Continuing Explorations into Filesystems and Paging with L4Re
Saturday, April 8th, 2023Towards the end of last year, I spent a fair amount of time trying to tidy up and document the work I had been doing on integrating a conventional filesystem into the L4 Runtime Environment (or L4Re Operating System Framework, as it now seems to be called). Some of that effort was purely administrative, such as giving the work a more meaningful name and changing references to the naming in various places, whereas other aspects were concerned with documenting mundane things like how the software might be obtained, built and used. My focus had shifted somewhat towards sharing the work and making it slightly more accessible to anyone who might be interested (even if this is probably a very small audience).
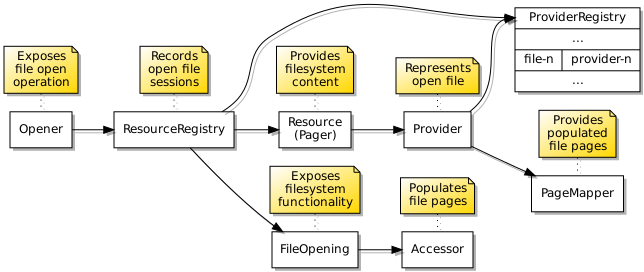
Previously, in seeking to demonstrate various mechanisms such as the way programs might be loaded and run, with their payloads paged into memory on demand, I had deferred other work that I felt was needed to make the software framework more usable. For example, I was not entirely happy with the way that my “client” library for filesystem access hid the underlying errors, making troubleshooting less convenient than it could be. Instead of perpetuating the classic Unix “errno” practice, I decided to give file data structures their own error member to retain any underlying error, meaning that a global variable would not be involved in any error reporting.
Other matters needed attending to, as well. Since acquiring a new computer in 2020 based on the x86-64 architecture, the primary testing environment for this effort has been a KVM/QEMU instance invoked by the L4Re build process. When employing the same x86-64 architecture for the instance as the host system, the instance should in theory be very efficient, but for some reason the startup time of such x86-64 instances is currently rather long. This was not the case at some point in the past, but having adopted the Git-based L4Re distribution, this performance regression made an appearance. Maybe at some stage in the future I will discover why it sits there for half a minute spinning up at the “Booting ROM” stage, but for now a reasonable workaround is to favour QEMU instances for other architectures when testing my development efforts.
Preserving Portability
Having long been aware of the necessity of software portability, I have therefore been testing the software in QEMU instances emulating the classic 32-bit x86 architecture as well as MIPS32, in which I have had a personal interest for several years. Surprisingly, testing on x86 revealed a few failures that were not easily explained, but I eventually tracked them down to interoperability problems with the L4Re IPC library, where that library was leaving parts of IPC message values uninitialised and causing my own IPC library to misinterpret the values being sent. This investigation also led me to discover that the x86 Application Binary Interface is rather different in character to the ABI for other architectures. On those other architectures, the alignment of members in structures (and of parameters in parameter lists) needs to be done more carefully due to the way values in memory are accessed. On x86, meanwhile, it seems that values of different sizes can be more readily packed together.
In any case, I came to believe that the L4Re IPC library is not following the x86 ABI specification in the way IPC messages are prepared. I did wonder whether this was deliberate, but I think that it is actually inadvertent. One of my helpful correspondents confirmed that there was indeed a discrepancy between the L4Re code and the ABI, but nothing came of any enquiries into the matter, so I imagine that in any L4Re systems deployed on x86 (although I doubt that there can be many), the use of the L4Re code on both sides of any given IPC transaction manages to conceal this apparent deficiency. The consequence for me was that I had to introduce a workaround in the cases where my code needs to interact with various existing L4Re components.
Several other portability changes were made to resolve a degree of ambiguity around the sizes of various types. This is where the C language family and various related standards and technologies can be infuriating, with care required when choosing data types and then using these in conjunction with libraries that might have their own ideas about which types should be used. Although there probably are good reasons for some types to be equivalent to a “machine word” in size, such types sit uncomfortably with types of other, machine-independent sizes. I am sure I will have to revisit these choices over and over again in future.
Enhancing Component Interface Descriptions
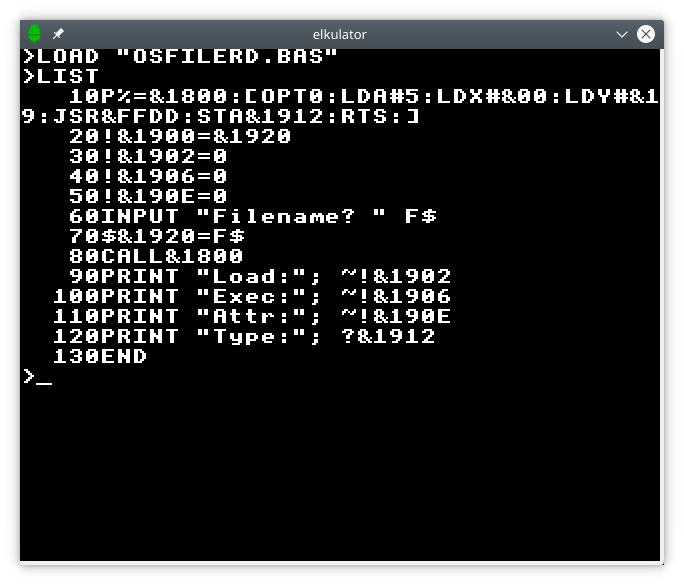
One thing I had been meaning to return to was the matter of my interface description language (IDL) tool and its lack of support for composing interfaces. For example, a component providing file content might expose several different interfaces for file operations, dataspace operations, and so on. These compound interfaces had been defined by specifying arguments for each invocation of the IDL tool that indicate all the interfaces involved, and thus the knowledge of each compound interface ended up being encoded as definitions within Makefiles like this:
mapped_file_object_INTERFACES = dataspace file flush mapped_file notification
A more natural approach involved defining these interfaces in the interface description language itself, but this was going to require putting in the effort to extend the tool, which would not be particularly pleasant, being written in C using Flex and Bison.
Eventually, I decided to just get on with remedying the situation, adding the necessary tool support, and thus tidying up and simplifying the Makefiles in my L4Re build system package. This did raise the complexity level in the special Makefiles provided to support the IDL tool – nothing in the realm of Makefiles is ever truly easy – but it hopefully confines such complexity out of sight and keeps the main project Makefiles as concise as can reasonably be expected. For reference, here is how a file component interface looks with this new tool support added:
interface MappedFileObject composes Dataspace, File, Flush, MappedFile, Notification;
And for reference, here is what one of the constituent interfaces looks like:
interface Flush
{
/* Flush data and update the size, if appropriate. */
[opcode(5)] void flush(in offset_t populated_size, out offset_t size);
};
I decided to diverge from previous languages of this kind and to use “composes” instead of language like “inherits”. These compound interface descriptions deliberately do not seek to combine interfaces in a way that entirely resembles inheritance as supported by various commonly used programming languages, and an interface composing other interfaces cannot also add operations of its own: it can merely combine other interfaces. The main reason for such limitations is the deliberate simplicity or lack of capability of the tool: it only really transcribes the input descriptions to equivalent forms in C or C++ and neglects to impose many restrictions of its own. One day, maybe I will revisit this and at least formalise these limitations instead of allowing them to emerge from the current state of the implementation.
A New Year
I had hoped to deliver something for broader perusal late last year, but the end of the year arrived and with it some intriguing but increasingly time-consuming distractions. Having written up the effective conclusion of those efforts, I was able to turn my attention to this work again. To start with, that involved reminding myself where I had got to with it, which underscores the need for some level of documentation, because documentation not only communicates the nature of a work to others but it also communicates it to one’s future self. So, I had to spend some time rediscovering the finer detail and reminding myself what the next steps were meant to be.
My previous efforts had demonstrated the ability to launch new programs from my own programs, reproducing some of what L4Re already provides but in a form more amenable to integrating with my own framework. If the existing L4Re code had been more obviously adaptable in a number of different ways throughout my long process of investigation and development for it, I might have been able to take some significant shortcuts and save myself a lot of effort. I suppose, however, that I am somewhat wiser about the technologies and techniques involved, which might be beneficial in its own way. The next step, then, was to figure out how to detect and handle the termination of programs that I had managed to launch.
In the existing L4Re framework, a component called Ned is capable of launching programs, although not being able to see quite how I might use it for my own purposes – that being to provide a capable enough shell environment for testing – had led me along my current path of development. It so happens that Ned supports an interface for “parent” tasks that is used by created or “child” tasks, and when a program terminates, the general support code for the program that is brought along by the C library includes the invocation of an operation on this parent interface before the program goes into a “wait forever” state. Handling this operation and providing this interface seemed to be the most suitable approach for replicating this functionality in my own code.
Consolidation and Modularisation
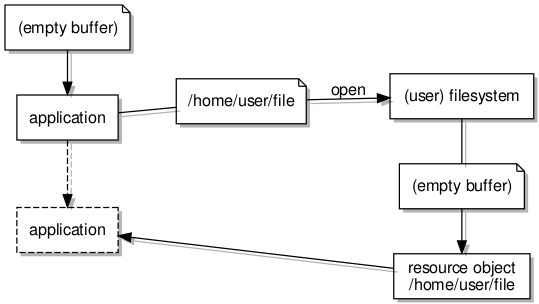
Before going any further, I wanted to consolidate my existing work which had demonstrated program launching in a program written specifically for that purpose, bringing along some accompanying abstractions that were more general in nature. First of all, I decided to try and make a library from the logic of the demonstration program I had written, so that the work involved in setting up the environment and resources for a new program could be packaged up and re-used. I also wanted the functionality to be available through a separate server component, so that programs wanting to start other programs would not need to incorporate this functionality but could instead make a request to this separate “process server” component to do the work, obtaining a reference to the new program in response.
One might wonder why one might bother introducing a separate component to start programs on another program’s behalf. As always when considering the division of functionality between components in a microkernel-based system, it is important to remember that components can have different configurations that afford them different levels of privilege within a system. We might want to start programs with one level of privilege from other programs with a different level of privilege. Another benefit of localising program launching in one particular component is that it might provide an overview of such activities across a number of programs, thus facilitating support for things like job and process control.
Naturally, an operating system does not need to consolidate all knowledge about running programs or processes in one place, and in a modular microkernel-based system, there need not even be a single process server. In fact, it seems likely that if we preserve the notion of a user of the system, each user might have their own process server, and maybe even more than one of them. Such a server would be configured to launch new programs in a particular way, having access only to resources available to a particular user. One interesting possibility is that of being able to run programs provided by one filesystem that then operate on data provided by another filesystem. A program would not be able to see the filesystem from which it came, but it would be able to see the contents of a separate, designated filesystem.
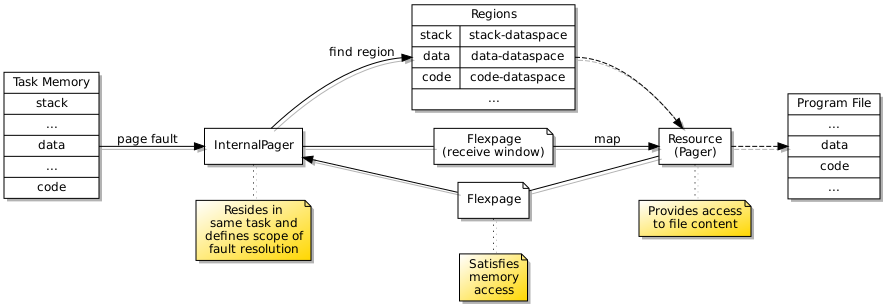
Region Mapper Deficiencies
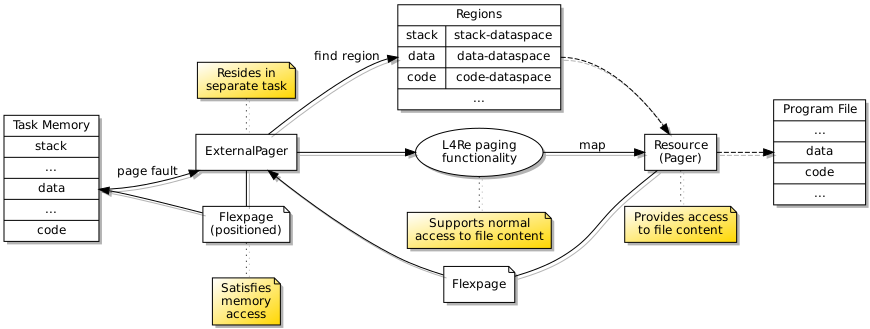
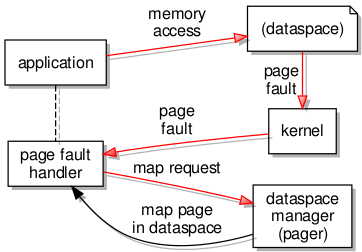
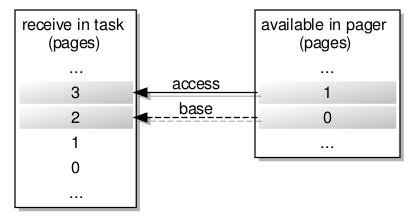
A few things conspired to make the path of progress rather less direct than it might have been. Having demonstrated the launching of trivial programs, I had decided to take a welcome break from the effort. Returning to the effort, I decided to test access to files served up by my filesystem infrastructure, and this caused programs to fail. In order to support notification events when accessing files, I employ a notification thread to receive such events from other components, but the initialisation of threading in the C library was failing. This turned out to be due to the use of a region mapper operation that I had not yet supported, so I had to undertake a detour to implement an appropriate data structure in the region mapper, which in C++ is not a particularly pleasant experience.
Later on, the region mapper caused me some other problems. I had neglected to implement the detach operation, which I rely on quite heavily for my file access library. Attempting to remedy these problems involved reacquainting myself with the region mapper interface description which is buried in one of the L4Re packages, not to be confused with plenty of other region mapper abstractions which do not describe the actual interface employed by the IPC mechanism. The way that L4Re has abandoned properly documented interface descriptions is very annoying, requiring developers to sift through pages of barely commented code and to be fully aware of the role of that code. I implemented something that seemed to work, quite sure that I still did not have all the details correct in my implementation, and this suspicion would prove correct later on.
Local and Non-Local Capabilities
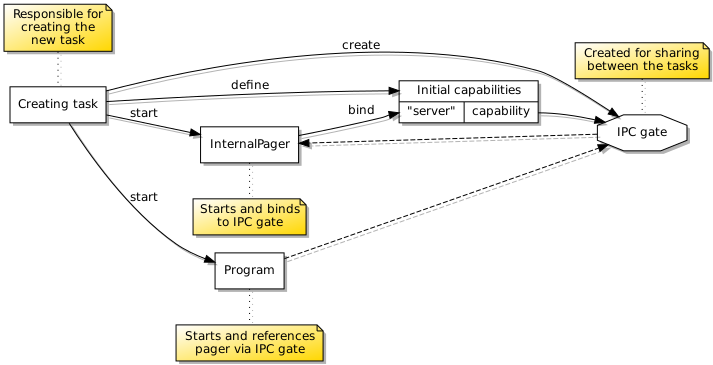
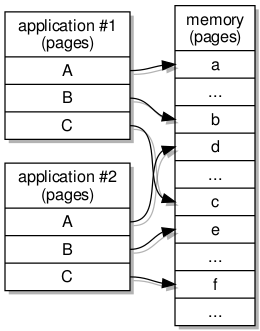
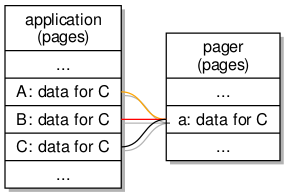
Another thing that I had not fully understood, when trying to put together a library handling IPC that I could tolerate working with, was the way that capabilities may be transferred in IPC messages within tasks. Capabilities are references to components in the system, and when transferred between tasks, the receiving task is meant to allocate a “slot” for each received capability. By choosing a slot denoted by an index, the task (or the program running in it) can tell the kernel where to record the capability in its own registry for the task, and by employing this index in its own registry, the program will be able to maintain a record of available capabilities consistent with that of the kernel.
The practice of allocating capability slots for received capabilities is necessary for transfers between tasks, but when the transfer occurs within a task, there is no need to allocate a new slot: the received capability is already recorded within the task, and so the item describing the capability in the message will actually encode the capability index known to the task. Previously, I was not generally sending capabilities in messages within tasks, and so I had not knowingly encountered any issues with my simplistic “general case” support for capability transfers, but having implemented a region mapper that resides in the same task as a program being run, it became necessary to handle the capabilities presented to the region mapper from within the same task.
One counterintuitive consequence of the capability management scheme arises from the general, inter-task transfer case. When a task receives a capability from another task, it will assign a new index to the capability ahead of time, since the kernel needs to process this transfer as it propagates the message. This leaves the task with a new capability without any apparent notion of whether it has seen that capability before. Maybe there is a way of asking the kernel if two capabilities refer to the same object, but it might be worthwhile just not relying on such facilities and designing frameworks around such restrictions instead.
Starting and Stopping
So, back to the exercise of stopping programs that I had been able to start! It turned out that receiving the notification that a program had finished was only the start; what then needed to happen was something of a mystery. Intuitively, I knew that the task hosting the program’s threads would need to be discarded, but I envisaged that the threads themselves probably needed to be discarded first, since they are assigned to the task and probably cannot have that task removed from under them, even if they are suspended in some sense.
But what about everything else referenced by the task? After all, the task will have capabilities for things like dataspaces that provide access to regions of files and to the program stack, for things like the filesystem for opening other files, for semaphore and IRQ objects, and so on. I cannot honestly say that I have the definitive solution, and I could not easily find much in the way of existing guidance, so I decided in the end to just try and tidy all the resources up as best I could, hopefully doing enough to make it possible to release the task and have the kernel dispose of it. This entailed a fairly long endeavour that also encouraged me to evolve the way that the monitoring of the process termination is performed.
When the started program eventually reaches the end and sends a message to its “parent” component, that component needs to record any termination state communicated in the message so that it may be passed on to the program’s creator or initiator, and then it also needs to commence the work of wrapping up the program. Here, I decided on a distinct component separate from one responsible for any paging activities to act as the contact point for the creating or initiating program. When receiving a termination message or signal, this component disconnects the terminating program from its internal pager by freeing the capability, and this then causes the internal pager to terminate, itself sending a signal to its own parent.
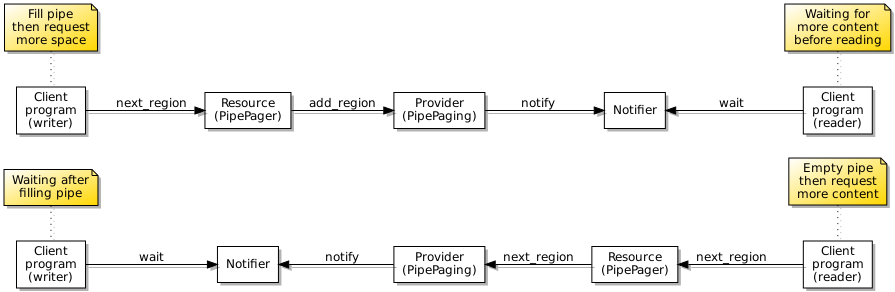
One important aspect of starting and terminating processes is that of notifying the party that sought to start a process in the first place. For filesystem operations, I had already implemented support for certain notification events related to opening, modifying and closing files and pipes, with these being particularly important for pipes. I wanted to extend this support to processes so that it might be possible to monitor files, pipes and processes together using a kind of select or poll operation. This led to a substantial detour where I became dissatisfied with the existing support, modified it, had to debug it, and remain somewhat concerned that it might need more work in the future.
Testing on the different architectures under QEMU also revealed that I would need to handle the possibility that a program might be started and run to completion before its initiator had even received a reference to the program for notification purposes. Fortunately, a similar kind of vanishing resource problem arose when I was developing the file paging system, and so I had a technique available to communicate the reference to the process monitor component to the initiator of the program, ensuring that the process monitor becomes established in the kernel’s own records, before the program itself gets started, runs and completes, avoiding the process monitor being tidied up before its existence becomes known to the wider system.
Wrapping Up Again
A few concerns remain with the state of the work so far. I experienced problems with filesystem access that I traced to the activity of repeatedly attaching and detaching dataspaces, which is something my filesystem access library does deliberately, but the error suggested that the L4Re region mapper had somehow failed to attach the appropriate region. This may well be caused by issues within my own code, and my initial investigation did indeed uncover a problem in my own code where the size of the attached region of a file would gradually increase over time. With this mistake fixed, the situation was improved, but the underlying problem was not completely eliminated, judging from occasional errors. A workaround has been adopted for now.
Various other problems arose and were hopefully resolved. I would say that some of them were due to oversights when getting things done takes precedence over a more complete consideration of all the issues, particularly when working in a language like C++ where lower-level chores like manual memory management enter the picture. The differing performance when emulating various architectures under QEMU also revealed a deficiency with my region mapper implementation. It turned out that detach operations were not returning successfully, leading the L4Re library function to return without invalidating memory pages, and so my file access operations were returning pages of incorrect content instead of the expected file content for the first few accesses until the correct pages had been paged in and were almost continuously resident.
Here, yet more digging around in the L4Re code revealed an apparent misunderstanding about the return value associated with one of the parameters to the detach operation, that of the detached dataspace. I had concluded that a genuine capability was meant to be returned, but it seems that a simple index value is returned in a message word instead of a message item, and so there is no actual capability transferred to the caller, not even a local one. The L4Re IPC framework does not really make the typing semantics very clear, or at least not to me, and the code involved is quite unfathomable. Again, a formal interface specification written in a clearly expressed language would have helped substantially.
Next Steps
I suppose progress of sorts has been made in the last month or so, for which I can be thankful. Although tidying up the detritus of my efforts will remain an ongoing task, I can now initiate programs and wait for them to finish, meaning that I can start building up test suites within the environment, combining programs with differing functionality in a Unix-like fashion to hopefully validate the behaviour of the underlying frameworks and mechanisms.
Now, I might have tried much of this with L4Re’s Lua-based scripting, but it is not as straightforward as a more familiar shell environment, appearing rather more low-level in some ways, and it is employed in a way that seems to favour parallel execution instead of the sequential execution that I might desire when composing tests: I want tests to involve programs whose results feed into subsequent programs, as opposed to just running a load of programs at once. Also, without more extensive documentation, the Lua-based scripting support remains a less attractive choice than just building something where I get to control the semantics. Besides, I also need to introduce things like interprocess pipes, standard input and output, and such things familiar from traditional software platforms. Doing that for a simple shell-like environment would be generally beneficial, anyway.
Should I continue to make progress, I would like to explore some of the possibilities hinted at above. The modular architecture of a microkernel-based system should allow a more flexible approach in partitioning the activities of different users, along with the configuration of their programs. These days, so much effort is spent in “orchestration” and the management of containers, with a veritable telephone directory of different technologies and solutions competing for the time and attention of developers who are now also obliged to do the work of deployment specialists and systems administrators. Arguably, much of that involves working around the constraints of traditional systems instead of adapting to those systems, with those systems themselves slowly adapting in not entirely convincing or satisfactory ways.
I also think back to my bachelor’s degree dissertation about mobile software agents where the idea was that untrusted code might be transmitted between systems to carry out work in a safe and harmless fashion. Reducing the execution environment of such agent programs to a minimum and providing decent support for monitoring and interacting with them would be something that might be more approachable using the techniques explored in this endeavour. Pervasive, high-speed, inexpensively-accessed networks undermined the envisaged use-cases for mobile agents in general, although the practice of issuing SQL queries to database servers or having your browser run JavaScript programs deployed in Web pages demonstrates that the general paradigm is far from obsolete.
In any case, my “to do” list for this project will undoubtedly remain worryingly long for the foreseeable future, but I will hopefully be able to remedy shortcomings, expand the scope and ambition of the effort, and continue to communicate my progress. Thank you to those who have made it to the end of this rather dry article!