Paul Boddie's Free Software-related blog
Paul's activities and perspectives around Free Software
Notions of Progress on the Free Software Desktop
November 7th, 2013
Once again, discussion about Free Software communities is somewhat derailed by reflections on the state of the Free Software desktop. To be fair to participants in the discussion, the original observations about communities were so unspecific that people would naturally wonder which communities were being referenced.
Usability and Accessibility
As always, frustrating elements of recent Free Software desktop environments were brought up for criticism and evaluation. One of them concerned the “plasmoid” enhancements of KDE 4 (or KDE Plasma Desktop as it is known according to the rebranding of KDE assets) which are often regarded as superfluous distractions from the work of perfecting the classic desktop environment. Amidst all this, the “folder view” plasmoid (or desktop widget) in particular came under scrutiny. As I understand it, the “folder view” is just a panel or window that groups icons in a region on the desktop background, and I acknowledged that it certainly represents an improvement over managing icons on a normal desktop, but that it can also confuse people when they accidentally close the folder view – easy to do with a stray mouse click – leaving them to wonder where their icons went.
Such matters of usability make me wonder how well tested some of the concepts employed in these environments really are, despite insistences that usability experts have been involved and that non-experts in the field of usability are unable to see the forest for the trees. From my own experiences, I feel that the developers would really benefit from doing phone support for their wares, especially with users who haven’t learned all the fancy terminology and so must describe what they see from first principles and be told what to do at a similar level. Even better: such support should be undertaken from memory and not sitting in front of a similarly configured computer.
Although it is a somewhat separate discipline with different constraints, I also suspect that such “over the phone” exercises might help accessibility as well. An inexperienced user may provide different information to that provided by something like a screen reader, where the former may struggle to articulate concepts and the latter may merely describe the environment according to prescribed terms, and where the former may be able to use more flexible powers of description whereas the latter can only rely on the cooperation of other programs to populate a simplistic description of the state of the environment, but the exercise of being a person cut off from the rich graphical scenery and their familiar interaction mechanisms might put the usability and accessibility of the software into perspective for the developers.
The Measure of Progress
But back to the Free Software desktop in general, if only to contemplate notions of progress and to consider whether lessons really have been learned, or whether people would rather not think about the things which went wrong, labelling them as “finished business” or “water under the bridge” and urging people not to bring such matters up again. One participant remarked about how it took six years from 2005 to 2011 for KDE 4 to become as usable as its predecessor. A response to this indicated that this was actually “fantastic” progress given that Google used as much time to make Android “decent”.
Fantastic it may be, but we should not consider the endeavour as a software development project in isolation, with the measure of success being that something was created from nothing in six short years. Indeed, we must consider what was already there – absolutely not nothing – and how the result of the development measures up against that earlier system. As far as getting Free Software in front of people and building on earlier achievements are concerned, those six years can almost be considered six lost years. Nobody should be patting themself on the back upon hearing that someone in 2013 can move from KDE 3 to KDE 4 and feel that at least they didn’t lose much functionality.
The Role of Applications
It was also noted that KDE development now focuses more on application development than on the environment itself. One must therefore ask where we are with regard to parity with the suite of applications running under KDE 3. Here, I can only describe my own experiences, but this should be flattering to any constrained selection of updated applications because of my own rather conservative application choices.
Kontact is usable because I imagine various companies needed it to be usable to stay in business (and even then I don’t know the story of the diversions via Nepomuk and other PIM initiatives that could have endangered that application’s viability); Digikam is usable because the developers remained interested in improving the software and even maintained the KDE 3 version for a while; Okular has picked up where KPDF left off; K3B still works much the same as before. There are presumably regressions and improvements in all these: Kontact, for instance, is much slower in certain areas such as message sorting, but it probably has more robust and coherent PGP and S/MIME support than its predecessor (which may have been suffering from lack of maintenance at both the project and distribution level).
Meanwhile, Amarok has become a disaster with an incoherent interface involving lots of “in the know” controls, and after it stopped playback mid-track for the nth time and needed a complete restart to get sound back, I switched to Minirok out of desperation. Other applications took a permanent holiday, such as Kopete which I don’t miss because my IRC needs are covered by Konversation.
Stuff like Konqueror is still around, despite being under threat of complete replacement by Dolphin, although it has picked up the little “+” and “-” controls that pervade KDE now. Such controls confuse various classes of user through poor visual contrast (a tiny symbol in red or green superimposed on a multicolour icon!) while demanding from such users better than average motor skills (“to open the document aim at the tiny area but not the tiny area within the tiny area”).
Change You Can Believe In?
You wouldn’t think that I appreciate the work done on the Free Software desktop, but I do. What frustrates me and a lot of other people, however, is the way that things that should have been “behind the scenes” infrastructure improvements (Qt 3 being superseded by Qt 4, for instance) that could have been undertaken whilst preserving continuity for users have instead been thrust at those users in the form of unnecessary decisions about which functionality they can afford to lose in order to have a supported and secure system that will not gradually fall apart over time. (Not that KDE is unique in this respect, consider the Python 2 to Python 3 transition and the disruption even such a leisurely transition can cause.)
Exposing change to a group of people creates costs for those people, and when those people have other things than computing as the principal focus in their lives, such change can have damaging effects on their continued use of the software and on the quality of their lives. Following the latest trends, discovering the newest software, or just discovering how their existing software functions since the last vendor-initiated update are all distractions for people who just want to sit down, do some things on the computer, and then go back to their lives. In today’s gadget-pushing society, the productivity benefits of personal computing are being eroded by a fanaticism for showing off new and different things mostly for the sake of them being, well, new and different. Bored children may enjoy the fire-hose of new “apps”, tricks and gadgets, but that shouldn’t mean that everybody else has to be made to enjoy it as well or be considered backward “technophobes” who “don’t understand” or “won’t embrace” new technology.
One can argue that by failing to shield users from the cost of change, especially when the level of functionality remains largely similar, Free Software desktop developers have imperilled their own mission with the result that they now have to make up lost ground in the struggle to get people to use their software. But even to those developers who don’t care about such things, the other criticism that could be levelled against them might be a more delicate matter and more difficult to reconcile with their technical reputation: churning up change and making others deal with it can arguably be regarded as bad software project management and, indeed, bad project management in general.
Maybe such considerations also have something to say about the direction any given community might choose to follow, and whether bold new ideas should be embraced without a thorough consideration of the consequences.
Neo900: And they’re off!
November 1st, 2013
Having mentioned the Neo900 smartphone initiative previously, it seems pertinent to note that it has moved beyond the discussion phase and into the fundraising phase. Compared to the Ubuntu Edge, the goals are fairly modest – 25000 euros versus tens of millions of dollars – but the way this money will be spent has been explained in somewhat more detail than appeared to be the case for the Ubuntu Edge. Indeed, the Neo900 initiative has released a feasibility study document describing the challenges confronting the project: it contains a lot more detail than the typical “we might experience some setbacks” disclaimer on the average Kickstarter campaign page.
It’s also worth noting that as the Neo900 inherits a lot from the GTA04, as the title of the feasibility study document indicates when it refers to the device as the “GTA04b7”, and as the work is likely to be done largely within the auspices of the existing GTA04 endeavour, the fundraising is being done by Golden Delicious (the originators of the GTA04) themselves. From reading the preceding discussion around the project, popular fundraising sites appear to have conditions or restrictions that did not appeal to the project participants: Kickstarter has geographical limitations (coincidentally involving the signatory nations of the increasingly notorious UKUSA Agreement), and most fundraising sites also take a share of the raised funds. Such trade-offs may make sense for campaigns wanting to reach a large audience (and who know how to promote themselves to get prominence on such sites), but if you know who your audience is and how to reach them, and if you already have a functioning business, it could make sense to cut the big campaign sites out of the loop.
It will certainly be interesting to see what happens next. An Openmoko successor coming to the rescue of a product made by the mobile industry’s previously most dominant force: that probably isn’t what some people expected, either at Openmoko or at that once-dominant vendor.
Dell and the Hardware Vendors Page
October 31st, 2013
Hugo complains about Dell playing around with hardware specifications on their Ubuntu-based laptop products. (Hugo has been raising some pretty interesting issues, lately!)
I think that one reason why Dell was dropped from the Hardware Vendors page on the FSFE Fellowship Wiki was that even though Dell was promoting products with GNU/Linux pre-installed, actually finding them remained a challenge involving navigating through page after page of “Dell recommends Windows Vista/Windows 8/Windows Whatever” before either finding a low-specification and overpriced afterthought of a product or the customer just giving up on the whole idea.
Every time they “embrace Linux” I’d like to think that Dell are serious – indeed, Dell manages to support enterprise distributions of GNU/Linux on servers and workstations, so they can be serious, making their antics somewhat suspiciously incompetent at the “home and small office” level – but certainly, the issue of the changing chipset is endemic: I’m pretty sure that a laptop I had to deal with recently didn’t have the advertised chipset, and I tried as hard as possible to select the exact model variant, knowing that vendors switch things out “on the quiet” even for the same model. On that occasion, it was Lenovo playing around.
The first thing any major vendor should do to be taken seriously is to guarantee that if they sell a model with a specific model number then it has a precise and unchanging specification and that both the proper model number and the specification are publicly advertised. Only then can we rely on and verify claims of compatibility with our favourite Free Software operating systems.
Until then, I can only recommend buying a system from a retailer who will stand by their product and attempt to ensure that it will function correctly with the Free Software of your choice, not only initially but also throughout a decent guarantee period. Please help us maintain the Hardware Vendors page and to support vendors and retailers who support Free Software themselves.
(Note to potential buyers and vendors: the Hardware Vendors page does not constitute any recommendation or endorsement of products or services, nor does the absence of any vendor imply disapproval of that vendor’s products. The purpose of the page is to offer information about available products and services based on the experiences and research of wiki contributors, and as such is not a marketplace or a directory where vendors may request or demand to be represented. Indeed, the best way for a vendor to be mentioned on that page is to coherently and consistently offer products that work with Free Software and that satisfy customer needs so that someone may feel happy enough with their purchase that they want to tell other people about it. Yes, that’s good old-fashioned service being recognised and rewarded: an unusual concept in the modern world of business, I’m sure.)

The inside of some random Dell computer at a former workplace - this one may not have been running GNU/Linux, but my Dell workstation was
The Ben NanoNote: An Overlooked Hardware Experimentation Platform
October 30th, 2013
The Ben NanoNote is a pocket computer with a 3-inch screen and organiser-style keyboard announced in 2010 as the first in a line of copyleft hardware products under the Qi-Hardware umbrella: an initiative to collaboratively develop open hardware with full support for Free Software. With origins as an existing electronic dictionary product, the Ben NanoNote was customised for use as a general-purpose computing platform and produced in a limited quantity, with plans for successors that sadly did not reach full production.

The Ben NanoNote with illustrative beverage (not endorsed by anyone involved with this message, all trademarks acknowledged, call off the lawyers!)
When the Ben (as it is sometimes referred to in short form) first became known to a wider audience, many people focused on those specifications common to most portable devices sold today: the memory and screen size, what kind of networking it has (or doesn’t have). Some people wondered what the attraction was of a device that wasn’t wireless-capable when supposedly cheaper wireless communicator devices could be obtained. Even the wiki page for the Ben has only really prominently promoted the Free Software side of the device, mentioning its potential for making customised end-user experiences, and as an appliance for open content or for music and video playback.
Certainly, the community around the Ben has a lot to be proud of with regard to Free Software support. A perusal of the Qi-Hardware news page reveals the efforts to make sure that the Ben was (and still is) completely supported by Free Software drivers within the upstream Linux kernel distribution. With a Free Software bootloader, the Ben is probably one of the few devices that could conceivably get some kind of endorsement for the complete absence of proprietary software, including firmware blobs, from organisations like the FSF who naturally care about such things. (Indeed, a project recommended by the FSF whose output appears to be closely related to the Ben’s default software distribution publishes a short guide to installing their software on the Ben.)
But not everybody focused only on the software upon learning about the device: some articles covered the full range of ambitions and applications anticipated for the Ben and for subsequent devices in the NanoNote series. And work got underway rather quickly to demonstrate how the Ben might complement the Arduino range of electronics prototyping and experimentation boards. Although there were concerns that the interfacing potential of the Ben might be a bit limited, with only USB peripheral support available via the built-in USB port (thus ruling out the huge range of devices accessible to USB hosts), the alternatives offered by the device’s microSD port appear to offer a degree of compensation. (The possibility of using SDIO devices had been mentioned at the very beginning, but SDIO is not as popular as some might have wished, and the Ben’s microSD support seems to go only as far as providing MMC capabilities in hardware, leaving out desirable features such as hardware SPI support that would make programming slightly easier and performance substantially better. Meanwhile, some people even took the NanoNote platform to a different level by reworking the Ben, freeing up connections for interfacing and adding an FPGA, but the resulting SIE device apparently didn’t make it beyond the academic environments for which it was designed.)
Thus, the Universal Breakout Board (UBB) was conceived: a way of “breaking out” or exposing the connections of the microSD port to external devices whilst communicating with those devices in a different way than one would with SD-based cards. Indeed, the initial impetus for the UBB was to investigate whether the Ben could be interfaced to an Ethernet board and thus provide dependency-free networking (as opposed to using Ethernet-over-USB to a networked host computer or suitably configured router). Sadly, some of those missing SD-related features have an impact on performance and practicality, but that doesn’t stop the UBB from being an interesting avenue of experimentation. To distinguish between SD-related usage and to avoid trademark issues, the microSD port is usually referred to as the 8:10 port in the context of the UBB.

The Universal Breakout Board that plugs into the 8:10 (microSD) slot
(The UBB image originates from Qi-Hardware and is CC-BY-SA 3.0 licensed.)
{kind=link}
Interfacing in Comfort
A lot of experimentation with computer-controlled electronics is done using microcontroller solutions like those designed and produced by Arduino, whose range of products starts with the modestly specified Arduino Uno with an ATmega328 CPU providing 32K (kilobytes) of flash memory and 2K of “conventional” static RAM (SRAM). Such specifications sound incredibly limiting, and when one considers that many microcomputers in 1983 – thirty years ago – had at least 32K of “conventional” readable and writable memory, albeit not all of it being always available for use on some machines, devices such as the Uno do not seem to represent much of an advance. However, such constraints can also be liberating: programs written to run in such limited space on the “bare metal” (there being no operating system) can be conceptually simple and focus on very specific interfacing tasks. Nevertheless, the platform requires some adjustment, too: data that will not be updated while a program runs on the device must be packed away in the flash memory where it obviously cannot be changed, and data that the device manipulates or collects must be kept within the limits of the precious SRAM, bearing in mind that the program stack may also be taking up space there, too.
As a consequence, the Arduino platform benefits from a vibrant market in add-ons that extend the basic boards such as the Uno with useful capabilities that in some way make up for those boards’ deficiencies. For example, there are several “shield” add-on products that provide access to SD cards for “data logging“: essential given that the on-board SRAM is not likely to be able to log much data (and is volatile), and given that the on-board flash memory cannot be rewritten during operation. Other add-ons requiring considerable amounts of data also include such additional storage, so that display shields will incorporate storage for bitmaps that might be shown on the display: the Arduino TFT LCD Screen does precisely this by offering a microSD slot. On the one hand, the basic boards offer only what people really need as the foundational component of their projects, but this causes add-on designers to try and remedy the lack of useful core functionality at every turn, putting microSD or SD storage on every shield or extension board just because the user might not have such capabilities already.
Having said all this, the Arduino platform generally only makes you pay for what you need, and for many people this is interesting enough that it explains Arduino’s continuing success. Nevertheless, for some activities, the Arduino platform is perhaps too low-level and to build and combine the capabilities one might need for a project – to combine an Arduino board with numerous shields and other extensions – would be troublesome and possibly unsatisfactory. At some point, one might see the need to discard the “form factor” of the Arduino and to use the technological building blocks that comprise the average Arduino board – the microcontroller and other components – in order to make a more integrated, more compact device with the additional capabilities of choice. For instance, if one wanted to make a portable music player with Arduino, one could certainly acquire shields each providing a screen and controls (and microSD slot), headphone socket and audio playback (and microSD slot), and combine them with the basic board, hoping that they are compatible or working round any incompatibilities by adding yet more hardware. And then one would want to consider issues of power, whether using a simple battery-to-power-jack solution would be good enough or whether there should be a rechargeable battery with the necessary power circuit. But the result of combining an Arduino with shields would not be as practical as a more optimised device.

The Arduino Duemilanove attached to a three-axis accelerometer breakout board
The Opportunity
In contrast to the “bare metal” approach, people have been trying and advocating other approaches in recent times. First of all, it has been realised that many people would prefer the comfort of their normal computing environment, or at least one with many of the capabilities they have come to expect, to a very basic environment that has to be told to run a single, simple program that needs to function correctly or be made to offer some rudimentary support for debugging when deployed. Those who promote solutions like the Raspberry Pi note that it runs a desktop operating system, typically GNU/Linux, and thus offers plenty of facilities for writing programs and running them in pleasant ways. Thus, interfacing with other hardware becomes more interactive and easier to troubleshoot, and it might even permit writing interfacing programs in high-level languages like Python as opposed to low-level languages like C or assembly language. In effect, the more capable platform with its more generous resources, faster processor and a genuine operating system provide opportunities that a microcontroller-based solution just cannot provide.
If this was all that were important then we would surely have reached the end of the matter, but there is more to consider. The Raspberry Pi is really a desktop computer replacement: you plug in USB peripherals and a screen and you potentially have a replacement for your existing x86-based personal computer. But it is in many ways only as portable and as mobile as the Arduino, and absolutely less so in its primary configuration. Certainly, people have done some interesting experiments adding miniature keyboards and small screens to the Raspberry Pi, but it starts to look like the situation with the Arduino when trying to build up some capability or other from too low a starting point. Such things are undoubtedly achievements in themselves, and like climbing a mountain or going into space, showing that it could be done is worthy of our approval, but just like those great achievements it would be a shame to go to all that effort without also doing a bit of science in the process, would it not?

An e-paper display connected to the Ben NanoNote via a cable and the Sparkfun "microSD Sniffer" board
This is where the Ben enters the picture. Because it is a pocket computer with a built-in screen and battery (and keyboard), you can perform various mobile experiments without having to gear up to be mobile in the first place. Perhaps most of the time, it may well be sitting on your desk next to a desktop computer and being remotely accessed using a secure shell connection via Ethernet-over-USB, acting as a mere accessory for experimentation. An example of this is a little project where I connected an e-paper screen to the Ben to see how hard it would be to make that screen useful. Of course, I could also take this solution “on the road” if I wanted, and it would be largely independent of any other computing infrastructure, although I will admit to not having run native compilers on the Ben myself – everything I have compiled has actually been cross-compiled using the OpenWrt toolchain targeting the Ben – but it should be possible to develop on the road, too.
But for truly mobile experimentation, where having an untethered device is part of the experiment, the Ben offers something that the Raspberry Pi and various single-board computer solutions do not: visualisation on the move. One interesting project that pioneered this is the UBB-LA (UBB Logic Analyzer) which accepts signals via the Ben’s 8:10 port and displays a time-limited capture of signal data on the screen. One area that has interested me for a while has been that of orientation and motion sensor data, with the use of gyroscopes and accelerometers to determine the orientation and motion of devices. Since there are many “breakout boards” (small boards providing convenient access to components) offering these kinds of sensors, and since the communication with these sensors is within the constraints of the 8:10 port bandwidth, it became attractive to use the Ben to prototype some software for applications which might use such data, and the Ben’s screen provides a useful way of visualising the interpretation of the data by the software. Thus, another project was conceived that hopefully provides the basis for more sophisticated experiments into navigation, interaction and perhaps even things like measurement.
{kind=link}

The Pololu MinIMU-9 board connected to the Ben NanoNote in a horizontal position, showing the orientation information from the board
The Differentiator
Of course, sensor applications are becoming commonplace due to the inclusion of gyroscopes, accelerometers, magnetometers and barometers into smartphones. Indeed, this was realised within the open hardware community several years ago with the production of the Openmoko Freerunner Navigation Board that featured such sensors and additional interfacing components. Augmented reality applications and fancy compass visualisations are becoming standard features on smartphones, complementing navigation data from GPS and comparable satellite navigation systems, and the major smartphone software vendors provide APIs to access such components. Indeed, many of the components used in smartphones feature on the breakout boards mentioned above, unsurprisingly, because their cost has been driven down and made them available and affordable for a wider range of applications.
So what makes the Ben NanoNote interesting when you could just buy a smartphone and code against, say, the Android API? Well, as many people familiar with software and hardware freedom will already know, being able to use an API is perhaps only enough if you never intend to improve the software providing that API, or share that software and any improvements you make to it with others, and if you never want to know what the code is really doing, anyway. Furthermore, you may not be able to change or upgrade that software or to deploy your own software on a smartphone you have bought, despite vigorous efforts to make this your right.
Even if you think that the software providers have done a good job interpreting the sensor data and translating it into something usable that a smartphone application might use, and this is not a trivial achievement by any means, you may also want to try and understand how the device interacts with the sensors at a lower level. It is rather likely that an Android smartphone, for example, will communicate with an accelerometer using a kernel module that resides in the upstream Linux kernel source code, and you could certainly take a look at that code, but as thirty years of campaigning for software freedom has shown, taking a look is not as good as improving, sharing and deploying that code yourself. Certainly, you could “root” your smartphone and install an alternative operating system that gives you the ability to develop and deploy kernel modules and even user-space code – normal programs – that access the different sensors, but you take your chances doing so.
Meanwhile, the Ben encourages experimentation by letting you re-flash the bootloader and operating system image, and you can build your own kernel and root filesystem populated with programs of your choice, all of it being Free Software and doing so using only Free Software. Things that still surprise people with modified smartphone images like being able to log in and get a secure shell session and to run “normal Linux programs” are the very essence of the Ben. It may not have wireless or cellular networking as standard – a much discussed topic that can be solved in different ways – but that can only be good news for the battery life.
The Successor?
“What would I use it for?” That might have been my first reaction to the Ben when I first heard about it. I don’t buy many gadgets – my mobile telephone is almost ten years old – and I always try to justify gadget purchases, perhaps because growing up in an age where things like microcomputers were appearing but were hardly impulse purchases, one learns how long-lived technology products can be when they are made to last and made to a high quality: their usefulness does not cease merely because a new product has become available. Having used the Ben, it is clear that although its perceived origins as some kind of dictionary, personal organiser or music player are worthy in themselves, it just happens to offer some fun as a platform for hardware experimentation.
I regard the Ben as something of a classic. It might not have a keyboard that would appeal to those who bought Psion organiser products at the zenith of that company’s influence, and its 320×240 screen seems low resolution in the age of large screen laptops and tablets with “retina” displays, but it represents something that transcends specifications and yet manages to distract people when they see one. Sadly, it seems likely that remaining stocks will eventually be depleted and that opportunities to acquire a new one will therefore cease.
Plans for direct successors of the Ben never really worked out, although somewhat related products do exist: the GCW-Zero uses an Ingenic SoC just like the Ben does, and software development for both devices engages a common community in many respects, but the form factor is obviously different. The Pandora has a similar form factor and has a higher specification but also has a higher price, but it is apparently not open hardware. The Neo900, if it comes to pass (and it hopefully will), may offer a good combination of Free Software and open hardware, but it will understandably not come cheap.
One day, well-funded organisations may recognise and reward the efforts of the open hardware pioneers. Imitating aspirational product demonstrations and trying to get in on the existing action is all very well, not to mention going your own way, but getting involved in the open hardware communities and helping them to build new things would benefit everybody. I can only hope that such organisations come to their senses soon so that more people can have the opportunity to play with sensors, robotics and all the other areas of hardware experimentation, and that a healthy diversity of platforms may be sustained to encourage such experimentation long into the future.
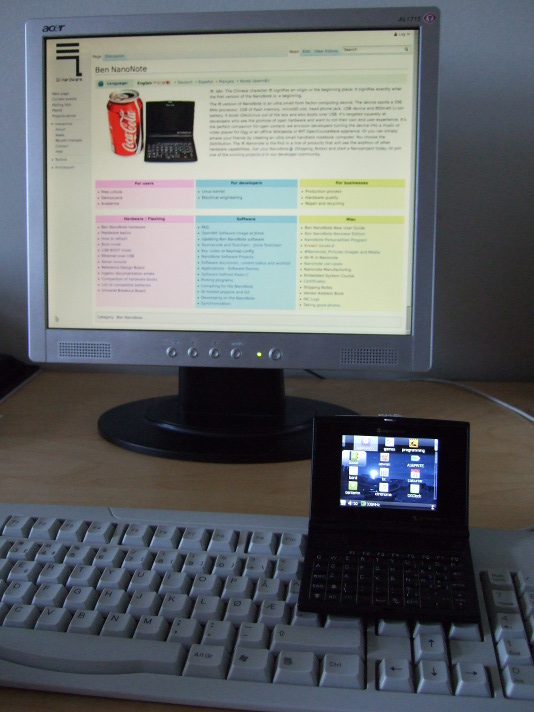
The Ben NanoNote and regular-sized desktop computer accessories
More on Kolab and Debian
October 23rd, 2013
Well, after my recent blog post highlighting some surprising problems with my Kolab installation – not at all a complaint about the packages, really, but more of a contribution towards improving the packaging situation, as I see it at least – some more interest in the situation around Kolab packaging for Debian has been shown:
- HowTo improve Debian packages using OBS describes the documented packaging-related process in more detail for a specific improvement.
- A Call for Participation invites those interested in Debian packaging to get involved.
Packaging for Debian can be a challenge. My own experience involved a pure-Python tool and still required lots of iterations to satisfy the Debian gatekeepers; this is understandable given that they try to virtually guarantee a coherent experience and provide a large selection of software whose copyright and licensing status must be clear, acceptable and without nasty surprises. I respect the effort that has gone into Kolab packaging for Debian already: without that effort, I probably wouldn’t even have tried the software.
The plan now must surely involve input from the Debian groupware initiative, especially as the Kolab architecture presumably resembles some of the other packaged solutions, and those who have contributed to the existing packaging work, as well as some discussion on the Kolab development mailing list, and some effort with the Open Build Service tools (with the “build commander” tool fortunately being available as a Debian package).
It is unfortunate that as Torsten points out, “Currently, there’s only one volunteer working on the Debian packages in his limited spare time, but hundreds of people who want to use reliable Debian packages.” Meanwhile, Timotheus points out, “Since there seems to be no corporate funding available for the Debian packages, we all need to pull together as a community and get it done!” It seems to me that those organisations that stand to benefit from more adoption of Free Software groupware, especially those using Debian as their foundation, might do well to assist this work instead of waiting for people to get it done in their free time.
Kolab and Debian Packaging Pitfalls
October 21st, 2013
Hugo Roy has been trying to install Kolab and not getting on particularly well with it. His experiences persuaded me to take another look at my Kolab installation done back in June, and to my surprise it didn’t seem to work any more. I eventually discovered some things that will probably need fixing in the packaging, and these are mentioned below. I suppose I’ll try and pursue these with the developers and packagers.
The LDAP server (provided by the 389-ds suite of packages, but actually started when the ns-slapd program is run, and known as the dirsrv service – yes, all very confusing stuff) doesn’t want to run until the permissions are fixed on the /var/run/dirsrv and /var/lock/dirsrv directories so that the ns-slapd program can create pid and lock files.
The kolab-saslauthd service won’t be running if the LDAP server isn’t running. (You can check this using service --status-all and seeing what is running and what isn’t.) Some Kolab programs seem to get upset when they can’t connect to the LDAP or IMAP servers, and if the LDAP server is brought up, there’s a frequent, recurring error from a Python program complaining about IMAP server connections failing…
Traceback (most recent call last):
File "/usr/lib/python2.7/dist-packages/kolabd/process.py", line 44, in synchronize
auth.synchronize()
File "/usr/lib/python2.7/dist-packages/pykolab/auth/__init__.py", line 243, in synchronize
self._auth.synchronize()
File "/usr/lib/python2.7/dist-packages/pykolab/auth/ldap/__init__.py", line 860, in synchronize
callback=self._synchronize_callback,
File "/usr/lib/python2.7/dist-packages/pykolab/auth/ldap/__init__.py", line 2151, in _search
secondary_domains
File "", line 10, in
File "/usr/lib/python2.7/dist-packages/pykolab/auth/ldap/__init__.py", line 1895, in _persistent_search
secondary_domains=secondary_domains
File "/usr/lib/python2.7/dist-packages/pykolab/auth/ldap/__init__.py", line 1735, in _synchronize_callback
eval("self._change_none_%s(entry, change_dict)" % (entry['type']))
File "", line 1, in
File "/usr/lib/python2.7/dist-packages/pykolab/auth/ldap/__init__.py", line 1389, in _change_none_user
self.imap.connect(domain=self.domain)
File "/usr/lib/python2.7/dist-packages/pykolab/imap/__init__.py", line 144, in connect
self._imap[hostname].login(admin_login, admin_password)
File "/usr/lib/python2.7/dist-packages/pykolab/imap/cyrus.py", line 133, in login
cyruslib.CYRUS.login(self, *args, **kw)
File "/usr/lib/python2.7/dist-packages/cyruslib.py", line 416, in login
self.__doexception("LOGIN", error)
File "/usr/lib/python2.7/dist-packages/cyruslib.py", line 359, in __doexception
self.__doraise( function.upper(), msg )
File "/usr/lib/python2.7/dist-packages/cyruslib.py", line 368, in __doraise
raise CYRUSError( idError[0], mode, msg )
CYRUSError: (10, 'LOGIN', 'generic failure')
Restarting the kolab-saslauthd service fixes this; maybe restarting the cyrus-imapd service also helps. Restarting the kolab-server service should apparently synchronise the constituent services, but I’m not sure it helps if you get the above Python error. You may also see an LDAP-related error which just appears to be the same program or a related one getting even more upset about the LDAP server.
Also, if you don’t update for a while, the clamav-freshclam service uses a lot of CPU and bandwidth performing updates. Such stuff needs turning off if you value your computer’s interactivity, in my experience.
Neo900: Combining Communities to Create Opportunities
September 10th, 2013
Ever since the withdrawal of Openmoko from open smartphone development, it appears to have been challenging to find large numbers of people who might be interested in supporting similar open hardware efforts, either by having them put down money to fund the development and production of devices, or by encouraging them to develop Free Software to run on the hardware produced by those efforts. That anyone can go and buy an Android phone and tell themselves that it is just like that dream they once had of running Linux on a phone (if they turn the lights down low enough and ignore the technical and ethical limitations) serves as just enough of a distraction to keep people merely curious about things like Openmoko and open hardware, persuading them to hold off supporting such things until everybody else has jumped on board and already made it a safe choice. It almost goes without saying that where risk-takers are needed to make something happen, that thing is not going to happen if everybody looks to everybody else to take the risk. (And even when people do take the risk, they seem to think that their pledges and donations are as good as money in the bank, but that is another story.)
Naturally, the Ubuntu Edge campaign showed that some money is floating around and can be attracted to suitably exciting projects. Unfortunately, one may be tempted to conclude that anything more mundane than a next generation product – one that can only be delivered at some point in the future, once it becomes feasible and economic to manufacture and sell something with “out of this world” specifications – is unlikely to attract the interest of potential customers with money to pledge towards something. Such potential customers surely want something their money cannot already buy, and offering only things like openness and freedom as enhancements to today’s specifications is perhaps not exciting enough for some of those people.
It is therefore rather refreshing that two communities have recently become more aware of the possibilities offered by, and available to, open hardware: the OpenPhoenux community with their ongoing GTA04 project to follow on from the work of Openmoko, and the Maemo community seeking a sustainable future beyond the now-discontinued Nokia N900 smartphone. Despite heroic efforts to sustain the GTA04 project, outside interest has apparently been low enough that additional production has been placed on hold: a minimum number of orders needs to exist before any kind of further manufacturing can take place. Meanwhile, a community of people whose devices may one day fail to function or perhaps no longer function already, forcing them to seek replacements in the second-hand market with all the usual online auction profiteering and the purchasing uncertainties that go along with it, have been made aware of an active hardware project whose foundations largely resemble those of the devices they wish to sustain.
So, unlike Ubuntu Edge, the Neo900 initiative is not offering next year’s hardware. In fact, it is not even offering this year’s hardware. But what it does offer is a sustainable path into the future for those who like the form factor and software provided by the N900: people who were having to come to terms with buying a device that would not be as satisfactory as the one they already have, merely because the device they already have has reached the end of its usable life, and because the mobile device industry has a different idea of progress from the one they happen to have. In effect, the Neo900 is about taking control, owning the roadmap, deciding when or whether the fads and fashions of the industry at large will serve them better, and being able to choose or to reject the wider industry’s offerings on a more reasonable timescale.
The N900, as a product abandoned some time ago by Nokia as it retreated into being a vassal state of the Microsoft empire, gets an opportunity to rise from the ashes of the ruin wrought by the establishment of that corporate relationship. At a time where Nokia sees its core business incorporated into Microsoft itself in the final chapter of what has to be one of the most widely predicted and reported acts of alleged corporate looting in recent years, and where former Nokia executives announce plans to re-establish the business independently by attracting neglected Nokia talent, the open phoenix in the form of OpenPhoenux may help the N900 to rise above its troubled past and to shine once again as its former custodians struggle with the mayhem of corporate integration or corporate reconstruction, depending on where they end up.
People might wonder why anyone would want more of the same rather than something new, different, exciting, shiny. The fact is that away from the noise of exhibition floor, trade show and developer conference demonstrations, most people just want something that works and, preferably, something they already know. Their life goes on and does not wait for them to have to learn the latest gestures and moves to make some new gadget do what their old gadget was doing before it broke down. Some people – those with an N900 or those who wanted one – now have a new opportunity available to them, thanks to open hardware and the Neo900 initiative. For the rest of us, it offers more choice and maybe some hope that open hardware will be able to cater to more people in times to come.
Terms of the Pirates
September 3rd, 2013
According to the privacy policy on the Web site of the UK Pirate Party, “The information generated by the cookie about your use of the website (including your IP address) will be transmitted to and stored by Google on servers in the United States.” Would it not be more appropriate for the pirates to do their own visitor analysis using a Free Software solution like Piwik?
Come on, pirates, you can do better than this!
Licensing in a Post Copyright World: Some Clarifications
July 28th, 2013
Every now and then, someone voices their dissatisfaction with the GNU General Public License (GPL). A recent example is the oddly titled Licensing in a Post Copyright World: odd because if anything copyright is getting stronger, even though public opposition to copyright legislation and related measures is also growing. Here I present some necessary clarifications for anyone reading the above article. This is just a layman’s interpretation, not legal advice.
Licence Incompatibility
It is no secret that code licensed only under specific versions of the GPL cannot be combined with code under other specific versions of the GPL such that the resulting combination will have a coherent and valid licence. But why are the licences incompatible? Because the decision was taken to strengthen the GPL in version 3 (GPLv3), but since this means adding more conditions to the licence that were not present in version 2 (GPLv2), and since GPLv2 does not let people who are not the authors of the code involved add new conditions, the additional conditions of GPLv3 cannot be applied to the “GPLv2 only” licensed code. Meanwhile, the “GPLv3 only” licensed code requires these additional conditions and does not allow people who are not the authors of the code to strip them away to make the resulting whole distributable under GPLv2. There are ways to resolve this as I mention below.
(There apparently was an initiative to make version 2.2 of the GPL as a more incremental revision of the licence, although incorporating AGPLv3 provisions, but according to one of the central figures in the GPL drafting activity, work progressed on GPLv3 instead. I am sure some people wouldn’t have liked the GPLv2.2 anyway, as the AGPLv3 provisions seem to be one of many things they don’t like.)
Unnecessary Amendments
Why is the above explanation about licence compatibility so awkward? Because of the “only” stipulation that people put on their code, against the advice of the authors of the licence. It turns out that some people have so little trust in the organisation that wrote the licence they have nevertheless chosen to use that in a flourish of self-assertion, they needlessly stipulate “only” instead of “or any later version” and feel that they have mastered the art of licensing.
So the problems experienced by projects who put “only” everywhere, becoming “stuck” on certain GPL versions is a situation of their own making, like someone seeing a patch of wet cement and realising that their handprint can be preserved for future generations to enjoy. Other projects suffer from such distrust, too, because even if they use “or any later version” to future-proof their licensing, they can be held back by the “only” crowd if they make use of that crowd’s software, rendering the licence upgrade option ineffective.
It is somewhat difficult to make licences that request that people play fair and at the same time do not require people to actually do anything to uphold that fairness, so when those who write the licences give some advice, it is somewhat impertinent to reject that advice and then to blame those very people for one’s own mistake later on. Even people who have done the recommended thing, but who suffer from “only” proliferation amongst the things on which their code depends should be blaming the people who put “only” everywhere, not the people who happened to write the licence in the first place.
A Political Movement
The article mentions that the GPL has become a “political platform”. But the whole notion of copyleft has been political from the beginning because it is all about a social contract between the developers and the end-users: not exactly the preservation of a monopoly on a creative work that the initiators of copyright had in mind. The claim is made that Apple shuns GPLv3 because it is political. In fact, companies like Apple and Nokia chiefly avoid GPLv3 because the patent language has been firmed up and makes those companies commit to not suing recipients of the code at will. (Nokia trumpeted a patent promise at one point, as if the company was exhibiting extreme generosity, but it turned out that they were obliged to license the covered patents because of the terms of GPLv2.) Apple has arguably only accepted the GPL in the past because the company could live with the supposed inconvenience of working with a wider development community on that community’s terms. As projects like WebKit have shown, even when obliged to participate under a copyleft licence, Apple can make collaboration so awkward that some participants (such as Google) would rather cultivate their own fork than deal with Apple’s obsession to control everything.
It is claimed that “the license terms are a huge problem for companies”, giving the example of Apple wanting to lock down their products and forbid anyone from installing anything other than Apple-approved software on devices that they have paid for and have in their own possession, claiming that letting people take control of their devices would obligate manufacturers to “get rid of the devices’ security systems”. In fact, it is completely possible to give the choice to users to either live with the restrictions imposed by the vendor and be able to access whichever online “app” store is offered by that vendor, or to let those users “root” or “jailbreak” their device and to tell them that they must find other sources of software and content. Such choices do not break any security systems at all, or at least not ones that we should be caring very much about.
People like to portray the FSF as being inflexible and opposed to the interests of businesses. However, the separation of the AGPL and the GPL contradicts such convenient assertions. Meanwhile, the article seems to suggest that we should blame the GPL for Apple’s inflexibility, which is, of course, absurd.
Blaming the Messenger
The article blames the AGPLv3 for the proliferation of “open core” business models. Pointing the finger at the licence and blaming it for the phenomenon is disingenuous since one could very easily concoct a licence that requires people to choose either no-cost usage, where they must share their code, or paid usage, where they get to keep their code secret. The means by which people can impose such a choice is their ownership of the code.
Although people can enforce an “open core” model more easily using copyleft licensing as opposed to permissive licensing, this is a product of the copyright ownership or assignment regime in place for a project, not something that magically materialises because a copyleft licence was chosen. It should be remembered that copyleft licences effectively regulate and work best with projects having decentralised ownership. Indeed, people have become more aware of copyright and licensing transfers and assignments perhaps as a result of “open core” business models and centralised project ownership, and they should be distrustful of commercial entities wanting such transfers and assignments to be made, regardless of any Free Software licence chosen, because they designate a privileged status in a project. Skepticism has even been shown towards the preference that projects transfer enforcement rights, if not outright ownership, to the FSF. Such skepticism is only healthy, even if one should probably give the FSF the benefit of the doubt as to the organisation’s intentions, in contrast to some arbitrary company who may change strategy from quarter to quarter.
The article also blames the GPLv3 or the AGPLv3 for the behaviour of “licence trolls”, but this is disingenuous. If Oracle offers a product with a choice of AGPLv3 or a special commercial licence, and if as a consequence those who want permissively licensed software for use in their proprietary products cannot get such software under permissive licences, it is the not the fault of any copyleft licence for merely existing: it is the fault (if this is even a matter of blame) of those releasing the software and framing the licence choices. Again, you do not need the FSF’s copyleft licences to exist to offer customers a choice of paying money or making compromises on how they offer their own work.
Of course, if people really cared about the state of projects that have switched licences, they would step up and provide a viable fork of the code starting from a point just before the licence change, but as can often be the case with permissively licensed software and a community of users dependent on a strong vendor, most people who claim to care are really looking for someone else to do the work so that they can continue to enjoy free gifts with as few obligations attached as possible. There are permissively licensed software projects with vibrant development communities, but remaining vibrant requires people to cooperate and for ownership to be distributed, if one really values community development and is not just looking for someone with money to provide free stuff. Addressing fundamental matters of project ownership and governance will get you much further than waving a magic wand and preferring permissive licensing, because you will be affected by those former things whichever way you decide to go with the latter.
Defining the New Normal
The article refers to BusyBox being “infamous” for having its licence enforced. That is a great way of framing reasonable behaviour in such a way as to suggest that people must be perverse for wanting to stand behind the terms under which, and mechanisms through which, they contributed their effort to a project. What is perverse is choosing a licence where such terms and mechanisms are defined and then waiving the obligation to defend it: it would not only be far easier to just choose another licence instead, but it would also be more honest to everyone wanting to use that project as well as everyone contributing to the project, too. The former group would have legal clarity and not the nods and winks of the project leadership; the latter group would know not to waste their time most likely helping people make proprietary software, if that is something they object to.
Indeed, when people contribute to a project it is on the basis of the social contract of the licence. When the licence is a copyleft licence, people will care whether others uphold their obligations. Some people say that they do not want the licence enforced on a project they contribute to. They have a right to express their own preference, but they cannot speak for everyone else who contributed under the explicit social contract that is the licence. Where even one person who has a contribution to a project sees their code used against the terms of the licence, that person has the right to demand that the situation be remedied. Denying individuals such rights because “they didn’t contribute very much” or “the majority don’t want to enforce the licence” (or even claiming that people are “holding the project to ransom”) sets a dangerous precedent and risks making the licence unenforceable for such projects as well as leaving the licence itself as a worthless document that has nothing to say about the culture or functioning of the project.
Some people wonder, “Why do you care what people do with your code? You have given it away.” Firstly, you have not given it away: you have shared it with people with the expectation that they will continue to share it. Copyleft licensing is all about the rights of the end-user, not about letting people do what they want with your code so that the end-user gets a binary dropped in their lap with no way of knowing what it is, what it does, or having any way of enjoying the rights given to the people who made that binary. As smartphone purchasers are discovering, binary-only shipments lead to unsustainable computing where devices are made obsolete not by fundamental changes in technology or physical wear and tear but by the unavailability of fixed, improved or maintained software that keep such devices viable.
Agreeing on the Licence
Disregarding the incompatibility between GPL versions, as discussed above, it appears more tempting to blame the GPL for situations of GPL-incompatibility than it does to blame other licences written after GPLv2 for causing such incompatibility in the first place. The article mentions that Sun deliberately made the CDDL incompatible with the GPL, presumably because they did not want people incorporating Solaris code into the GNU or Linux projects, thus maintaining that “competitive edge”. We all know how that worked out for Solaris: it can now be considered a legacy platform like AIX, HP-UX, and IRIX. Those who like to talk up GPL incompatibilities also like to overlook the fact that GPLv3 provides additional compatibility with other licences that had not been written in a GPLv2-compatible fashion.
The article mentions MoinMoin as being affected by a need for GPLv2 compatibility amongst its dependencies. In fact, MoinMoin is licensed under the GPLv2 or any later version, so those combining MoinMoin with various Apache Software Licence 2.0 licensed dependencies could distribute the result under GPLv3 or any later version. For those projects who stipulated GPLv2 only (against better advice) or even ones who just want the choice of upgrading the licence to GPLv3 or any later version, it is claimed that projects cannot change this largely because the provenance of the code is frequently uncertain, but the Mercurial project managed to track down contributors and relicensed to GPLv2 or any later version. It is a question of having the will and the discipline to achieve this. If you do not know who wrote your project’s code, not even permissive licences will protect you from claims of tainted code, should such claims ever arise.
The Fear Factor
Contrary to popular belief, all licences require someone to do (or not do) something. When people are not willing to go along with what a licence requires, we get into the territory of licence violation, unless people are taking the dishonest route of not upholding the licence and thus potentially betraying their project’s contributors. And when people fall foul of the licence, either inadvertently or through dishonesty, people want to know what might happen next.
It is therefore interesting that the article chooses to dignify claims of a GPL “death penalty”, given that such claims are largely made by people wanting to scare off others from Free Software, as was indeed shown when there may have been money and reputations to be made by engaging in punditry on the Google versus Oracle case. Not only have the actions taken to uphold the GPL been reasonable (contrary to insinuations about “infamous” reputations), but the licence revision process actually took such concerns seriously: version 3 of the GPL offers increased confidence in what the authors of the GPL family of licences actually meant. Obviously, by shunning GPLv3 and stipulating GPLv2 “only”, recipients of code licensed in such a way do not get the benefit of such increased clarity, but it is still likely that the fact that the licence authors sought to clarify such things may indeed weigh on interpretations of GPLv2, bringing some benefit in any case.
The Scapegoat
People like to invoke outrage by mentioning Richard Stallman’s name and some of the things he has said. Unfortunately for those people, Stallman has frequently been shown to be right. Interestingly, he has been right about issues that people probably did not consider to be of serious concern at the time they were raised, so that mentions of patents in GPLv2 not only proved to be far-sighted and useful in ensuring at least a workable level of protection for Free Software developers, but they also alerted Free Software communities, motivated people to resist patent expansionism, and predicted the unfortunate situation of endless, costly litigation that society currently suffers from. Such things are presumably an example of “specific usecases that were relevant at the time the license was written” according to the article, but if licence authors ignore such things, others may choose to consider them and claim some freedom in interpreting the licence on their behalf. In any case, should things like patents and buy-to-rent business models ever become extinct, a tidying up of the licence text for those who cannot bear to be reminded of them will surely do just fine.
Especially certain elements in the Python community seem to have a problem with Stallman and copyleft licensing, some blaming disagreements with, and the influence of, the FSF during the Python 1.6 licensing fiasco where the FSF rightly pointed out that references to venues (“Commonwealth of Virginia”) and having “click to accept” buttons in the licence text (with implicit acceptance through usage) would cause problems. Indeed, it is all very well lamenting that the interactions of licences with local law is not well understood, but one would think that where people have experience with such matters, others might choose to listen to such opinions.
It is a misrepresentation of Stallman’s position to claim that he wants strong copyright, as the article claims: in fact, he appears to want a strengthening of the right to share; copyleft is only a strategy to achieve this in a world with increasingly stronger copyright legislation. His objections to the Swedish Pirate Party’s proposals on five year copyright terms merely follow previous criticisms of additional instruments – in this case end-user licence agreements (EULAs) – that allow some parties to circumvent copyright restrictions on other people’s work whilst imposing additional restrictions – in previous cases, software patents – on their own and others’ works. Finding out what Stallman’s real position might require a bit of work, but it isn’t secret and in fact even advocates significantly reduced copyright terms, just as the Pirate Party advocates. If one is going to describe someone else’s position on a topic, it is best not to claim anything at all if the alternative is to just make stuff up instead.
The article ramps up the ridicule by claiming that the FSF itself claims that “cloud computing is the devil, cell phones are exclusively tracking devices”. Ridiculing those with legitimate concerns about technology and how it is used builds a culture of passive acceptance that plays into the hands of those who will exploit public apathy to do precisely what people labelled as “paranoid” or “radical” had warned everyone about. Recent events have demonstrated the dangers of such fashionable and conformist ridicule and the complacency it builds in society.
All Things to All People
Just as Richard Stallman cannot seemingly be all things to all people – being right about things like the threat of patents, for example, is just so annoying to those who cannot bring themselves to take such matters seriously – so the FSF and the GPL cannot be all things to all people, either. But then they are not claiming to be! The FSF recognises other software licences as Free Software and even recommends non-copyleft licences from time to time.
For those of us who prefer to uphold the rights of the end-user, so that they may exercise control over their computing environment and computing experience, the existence of the GPL and related copyleft licences is invaluable. Such licences may be complicated, but such complications are a product of a world in which various instruments are available to undermine the rights of the end-user. And defining a predictable framework through which such licences may be applied is one of the responsibilities that the FSF has taken upon itself to carry out.
Indeed, few other organisations have been able to offer what the FSF and closely associated organisations have provided over the years in terms of licensing and related expertise. Maybe such lists of complaints about the FSF or the GPL are a continuation of the well-established advertising tradition of attacking a well-known organisation to make another organisation or its products look good. The problem is that nobody really looks good as a result: people believe the bizarre insinuations of political propaganda and are less inclined to check what the facts say on whichever matter is being discussed.
People are more likely to make bad choices when they have only been able to make uninformed choices. The article seeks to inform people about some of the practicalities of licence compatibility but overemphasises sources with an axe to grind – and, in some cases, sources with rather dubious motivations – that are only likely to drive people away from reliable sources of information, filling the knowledge gap of the reader with innuendo from third parties instead. If the intention is to promote permissive licensing or merely licences that are shorter than the admittedly lengthy GPL, we would all be better served if those wishing to do so would stick to factual representations of both licensing practice and licence author intent.
And as for choosing a licence, some people have considered such matters before. Seeking to truly understand licences means having all the facts on the table, not just the ones one would like others to consider combined with random conjecture on the subject. I hope I have, at least, brought some of the missing facts to the table.
Ubuntu Edge: Making Things Even Harder for Open Hardware?
July 24th, 2013
The idea of a smartphone supportive of Free Software, using hardware that can be supported using Free Software, goes back a few years. Although the Openmoko Neo 1973 attracted much attention back in 2007, not only for its friendliness to Free Software but also for the openness around its hardware design, the Trolltech Greenphone had delivered, almost a full year before the Neo, a hardware platform that ran mostly Free Software and was ultimately completely supported using entirely Free Software (something that had been a matter of some earlier dispute). Unfortunately, both of these devices were discontinued fairly quickly: the Greenphone was more a vehicle to attract interest in the Qt-based Qtopia environment amongst developers, existing handset manufacturers and operators, and although the Neo 1973 was superseded by the Neo FreeRunner, the commercial partner of the endeavour eventually chose to abandon development of the platform and further products of this nature. (Openmoko now sells a product called WikiReader, which is an intriguing concept in itself, principally designed as an offline reader for Wikipedia.)
What survived the withdrawal of Openmoko from the pursuit of the Free Software smartphone was the community or communities around such work, having taken an active interest in developing software for such devices and having seen the merits of being able to influence the design of such devices through the principles of open hardware. Some efforts were made to continue the legacy: the GTA04 project develops and offers replacement hardware for the FreeRunner (known as GTA02 within the Openmoko project) using updated and additional components; a previous “gta02-core” effort attempted to refine the development process and specification of a successor to the FreeRunner but did not appear to produce any concrete devices; a GTA03 project which appeared to be a more participative continuation of the previous work, inviting the wider community into the design process alongside those who had done the work for the previous generations of Neo devices, never really took off other than to initiate the gta02-core effort, perhaps indicating that as the commercial sponsor’s interest started to vanish, the community was somewhat unreasonably expected to provide the expertise withdrawn by the sponsor (which included a lot of the hardware design and manufacturing expertise) as well as its own. Nevertheless, there is a degree of continuity throughout the false starts of GTA03 and gta02-core through to GTA04 and its own successes and difficulties today.
Then and Now
A lot has happened in the open hardware world since 2007. Platforms like Arduino have become very popular amongst electronics enthusiasts, encouraging the development of derivatives, clones, accessories and an entire marketplace around experimentation, prototyping and even product development. Other long-established microcontroller-based solution vendors have presumably benefited from the level of interest shown towards Arduino and other “-duino” products, too, even if those solutions do not give customers the right to copy and modify the hardware as Arduino does with its hardware licensing. Access to widely used components such as LCD panels has broadened substantially with plenty of reasonably priced products available that can be fairly easily connected to devices like the Arduino, BeagleBoard, Raspberry Pi and many others. Even once-exotic display technologies like e-paper are becoming accessible to individuals in the form of ready-to-use boards that just plug into popular experimenter platforms.
Meanwhile, more sophisticated parts of the open hardware world have seen their own communities develop in various ways. One community emerging from the Openmoko endeavour was Qi-Hardware, supported by Sharism who acquired the rights to produce the Ben NanoNote from the vendor of an existing product, thus delivering a device with completely documented electronics hardware, every aspect of which can be driven by Free Software. Unfortunately, efforts to iterate on the concept stalled after attempts to make improved revisions of the Ben, presumably in preparation to deliver future versions of the NanoNote concept. Another project founded under the Qi-Hardware umbrella has been extending the notion of “copyleft hardware” to system on a chip (SoC) solutions and delivering the Milkymist platform in the shape of the Milkymist One video synthesizer. Having dealt with commercially available but proprietary SoC solutions, such as the SoC used in the Ben NanoNote, there appears to be a desire amongst some to break free of the dependency on silicon vendors and their often poorly documented products and to take control not only of the hardware using Free Software tools, but also to decide how the very hardware platform itself is designed and built.
There are plenty of other hardware development initiatives taking place – OpenPandora, the EOMA-68 initiative, the Vivaldi KDE tablet (which is now going to be based on EOMA-68 hardware), the Novena open laptop – many of which have gained plenty of experience – sometimes very hard-earned experience – in getting hardware designed and produced. Indeed, the history of the Vivaldi initiative seems to provide a good illustration of how lessons that others have already learned are continuing to be learned independently: having negotiated manufacturing whilst suffering GPL-violating industry practices, the manufacturer changed the specification and rendered a lot of the existing work useless (presumably the part supporting the hardware with Free Software drivers).
In short, if you are considering designing a device “to run Linux”, the chances are that someone else is already doing just that. When people suggest that you look at various other projects or initiatives, they are not doing so to inflate the reputation of those projects: it is most likely the case that people associated with those projects can give you advice that will save you time and effort, even if there is no further collaboration to be had beyond exchanges of useful information.
The Competition for Attention
Ubuntu Edge – the recently announced, crowd-funded “dockable” smartphone – emerges at a time when there are already many existing open hardware projects in need of funding. Those who might consider supporting such worthy efforts may be able to afford supporting more than one of them, but they may find it difficult to justify doing so. Precious few details exist of the hardware featured in the Ubuntu Edge product, and it would be reasonable to suspect given the emphasis on specifications and features that it will not be open hardware. Moreover, given the tendency of companies wishing to enter the smartphone market to do so as conveniently as possible by adopting the “chipset of the month”, combined with the scarcity of silicon favouring true Free Software support, we might also suspect that the nature of the software support will be less than what we should be demanding: the ability to modify and maintain the software in order to use the hardware indefinitely and independently of the vendor.
Meanwhile, other worthy projects beyond the open hardware realm compete for the money of potential sponsors and donors. The Fairphone initiative has also invited people to pledge money towards the delivery of devices, although in a more tangible fashion than Ubuntu Edge, with genuine plans having been made for raw materials sourcing and device manufacture, and with software development supposedly undertaken on behalf of the project. As I noted previously, there are some unfortunate shortcomings with the Fairphone initiative around the openness of the software, and unless the participants are able to change the mindset of the chipset vendor and the suppliers of various technologies incorporated into the chipset, sustainable Free Software support may end up being dependent on reverse-engineering efforts. Mozilla’s Firefox OS, meanwhile, certainly emphasises a Free Software stack along with free and open standards, but the status of the software support for certain hardware functions are likely to be dependent on the details of the actual devices themselves.
Interest in open phones is not new, nor even is interest in “dockable” smartphones, and there are plenty of efforts to build elements of both while upholding Free Software support and even the principles of open hardware. Meanwhile, the Ubuntu Edge campaign provides no specifics about the details of the hardware; it is thus unable to make any commitment about Free Software drivers or binary firmware “blobs”. Maybe the intention is to one day provide things like board layouts and case designs as resources for further use and refinement by the open hardware community, but the recent track-record of Canonical and Ubuntu with secretive and divisive – or at least not particularly transparent or cooperative – product development suggests that this may be too much to hope.
Giving the Gift
$32 million is a lot of money. Broken into $600 chunks with the reward of the advertised device, or a consolation prize of your money back minus a few percent in fees and charges if the fund-raising campaign fails to reach its target, it is a lot of money for an individual, too. (There is also the worst-case eventuality that the target is met but the product is not delivered, at which point everybody might have found that they have merely made a donation towards a nice but eventually unrealisable or undeliverable idea.) One could do quite a bit of good work with even small multiples of $600, and with as much as around 0.5% of the Ubuntu Edge campaign target, one could fund something like the GCW Zero. That might not aggressively push back the limits of mobile technology on every front, but it gives people something different and valuable to them while still leaving plenty of money floating around looking for a good cause.
But it is not merely about the money, even though many of those putting down money for the Ubuntu Edge are likely to have ruled out doing the same for the Fairphone (and perhaps some of those who have ordered their Fairphone regret placing their order now that the Ubuntu Edge has made its appearance), purely because they neither need nor can reasonably afford or justify buying two new smartphones for delivery at some point in the future. The other gift that could be given is collaboration and assistance to the many projects already out there toiling to put Linux on some SoC or other, developing an open hardware design for others to use and improve, and deepening community expertise that might make these challenges more tolerable in the future.
Who knows how the Ubuntu Edge will be developed if or when the funding target is reached, or regardless of it being reached? But imagine what it would be like if such generosity could be directed towards existing work and if existing and new projects were able to work more closely with each other; if the expertise in different projects could be brought in to make some new endeavour more likely to succeed and less fraught with problems; if communities were included, encouraged to participate, and encouraged to take their own work further to enrich their own project and improve any future collaborations.
Investing, not Purchasing
$32 million is a lot of money. Less exciting things (to the average gadget buyer) like the OpenRISC funding drive to produce an ASIC version of an open hardware SoC wanted only $250000 – still a lot of money, but less than 1% of the Ubuntu Edge campaign target – and despite the potential benefits for both individuals and businesses it still fell far short of the mark, but if such projects were funded they might open up opportunities that do not exist now and would probably still not exist if Ubuntu got their product funded. And there are plenty of other examples where donations are more like investments in a sustainable future instead of one-off purchases of nice-looking gadgets.
Those thinking about making a Free Software phone might want to check in with the GTA04 project to see if there is anything they can learn or help out with. Similarly, that project could perhaps benefit from evaluating the EOMA-68 initiative which in turn could consider supporting genuinely open SoCs (and also removing the uncertainty about patent assertion for participants in the initiative by providing transparent governance mechanisms and not relying on the transient goodwill of the current custodians). As expertise is shared and collaboration increases, the money might start to be spread around a bit more as well, and cash-starved projects might be able to do things before those things become less interesting or even irrelevant because the market has moved on.
We have to invest both financially and collaboratively in the good work already taking place. To not do so means that opportunities that are almost within our grasp are not seized, and that people who have worked hard to offer us such opportunities are let down. We might lose the valuable expertise of such people through pure disillusionment, and yet the casual observer might still wonder when we might see the first fully open, Free Software friendly, mass-market-ready smartphone, thinking it is simply beyond “the community” to deliver. In fact, we might be letting the opportunity to deliver such things pass us by more often than we realise, purely out of ignorance of the ongoing endeavours of the community.
Diversions and Distractions
Ubuntu Edge sounds exciting. It is just a shame that it does not appear to enable and encourage everyone who has already been working to realise such ambitions on substantially lower budgets and with less of a brand reputation to cultivate the interest of the technology media and enthusiastic consumers. Millions of dollars of committed funds and an audience preferring to take the passive position of expectant customers, as opposed to becoming active contributors to existing efforts, all adds up to a diversion of participation and resources from open hardware projects.
Such blockbuster campaigns may even distract from open hardware projects because for those who might need slight persuasion to get involved, the apparition of an easy solution demanding only some spare cash and no intellectual investment may provide the discouragement necessary to affirm that as with so many other matters, somebody else has got them covered. Consequently, such people retreat from what might have been a rewarding pursuit that deepens their understanding of technology and the issues around it.
Not everyone has the time or inclination to get involved with open hardware, of course, especially if they are starting with practically no knowledge of the field. But with many people and their green pieces of paper parked and waiting for Ubuntu Edge, it is certainly possible to think that the campaign might make things even harder for the open hardware movement to get the recognition and the traction it deserves.