Paul Boddie's Free Software-related blog
Paul's activities and perspectives around Free Software
Dataspaces and Paging in L4Re
The experiments covered by my recent articles about filesystems and L4Re managed to lead me along another path in the past few weeks. I had defined a mechanism for providing access to files in a filesystem via a programming interface employing interprocess communication within the L4Re system. In doing so, I had defined calls or operations that would read from and write to a file, observing that some kind of “memory-mapped” file support might also be possible. At the time, I had no clear idea of how this would actually be made to work, however.
As can often be the case, once some kind of intellectual challenge emerges, it can become almost impossible to resist the urge to consider it and to formulate some kind of solution. Consequently, I started digging deeper into a number of things: dataspaces, pagers, page faults, and the communication that happens within L4Re via the kernel to support all of these things.
Dataspaces and Memory
Because the L4Re developers have put a lot of effort into making a system where one can compile a fairly portable program and probably expect it to work, matters like the allocation of memory within programs, the use of functions like malloc, and other things we take for granted need no special consideration in the context of describing general development for an L4Re-based system. In principle, if our program wants more memory for its own use, then the use of things like malloc will probably suffice. It is where we have other requirements that some of the L4Re abstractions become interesting.
In my previous efforts to support MIPS-based systems, these other requirements have included the need to access memory with a fixed and known location so that the hardware can be told about it, thus supporting things like framebuffers that retain stored data for presentation on a display device. But perhaps most commonly in a system like L4Re, it is the need to share memory between processes or tasks that causes us to look beyond traditional memory allocation techniques at what L4Re has to offer.
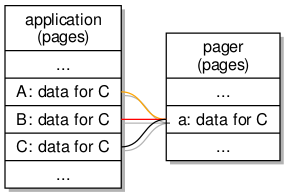
Indeed, the filesystem work so far employs what are known as dataspaces to allow filesystem servers and client applications to exchange larger quantities of information conveniently via shared buffers. First, the client requests a dataspace representing a region of memory. It then associates it with an address so that it may access the memory. Then, the client shares this with the server by sending it a reference to the dataspace (known as a capability) in a message.
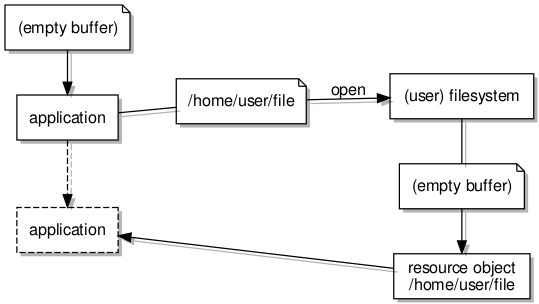
Opening a file using shared memory containing file information
The kernel, in propagating the message and the capability, makes the dataspace available to the server so that both the client and the server may access the memory associated with the dataspace and that these accesses will just work without any further effort. At this level of sophistication we can get away with thinking of dataspaces as being blocks of memory that can be plugged into tasks. Upon obtaining access to such a block, reads and writes (or loads and stores) to addresses in the block will ultimately touch real memory locations.
Even in this simple scheme, there will be some address translation going on because each task has its own way of arranging its view of memory: its virtual address space. The virtual memory addresses used by a task may very well be different from the physical memory addresses indicating the actual memory locations involved in accesses.
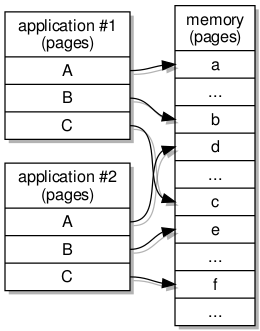
An illustration of virtual memory corresponding to physical memory
Such address translation is at the heart of operating systems like those supported by the L4 family of microkernels. But the system will make sure that when a task tries to access a virtual address available to it, the access will be translated to a physical address and supported by some memory location.
Mapping and Paging
With some knowledge of the underlying hardware architecture, we can say that each task will need support from the kernel and the hardware to be able to treat its virtual address space as a way of accessing real memory locations. In my experiments with simple payloads to run on MIPS-based hardware, it was sufficient to define very simple tables that recorded correspondences between virtual and physical addresses. Processes or tasks would access memory addresses, and where the need arose to look up such a virtual address, the table would be consulted and the hardware configured to map the virtual address to a physical address.
Naturally, proper operating systems go much further than this, and systems built on L4 technologies go as far as to expose the mechanisms for normal programs to interact with. Instead of all decisions about how memory is mapped for each task being taken in the kernel, with the kernel being equipped with all the necessary policy and information, such decisions are delegated to entities known as pagers.
When a task needs an address translated, the kernel pushes the translation activity over to the designated pager for a decision to be made. And the event that demands an address translation is known as a page fault since it occurs when a task accesses a memory page that is not yet supported by a mapping to physical memory. Pagers are therefore present to receive page fault notifications and to respond in a way that causes the kernel to perform the necessary privileged actions to configure the hardware, this being one of the few responsibilities of the kernel.

The role of a pager in managing access to the contents of a dataspace
Treating a dataspace as an abstraction for memory accessed by a task or application, the designated pager for the dataspace acts as a dataspace manager, ensuring that memory accesses within the dataspace can be satisfied. If an access causes a page fault, the pager must act to provide a mapping for the accessed page, leaving the application mostly oblivious to the work going on to present the dataspace and its memory as a continuously present resource.
An Aside
It is rather interesting to consider the act of delegation in the context of processor architecture. It would seem to be fairly common that the memory management units provided by various architectures feature built-in support for consulting various forms of data structures describing the virtual memory layout of a process or task. So, when a memory access fails, the information about the actual memory address involved can be retrieved from such a predefined structure.
However, the MIPS architecture largely delegates such matters to software: a processor exception is raised when a “bad” virtual address is used, and the job of doing something about it falls immediately to a software routine. So, there seems to be some kind of parallel between processor architecture and operating system architecture, L4 taking a MIPS-like approach of eager delegation to a software component for increased flexibility and functionality.
Messages and Flexpages
So, the high-level view so far is as follows:
- Dataspaces represent regions of virtual memory
- Virtual memory is mapped to physical memory where the data actually resides
- When a virtual memory access cannot be satisfied, a page fault occurs
- Page faults are delivered to pagers (acting as dataspace managers) for resolution
- Pagers make data available and indicate the necessary mapping to satisfy the failing access
To get to the level of actual implementation, some familiarisation with other concepts is needed. Previously, my efforts have exposed me to the interprocess communications (IPC) central in L4Re as a microkernel-based system. I had even managed to gain some level of understanding around sending references or capabilities between processes or tasks. And it was apparent that this mechanism would be used to support paging.
Unfortunately, the main L4Re documentation does not seem to emphasise the actual message details or protocols involved in these fundamental activities. Instead, the library code is described in reference documentation with some additional explanation. However, some investigation of the code yielded some insights as to the kind of interfaces the existing dataspace implementations must support, and I also tracked down some message sending activities in various components.
When a page fault occurs, the first thing to know about it is the kernel because the fault occurs at the fundamental level of instruction execution, and it is the kernel’s job to deal with such low-level events in the first instance. Notification of the fault is then sent out of the kernel to the page fault handler for the affected task. The page fault handler then contacts the task’s pager to request a resolution to the problem.
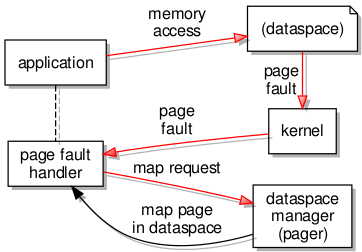
Page fault handling in detail
In L4Re, this page fault handler is likely to be something called a region mapper (or perhaps a region manager), and so it is not completely surprising that the details of invoking the pager was located in some region mapper code. Putting together both halves of the interaction yielded the following details of the message:
- map: offset, hot spot, flags → flexpage
Here, the offset is the position of the failing memory access relative to the start of the dataspace; the flags describe the nature of the memory to be accessed. The “hot spot” and “flexpage” need slightly more explanation, the latter being an established term in L4 circles, the former being almost arbitrarily chosen and not particularly descriptive.
The term “flexpage” may have its public origins in the “Flexible-Sized Page-Objects” paper whose title describes the term. For our purposes, the significance of the term is that it allows for the consideration of memory pages in a range of sizes instead of merely considering a single system-wide page size. These sizes start at the smallest page size supported by the system (but not necessarily the absolute smallest supported by the hardware, but anyway…) and each successively larger size is double the size preceding it. For example:
- 4096 (212) bytes
- 8192 (213) bytes
- 16384 (214) bytes
- 32768 (215) bytes
- 65536 (216) bytes
- …
When a page fault occurs, the handler identifies a region of memory where the failing access is occurring. Although it could merely request that memory be made available for a single page (of the smallest size) in which the access is situated, there is the possibility that a larger amount of memory be made available that encompasses this access page. The flexpage involved in a map request represents such a region of memory, having a size not necessarily decided in advance, being made available to the affected task.
This brings us to the significance of the “hot spot” and some investigation into how the page fault handler and pager interact. I must admit that I find various educational materials to be a bit vague on this matter, at least with regard to explicitly describing the appropriate behaviour. Here, the flexpage paper was helpful in providing slightly different explanations, albeit employing the term “fraction” instead of “hot spot”.
Since the map request needs to indicate the constraints applying to the region in which the failing access occurs, without demanding a particular size of region and yet still providing enough useful information to the pager for the resulting flexpage to be useful, an efficient way is needed of describing the memory landscape in the affected task. This is apparently where the “hot spot” comes in. Consider a failing access in page #3 of a memory region in a task, with the memory available in the pager to satisfy the request being limited to two pages:
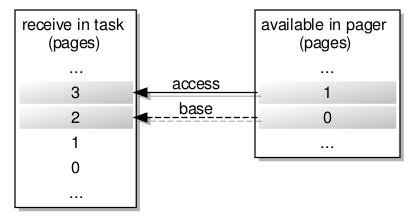
Mapping available memory to pages in a task experiencing a page fault
Here, the “hot spot” would reference page #3, and this information would be received by the pager. The significance of the “hot spot” appears to be the location of the failing access within a flexpage, and if the pager could provide it then a flexpage of four system pages would map precisely to the largest flexpage expected by the handler for the task.
However, with only two system pages to spare, the pager can only send a flexpage consisting of those two pages, the “hot spot” being localised in page #1 of the flexpage to be sent, and the base of this flexpage being the base of page #0. Fortunately, the handler is smart enough to fit this smaller flexpage onto the “receive window” by using the original “hot spot” information, mapping page #2 in the receive window to page #0 of the received flexpage and thus mapping the access page #3 to page #1 of that flexpage.
So, the following seems to be considered and thus defined by the page fault handler:
- The largest flexpage that could be used to satisfy the failing access.
- The base of this flexpage.
- The page within this flexpage where the access occurs: the “hot spot”.
- The offset within the broader dataspace of the failing access, it indicating the data that would be expected in this page.
(Given this phrasing of the criteria, it becomes apparent that “flexpage offset” might be a better term than “hot spot”.)
With these things transferred to the pager using a map request, the pager’s considerations are as follows:
- How flexpages of different sizes may fit within the memory available to satisfy the request.
- The base of the most appropriate flexpage, where this might be the largest that fits within the available memory.
- The population of the available memory with data from the dataspace.
To respond to the request, the pager sends a special flexpage item in its response message. Consequently, this flexpage is mapped into the task’s address space, and the execution of the task may resume with the missing data now available.
Practicalities and Pitfalls
If the dataspace being provided by a pager were merely a contiguous region of memory containing the data, there would probably be little else to say on the matter, but in the above I hint at some other applications. In my example, the pager only uses a certain amount of memory with which it responds to map requests. Evidently, in providing a dataspace representing a larger region, the data would have to be brought in from elsewhere, which raises some other issues.
Firstly, if data is to be copied into the limited region of memory available for satisfying map requests, then the appropriate portion of the data needs to be selected. This is mostly a matter of identifying how the available memory pages correspond to the data, then copying the data into the pages so that the accessed location ultimately provides the expected data. It may also be the case that the amount of data available does not fill the available memory pages; this should cause the rest of those pages to be filled with zeros so that data cannot leak between map requests.
Secondly, if the available memory pages are to be used to satisfy the current map request, then what happens when we re-use them in each new map request? It turns out that the mappings made for previous requests remain active! So if a task traverses a sequence of pages, and if each successive page encountered in that traversal causes a page fault, then it will seem that new data is being made available in each of those pages. But if that task inspects the earlier pages, it will find that the newest data is exposed through those pages, too, banishing the data that we might have expected.
Of course, what is happening is that all of the mapped pages in the task’s dataspace now refer to the same collection of pages in the pager, these being dedicated to satisfying the latest map request. And so, they will all reflect the contents of those available memory pages as they currently are after this latest map request.
The effect of mapping the same page repeatedly
One solution to this problem is to try and make the task forget the mappings for pages it has visited previously. I wondered if this could be done automatically, by sending a flexpage from the pager with a flag set to tell the kernel to invalidate prior mappings to the pager’s memory. After a time looking at the code, I ended up asking on the l4-hackers mailing list and getting a very helpful response that was exactly what I had been looking for!
There is, in fact, a special way of telling the kernel to “unmap” memory used by other tasks (l4_task_unmap), and it is this operation that I ended up using to invalidate the mappings previously sent to the task. Thus the task, upon backtracking to earlier pages, finds that the mappings from virtual addresses to the physical memory holding the latest data are absent once again, and page faults are needed to restore the data in those pages. The result is a form of multiplexing access to a resource via a limited region of memory.
Applications of Flexible Paging
Given the context of my investigations, it goes almost without saying that the origin of data in such a dataspace could be a file in a filesystem, but it could equally be anything that exposes data in some kind of backing store. And with this backing store not necessarily being an area of random access memory (RAM), we enter the realm of a more restrictive definition of paging where processes running in a system can themselves be partially resident in RAM and partially resident in some other kind of storage, with the latter portions being converted to the former by being fetched from wherever they reside, depending on the demands made on the system at any given point in time.
One observation worth making is that a dataspace does not need to be a dedicated component in the system in that it is not a separate and special kind of entity. Anything that is able to respond to the messages understood by dataspaces – the paging “protocol” – can provide dataspaces. A filesystem object can therefore act as a dataspace, exposing itself in a region of memory and responding to map requests that involve populating that region from the filesystem storage.
It is also worth mentioning that dataspaces and flexpages exist at different levels of abstraction. Dataspaces can be considered as control mechanisms for accessing regions of virtual memory, and the Fiasco.OC kernel does not appear to employ the term at all. Meanwhile, flexpages are abstractions for memory pages existing within or even independently of dataspaces. (If you wish, think of the frame of Banksy’s work “Love is in the Bin” as a dataspace, with the shredded pieces being flexpages that are mapped in and out.)
One can envisage more exotic forms of dataspace. Consider an image whose pixels need to be computed, like a ray-traced image, for instance. If it exposed those pixels as a dataspace, then a task reading from pages associated with that dataspace might cause computations to be initiated for an area of the image, with the task being suspended until those computations are performed and then being resumed with the pixel data ready to read, with all of this happening largely transparently.
I started this exercise out of somewhat idle curiosity, but it now makes me wonder whether I might introduce memory-mapped access to filesystem objects and then re-implement operations like reading and writing using this particular mechanism. Not being familiar with how systems like GNU/Linux provide these operations, I can only speculate as to whether similar decisions have been taken elsewhere.
But certainly, this exercise has been informative, even if certain aspects of it were frustrating. I hope that this account of my investigations proves useful to anyone else wondering about microkernel-based systems and L4Re in particular, especially if they too wish there were more discussion, reflection and collaboration on the design and implementation of software for these kinds of systems.