Paul Boddie's Free Software-related blog
Paul's activities and perspectives around Free Software
Making the Best of a Bad Deal
January 7th, 2015
I had the opportunity over the holidays to browse the January 2015 issue of “Which?” – the magazine of the Consumers’ Association in Britain – which, amongst other things, covered the topic of “technology ecosystems“. Which? has a somewhat patchy record when technology matters are taken into consideration: on the one hand, reviews consider the practical and often mundane aspects of gadgets such as battery life, screen brightness, and so on, continuing their tradition of giving all sorts of items a once over; on the other hand, issues such as platform choice and interoperability are typically neglected.
Which? is very much pitched at the “empowered consumer” – someone who is looking for a “good deal” and reassurances about an impending purchase – and so the overriding attitude is one that is often in evidence in consumer societies like Britain: what’s in it for me? In other words, what goodies will the sellers give me to persuade me to choose them over their competitors? (And aren’t I lucky that these nice companies are throwing offers at me, trying to win my custom?) A treatment of ecosystems should therefore be somewhat interesting reading because through the mere use of the term “ecosystem” it acknowledges that alongside the usual incentives and benefits that the readership is so keen to hear about, there are choices and commitments to be made, with potentially negative consequences if one settles in the wrong ecosystem. (Especially if others are hell-bent on destroying competing ecosystems in a “war” as former Nokia CEO Stephen Elop – now back at Microsoft, having engineered the sale of a large chunk of Nokia to, of course, Microsoft – famously threatened in another poor choice of imagery as part of what must be the one of the most insensitively-formulated corporate messages of recent years.)
Perhaps due to the formula behind such articles in Which? and similar arenas, some space is used to describe the benefits of committing to an ecosystem. Above the “expert view” describing the hassles of switching from a Windows phone to an Android one, the title tells us that “convenience counts for a lot”. But the article does cover problems with the availability of applications and services depending on the platform chosen, and even the matter of having to repeatedly buy access to content comes up, albeit with a disappointing lack of indignance for a topic that surely challenges basic consumer rights. The conclusion is that consumers should try and keep their options open when choosing which services to use. Sensible and uncontroversial enough, really.
The Consequences of Apathy
But sadly, Which? is once again caught in a position of reacting to technology industry change and the resulting symptoms of a deeper malaise. When reviewing computers over the years, the magazine (and presumably its sister publications) always treated the matter of platform choice with a focus on “PCs and Macs” exclusively, with the latter apparently being “the alternative” (presumably in a feeble attempt to demonstrate a coverage of choice that happens to exist in only two flavours). The editors would most likely protest that they can only cover the options most widely available to buy in a big-name store and that any lack of availability of a particular solution – say, GNU/Linux or one of the freely available BSDs – is the consequence of a lack of consumer interest, and thus their readership would also be uninterested.
Such an unwillingness to entertain genuine alternatives, and to act in the interests of members of their audience who might be best served by those solutions, demonstrates that Which? is less of a leader in consumer matters than its writers might have us believe. Refusing to acknowledge that Which? can and does drive demand for alternatives, only to then whine about the bundled products of supposed consumer interest, demonstrates a form of self-imposed impotence when faced with the coercion of proprietary product upgrade schedules. Not everyone – even amongst the Which? readership – welcomes the impending vulnerability of their computing environment as another excuse to go shopping for shiny new toys, nor should they be thankful that Which? has done little or nothing to prevent the situation from occurring in the first place.
Thus, Which? has done as much as the rest of the mainstream technology press to unquestioningly sustain the monopolistic practices of the anticompetitive corporate repeat offender, Microsoft, with only a cursory acknowledgement of other platforms in recent years, qualified by remarks that Free Software alternatives such as GNU/Linux and LibreOffice are difficult to get started with or not what people are used to. After years of ignoring such products and keeping them marginalised, this would be the equivalent of denying someone the chance to work and then criticising them for not having a long list of previous employers to vouch for them on their CV. Noting that 1.1-billion people supposedly use Microsoft Office (“one in seven people on the planet”) makes for a nice statistic in the sidebar of the print version of the article, but how many people have a choice in doing so or, for that matter, in using other Microsoft products bundled with computers (or foisted on office workers or students due to restrictive or corrupt workplace or institutional policies)? Which? has never been concerned with such topics, or indeed the central matter of anticompetitive software bundling, or its role in the continuation of such practices in the marketplace: strange indeed for a consumer advocacy publication.
At last, obliged to review a selection of fundamentally different ecosystem choices – as opposed to pretending that different vendor badges on anonymous laptops provide genuine choice – Which? has had to confront the practical problems brought about by an absence of interoperability: that consumers might end up stranded with a large, non-transferable investment in something they no longer wish to be a part of. Now, the involvement of a more diverse selection of powerful corporate interests have made such matters impossible to ignore. One gets the impression that for now at least, the publication cannot wish such things away and return to the lazy days of recommending that everyone line up and pay a single corporation their dues, refusing to believe that there could be anything else out there, let alone usable Free Software platforms.
Beyond Treating the Symptoms
Elsewhere in the January issue, the latest e-mail scam is revealed. Of course, a campaign to widen the adoption of digitally-signed mail would be a start, but that is probably too much to expect from Which?: just as space is dedicated to mobile security “apps” in this issue, countless assortments of antivirus programs have been peddled and reviewed in the past, but solving problems effectively requires a leader rather than a follower. Which? may do the tedious job of testing kettles, toasters, washing-up liquids, and much more to a level of thoroughness that would exhaust most people’s patience and interest. And to the publication’s credit, a certain degree of sensible advice is offered on topics such as online safety, albeit with the usual emphasis on proprietary software for the copy of Windows that members of its readership were all forced to accept. But in technology, Which? appears to be a mere follower, suggesting workarounds rather than working to build a fair market for safe, secure and interoperable products.
It is surely time for Which? to join the dots and to join other organisations in campaigning for fundamental change in the way technology is delivered by vendors and used throughout society. Then, by upholding a fair marketplace, interoperability, access to digital signature and encryption technologies, true ownership of devices and of purchased content, and all the things already familiar to Free Software and online rights advocates, they might be doing their readership a favour after all.
Python’s email Package and the “PGP/MIME” Question
January 7th, 2015
I vaguely follow the development of Mailpile – the Free Software, Web-based e-mail client – and back in November 2014, there was a blog post discussing problems that the developers had experienced while working with PGP/MIME (or OpenPGP as RFC 3156 calls it). A discussion also took place on the Gnupg-users mailing list, leading to the following observation:
Yes, Mailpile is written in Python and I've had to bend over backwards in order to validate and generate signatures. I am pretty sure I still have bugs to work out there, trying to compensate for the Python library's flaws without rewriting the whole thing is, long term, a losing game. It is tempting to blame the Python libraries, but the fact is that they do generate valid MIME - after swearing at Python for months, it dawned on me that it's probably the PGP/MIME standard that is just being too picky.
Later, Bjarni notes…
Similarly, when generating messages I had to fork the Python lib's generator and disable various "helpful" hacks that were randomly mutating the behavior of the generator if it detected it was generating an encrypted message!
Coincidentally, while working on PGP/MIME messaging in another context, I also experienced some problems with the Python email package, mentioning them on the Mailman-developers mailing list because I had been reading that list and was aware that a Google Summer of Code project had previously been completed in the realm of message signing, thus offering a potential source of expertise amongst the list members. Although I don’t think I heard anything from the GSoC participant directly, I had the benefit of advice from the same correspondent as Bjarni, even though we have been using different mailing lists!
Here‘s what Bjarni learned about the “helpful” hacks:
This is supposed to be http://bugs.python.org/issue1670765, which is claimed to be resolved.
Unfortunately, the special-case handling of headers for “multipart/signed” parts is presumably of limited “help”, and other issues remain. As I originally noted…
So, where the email module in Python 2.5 likes to wrap headers using tab character indents, the module in Python 2.7 prefers to use a space for indentation instead. This means that the module reformats data upon being asked to provide a string representation of it rather than reporting exactly what it received.
Why the special-casing wasn’t working for me remains unclear, and so my eventual strategy was to bypass the convenience method in the email API in order to assert some form of control over the serialisation of e-mail messages. It is interesting to note that the “fix” to the Python standard library involved changing the documentation to note the unsatisfactory behaviour and to leave the problem essentially unsolved. This may not have been unreasonable given the design goals of the email package, but it may have been better to bring the code into compliance with user expectations and to remedy what could arguably be labelled a design flaw of the software, even if it was an unintended one.
Contrary to the expectations of Python’s core development community, I still develop using Python 2 and probably won’t see any fixes to the standard library even if they do get made. So, here’s my workaround for message serialisation from my concluding message to the Mailman-developers list:
# given a message... out = StringIO() generator = Generator(out, False, 0) # disable reformatting measures generator.flatten(message) # out.getvalue() now provides the serialised message
It’s interesting to see such problems occur for different people a few months apart. Maybe I should have been following Mailpile development a bit more closely, but with it all happening at GitHub (with its supposedly amazing but, in my experience, rather sluggish and clumsy user interface), I suppose I haven’t been able to keep up.
Still, I hope that others experiencing similar difficulties become more aware of the issues by seeing this article. And I hope that Bjarni and the Mailpile developers haven’t completely given up on OpenPGP yet. We should all be working more closely together to get usable, Free, PGP-enabled, standards-compliant mail software to as many people as possible.
A Note on Kolab and Debian Packaging
December 19th, 2014
I thought it might be helpful if I wrote a quick note about my previous work on Debian packaging and Kolab. As my blog can attest, I have written a few articles about packaging and the effort required to make Kolab somewhat more amenable to a convenient and properly functioning installation on Debian systems. Unfortunately, perhaps due to a degree of overambition and perhaps due to me being unable to deliver a convincing and/or palatable set of modifications to achieve these goals, no progress was made over the year or so I spent looking at the situation. I personally do not feel that there was enough of a productive dialogue about aligning these goals with those of the core developers of Kolab, and despite a certain level of interest from others, I no longer have the motivation to keep working on this problem.
Occasionally, I receive mails from people who have read about my experiments with Debian packaging or certain elements of Kolab configuration that became part of the packaging work. This message is intended to communicate that I am no longer working on such things. Getting Kolab to work with other mail transport/delivery/storage systems or other directory systems is not particularly difficult for those with enough experience (and I am a good example of someone who has been able to gain that experience relatively quickly), but integrating this into setup-kolab in an acceptable fashion ultimately proved to be an unrealisable goal.
Other people will presumably continue their work packaging various Kolab libraries for Debian, and some of these lower-level packages may even arrive in the stable release of Debian fairly soon, perhaps even delivering a recent version of those libraries. I do not, however, see any progress on getting other packages into Debian proper. I continue to have the opinion that this unfortunate situation will limit wider adoption of the Kolab technologies and does nobody but the proprietary competition any good.
Since I do not believe in writing software that will never be used – having had that experience in a professional setting where I at least had the consolation of getting paid for such disappointing outcomes (and for the waste of my time) – my current focus is on developing a low-impact form of standards-based calendaring for existing mail systems, without imposing extensive infrastructure requirements when adopting such a solution, and I hope to have something useful to show in the fairly near future. This time last year, I was much more upbeat about the prospect of getting Kolab into Debian and into more people’s hands. Now, I only wish that I had changed course earlier and started on my current endeavour considerably sooner.
But as people like to say: better late than never. I look forward to sharing my non-Kolab groupware developments in the coming months.
People and their Walled Gardens
December 15th, 2014
I wasn’t the only one to notice a discussion about moving Python-related resources to GitHub recently. An article on LWN covered the matter and was followed by the usual assortment of comments, but having expected the usual expression of sentiments about how people should supposedly all migrate to Git (something I completely disagree with for a number of reasons), what I found surprising was a remark indicating that some people use GitHub as their “one stop” source of code for any project they might wish to use. In other words, GitHub is their “App Store”, curated experience, or “walled garden”: why should they bother with the rest of the Internet?
Of course, one could characterise such an interpretation of their remark as being somewhat unfair: after all, the author of the comment is not pushing their comment to GitHub to be magically pulled by LWN and published in a comment thread; they must therefore be actively using other parts of the Internet, too. But the “why bother with anything else?” mentality is worrying: demanding that everybody use a particular Internet site for their work to be considered as being something of value undermines freedom of choice, marginalises those who happen to prefer other solutions, and, in this case, cultivates a dependency on a corporate entity whose activities may not always prove to be benign. Corporate gatekeepers frequently act in ways that provoke accusations of censorship or of holding their users to ransom.
Sweetening a Bitter Pill
Many people seem to be infatuated with GitHub, perhaps because it offers conveniences that might make Git more bearable to use. I personally find Git’s command line interface to be incoherent in comparison to other tools, and despite praise of tools like gitk by Git advocates (with their claims of superior Git tooling), I find that things like the graphlog feature in Mercurial give me, in that particular instance, a proper graphical history at the command line in an instant, without messing around with some clumsy Tk-based interface with a suboptimal presentation of the different types of information (and I could always use things like TortoiseHg if I really wanted a graphical user interface myself). So maybe I wouldn’t see the point of a proprietary Web-based interface to use with Mercurial, especially since the built-in Web interface is pretty good and is in many ways better than attempts to provide similar functionality in a tool-neutral way.
People do seem rather willing to discard many of the benefits of the distributed nature of Git and are quite happy to have a single point of failure in their projects and businesses: when GitHub becomes unreachable in such environments, everything grinds to a halt, despite the fact that they all sit there with the code and could interact with each other directly. Popularity and the “network effect” seem to be the loudest arguments in favour of dumping all their code on some distant servers, with the idea being that “social” project hosting will bring in the contributors. Although I accept that for potential contributors who have no convenient way of hosting their own code, such services provide an obvious solution – “fork” the project, pull, make changes, push, dispatch a “pull request” – and allow them to avoid having to either provide hosting for their own code themselves or to coordinate their work in other ways, everything now has to go through the same infrastructure and everyone now has to sign up for the same service, adhere to the same terms and conditions, and risk interruptions to their work caused by anything from downtime and communications failures to the consequences of litigation or such services being obvious targets for criminal or politically-motivated misbehaviour. Not only do the custodians of a project no longer control their own project, but they also put that project at considerable risk.
Perhaps all the risks would be worth it if “going social” attracted contributors. When looking at project-hosting sites, I tend to see numerous forks of project code that mostly seem to have been created enthusiastically at some point in time, only to now be dormant and have seen no actual changes committed at all: whether the user concerned created a fork in an aspirational moment not unlike making a New Year’s resolution, or whether they have done it to demonstrate their supposed credibility (“look at me: I forked the Linux kernel!”), neither kind of motivation is helping such projects get any contributions of value. Making things easier is not a bad idea in itself, nor is getting the attention of the right people. The issue here is whether one finds the right people on such project-hosting sites, or whether one merely finds a lot of people who aspire to do something but who will still do very little regardless of how easy it supposedly is.
Body of Convenience
Although the original discussion is mostly concerned with the core development of the CPython implementation and the direction of the Python language, it is hard to separate the issues involved from the activities of the Python Software Foundation. Past experience suggests that some people involved with both of these things do not seem to prioritise ethical concerns – it is no coincidence that the word “pragmatic” appears in the LWN coverage – and it disappoints me greatly that when ethical concerns about GitHub’s corporate culture were raised, few people seemed interested in taking them into consideration. Once again, the label of “ideology” is wielded, together with the idea that doing the right thing is too complicated and therefore not worth pursuing at all, leading to the absurd conclusion that it is better to favour the party shown to have done wrong over all other parties who, as far as we know, have not done any wrong but should be suspected of it, anyway.
With the PSF taking diversity and equal opportunities seriously, one might expect people to “join the dots” on this matter and for people to be engaged in showing that the organisation is unconditionally committed to such causes and is willing to use its public influence for the common good, but I suppose that since GitHub is not a “Python company” anyone with a problem with the corporate culture in question is simply out of luck. Once again, ethics stand in the way of the toys, and “pragmatism” is a nice term to use to indicate that the core Python development community and the organisation that supports it should have as narrow a focus as possible, even if that means neglecting the social movements that brought about the environment that enabled Python to become the successful technology that it is today.
(The matter at the centre of those ethical concerns was wrapped up either definitively or inconclusively depending on who you wish to believe and how credible you regard the company’s own review of the matter to be. This article does not intend to express a view on that matter itself, but does stress that where ethical concerns have been raised, those concerns should be addressed and not ignored.)
Easy Way Out
Python is getting a lot of competition from other technologies these days. For example, Google’s Go stole some thunder from Python both within the company and elsewhere, and there are people who admit to switching to Go in order to remedy some of the long-standing issues they experienced with Python implementations (mostly related to performance and scalability). As I noted before, had Python implementations, libraries and the language definition been improved to alleviate concerns about Python’s suitability in various domains, Python would be in a stronger position than it is now: a position which arguably resembles that of Perl at the height of its popularity. Sure, choosing Python for your next project in certain domains is an easy decision (just as Perl devotees used to annoyingly insist that people just “use Perl”), but there are plenty of other areas where Python has more or less forfeited the contest: how is Python doing on Android, for instance? People who do Python or Django all-day-every-day may not see a problem, but that doesn’t mean that there isn’t a fundamental problem waiting for a remedy.
It is understandable that people want to play the popularity card: if there’s an easy way of clawing back the masses, why not play it? Unfortunately, there may not be an easy way. Catching up with the development backlog may actually be achieved more effectively by addressing other shortcomings of the development workflow. And there’s an assumption that a crowd of ready-to-start contributors are lurking on GitHub when, despite the aforementioned evidence of people only wanting to play inside the walled garden, anyone sufficiently motivated to improve Python would surely have moved beyond a consumer mindset and would have sought out the development community already.
Python development is a relatively well-resourced activity compared to many voluntary endeavours, and the PSF is responsible for much of the infrastructure that supports the developer communities around Python. Although many benefits are derived from things like the mailing lists hosted at python.org, there are always those who are enticed by other providers and technological platforms. In matters relating to the PSF, the occasional Google spreadsheet or form has been circulated, much to the dismay of some people who would rather not have to use online resources that may require a Google account (and if not that, then maybe a fast computer and cheap energy to power all the JavaScript). Bringing up additional PSF-driven services requires time and effort that may be in short supply (as I have experienced in recent months, despite the help of various stalwarts of the community, including one kind enough to drop my name into this particular debate!), and efforts to just procure help and bypass the community have arguably caused an even greater burden on volunteers, even leading to matters as severe as the temporary abandonment of valuable resources such as the Python Job Board (out of action since February 2014).
Concerns about the future relevance and popularity of Python itself may not be so easily addressed and overcome, but that is a topic for another time. But the task of rebalancing relationships – between the PSF, the core developers, and the community volunteers who keep the wheels turning on the Python online assets – is one that cannot be ignored, either. And retreating to the comfort of today’s favourite walled gardens is perhaps too much of an easy way out that ignores the lessons of the past (despite assertions to the contrary) and leaves such relationships in their current, somewhat precarious state, undermining those trying to uphold the independence and viability of the initiative, potentially causing even more work and inconvenience for infrastructure volunteers, presenting an incoherent collection of project resources to contributors, all in the vague hope of grabbing the attention of people who cannot otherwise be relied upon to look further than the ends of their own noses.
Maybe people should be looking for more substantial remedies than quick fixes in walled gardens to address Python’s contribution, popularity and development issues.
The Unplanned Obsolescence of the First Fairphone Device
December 12th, 2014
About a year-and-a-half ago, I gave my impressions of the Fairphone, noting that the initiative was worthy in terms of its social and sustainability goals, but that it had neglected the “fairness” of the software to be provided with each device. Although the Fairphone organisation had made “root access” – or more correctly stated, “owner control” – of the device a priority and had decided to provide its user interface enhancements to Android as Free Software, it had chosen to use a set of hardware technologies with a poor record of support for Free Software.
It might be said that such an initiative cannot possibly hope to act in the most prudent manner in every respect. However, unlike expertise in minerals sourcing, complicated global supply chains, and proprietary manufacturing activities, expertise on matters of hardware support for Free Software is available almost in abundance to anyone who can be bothered to ask. Many people already struggle with poorly-supported hardware for which only binary firmware or driver releases are available from the manufacturer, often resulting in incorrectly-performing hardware with no chance of future fixes as the manufacturer discontinues support in order to focus on selling new products. Others struggle with continuing but inconvenient forms of support on the manufacturer’s own timescale and terms.
Consequently, there are increasing numbers of people with experience of reverse engineering, documenting, and reimplementing firmware and drivers for proprietary hardware, many of whom would only be too happy to share their experiences with others wishing to avoid the pitfalls of being tied to a proprietary hardware vendor with a proprietary software mentality. There are also communities developing open hardware who seek out enlightened hardware vendors that encourage Free Software drivers for their products and may even support firmware that is also Free Software on their devices. There are even people developing smartphones in the open whose experiences and opinions would surely be valuable to anyone needing advice on the more reliable, open and trustworthy hardware vendors.
One community that has remained active despite various setbacks is the one pursuing the development of the EOMA-68 modular computing platform. It was precisely this kind of “ODM versus chipset vendor versus Free Software community” circus that prompted the development of an open platform and attempts to reach out and cultivate constructive communications with various silicon vendors. Such vendors, notably Allwinner Technology (in the case of EOMA-68), but also other companies that have previously been open to dialogue, have had the realisation that Free Software is an asset, and that Free Software communities are their partners and not just a bunch of people whose work can be taken and used without paying attention to the terms under which that work was originally shared. Such dialogues are ongoing and are subject to setbacks as well as progress, but it is far better to cultivate good practices than to ignore bad practices and to dump the ugly result onto the end-user.
Now, the Fairphone organisation has started to reconsider the software issue in light of the real possibility that their device will not be upgradeable beyond an old release of Android:
“We are actively looking at ways to achieve this goal, but we’re trying to be realistic and face the fact that the first Fairphones will most likely not be upgraded beyond Android 4.2.”
Given that the viability of devices depends not only on the continued functioning of the hardware but also the correct functioning of the software, and that one motivation that many people have stated for upgrading their phone is to gain access to a supported operating system distribution and/or one that supports applications they need or desire, the unfortunate neglect of software sustainability has undermined the general sustainability of the device. It may very well be the case that the Fairphone organisation’s initiatives around re-use and recycling can mitigate the problems caused by any abandonment of these devices, as people seek out replacements that do what they demand of them, but one of the most potent goals of reducing consumption by providing a long-lasting device has been undermined by something that should be the easiest part of the product to change, maintain, upgrade and even to remedy shortcomings with the chosen physical components; something whose lifespan is dictated far less by physical constraints than the assembly of physical components making up the device itself.
It is quite possible that certain industry practices have remained unknown to the Fairphone organisation, despite bitter experiences elsewhere, and that they are only now catching up with what many other people have learned over the years:
“Our chipset vendor MediaTek is only publicly releasing what it is bound to by the obligatory terms of the GNU public license GPL (the Linux Kernel and a few userland programs) and has chosen not to release any of the Android source code.”
Once again, the GPL demonstrates its worth as a necessary tool to ensure that the end-user remains in control. Unfortunately, Google decided that the often shoddy practices of its hardware and industry partners should be indulged by allowing them to make proprietary products with Google’s permissively-licensed code. It could be worse: some hardware vendors violate the GPL and blame their suppliers, requiring anyone seeking recourse to traverse the supply chain as far as it goes, potentially to some obscure company in a faraway land whose management plead poverty while actually doing very nicely selling their services to anyone willing to pay; others just appear to brazenly violate the GPL and dare someone to sue them.
The Fairphone organisation could have valued the sustainability benefits of Free Software and cooperative hardware vendors. In doing so, by merely asking for informed opinions, they would have avoided this mess entirely. Unfortunately, they may have focused too narrowly only on certain worthy and necessary topics, maintaining an oversimplified view of software that, if mainstream media punditry is to be believed, is merely transient and interchangeable: something that can be made to run on any hardware as if by magic, with each upgrade replacing what was there before with something that is always better, only ever offering improvements and benefits. Those of us with more than a passing knowledge of systems development know that such beliefs are really delusions produced from a lack of experience or a wish to believe that unfamiliar things are easier than they actually are.
Since we cannot go back and change the way things were done before, I suppose that now is the time to deliver on the sustainability promise by fully and properly promoting and supporting Free Software on any future Fairphone device. Which means that the Fairphone organisation has to start listening to people with experience of reliably deploying and supporting Free Software on open or properly-documented hardware, instead of going along with whatever some supplier (and their potentially GPL-violating associates) would have them do just to get the contract in the bag and the device out of the door.
Tuning digiKam’s Previews
June 17th, 2014
It is entirely possible that I am doing something wrong as usual, but my way of using digiKam is as follows:
- Plug in camera or other media.
- Choose to download using digiKam when prompted by the notifier.
- Wait while digiKam loads.
- Download new images in the pop-up window that digiKam offers containing thumbnails.
- View the images in the album, clicking on them to see them at a decent size, zooming in to see detail.
It is also entirely possible that by not choosing to edit images in digiKam, I am missing out on vital functionality, although I rather adhere to the school of photography that involves as little postprocessing as possible (also known as “PP” amongst squabbling online photography forum participants). Anyone who has had to scan negatives with a flatbed scanner with a negative adapter and deal with constant dust contamination, never mind develop film, soon realises what a burden has been lifted from them by digital photography. (On the subject of developing using film, ignoring some work experience in a print shop, I have only ever done so in the distant past with a pinhole photography kit, which was actually fun. Doing so regularly would be somewhat more tedious, I can imagine.)
What I didn’t realise until today, and it was driving me crazy, was that another piece of vital functionality seems to be reserved for the editing mode in digiKam unless you change the settings. I was seeing rather pixelated images at the “1:1” or 100% view and rather surprised that a camera I had recently bought was performing so badly: was my camera really so badly configured? To keep this story moving at an acceptable pace, I’ll give you the briefest comprehensible summary of my investigation and its conclusion.
First, I configured my camera to take raw images, and then I took some raw images: digiKam imported them, which is a nice touch, but I really wanted to see what the sensor was actually producing (and actually I still have to figure that out). And so I launched the editing mode and, to my surprise, got to see my pictures in all their proper glory, no pixelation or anything of the kind: they were what I was expecting from the very beginning. And then I realised that perhaps digiKam treats the album view as some kind of preview, even when you view the images at full resolution. This led me into the “Settings” menu and into “Configure digiKam…” and here is what I found:
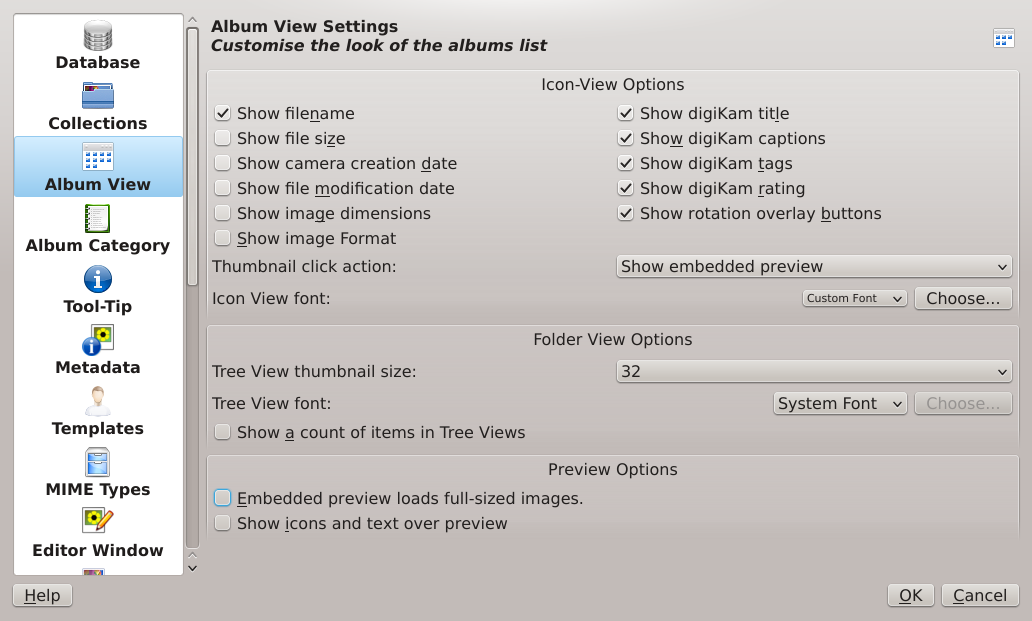 The digiKam settings of note in this particular case
The digiKam settings of note in this particular case
Here, I’ve helped you out a little in finding the offending setting: it’s in the “Preview Options” part at the bottom and is called “Embedded preview loads full-sized images.” Selecting this has a dramatic effect on the “preview” as can be seen from an image with this setting in its apparently natural unselected state:

Pixelation visible in a full resolution crop in digiKam
And here is the result when selecting the setting:

A full resolution crop being displayed properly
So what do we learn from this? Well, it did occur to me that perhaps I’m just not using digiKam in the right way: “everybody else” goes into every image with the editor, or maybe the slideshow option displays images properly and they all use that to properly look at their photographic output. But I remain baffled as to why anyone would want to see some presumably optimised-for-performance preview when they are looking at their images at full resolution. For anyone suffering from this unfathomable behaviour, I hope this article floats into your Internet frame of view so that you can avoid the same frustration.
Update
It turns out that the low resolution preview feature is covered by a reported bug in digiKam.
Meanwhile, I have since realised that allowing digiKam to “download” pictures from an SD card, it wants to rotate them all even if there’s no rotation necessary, actually changing all the files. With this errant behaviour avoided by just copying the pictures from the card directly (and using Gwenview to view them), it turns out that digiKam is quite happy to show pictures in the correct orientation all by itself. Unfortunately, it seems completely unable to convince itself that its own erroneous understanding of the orientation of some pictures (“downloaded” by digiKam and subsequently replaced by the actual image files straight from the card) should be suspended even after I moved those pictures out of digiKam, removed all image entries from the album concerned from its database, and removed all thumbnail entries from the album concerned from its thumbnail database.
I am starting to feel that the simpler option – Gwenview – is looking better all the time, but I’ll miss the tagging features of digiKam and the relatively convenient EXIF perusal, especially since Gwenview’s tagging seems broken for me and its EXIF support seems somewhat perfunctory.
Når sannheten kommer frem
April 28th, 2014
For noen måneder siden skrev jeg om avgjørelsen foretatt av ledelsen til Universitetet i Oslo å innføre Microsoft Exchange som gruppevareløsning. I teksten viste jeg til kommentarer som handlet om Roundcube og hvorfor den løsningen ikke kunne brukes i fremtiden hos UiO. Nå etter at universitetets IT-avdeling publiserte en nyhetssak som omtaler SquirrelMail, får jeg muligheten til å grave opp og dele noen detaljer fra mine samtaler med talspersonen tilknyttet prosjektet som vurderte Exchange og andre løsninger.
Når man ser rundt på nettet, virker det ikke uvanlig at organisasjoner innførte Roundcube parallelt med SquirrelMail på grunn av bekymringer om “universell utforming” (UU). Men i samtaler med prosjektet ble jeg fortalt at diverse mangler i UU-støtte var en aktuell grunn for at Roundcube ikke kunne bli en del av en fremtidig løsning for webmail hos UiO. Nå kommer sannheten frem:
“Ved innføringen av Roundcube som UiOs primære webmail-tjeneste fikk SquirrelMail lov til å leve videre i parallell fordi Roundcube hadde noen mangler knyttet til universell utforming. Da disse var forbedret hadde ledelsen besluttet at e-post og kalender skulle samles i et nytt system.”
Det finnes to ting som fanger vår oppmerksomhet her:
- At Roundcube hadde mangler “ved innføringen”, mens Roundcube hadde vært i bruk i noen år før den tvilsomme prosessen ble satt i gang for å vurdere e-post og kalenderløsninger.
- At forbedringene kom tilfeldigvis for sent for å påvirke ledelsens beslutning å innføre Exchange.
I fjor sommer, uten å dele prosjektgruppens påstander om mangler i Roundcube direkte i offentlighet, hørte jeg med andre om det fantes kjente mangler og forbedringspotensial i Roundcube i dette området. Var UU virkelig noe som hindret utbredelsen av Roundcube? Jeg satte meg inn i UU-teknologier og prøvde noen av dem med Roundcube for å se om situasjonen kunne forbedres med egen innsats. Det kan hende at det var store mangler i Roundcube tilbake i 2011 da prosjektgruppen begynte sitt arbeid – jeg velger ikke å hevde noe slikt – men etter at slike mangler ikke kom frem i 2012 i prosjektets sluttrapport (der Roundcube faktisk ble anbefalt som en del av den åpne kandidaten), må vi konkludere at slike bekymringer var for lengst borte og at universitetets egen webmail-tjeneste, selv om den er tilpasset organisasjonens egen visuelle profil (som kan ha noe å si om vedlikehold), var og fortsatt er tilgjengelig for alle brukere.
Hvis vi våger å tro at utdraget ovenfor forteller sannheten må vi nå konkludere at ledelsens beslutning fant sted lenge før selve prosessen som skulle underbygge denne beslutningen ble avsluttet. Og her må vi anse ordene “ledelsen besluttet” i et annet lys enn det som ellers er vanlig – der ledelsen først drar nytte av kompetanse i organisasjonen, og så tar en informert beslutning – med å anta at, som tidligere skrevet, noen “måtte ha” noe de likte, tok beslutningen de ville ta uansett, og så fikk andre til å finne på unnskyldninger og et grunnlag som virker fornuftig nok overfor utenforstående.
Det er én sak at en tilstrekkelig og fungerende IT-løsning som også er fri programvare svartmales mens tilsynelatende upopulære proprietære løsninger som Fronter når ikke opp slik at problemer rapportert i 2004 ble omtalt igjen i 2012 uten at produsenten gjør noe vesentlig mer enn å love å “jobbe med tilgjengelighet” fremover. Det er en annen sak at bærekraftige investeringer i fri programvare virker så fremmed til beslutningstakere hos UiO at folk heller vil snu arbeidsdagen til den vanlige ansatte opp-ned, slik utskiftningen av e-postinfrastrukturen har gjort for noen, enn å undersøke muligheten til å foreta relativt små utviklingsoppgaver for å oppgradere eksisterende systemer, og slippe at folk må “[stå] på dag og natt” i løpet av “de siste månedene” (og her viser vi selvsagt ikke til folk i ledelsen).
At ansatte i IT-avdelingen fikk munnkurv omkring prosessen og måtte forlange at deler av beslutningsgrunnlaget ikke når frem til offentligheten. At “menige” IT-ansvarlige må løpe hit og dit for å sørge for at ingen blir altfor misfornøyd med utfallet til en avgjørelse hverken de eller andre vanlige ansatte hadde vesentlig innflytelse på. At andre må tilpasse seg preferansene til folk som egentlig burde hatt ingenting å si om hvordan andre utfører sitt daglig arbeid. Alt dette sier noe om ledelseskulturen og demokratiske tilstander internt i Universitetet i Oslo.
Men sannheten kommer langsomt frem.
Mobile Tethering, Privacy and Predatory Practices
April 26th, 2014
Daniel Pocock provides some fairly solid analogies regarding arbitrary restrictions on mobile network usage, but his blog system seems to reject my comment, so here it is, mostly responding to Adam Skutt’s remark on “gas-guzzlers” (cars that needlessly consume more petrol/gasoline than they really need to).
The second example or analogy mentions “exotic” cars, not necessarily gas-guzzling ones. The point being highlighted is that when producers can ascertain or merely speculate that customers can afford higher prices, they may decide to exploit those customers; things like “tourist prices” are another example of such predatory practices.
I think the first example is a fairly solid rebuttal of the claim that this is all about likely bandwidth consumption (and that tethered devices would demand more than mobile devices). Just as the details of the occupants of a vehicle should be of no concern to a petrol station owner, so should the details of network-using programs be of no concern to a mobile network operator.
Operators are relying on the assumption that phones are so restricted that their network usage will be constrained accordingly, but this won’t be the case forever and may not even be the case now. They should stop pining for the days when phones were totally under their own control, with every little feature being a paid upgrade to unlock capabilities that the device had from the moment it left the factory.
I know someone whose carrier-locked phone wouldn’t share pictures over Bluetooth whereas unlocked phones of the same type would happily do so. Smartphones are said to be a computer in one’s pocket: this means that we should also fight to uphold the same general purpose computing rights that, throughout the years, various organisations have sought to deny us all from our desktop and laptop computers.
Minimal Kolab: Unbundling the LDAP and IMAP Components
March 8th, 2014
In my last post about Kolab I hinted about unbundling the LDAP server and using a remote server for LDAP service. Since then, I’ve been looking at making the IMAP server an “unbundled” component – IMAP service still being required, of course – and even at supporting Dovecot in setup-kolab as well. After all, choice is an important motivation for adopting Free Software, and we should at least try and make that choice convenient to exercise where possible. Supporting a choice of IMAP servers gives everyone a bit more flexibility and should make Kolab a bit easier to adopt. The Dovecot work is still very much in progress, however.
As you may recall, I wanted to deploy an XMPP server – ejabberd – on one host and the rest of the Kolab stack on another host, and yet retain the possibility of configuring these different components using setup-kolab. To support this specific situation, and to eventually move beyond it to support other architectural configurations, I have chosen to introduce a new metapackage called kolab-minimal: the glue components of Kolab plus the Web components minus the “infrastructure” components, those being the components providing the LDAP, IMAP and mail transport services. Here’s where this takes us:
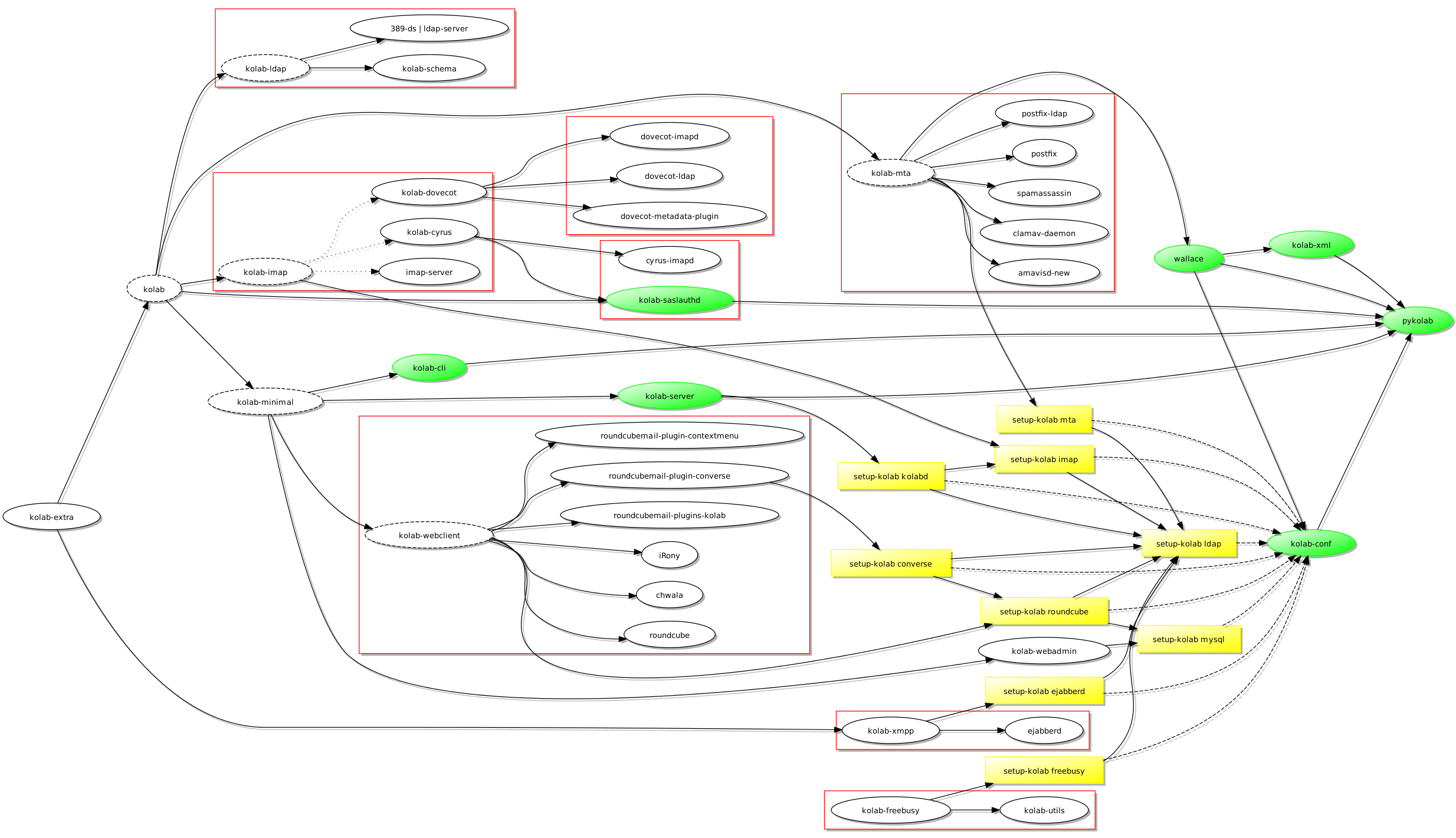
A dependency diagram for Kolab featuring a kolab-minimal package and the different setup-kolab invocations
If you want to install the complete stack, the kolab metapackage will bring everything you need into the installation and hopefully provide you with a self-contained solution. But now, the kolab metapackage is formulated in terms of the “infrastructure” components plus kolab-minimal. And if you want to install something that gets its services from other computers, kolab-minimal should be all you need.
Obviously, this work deviates from the “official” Kolab packages, but since it appears that those packages aren’t being refreshed with upstream fixes as often as might be desirable, I’ve decided to put some source packages online. If you should be tempted to build them and try them out, please remember to do so in a test environment and that you do so at your own peril! And if you want to track my packaging changes, I’ve put a collection of repositories online, too.
Note that the XMPP dependencies (Converse and ejabberd) are integrated into the above, but more testing is really needed to make sure that they become robust additions. Indeed, as part of the Converse plugin package there’s a patch that fixes an annoying bug that makes deploying the plugin almost like an “all or nothing” affair. So I’ve put them under a new metapackage – kolab-extra – for now.
And the way the packaging invokes the configuration program – setup-kolab – probably needs some review, particularly the way setup-kolab wants to edit or replace configuration files of other packages. Some insights into the proper Debian way of doing this would be very useful indeed. I can imagine Kolab using configuration files in slightly different locations and changing references to where the configuration lives in only one key place (or a few key places), leaving the originals intact, but I haven’t been able to look at this in depth.
And with that, I’ll give my modestly equipped desktop computer a rest from running two User Mode Linux instances and pdebuild in 1GB RAM (of the semiconductor variety, plus some swap).
Kolab, Debian, LDAP and XMPP
February 21st, 2014
I had another chance to look at Kolab and the dependency graph recently. Having been inspired by the prospect of chat integration within Roundcube, I set out to install a suitable XMPP server, and it seemed that ejabberd was the most likely choice on Debian systems such as my own. Here is what the configuration would ideally look like:
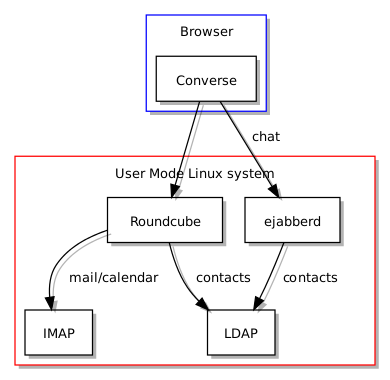
Kolab, Roundcube and ejabberd running in a User Mode Linux environment
But I then discovered that ejabberd did not seem to work with the User Mode Linux environment in which I test my packages. This then gave me an excuse to contemplate the relationship between the different components. LDAP is central to the way Kolab manages credentials and is employed by ejabberd to authenticate users, but the LDAP service does not need to be located on the same server. Indeed, it is likely that in a larger organisation the services would reside on a number of different computers.
Repositioning LDAP
Since I was interested in writing a component to configure ejabberd for integration with the other Kolab components, but that this service would have to be installed outside my own User Mode Linux environment (within which Roundcube happens to reside), I therefore needed to find a way of teaching setup-kolab (Kolab’s setup script) about remote LDAP services as an alternative to any such service running on the same machine. And from this perspective I realised that the dependency on LDAP is a “soft” one: it is entirely possible to want to install Kolab without also installing an LDAP server suite, but the need for LDAP service remains. It thus falls on other computers to provide LDAP services to the computer running the chat service (and to the other Kolab services, too).
A bit of adjustment to the setup_ldap module in pykolab and it became possible to choose a local directory or a remote one accessible via LDAP. At this point, running ejabberd outside User Mode Linux (UML) and connecting to the LDAP service running inside UML looked feasible, and I developed a setup-kolab component to propagate Kolab settings to ejabberd’s configuration file, but my desktop environment’s chat program didn’t seem interested in joining the testing effort. That meant that I really had to get the Converse plugin working within Roundcube, thus enabling chat within the webmail environment.
Enlisting Converse
Naturally, this meant figuring out a reliable way of configuring Converse, and thus another setup-kolab component was created for this purpose. So far, so straightforward: get Converse to talk to an XMPP service and the job is done. But now in my arrangement, the XMPP service – ejabberd – is situated in a remote location from Converse and in a separate location from Roundcube, and is thus not accessible without some additional measures. Converse runs JavaScript in the browser, but that code needs to “bind” to the XMPP service in order to be able to use it, and a general security measure enforced in browsers is that scripts aren’t allowed to talk to any location on the Internet just because they want to: instead, they may be restricted to only being capable of sending information to the server that delivered them to the browser in the first place. Here is a diagram illustrating the problem:
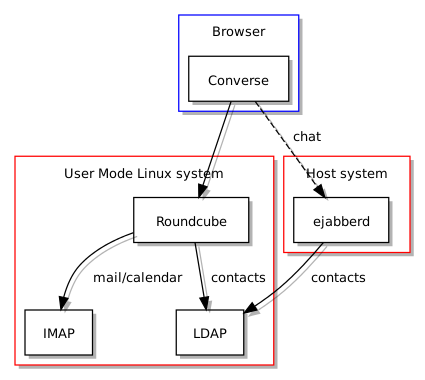
Kolab, Roundcube and ejabberd, but with Converse wanting to communicate with two different hosts
Since Converse wants to talk to the XMPP service, but given that the XMPP service is not located in the same place as the Web server that sent it to the browser, a proxy must be deployed to listen to Converse within the Web environment and then relay the communications to ejabberd. This involves configuring Apache to receive requests and pretend to be the “connection manager”, and then Apache forwards such requests to the real connection manager provided by ejabberd. Thus, the following diagram illustrates the solution to this distribution of services problem:
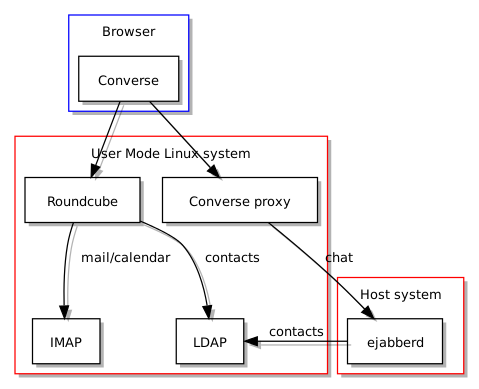
Kolab, Roundcube and ejabberd, with the latter being reached via a proxy from Roundcube
Thus, the task of setting up chat in Roundcube, integrated with Kolab, involves the following:
- The configuration of ejabberd to authenticate users using Kolab account details stored in the LDAP directory
- The configuration of Roundcube to enable the Converse plugin and…
- The deployment of a proxy site in Apache to forward Converse’s chat requests to ejabberd
The State of Play
There seems to be plenty of integration work still to be done. Although Converse can obtain contact details supplied by ejabberd from the LDAP service and thus provide immediate access to other users in the same organisation, the level of integration with the rest of the interface is still fairly loose: you cannot find a chat button in the address book for each contact, for example. Even so, the level of convenience probably already matches various other groupware solutions.
I can’t wait to see what kind of communication or collaboration technology will be next, even if there will be a degree of work to make it a bit easier to set up with Kolab. And that reminds me to get the configuration nuts and bolts packed off and sent upstream so that everybody else can try it out.