen. All it required was a configuration that started all the right programs and wired them up.
Again, we may contemplate what the CI20 was probably supposed to be: some kind of set-top box providing access to media files stored on memory cards or flash memory, possibly even downloaded from the Internet. On such a device, developed further into a product, there might well have been a front panel display indicating the status of the device, the current media file details, or just something as simple as the time and date.
Here, an LCD is used and not in any sensible orientation for use in such a product, either. We would want to use some kind of right-angle connector to make it face towards the viewer. Once upon a time, vacuum fluorescent displays were common for such applications, but I could imagine a simple, backlit, low-resolution monochrome LCD being an alternative now, maybe with RGB backlighting to suit the user’s preferences.
Then again, for prototyping, a bright LCD like this, decadent though it may seem, somehow manages to be cheaper than much simpler backlit, character matrix displays. And I also wonder how many people ever attached two displays to their CI20.
Testing Newer Work on Older Boards
December 14th, 2024
Since I’ve been doing some housekeeping in my low-level development efforts, I had to get the MIPS Creator CI20 out and make sure I hadn’t broken too much, also checking that the newer enhancements could be readily ported to the CI20’s pinout and peripherals. It turns out that the Pimoroni Pirate Audio speaker board works just fine on the primary expansion header, at least to use the screen, and doesn’t need the backlight pin connected, either.

The Pirate Audio speaker hat on the MIPS Creator CI20.
Of course, the CI20 was designed to be pinout-compatible with the original Raspberry Pi, which had a 26-pin expansion header. This was replaced by a 40-pin header in subsequent Raspberry Pi models, presumably wrongfooting various suppliers of accessories, but the real difficulties will have been experienced by those with these older boards, needing to worry about whether newer, 40-pin “hat” accessories could be adapted.
To access the Pirate Audio hat’s audio support, some additional wiring would, in principle, be necessary, but the CI20 doesn’t expose I2S functionality via its headers. (The CI20 has a more ambitious audio architecture involving a codec built into the JZ4780 SoC and a wireless chip capable of Bluetooth audio, not that I’ve ever exercised this even under Linux.) So, this demonstration is about as far as we can sensibly get with the CI20. I also tested the Waveshare panel and it seemed to work, too. More testing remains, of course!
A Small Update
December 6th, 2024
Following swiftly on from my last article, I decided to take the opportunity to extend my framebuffer components to support an interface utilised by the L4Re framework’s Mag component, which is a display multiplexer providing a kind of multiple window environment. I’m not sure if Mag is really supported any more, but it provided the basis of a number of L4Re examples for a while, and I brought it into use for my own demonstrations.
Eventually, having needed to remind myself of some of the details of my own software, I managed to deploy the collection of components required, each with their own specialised task, but most pertinently a SoC-specific SPI driver and a newly extended display-specific framebuffer driver. The framebuffer driver could now be connected directly to Mag in the Lua-based coordination script used by the Ned initialisation program, which starts up programs within L4Re, and Mag could now request a region of memory from the framebuffer driver for further use by other programs.
All of this extra effort merely provided another way of delivering a familiar demonstration, that being the colourful, mesmerising spectrum example once provided as part of the L4Re software distribution. This example also uses the programming interface mentioned above to request a framebuffer from Mag. It then plots its colourful output into this framebuffer.
The result is familiar from earlier articles:

The spectrum example on a screen driven by the ILI9486 controller.
The significant difference, however, is that underneath the application programs, a combination of interchangeable components provides the necessary adaptation to the combination of hardware devices involved. And the framebuffer component can now completely replace the fb-drv component that was also part of the L4Re distribution, thereby eliminating a dependency on a rather cumbersome and presumably obsolete piece of software.
Recent Progress
December 2nd, 2024
The last few months have not always been entirely conducive to making significant progress with various projects, particularly my ongoing investigations and experiments with L4Re, but I did manage to reacquaint myself with my previous efforts sufficiently to finally make some headway in November. This article tries to retrieve some of the more significant accomplishments, modest as they might be, to give an impression of how such work is undertaken.
Previously, I had managed to get my software to do somewhat useful things on MIPS-based single-board computer hardware, showing graphical content on a small screen. Various problems had arisen with regard to one revision of a single-board computer for which the screen was originally intended, causing me to shift my focus to more general system functionality within L4Re. With the arrival of the next revision of the board, I leveraged this general functionality, combining it with support for memory cards, to get my minimalist system to operate on the board itself. I rather surprised myself getting this working, it must be said.
Returning to the activity at the start of November, there were still some matters to be resolved. In parallel to my efforts with L4Re, I had been trying to troubleshoot the board’s operation under Linux. Linux is, in general, a topic upon which I do not wish to waste my words. However, with the newer board revision, I had also acquired another, larger, screen and had been investigating its operation, and there were performance-related issues experienced under Linux that needed to be verified under other conditions. This is where a separate software environment can be very useful.
Plugging a Leak
Before turning my attention to the larger screen, I had been running a form of stress test with the smaller screen, updating it intensively while also performing read operations from the memory card. What this demonstrated was that there were no obvious bandwidth issues with regard to data transfers occurring concurrently. Translating this discovery back to Linux remains an ongoing exercise, unfortunately. But another problem arose within my own software environment: after a while, the filesystem server would run out of memory. I felt that this problem now needed to be confronted.
Since I tend to make such problems for myself, I suspected a memory leak in some of my code, despite trying to be methodical in the way that allocated objects are handled. I considered various tools that might localise this particular leak, with AddressSanitizer and LeakSanitizer being potentially useful, merely requiring recompilation and being available for a wide selection of architectures as part of GCC. I also sought to demonstrate the problem in a virtual environment, this simply involving appropriate test programs running under QEMU. Unfortunately, the sanitizer functionality could not be linked into my binaries, at least with the Debian toolchains that I am using.
Eventually, I resolved to use simpler techniques. Wondering if the memory allocator might be fragmenting memory, I introduced a call to malloc_stats, just to get an impression of the state of the heap. After failing to gain much insight into the problem, I rolled up my sleeves and decided to just look through my code for anything I might have done with regard to allocating memory, just to see if I had overlooked anything as I sought to assemble a working system from its numerous pieces.
Sure enough, I had introduced an allocation for “convenience” in one kind of object, making a pool of memory available to that object if no specific pool had been presented to it. The memory pool itself would release its own memory upon disposal, but in focusing on getting everything working, I had neglected to introduce the corresponding top-level disposal operation. With this remedied, my stress test was now able to run seemingly indefinitely.
Separating Displays and Devices
I would return to my generic system support later, but the need to exercise the larger screen led me to consider the way I had previously introduced support for screens and displays. The smaller screen employs SPI as the communications mechanism between the SoC and the display controller, as does the larger screen, and I had implemented support for the smaller screen as a library combining the necessary initialisation and pixel data transfer code with code that would directly access the SPI peripheral using a SoC-specific library.
Clearly, this functionality needed to be separated into two distinct parts: the code retaining the details of initialising and operating the display via its controller, and the code performing the SPI communication for a specific SoC. Not doing this could require us to needlessly build multiple variants of the display driver for different SoCs or platforms, when in principle we should only need one display driver with knowledge of the controller and its peculiarities, this then being combined using interprocess communication with a single, SoC-specific driver for the communications.
A few years ago now, I had in fact implemented a “server” in L4Re to perform short SPI transfers on the Ben NanoNote, this to control the display backlight. It became appropriate to enhance this functionality to allow programs to make longer transfers using data held in shared memory, all of this occurring without those programs having privileged access to the underlying SPI peripheral in the SoC. Alongside the SPI server appropriate for the Ben NanoNote’s SoC, servers would be built for other SoCs, and only the appropriate one would be started on a given hardware device. This would then mediate access to the SPI peripheral, accepting requests from client programs within the established L4Re software architecture.
One important element in the enhanced SPI server functionality is the provision of shared memory that can be used for DMA transfers. Fortunately, this is mostly a matter of using the appropriate settings when requesting memory within L4Re, even though the mechanism has been made somewhat more complicated in recent times. It was also fortunate that I previously needed to consider such matters when implementing memory card support, saving me time in considering them now. The result is that a client program should be able to write into a memory region and the SPI server should be able to send the written data directly to the display controller without any need for additional copying.
Complementing the enhanced SPI servers are framebuffer components that use these servers to configure each kind of display, each providing an interface to their own client programs which, in turn, access the display and provide visual content. The smaller screen uses an ST7789 controller and is therefore supported by one kind of framebuffer component, whereas the larger screen uses an ILI9486 controller and has its own kind of component. In principle, the display controller support could be organised so that common code is reused and that support for additional controllers would only need specialisations to that generic code. Both of these controllers seem to implement the MIPI DBI specifications.
The particular display board housing the larger screen presented some additional difficulties, being very peculiarly designed to present what would seem to be an SPI interface to the hardware interfacing to the board, but where the ILI9486 controller’s parallel interface is apparently used on the board itself, with some shift registers and logic faking the serial interface to the outside world. This complicates the communications, requiring 16-bit values to be sent where 8-bit values would be used in genuine SPI command traffic.
The motivation for this weird design is presumably that of squeezing a little extra performance out of the controller that is only available when transferring pixel data via the parallel interface, especially desired by those making low-cost retrogaming systems with the Raspberry Pi. Various additional tweaks were needed to make the ILI9486 happy, such as an explicit reset pulse, with this being incorporated into my simplistic display component framework. Much more work is required in this area, and I hope to contemplate such matters in the not-too-distant future.
Discoveries and Remedies
Further testing brought some other issues to the fore. With one of the single-board computers, I had been using a microSD card with a capacity of about half a gigabyte, which would make it a traditional SD or SDSC (standard capacity) card, at least according to the broader SD card specifications. With another board, I had been using a card with a sixteen gigabyte capacity or thereabouts, aligning it with the SDHC (high capacity) format.
Starting to exercise my code a bit more on this larger card exposed memory mapping issues when accessing the card as a single region: on the 32-bit MIPS architecture used by the SoC, a pointer simply cannot address this entire region, and thus some pointer arithmetic occurred that had undesirable consequences. Constraining the size of mapped regions seemed like the easiest way of fixing this problem, at least for now.
More sustained testing revealed a couple of concurrency issues. One involved a path of invocation via a method testing for access to filesystem objects where I had overlooked that the method, deliberately omitting usage of a mutex, could be called from another component and thus circumvent the concurrency measures already in place. I may well have refactored components at some point, forgetting about this particular possibility.
Another issue was an oversight in the way an object providing access to file content releases its memory pages for other objects to use before terminating, part of the demand paging framework that has been developed. I had managed to overlook a window between two operations where an object seeking to acquire a page from the terminating object might obtain exclusive access to a page, but upon attempting to notify the terminating object, find that it has since been deallocated. This caused memory access errors.
Strangely, I had previously noticed one side of this potential situation in the terminating object, even writing up some commentary in the code, but I had failed to consider the other side of it lurking between those two operations. Building in the missing support involved getting the terminating object to wait for its counterparts, so that they may notify it about pages they were in the process of removing from its control. Hopefully, this resolves the problem, but perhaps the lesson is that if something anomalous is occurring, exhibiting certain unexpected effects, the cause should not be ignored or assumed to be harmless.
All of this proves to be quite demanding work, having to consider many aspects of a system at a variety of levels and across a breadth of components. Nevertheless, modest progress continues to be made, even if it is entirely on my own initiative. Hopefully, it remains of interest to a few of my readers, too.
Configuring a Program’s Environment
September 6th, 2024
Although there isn’t much to report of late, I thought that it might be appropriate to note a few small developments in my efforts related to L4Re. With travel, distractions, and various irritations intervening, only slow, steady progress was made during August.
Previously, I published a rather long article about operating systems and application environments, but this was not written spontaneously. In fact, it attempts to summarise various perspectives on such topics from the last fifty or so years, discovered as I reviewed the rather plentiful literature that is now readily accessible online. Alongside the distraction of reading historical documents, I had been slowly developing support for running programs in my L4Re-based environment, gradually bringing it to a point where I might be able to explore some more interesting topics.
One topic that overlapped with my last article and various conference talks was that of customising the view of the system a given program might have when it is run. Previous efforts had allowed me to demonstrate programs running and interacting with a filesystem, even one stored on a device such as a microSD card and accessed by hardware booting into L4Re, as opposed to residing in some memory in a QEMU virtual machine. And these programs were themselves granted the privilege of running their own programs. However, all of these programs resided in the same filesystem and also accessed this same filesystem.
Distinct Program Filesystems
What I wanted to do was to allow programs to see a different, customised filesystem instead of the main filesystem. Fortunately, my component architecture largely supported such a plan. When programs are invoked, the process server component supplies a filesystem reference to the newly invoked program, this reference having been the same one that the process server uses itself. To allow the program to see a different filesystem, all that is required is a reference to another filesystem be supplied.
So, the ability is required to configure the process server to utilise a distinct filesystem for invoked programs. After enhancing the process server to propagate a distinct filesystem to created processes, I updated its configuration in the Lua script within L4Re as follows:
l:startv({
caps = {
fsserver = ext2server_paulb, -- this is the filesystem the server uses itself
pipeserver = pipe_server,
prfsserver = ext2server_nested_paulb, -- this is the distinct filesystem for programs
prserver = process_server:svr(),
},
log = { "process", "y" },
},
"rom/process_server", "bin/exec_region_mapper", "prfsserver");
Now, the process server obtains the program or process filesystem from the “prfsserver” capability defined in its environment. This capability or reference can be supplied to each new process created when invoking a program.
Nesting Filesystems
Of course, testing this requires a separate filesystem image to be created and somehow supplied during the initialisation of the system. When prototyping using QEMU on a machine with substantial quantities of memory, it is convenient to just bundle such images up in the payload that is deployed within QEMU, these being exposed as files in a “rom” filesystem by the core L4Re components.
But on “real hardware”, it isn’t necessarily convenient to have separate partitions on a storage device for lots of different filesystems. Instead, we might wish to host filesystem images within the main filesystem, accessing these in a fashion similar to using the loop option with the mount command on Unix-like systems. As in, something like this, mounting “filesystem.fs” at the indicated “mountpoint” location:
mount -o loop filesystem.fs mountpoint
This led to me implementing support for accessing a filesystem stored in a file within a filesystem. In the L4Re build system, my software constructs filesystem images using a simple tool that utilises libext2fs to create an ext2-based filesystem. So, I might have a directory called “docs” containing some documents that is then packed up into a filesystem image called “docs.fs”.
This image might then be placed in a directory that, amongst other content, is packed up into the main filesystem image deployed in the QEMU payload. On “real hardware”, I could take advantage of an existing filesystem on a memory card, copying content there instead of creating an image for the main filesystem. But regardless of the approach, the result would be something like this:
> ls fs fs drwxrwxrwx- 1000 1000 1024 2 . drwxr-xr-x- 0 0 1024 7 .. -rw-r--r--- 1000 1000 102400 1 docs.fs
Here, “docs.fs” resides inside the “fs” directory provided by the main filesystem.
Files Providing Filesystems
With this embedded filesystem now made available, the matter of providing support for programs to access it largely involved the introduction of a new component acting as a block device. But instead of accessing something like a memory card (or an approximation of one for the purposes of prototyping), this block server accesses a file containing an embedded filesystem though an appropriate filesystem “client” programming interface. Here is the block server being started in the Lua script:
l:startv({
caps = {
blockserver = client_server:svr(),
fsserver = ext2server_paulb,
},
log = { "clntsvr", "y" },
},
-- program, block server capability to provide, memory pages
"rom/client_server", "blockserver", "10");
Then, a filesystem server is configured using the block server defined above, obtaining the nested filesystem from “fs/docs.fs” in the main filesystem to use as its block storage medium:
l:startv({
caps = {
blockserver = client_server,
fsserver = ext2server_nested:svr(),
pipeserver = pipe_server,
},
log = { "ext2svrN", "y" },
},
-- program, server capability, memory pages, filesystem capability to provide
"rom/ext2_server", "blockserver", "fs/docs.fs", "20", "fsserver");
Then, this filesystem server, utilising libext2fs coupled with a driver for a block device, can operate on the filesystem oblivious to what is providing it, which is another component that itself uses libext2fs! Thus, a chain of components can be employed to provide access to files within filesystems, themselves provided by files within other filesystems, and so on, eventually accessing blocks in some kind of storage device. Here, we will satisfy ourselves with just a single level of filesystems within files, however.
So, with the ability to choose a filesystem for new programs and with the ability to acquire a filesystem from the surrounding, main filesystem, it became possible to run a program that now sees a distinct filesystem. For example:
> run bin/ls drwxr-xr-x- 0 0 1024 4 . drwxr-xr-x- 0 0 1024 4 .. drwx------- 0 0 12288 2 lost+found drwxrwxrwx- 1000 1000 1024 2 docs [0] Completed with signal 0 value 0
Although a program only sees its own filesystem, it can itself run another program provided from outside. For example, getting “test_systemv” to run “cat”:
> run bin/test_systemv bin/cat docs/COPYING.txt Running: bin/cat Licence Agreement ----------------- All original work in this distribution is covered by the following copyright and licensing information:
Now, this seems counterintuitive. How does the program invoked from the simple shell environment, “test_systemv”, manage to invoke a program from a directory, “bin”, that is not visible and presumably not accessible to it? This can be explained by the process server. Since the invoked programs are also given a reference to the process server, this letting them start other programs, and since the process server is able to locate programs independently, the invoked programs may supply a program path that may not be accessible to them, but it may be accessible to the process server.
The result is like having some kind of “shadow” filesystem. Programs may be provided by this filesystem and run, but in this arrangement, they may only operate on a distinct filesystem where themselves and other programs may not even be present. Conversely, even if programs are provided in the filesystem visible to a program, they may not be run because the process server may not have access to them. If we wanted to provide an indication of the available programs, we might provide a “bin” directory in each program’s visible filesystem containing files with the names of the available programs, but these files would not need to be the actual programs and “running” them would not actually be running them at all: the shadow filesystem programs would be run instead.
Such trickery is not mandatory, of course. The same filesystem can be visible to programs and the process server that invoked them. But this kind of filesystem shadowing does open up some possibilities that would not normally be available in a conventional environment. Certainly, I imagine that such support could be introduced to everybody’s own favourite operating system, too, but the attraction here is that such experimentation comes at a relatively low level of effort. Moreover, I am not making anyone uncomfortable modifying another system, treading on people’s toes, theatening anyone’s position in the social hierarchy, and generally getting them on the defensive, inviting the inevitable, disrespectful question: “What is it you are trying to do?”
As I noted last time, there isn’t a singular objective here. Instead, the aim is to provide the basis for multiple outcomes, hopefully informative and useful ones. So, in keeping with that agenda, I hope that this update was worth reading.
Reformulating the Operating System
July 27th, 2024
As noted previously, two of my interests in recent times have been computing history and microkernel-based operating systems. Having perused academic and commercial literature in the computing field a fair amount over the last few years, I experienced some feelings of familiarity when looking at the schedule for FOSDEM, which took place earlier in the year, brought about when encountering a talk in the “microkernel and component-based OS” developer room: “A microkernel-based orchestrator for distributed Internet services?”
In this talk’s abstract, mentions of the complexity of current Linux-based container solutions led me to consider the role of containers and virtual machines. In doing so, it brought back a recollection of a paper published in 1996, “Microkernels Meet Recursive Virtual Machines”, describing a microkernel-based system architecture called Fluke. When that paper was published, I was just starting out in my career and preoccupied with other things. It was only in pursuing those interests of mine that it came to my attention more recently.
It turned out that there were others at FOSDEM with similar concerns. Liam Proven, who regularly writes about computing history and alternative operating systems, gave a talk, “One way forward: finding a path to what comes after Unix”, that combined observations about the state of the computing industry, the evolution of Unix, and the possibilities of revisiting systems such as Plan 9 to better inform current and future development paths. This talk has since been summarised in four articles, concluding with “A path out of bloat: A Linux built for VMs” that links back to the earlier parts.
Both of these talks noted that in attempting to deploy applications and services, typically for Internet use, practitioners are now having to put down new layers of functionality to mitigate or work around limitations in existing layers. In other words, they start out with an operating system, typically based on Linux, that provides a range of features including support for multiple users and the ability to run software in an environment largely confined to the purview of each user, but end up discarding most of this built-in support as they bundle up their software within such things as containers or virtual machines, where the software can pretend that it has access to a complete environment, often running under the control of one or more specific user identities within that environment.
With all this going on, people should be questioning why they need to put one bundle of software (their applications) inside another substantial bundle of software (an operating system running in a container or virtual machine), only to deploy that inside yet another substantial bundle of software (an operating system running on actual hardware). Computing resources may be the cheapest they have ever been, supply chain fluctuations notwithstanding, but there are plenty of other concerns about building up levels of complexity in systems that should prevent us from using cheap computing as an excuse for business as usual.
A Quick Historical Review
In the early years of electronic computing, each machine would be dedicated to running a single program uninterrupted until completion, producing its results and then being set up for the execution of a new program. In this era, one could presumably regard a computer simply as the means to perform a given computation, hence the name.
However, as technology progressed, it became apparent that dedicating a machine to a single program in this way utilised computing resources inefficiently. When programs needed to access relatively slow peripheral devices such as reading data from, or writing data to, storage devices, the instruction processing unit would be left idle for significant amounts of cumulative time. Thus, solutions were developed to allow multiple programs to reside in the machine at the same time. If a running program had paused to allow data to transferred to or from storage, another program might have been given a chance to run until it also found itself needing to wait for those peripherals.
In such systems, each program can no longer truly consider itself as the sole occupant or user of the machine. However, there is an attraction in allowing programs to be written in such a way that they might be able to ignore or overlook this need to share a computer with other programs. Thus, the notion of a more abstract computing environment begins to take shape: a program may believe that it is accessing a particular device, but the underlying machine operating software might direct the program’s requests to a device of its own choosing, presenting an illusion to the program.
Although these large, expensive computer systems then evolved to provide “multiprogramming” support, multitasking, virtual memory, and virtual machine environments, it is worth recalling the evolution of computers at the other end of the price and size scale, starting with the emergence of microcomputers from the 1970s onwards. Constrained by the availability of affordable semiconductor components, these small systems at first tended to limit themselves to modest computational activities, running one program at a time, perhaps punctuated occasionally by interrupts allowing the machine operating software to update the display or perform other housekeeping tasks.
As microcomputers became more sophisticated, so expectations of the functionality they might deliver also became more sophisticated. Users of many of the earlier microcomputers might have run one application or environment at a time, such as a BASIC interpreter, a game, or a word processor, and what passed for an operating system would often only really permit a single application to be active at once. A notable exception in the early 1980s was Microware’s OS-9, which sought to replicate the Unix environment within the confines of 8-bit microcomputer architecture, later ported to the Motorola 68000 and used in, amongst other things, Philips’ CD-i players.
OS-9 offered the promise of something like Unix on fairly affordable hardware, but users of systems with more pedestrian software also started to see the need for capabilities like multitasking. Even though the dominant model of microcomputing, perpetuated by the likes of MS-DOS, had involved running one application to do something, then exiting that application and running another, it quickly became apparent that users themselves had multitasking impulses and were inconvenienced by having to finish off something, even temporarily, switch to another application offering different facilities, and then switch back again to resume their work.
Thus, the TSR and the desk accessory were born, even finding a place on systems like the Apple Macintosh, whose user interface gave the impression of multitasking functionality and allowed switching between applications, even though only a single application could, in general, run at a time. Later, Apple introduced MultiFinder with the more limited cooperative flavour of multitasking, in contrast to systems already offering preemptive multitasking of applications in their graphical environments. People may feel the compulsion to mention the Commodore Amiga in such contexts, but a slightly more familiar system from a modern perspective would be the Torch Triple X workstation with its OpenTop graphical environment running on top of Unix.
The Language System Phenomenon
And so, the upper and lower ends of the computing market converged on expectations that users might be able to run many programs at a time within their computers. But the character of these expectations might have been coloured differently from the prior experiences of each group. Traditional computer users might well have framed the environment of their programs in terms of earlier machines and environments, regarding multitasking as a convenience but valuing compatibility above all else.
At the lower end of the market, however, users were looking to embrace higher-level languages such as Pascal and Modula-2, these being cumbersome on early microprocessor systems but gradually becoming more accessible with the introduction of later systems with more memory, disk storage and processors more amenable to running such languages. Indeed, the notion of the language environment emerged, such as UCSD Pascal, accompanied by the portable code environment, such as the p-System hosting the UCSD Pascal environment, emphasising portability and defining a machine detached from the underlying hardware implementation.
Although the p-System could host other languages, it became closely associated with Pascal, largely by being the means through which Pascal could be propagated to different computer systems. While 8-bit microcomputers like the BBC Micro struggled with something as sophisticated as the p-System, even when enhanced with a second processor and more memory, more powerful machines could more readily bear the weight of the p-System, even prompting some to suggest at one time that it was “becoming the de facto standard operating system on the 68000”, supplied as standard on 68000-based machines like the Sage II and Sage IV.
Such language environments became prominent for a while, Lisp and Smalltalk being particularly fashionable, and with the emergence of the workstation concept, new and divergent paths were forged for a while. Liam Proven previously presented Wirth’s Oberon system as an example of a concise, efficient, coherent environment that might still inform the technological direction we might wish to take today. Although potentially liberating, such environments were also constraining in that their technological homogeneity – the imposition of a particular language or runtime – tended to exclude applications that users might have wanted to run. And although Pascal, Oberon, Lisp or Smalltalk might have their adherents, they do not all appeal to everyone.
Indeed, during the 1980s and even today, applications sell systems. There are plenty of cases where manufacturers ploughed their own furrow, believing that customers would see the merits in their particular set of technologies and be persuaded into adopting those instead of deploying the products they had in mind, only to see the customers choose platforms that supported the products and technologies that they really wanted. Sometimes, vendors doubled down on customisations to their platforms, touting the benefits of custom microcode to run particular programs or environments, ignoring that customers often wanted more generally useful solutions, not specialised products that would become uncompetitive and obsolete as technology more broadly progressed.
For all their elegance, language-oriented environments risked becoming isolated enclaves appealing only to their existing users: an audience who might forgive and even defend the deficiencies of their chosen systems. For example, image-based persistence, where software could be developed in a live environment and “persisted” or captured in an image or “world” for later use or deployment, remains a tantalising approach to software development that sometimes appeals to outsiders, but one can argue that it also brings risks in terms of reproducibility around software development and deployment.
If this sounds familiar to anyone old enough to remember the end of the 1990s and the early years of this century, probing this familiarity may bring to mind the Java bandwagon that rolled across the industry. This caused companies to revamp their product lines, researchers to shelve their existing projects, developers to encounter hostility towards the dependable technologies they were already using, and users to suffer the mediocre applications and user interfaces that all of this upheaval brought with it.
Interesting research, such as that around Fluke and similar projects, was seemingly deprioritised in favour of efforts that presumably attempted to demonstrate “research relevance” in the face of this emerging, everything-in-Java paradigm with its “religious overtones”. And yet, commercial application of supposedly viable “pure Java” environments struggled in the face of abysmal performance and usability.
The Nature of the Machine
Users do apparently value heterogeneity or diversity in their computing environments, to be able to mix and match their chosen applications, components and technologies. Today’s mass-market computers may have evolved from the microcomputers of earlier times, accumulating workstation, minicomputer and mainframe technologies along the way, and they may have incorporated largely sensible solutions in doing so, but it can still be worthwhile reviewing how high-end systems of earlier times addressed issues of deploying different kinds of functionality safely within the same system.
When “multiprogramming” became an essential part of most system vendors’ portfolios, the notion of a “virtual machine” emerged, this being the vehicle through which a user’s programs could operate or experience the machine while sharing it with other programs. Today, using our minicomputer or Unix-inspired operating systems, we think of a virtual machine as something rather substantial, potentially simulating an entire system with all its peculiarities, but other interpretations of the term were once in common circulation.
In the era when the mainframe reigned supreme, their vendors differed in their definitions of a virtual machine. International Computers Limited (ICL) revamped their product range in the 1970s in an attempt to compete with IBM, introducing their VME or Virtual Machine Environment operating system to run on their 2900 series computers. Perusing the literature related to VME reveals a system that emphasises different concepts to those we might recognise from Unix, even though there are also many similarities that are perhaps obscured by differences in terminology. Where we are able to contrast the different worlds of VME and Unix, however, is in the way that ICL chose to provide a Unix environment for VME.
As the end of the 1980s approached, once dominant suppliers with their closed software and solution ecosystems started to get awkward questions about Unix and “open systems”. The less well-advised, like Norway’s rising star, Norsk Data, refused to seriously engage with such trends, believing their own mythology of technological superiority, until it was too late to convince their customers switching to other platforms that they had suddenly realised that this Unix thing was worthwhile after all. ICL, meanwhile, only tentatively delivered a Unix solution for their top-of-the-line systems.
Six years after ICL’s Series 39 mainframe range was released, and after years of making a prior solution selectively available, ICL’s VME/X product was delivered, offering a hosted Unix environment within VME, broadly comparable with Amdahl’s UTS and IBM’s IX/370. Eventually, VME/X was rolled into OpenVME, acknowledging “open systems” rather like Digital’s OpenVMS, all without actually being open, as one of my fellow students once joked. Nevertheless, VME/X offers an insight into what a virtual machine is in VME and how ICL managed to map Unix concepts into VME.
Reading VME documentation, one gets the impression that, fundamentally, a virtual machine in the VME sense is really about giving an environment to a particular user, as opposed to a particular program. Each environment has its own private memory regions, inaccessible to other virtual machines, along with other regions that may be shared between virtual machines. Within each environment, a number of processes can be present, but unlike Unix processes, these are simply execution contexts or, in Unix and more general terms, threads.
Since the process is the principal abstraction in Unix through which memory is partitioned, it is curious that in VME/X, the choice was made to not map Unix processes to VME virtual machines. Instead, each “terminal user”, each “batch job” (not exactly a Unix concept), as well as “certain daemons” were given their own virtual machines. And when creating a new Unix process, instead of creating a new virtual machine, VME/X would in general create a new VME process, seemingly allowing each user’s processes to reside within the same environment and to potentially access each other’s memory. Only when privilege or user considerations applied, would a new process be initiated in a new virtual machine.
Stranger than this, however, is VME’s apparent inability to run multiple processes concurrently within the same virtual machine, even on multiprocessor systems, although processes in different virtual machines could run concurrently. For one process to suspend execution and yield to another in the same virtual machine, a special “process-switching call” instruction was apparently needed, providing a mechanism like that of green threads or fibers in other systems. However, I could imagine that this could have provided a mechanism for concealing each process’s memory regions from others by using this call to initiate a reconfiguration of the memory segments available in the virtual machine.
I have not studied earlier ICL systems, but it would not surprise me if the limitations of this environment resembled those of earlier generations of products, where programs might have needed to share a physical machine graciously. Thus, the heritage of the system and the expectations of its users from earlier times appear to have survived to influence the capabilities of this particular system. Yet, this Unix implementation was actually certified as compliant with the X/Open Portability Guide specifications, initially XPG3, and was apparently the first system to have XPG4 base compliance.
Partitioning by User
A tour of a system that might seem alien or archaic to some might seem self-indulgent, but it raises a few useful thoughts about how systems may be partitioned and the sophistication of such partitioning. For instance, VME seems to have emphasised partitioning by user, and this approach is a familiar and mature one with Unix systems, too. Traditionally, dedicated user accounts have been set up to run collections of associated programs. Web servers often tend to run in a dedicated account, typically named “apache” or “httpd”. Mail servers and database servers also tend to follow such conventions. Even Android has used distinct user accounts to isolate applications from each other.
Of course, when partitioning functionality by user in Unix systems, one must remember that all of the processes involved are isolated from each other, in that they do not share memory inadvertently, and that the user identity involved is merely associated with these processes: it does not provide a container for them in its own right. Indeed, the user abstraction is simply the way that access by these processes to the rest of the system is controlled, largely mediated by the filesystem. Thus, any such partitioning arrangement brings the permissions and access control mechanisms into consideration.
In the simplest cases, such as a Web server needing to be able to read some files, the necessary adjustments to groups or even the introduction of access control lists can be sufficient to confine the Web server to its own territory while allowing other users and programs to interact with it conveniently. For example, Web pages can be published and updated by adding, removing and changing files in the Web site directories given appropriate permissions. However, it is when considering the combination of servers or services, each traditionally operating under their own account, that administrators start to consider alternatives to such traditional approaches.
Let us consider how we might deploy multiple Web applications in a shared hosting environment. Clearly, it would be desirable to give all of these applications distinct user accounts so that they would not be able to interfere with each other’s files. In a traditional shared hosting environment, the Web application software itself might be provided centrally, with all instances of an application relying on the same particular version of the software. But as soon as the requirements for the different instances start to diverge – requiring newer or older versions of various components – they become unable to rely entirely on the centrally provided software, and alternative mechanisms for deploying divergent components need to be introduced.
To a customer of such a service having divergent requirements, the provider will suggest various recipes for installing new software, often involving language-specific packaging or building from source, with compilers available to help out. The packaging system of the underlying software distribution is then mostly being used by the provider itself to keep the operating system and core facilities updated. This then leads people to conclude that distribution packaging is too inflexible, and this conclusion has led people in numerous directions to try and address the apparently unmet needs of the market, as well as to try and pitch their own particular technology as the industry’s latest silver bullet.
There is arguably nothing to stop anyone deploying applications inside a user’s home directory or a subdirectory of the home directory, with /home/user/etc being the place where common configuration files are stored, /home/user/var being used for some kind of coordination, and so on. Many applications can be configured to work in another location. One problem is that this configuration is sometimes fixed within the software when it is built, meaning that generic packages cannot be produced and deployed in arbitrary locations.
Another is that many of the administrative mechanisms in Unix-like systems favour the superuser, rely on operating on software configured for specific, centralised locations, and only really work at the whole-machine level with a global process table, a global set of user identities, and so on. Although some tools support user-level activities, like the traditional cron utility, scheduling jobs on behalf of users, as far as I know, traditional Unix-like systems have never really let users define and run their own services along the same lines as is done for the whole system, administered by the superuser.
Partitioning by Container
If one still wants to use nicely distribution-packaged software on a per-user, per-customer or per-application basis, what tends to happen is that an environment is constructed that resembles the full machine environment, with this kind of environment existing in potentially many instances on the same system. In other words, just so that, say, a Debian package can be installed independently of the host system and any of its other users, an environment is constructed that provides directories like /usr, /var, /etc, and so on, allowing the packaging system to do its work and to provide the illusion of a complete, autonomous machine.
Within what might be called the Unix traditions, a few approaches exist to provide this illusion to a greater or lesser degree. The chroot mechanism, for instance, permits the execution of programs that are generally only able to see a section of the complete filesystem on a machine, located at a “changed root” in the full filesystem. By populating this part of the filesystem with files that would normally be found at the top level or root of the normal filesystem, programs invoked via the chroot mechanism are able to reference these files as if they were in their normal places.
Various limitations in the scope of chroot led to the development of such technologies as jails, Linux-VServer and numerous others, going beyond filesystem support for isolating processes, and providing a more comprehensive illusion of a distinct machine. Here, systems like Plan 9 showed how the Unix tradition might have evolved to support such needs, with Linux and other systems borrowing ideas such as namespaces and applying them in various, sometimes clumsy, ways to support the configuration of program execution environments.
Going further, technologies exist to practically simulate the experience of an entirely separate machine, these often bearing the “virtual machine” label in the vocabulary of our current era. A prime example of such a technology is KVM, available on Linux with the right kind of processor, which allows entire operating systems to run within another. Using a virtual machine solution of this nature is something of a luxury option for an application needing its own environment, being able to have precisely the software configuration of its choosing right down to the level of the kernel. One disadvantage of such full-fat virtual machines is the amount of extra software involved and those layers upon layers of programs and mechanisms, all requiring management and integration.
Some might argue for solutions where the host environment does very little and where everything of substance is done in one kind of virtual machine or other. But if all the virtual machines are being used to run the same general technology, such as flavours of Linux, one has to wonder whether it is worth keeping a distinct hypervisor technology around. That might explain the emergence of KVM as an attempt to have Linux act as a kind of hypervisor platform, but it does not excuse a situation where the hosting of entire systems is done in preference to having a more configurable way of deploying applications within Linux itself.
Some adherents of hypervisor technologies advocate the use of unikernels as a way of deploying lightweight systems on top of hypervisors, specialised to particular applications. Such approaches seem reminiscent of embedded application deployment, with entire systems being built and tuned for precisely one job: useful for some domains but not generally applicable or particularly flexible. And it all feels like the operating system is just being reinvented in a suboptimal, ad-hoc fashion. (Unikernels seem to feature prominently in the “microkernel and component-based OS” developer room at FOSDEM these days.)
Then there is the approach advocated in Liam Proven’s talk, of stripping down an operating system for hypervisor deployment, which would need to offer a degree of extra flexibility to be more viable than a unikernel approach, at least when applied to the same kinds of problems. Of course, this pushes hardware support out of the operating system and into the realm of the hypervisor, which could be beneficial if done well, or it could imperil support for numerous hardware platforms and devices due to numerous technological, economic and social reasons. Liam advocates pushing filesystem support out of the kernel, and potentially out of the operating system as well, although it is not clear what would then need to take up that burden and actually offer filesystem facilities.
Some Reflections
This is where we may return to those complaints about the complexity of modern hosting frameworks. That a need for total flexibility in every application’s software stack presents significant administrative challenges. But in considering the nature of the virtual machine in its historical forms, we might re-evaluate what kind of environment software really needs.
In my university studies, a project of mine investigated a relatively hot topic at the time: mobile software agents. One conclusion I drew from the effort was that programs could be written to use a set of well-defined interfaces and to potentially cooperate with other programs, without thousands of operating system files littering their shared environment. Naturally, such programs would not be running by magic: they would need to be supported by infrastructure that allows them to be loaded and executed, but all of this infrastructure can be maintained outside the environment seen by these programs.
At the time, I relied upon the Python language runtime for my agent programs with its promising but eventually inadequate support for safe execution to prevent programs from seeing the external machine environment. Most agent frameworks during this era were based on particular language technologies, and the emergence of Java only intensified the industry’s focus on this kind of approach, naturally emphasising Java, although Inferno also arrived at around this time and offered a promising, somewhat broader foundation for such work than the Java Virtual Machine.
In the third part of his article series, Liam Proven notes that Plan 9, Inferno’s predecessor, is able to provide a system where “every process is in a container” by providing support for customisable process namespaces. Certainly, one can argue that Plan 9 and Inferno have been rather overlooked in recent years, particularly by the industry mainstream. He goes on to claim that such functionality, potentially desirable in application hosting environments, “makes the defining features of microkernels somewhat irrelevant”. Here I cannot really agree: what microkernels actually facilitate goes beyond what a particular operating system can do and how it has been designed.
A microkernel-based approach not only affords the opportunity to define the mechanisms of any resulting system, but it also provides the ability to define multiple sets of mechanisms, all of them potentially available at once, allowing them to be investigated, compared, and even combined. For example, Linux retains the notion of a user of the system, maintaining a global registry of such users, and even with notionally distinct sets of users provided by user namespaces, cumbersome mappings are involved to relate those namespace users back to this global registry. In a truly configurable system, there can be multiple user authorities, each being accessible by an arbitrary selection of components, and some components can be left entirely unaware of the notion of a user whatsoever.
Back in the 1990s, much coverage was given to the notion of operating system personalities. That various products would, for example, support DOS or Windows applications as well as Macintosh ones or Unix ones or OS/2 ones. Whether the user interface would reflect this kind of personality on a global level or not probably kept some usability professionals busy, and I recall one of my university classmates talking about a system where it was apparently possible to switch between Windows or maybe OS/2 and Macintosh desktops with a key combination. Since his father was working at IBM, if I remember correctly, that could have been an incarnation of IBM’s Workplace OS.
Other efforts were made to support multiple personalities in the same system, potentially in a more flexible way than having multiple separate sessions, and certainly more flexible than just bundling up, virtualising or emulating the corresponding environments. Digital investigated the porting of VMS functionality to an environment based on the Mach 3.0 microkernel and associated BSD Unix facilities. Had Digital eventually adopted a form of OSF/1 based on Mach 3.0, it could have conceivably provided a single system running Unix and VMS software alongside each other, sharing various common facilities.
Regardless of one’s feelings about Mach 3.0, whether one’s view of microkernels is formed from impressions of an infamous newsgroup argument from over thirty years ago, or whether it considers some of the developments in the years since, combining disparate technologies in a coherent fashion within the same system must surely be a desirable prospect. Being able to do so without piling up entire systems on top of each other and drilling holes between the layers seems like a particularly desirable thing to do.
A flexible, configurable environment should appeal to those in the same position as the FOSDEM presenter wishing to solve his hosting problems with pruned-down software stacks, as well as appealing to anyone with their own unrealised ambitions for things like mobile software agents. Naturally, such a configurable environment would come with its own administrative overheads, like the need to build and package applications for deployment in more minimal environments, and the need to keep software updated once deployed. Some of that kind of work should arguably get done under the auspices of existing distribution frameworks and initiatives, as opposed to having random bundles of software pushed to various container “hubs” posing as semi-official images, all the while weighing down the Internet with gigabytes of data constantly scurrying hither and thither.
This article does not propose any specific solution or roadmap for any of this beyond saying that something should indeed be done, and that microkernel-based environments, instead of seeking to reproduce Unix or Windows all over again, might usefully be able to provide remedies that we might consider. And with that, I suppose I should get back to my own experiments in this area.
Reconsidering Classic Programming Interfaces
June 4th, 2024
Since my last update, I have been able to spend some time gradually broadening and hopefully improving the support for classic programming interfaces in my L4Re-based experiments, centred around a standard C library implementation based on Newlib. Of course, there were some frustrations experienced along the way, and much remains to be done, not only in terms of new functionality that will need to be added, but also verification and correction of the existing functionality as I come to realise that I have made mistakes, these inevitably leading to new frustrations.
One area I previously identified for broadened support was that of process creation and the ability to allow programs to start other programs. This necessitated a review of the standard C process control functions, which are deliberately abstracted from the operating system and are much simpler and more constrained than those found in the unistd.h file that Unix programmers might be more familiar with. The traditional Unix functions are very much tied up with the Unix process model, and there are some arguments to be made that despite being “standard”, these functions are a distraction and, in various respects, undesirable from a software architecture perspective, for both applications and the operating systems that run them.
So, ignoring the idea that I might support the likes of execl, execv, fork, and so on, I returned to consideration of the much more limited system function that is part of the C language standards, this simply running an abstract command provided by a character string and returning a result code when the command has completed:
int system(const char *command);
To any casual application programmer, this all sounds completely reasonable: they embed a command in their code that is then presented to “the system”, which runs the commands and hands back a result or status code. But those of us who are accustomed to running commands at the shell and in our own programs might already be picking apart this simple situation.
First of all, “the system” needs to have what the C standards documentation calls a “command processor”. In fact, even Unix standardisation efforts have adopted the term, despite the Linux manual pages referring to “the shell”. But at this point, my own system does not have a shell or a command processor, instead providing only a process server that manages the creation of new processes. And my process server deals with arrays or “vectors” of strings that comprise a command to be used to run a given program, configured by a sequence of arguments or parameters.
Indeed, this brings us to some other matters that may be familiar to anyone who has had the need to run commands from within programs: that of parameterising command invocations by introducing our own command argument values; and that of making sure that the representation of the program name and its arguments do not cause the shell to misinterpret these elements, by letting an errant space character break the program name into two, for instance. When dealing only with command strings, matters of quoting and tokenisation enter the picture, making the exercise very messy indeed.
So, our common experience has provided us with a very good reason to follow the lead of the classic execv Unix function and to avoid the representational issues associated with command string processing. In this regard, the Python standard library has managed to show the way in some respects, introducing the subprocess module which features interfaces that are equivalent to functions like system and popen, supporting the use of both command strings and lists of command elements to represent the invoked command.
Oddly, however, nobody seems to provide a “vector” version of the system function at the C language level, but it seemed to be the most natural interface I might provide in my own system:
int systemv(int argc, const char *argv[]);
I imagine that those doing low-level process creation in a Unix-style environment would be content to use the exec family of functions, probably in conjunction with the fork function, precisely because a function like execv “shall replace the current process image with a new process image”, as the documentation states. Obviously, replacing the current process isn’t helpful when implementing the system function because it effectively terminates the calling program, whereas the system function is meant to allow the program to continue after command completion. So, fork has to get involved somehow.
The Flow of Convention
I get the impression that people venturing along a similar path to mine are often led down the trail of compatibility with the systems that have gone before, usually tempted by the idea that existing applications will eventually be content to run on their system without significant modification, and thus an implementer will be able to appeal to an established audience. In this case, the temptation is there to support the fork function, the exec semantics, and to go with the flow of convention. And sometimes, a technical obstacle seems like a challenge to be met, to show that an implementation can provide support for existing software if it needs or wants to.
Then again, having seen situations where software is weighed down by the extra complexity of features that people believe it should have, some temptations are best resisted, perhaps with a robust justification for leaving out any particular supposedly desirable feature. One of my valued correspondents pointed me to a paper by some researchers that provides a robust argument for excluding fork and for promoting alternatives. Those alternatives have their shortcomings, as noted in the paper, and they seem rather complicated when considering simple situations like merely creating a completely separate process and running a new program in it.
Of course, there may still be complexity in doing simple things. One troublesome area was that of what might happen to the input and output streams of a process that creates another one: should the new process be able to receive the input that has been sent to the creating process, and should it be able to send its output to the recipient of the creating process’s output? For something like system or systemv, the initial “obvious” answer might be the total isolation of the created process from any existing input, but this limits the usefulness of such functions. It should arguably be possible to invoke system or systemv within a program that is accepting input as part of a pipeline, and for a process created by these functions to assume the input processing role transparently.
Indeed, the Unix world’s standards documentation for system extends the C standard to assert that the system function should behave like a combination of fork and execl, invoking the shell utility, sh, to initiate the program indicated in the call to system. It all sounds a bit prescriptive, but I suppose that what it largely means is that the input and output streams should be passed to the initiated program. A less prescriptive standard might have said that, of course, but who knows what kind of vendor lobbying went on to avoid having to modify the behaviour of those vendors’ existing products?
This leads to the awkward problem of dealing with the state of an input stream when such a stream is passed to another process. If the creating process has already read part of a stream, we need the newly created process to be aware of the extent of consumed data so that it may only read unconsumed data itself. Similarly, the newly created process must be able to append output to the existing output stream instead of overwriting any data that has already been written. And when the created process terminates, we need the creating process to synchronise its own view of the input and output streams. Such exercises are troublesome but necessary to provide predictable behaviour at higher levels in the system.
Some Room for Improvement
Another function that deserves revisiting is the popen function which either employs a dedicated output stream to capture the output of a created process within a program, or a dedicated input stream so that a program can feed the process with data it has prepared. The mode indicates what kind of stream the function will provide: “r” yields an output stream passing data out of the process, “w” yields an input stream passing data into the process.
FILE *popen(const char *command, const char *mode);
This function is not in the C language standards but in Unix-related standards, but it is too useful to ignore. Like the system function, the standards documentation also defines this function in terms of fork and execl, with the shell getting involved again. Not entirely obvious from this documentation is what happens with the stream that isn’t specified, however, but we can conclude that with its talk of input and output filters, as well as the mention of those other functions, that if we request an output stream from the new process, the new process will acquire standard input from the creating process as its own input stream. Correspondingly, if we request an input stream to feed the new process, the new process will acquire standard output for itself and write output to that.
This poses some concurrency issues that the system function largely avoids. Since the system function blocks until the created process is completed, the state of the shared input and output streams can be controlled. But with popen, the created process runs concurrently and can interact with whichever stream it acquired from the creating process, just as the creating process might also be using it, at least until pclose is invoked to wait for the completion of the created process. The standards documentation and the Linux manual page both note such pitfalls, but the whole business seems less than satisfactory.
Again, the Python standard library shows what a better approach might be. Alongside the popen function, the popen2 function creates dedicated input and output pipes for interaction with the created process, the popen3 function adds an error pipe to the repertoire, and there is even a popen4 function that presumably does what some people might expect from popen2, merging the output and error streams into a single stream. Naturally, this was becoming a bit incoherent, and so the subprocess module was brought in to clean it all up.
Our own attempt at a cleaner approach might involve the following function:
pid_t popenv(int argc, const char *argv[], FILE **input, FILE **output, FILE **error);
Here, we want to invoke a program using a vector containing the program and arguments, just as we did before, but we also want to acquire the input, output and error streams. However, we might allow any of these to be specified as NULL, indicating that any such stream will not be opened for the created process. Since this might cause problems, we might need to create special “empty” or “null” streams, where appropriate, so as not to upset the C library.
Unlike popen, we might also provide the process identifier for the created process. This would allow us to monitor the process, control it in some way, and to wait for its completion. The nature of a process identifier is potentially more complicated than one might think, especially in my own system where there can be many process servers, each of them creating new processes without any regard to the others.
A Simpler Portable Environment Standard
Maybe I am just insufficiently aware of the historical precedents in this regard, but it seems that while C language standards are disappointingly tame when it comes to defining interaction with the host environment, the Unix or POSIX standardisation efforts go into too much detail and risk burdening any newly designed system with the baggage of systems that happened to be commercially significant at a particular point in time. Windows NT infamously feigned compliance with such standards to unlock the door to lucrative government contracts and to subvert public software procurement processes, generating colossal revenues that easily paid for any inconvenient compliance efforts. However, for everybody else, such standards seem to encumber system and application developers with obligations and practices that could be refined, improved and made more suitable for modern needs.
My own work depends on L4Re which makes extensive use of capabilities to provide access to entities within the system. For example, each process relies on a task that provides a private address space, within which code and data reside, along with an object space that retains the capabilities available within the task. Although the Fiasco (or L4Re) microkernel has some notion of all the tasks in the system, as well as all the threads, together with other kinds of objects, such global information is effectively private to the kernel, and “user space” programs merely deal with capabilities that reference specific objects. For such programs, there is no way to get some kind of universal list of tasks or threads, or to arbitrarily request control over any particular instances of them.
In systems with different characteristics to the ones we already know, we have to ask ourselves whether we want to reproduce legacy behaviour. To an extent, it might be desirable to have registers of resident processes and the ability to list the ones currently running in the system, introducing dedicated components to retain this information. Indeed, my process servers could quite easily enumerate and remember the details of processes they create, also providing an interface to query this register, maybe even an interface to control and terminate processes.
However, one must ask whether this is essential functionality or not. For now, the rudimentary shell-like environment I employ to test this work provides similar functionality to the job control features of the average Unix shell, remembering the processes created in this environment and offering control in a limited way over this particular section of the broader system.
And so the effort continues to try and build something a little different from, and perhaps a bit more flexible than, what we use today. Hopefully it is something that ends up being useful, too.