Considering Unexplored Products of the Past: Formulating a Product
Friday, February 10th, 2023Previously, I described exploring the matter of developing emulation of a serial port, along with the necessary circuitry, for Elkulator, an emulator for the Acorn Electron microcomputer, motivated by a need to provide a way of transferring files into and out of the emulated computer. During this exploration, I had discovered some existing software that had been developed to provide some level of serial “filing system” support on the BBC Microcomputer – the higher-specification sibling of the Electron – with the development of this software having been motivated by an unforeseen need to transfer software to a computer without any attached storage devices.
This existing serial filing system software was a good indication that serial communications could provide the basis of a storage medium. But instead of starting from a predicament involving computers without usable storage facilities, where an unforeseen need motivates the development of a clever workaround, I wanted to consider what such a system might have been like if there had been a deliberate plan from the very beginning to deploy computers that would rely on a serial connection for all their storage needs. Instead of having an implementation of the filing system in RAM, one could have the luxury of putting it into a ROM chip that would be fitted in the computer or in an expansion, and a richer set of features might then be contemplated.
A Smarter Terminal
Once again, my interest in the historical aspects of the technology provided some guidance and some inspiration. When microcomputers started to become popular and businesses and institutions had to decide whether these new products had any relevance to their operations, there was some uncertainty about whether such products were capable enough to be useful or whether they were a distraction from the facilities already available in such organisations. It seems like a lifetime ago now, but having a computer on every desk was not necessarily seen as a guarantee of enhanced productivity, particularly if they did not link up to existing facilities or did not coordinate the work of a number of individuals.
At the start of the 1980s, equipping an office with a computer on every desk and equipping every computer with a storage solution was an expensive exercise. Even disk drives offering only a hundred kilobytes of storage on each removable floppy disk were expensive, and hard disk drives were an especially expensive and precious luxury that were best shared between many users. Some microcomputers were marketed as multi-user systems, encouraging purchasers to connect terminals to them and to share those precious resources: precisely the kind of thing that had been done with minicomputers and mainframes. Such trends continued into the mid-1980s, manifested by products promoted by companies with mainframe origins, such companies perpetuating entrenched tendencies to frame computing solutions in certain ways.
Terminals themselves were really just microcomputers designed for the sole purpose of interacting with a “host” computer, and institutions already operating mainframes and minicomputers would have experienced the need to purchase several of them. Until competition intensified in the terminal industry, such products were not particularly cheap, with the DEC VT220 introduced in 1983 costing $1295 at its introduction. Meanwhile, interest in microcomputers and the possibility of distributing some kinds of computing activity to these new products, led to experimentation in some organisations. Some terminal manufacturers responded by offering terminals that also ran microcomputer software.
Much of the popular history of microcomputing, familiar to anyone who follows such topics online, particularly through YouTube videos, focuses on adoption of such technology in the home, with an inevitable near-obsession with gaming. The popular history of institutional adoption often focuses on the upgrade parade from one generation of computer to the next. But there is a lesser told history involving the experimentation that took place at the intersection of microcomputing and minicomputing or mainframe computing. In universities, computers like the BBC Micro were apparently informally introduced as terminals for other systems, terminal ROMs were developed and shared between institutions. However, there seems to have been relatively little mainstream interest in such software as fully promoted commercial products, although Acornsoft – Acorn’s software outlet – did adopt such a ROM to sell as their Termulator product.
The Acorn Electron, introduced at £199, had a “proper” keyboard and the ability to display 80 columns of text, unlike various other popular microcomputers. Indeed, it may have been the lowest-priced computer to be able to display 80 columns of relatively high definition text as standard, such capabilities requiring extra cards for machines like the Apple II and the Commodore 64. Considering the much lower price of such a computer, the ongoing experimentation underway at the time with its sibling machine on alternative terminal solutions, and the generally favourable capabilities of both these machines, it seems slightly baffling that more was not done to pursue opportunities to introduce a form of “intelligent terminal” or “hybrid terminal” product to certain markets.
VIEW in 80 columns on the Acorn Electron.
None of this is to say that institutional users would have been especially enthusiastic. In some institutions, budgets were evidently generous enough that considerable sums of money would be spent acquiring workstations that were sometimes of questionable value. But in others, the opportunity to make savings, to explore other ways of working, and perhaps also to explicitly introduce microcomputing topics such as software development for lower-specification hardware would have been worthy of some consideration. An Electron with a decent monochrome monitor, like the one provided with the M2105, plus some serial hardware, could have comprised a product sold for perhaps as little as £300.
The Hybrid Terminal
How would a “hybrid terminal” solution work, how might it have been adopted, and what might it have been used for? Through emulation and by taking advantage of the technological continuity in multi-user systems from the 1980s to the present day, we can attempt to answer such questions. Starting with communications technologies familiar in the world of the terminal, we might speculate that a serial connection would be the most appropriate and least disruptive way of interfacing a microcomputer to a multi-user system.
Although multi-user systems, like those produced by Digital Equipment Corporation (DEC), might have offered network connectivity, it is likely that such connectivity was proprietary, expensive in terms of the hardware required, and possibly beyond the interfacing capabilities of most microcomputers. Meanwhile, Acorn’s own low-cost networking solution, Econet, would not have been directly compatible with these much higher-end machines. Acorn’s involvement in network technologies is also more complicated than often portrayed, but as far as Econet is concerned, only much later machines would more conveniently bridge the different realms of Econet and standards-based higher-performance networks.
Moreover, it remains unlikely that operators and suppliers of various multi-user systems would have been enthusiastic about fitting dedicated hardware and installing dedicated software for the purpose of having such systems communicate with third-party computers using a third-party network technology. I did find it interesting that someone had also adapted Acorn’s network filing system that usually runs over Econet to work instead over a serial connection, which presumably serves files out of a particular user account. Another discovery I made was a serial filing system approach by someone who had worked at Acorn who wanted to transfer files between a BBC Micro system and a Unix machine, confirming that such functionality was worth pursuing. (And there is also a rather more complicated approach involving more exotic Acorn technology.)
Indeed, to be successful, a hybrid terminal approach would have to accommodate existing practices and conventions as far as might be feasible in order to not burden or disturb the operators of these existing systems. One motivation from an individual user’s perspective might be to justify introducing a computer on their desk, to be able to have it take advantage of the existing facilities, and to augment those facilities where it might be felt that they are not flexible or agile enough. Such users might request help from the operators, but the aim would be to avoid introducing more support hassles, which would easily arise if introducing a new kind of network to the mix. Those operators would want to be able to deploy something and have it perform a role without too much extra thought.
I considered how a serial link solution might achieve this. An existing terminal would be connected to, say, a Unix machine and be expected to behave like a normal client, allowing the user to log into their account. The microcomputer would send some characters down the serial line to the Unix “host”, causing it to present the usual login prompt, and the user would then log in as normal. They would then have the option of conducting an interactive session, making their computer like a conventional terminal, but there would also be the option of having the Unix system sit in the background, providing other facilities on request.
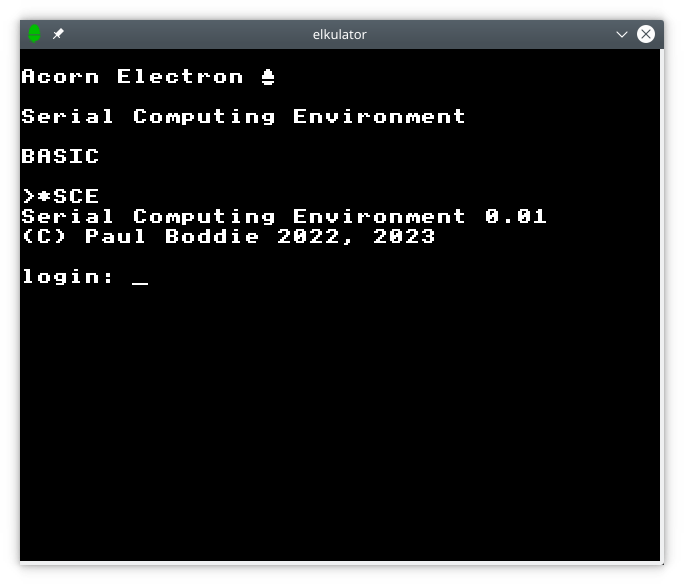
Logging into a remote service via a serial connection.
The principal candidates for these other facilities would be file storage and printing. Both of these things were centrally managed in institutions, often available via the main computing service, and the extensible operating system of the Electron and related microcomputers invites the development of software to integrate the core support for these facilities with such existing infrastructure. Files would be loaded from the user’s account on the multi-user system and saved back there again. Printing would spool the printed data to files somewhere in the user’s home directory for queuing to centralised printing services.
Attempting an Implementation
I wanted to see how such a “serial computing environment” would work in practice, how it would behave, what kinds of applications might benefit, and what kind of annoyances it might have. After all, it might be an interesting idea or a fun idea, but it need not be a particularly good one. The first obstacle was that of understanding how the software elements would work, primarily on the Electron itself, from the tasks that I would want the software to perform down to the way the functionality would be implemented. On the host or remote system, I was rather more convinced that something could be implemented since it would mostly be yet another server program communicating over a stream, with plenty of modern Unix conveniences to assist me along the way.
As it turned out, my investigations began with a trip away from home and the use of a different, and much more constrained, development environment involving an ARM-based netbook. Fortunately, Elkulator and the different compilers and tools worked well enough on that development hardware to make the exercise approachable. Another unusual element was that I was going to mostly rely on the original documentation in the form of the actual paper version of the Acorn Electron Advanced User Guide for information on how to write the software for the Electron. It was enlightening coming back to this book after a few decades for assistance on a specific exercise, even though I have perused the book many times in its revised forms online, because returning to it with a focus on a particular task led me to find that the documentation in the book was often vague or incomplete.
Although the authors were working in a different era and presumably under a degree of time pressure, I feel that the book in some ways exhibits various traits familiar to those of us working in the software industry, these indicating a lack of rigour and of sufficient investment in systems documentation. For this, I mostly blame the company who commissioned the work and then presumably handed over some notes and told the authors to fill in the gaps. As if to strengthen such perceptions of hurriedness and lack of review, it also does not help that “system” is mis-spelled “sysem” in a number of places in the book!
Nevertheless, certain aspects of the book were helpful. The examples, although focusing on one particular use-case, did provide helpful detail in deducing the correct way of using certain mechanisms, even if they elected to avoid the correct way of performing other tasks. Acorn’s documentation had a habit of being “preachy” about proper practices, only to see its closest developers ignore those practices, anyway. Eventually, on returning from my time away, I was able to fill in some of the gaps, although by this time I had a working prototype that was able to do basic things like initiate a session on the host system and to perform some file-related operations.
There were, and still are, a lot of things that needed, and still need, improvement with my implementation. The way that the operating system needs to be extended to provide extra filing system functionality involves plenty of programming interfaces, plenty of things to support, and also plenty of opportunities for things to go wrong. The VIEW word processor makes use of interfaces for both whole-file loading and saving as well as random-access file operations. Missing out support for one or the other will probably not yield the desired level of functionality.
There are also intricacies with regard to switching printing on and off – this typically being done using control characters sent through the output stream – and of “spool” files which capture character output. And filing system ROMs need to be initialised through a series of “service calls”, these being largely documented, but the overall mechanism is left largely undescribed in the documentation. It is difficult enough deciphering the behaviour of the Electron’s operating system today, with all the online guidance available in many forms, so I cannot imagine how difficult it would have been as a third party to effectively develop applications back in the day.
Levels of Simulation
To support the activities of the ROM software in the emulated Electron, I had to develop a server program running on my host computer. As noted above, this was not onerous, especially since I had already written a program to exercise the serial communications and to interact with the emulated serial port. I developed this program further to respond to commands issued by my ROM, performing host operations and returning results. For example, the CAT command produces a “catalogue” of files in a host directory, and so my server program performs a directory listing operation, collects the names of the files, and then sends them over the virtual serial link to the ROM for it to display to the user.
To make the experience somewhat authentic and to approximate to an actual deployment environment, I included a simulation of the login prompt so that the user of the emulated Electron would have to log in first, with the software also having to deal with a logged out (or not yet logged in) condition in a fairly graceful way. To ensure that they are logged in, a user selects the Serial Computing Environment using the *SCE command, this explicitly selecting the serial filing system, and the login dialogue is then presented if the user has not yet logged into the remote host. Once logged in, the ROM software should be able to test for the presence of the command processor that responds to issued commands, only issuing commands if the command processor has signalled its presence.
Although this models a likely deployment environment, I wanted to go a bit further in terms of authenticity, and so I decided to make the command processor a separate program that would be installed in a user account on a Unix machine. The user’s profile script would be set up to run the command processor, so that when they logged in, this program would automatically run and be ready for commands. I was first introduced to such practices in my first workplace where a menu-driven, curses-based program I had written was deployed so that people doing first-line technical support could query the database of an administrative system without needing to be comfortable with the Unix shell environment.
For complete authenticity I would actually want to have the emulated Electron contact a Unix-based system over a physical serial connection, but for now I have settled for an arrangement whereby a pseudoterminal is created to run the login program, with the terminal output presented to the emulator. Instead of seeing a simulated login dialogue, the user now interacts with the host system’s login program, allowing them to log into a real account. At that point, the command processor is invoked by the shell and the user gets back control.
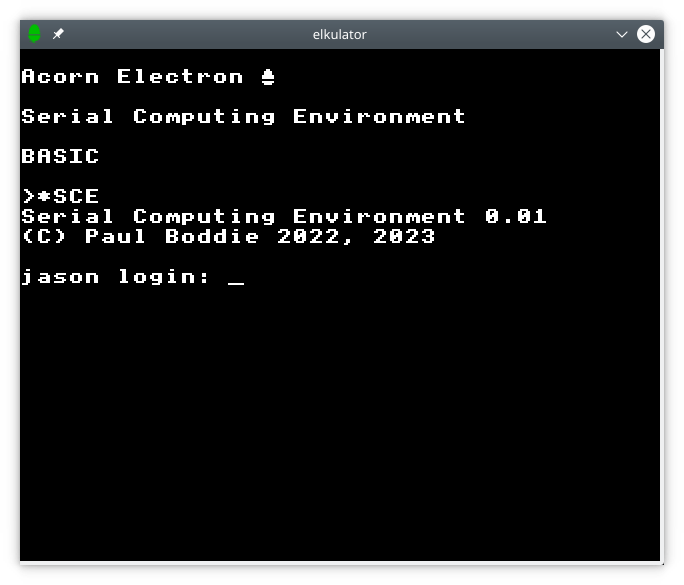
Obtaining a genuine login dialogue from a Unix system.
To prevent problems with certain characters, the command processor configures the terminal to operate in raw mode. Apart from that, it operates mostly as it did when run together with the login simulation which did not have to concern itself with such things as terminals and login programs.
Some Applications
This effort was motivated by the need or desire to be able to access files from within Elkulator, particularly from applications such as VIEW. Naturally, VIEW is really just one example from the many applications available for the Electron, but since it interacts with a range of functionality that this serial computing environment provides, it serves to showcase such functionality fairly well. Indeed, some of the screenshots featured in this and the previous article show VIEW operating on text that was saved and loaded over the serial connection.
Accessing files involves some existing operating system commands, such as *CAT (often abbreviated to *.) to list the catalogue of a storage medium. Since a Unix host supports hierarchical storage, whereas the Electron’s built-in command set only really addresses the needs of a flat storage medium (as provided by various floppy disk filing systems for Electron and BBC Micro), the *DIR command has been introduced from Acorn’s hierarchical filing systems (such as ADFS) to navigate between directories, which is perhaps confusing to anyone familiar with other operating systems, such as the different variants of DOS and their successors.
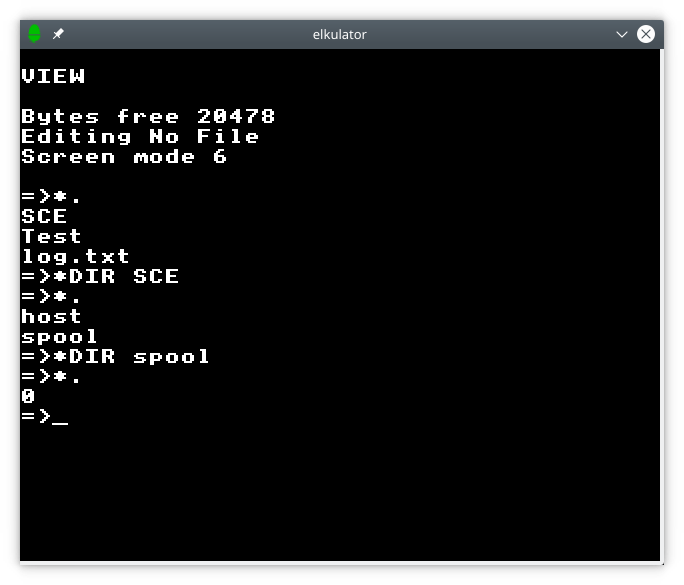
Using catalogue and directory traversal commands.
VIEW allows documents to be loaded and saved in a number of ways, but as a word processor it also needs to be able to print these documents. This might be done using a printer connected to a parallel port, but it makes a bit more sense to instead allow the serial printer to be selected and for printing to occur over the serial connection. However, it is not sufficient to merely allow the operating system to take over the serial link and to send the printed document, if only because the other side of this link is not a printer! Indeed, the command processor is likely to be waiting for commands and to see the incoming data as ill-formed input.
The chosen solution was to intercept attempts to send characters to a serial printer, buffering them and then sending the buffered data in special commands to the command processor. This in turn would write the printed characters to a “spool” file for each printing session. From there, these files could be sent to an appropriate printer. This would give the user rather more control over printing, allowing them to process the printout with Unix tools, or to select one particular physical printer out of the many potentially available in an organisation. In the VIEW environment, and in the MOS environment generally, there is no built-in list of printers or printer selection dialogue.
Since the kinds of printers anticipated for use with VIEW might well have been rather different from the kinds connected to multi-user systems, it is likely that some processing would be desirable where different text styles and fonts have been employed. Today, projects like PrinterToPDF exist to work with old-style printouts, but it is conceivable that either the “printer driver generator” in the View suite or some postprocessing tool might have been used to produce directly printable output. With unstyled text, however, the printouts are generally readable and usable, as the following excerpt illustrates.
A brief report on the experience of using VIEW as a word processor four decades on. Using VIEW on the Acorn Electron is an interesting experience and a glimpse into the way word processing was once done. Although I am a dedicated user of Vim, I am under no illusions of that program's word processing capabilities: it is deliberately a screen editor based on line editor heritage, and much of its operations are line-oriented. In contrast, VIEW is intended to provide printed output: it presents the user with a ruler showing the page margins and tab stops, and it even saves additional rulers into the stored document in their on-screen representations. Together with its default typewriter-style behaviour of allowing the cursor to be moved into empty space and of overwriting or replacing text, there is a quaint feel to it.
Since VIEW is purely text-based, I can easily imagine converting its formatting codes to work with troff. That would then broaden the output options. Interestingly, the Advanced User Guide was written in VIEW and then sent to a company for typesetting, so perhaps a workflow like this would have been useful for the authors back then.
A major selling point of the Electron was its provision of BBC BASIC as the built-in language. As the BBC Micro had started to become relatively widely adopted in schools across the United Kingdom, a less expensive computer offering this particular dialect of BASIC was attractive to purchasers looking for compatibility with school computers at home. Obviously, there is a need to be able to load and save BASIC programs, and this can be done using the serial connection.
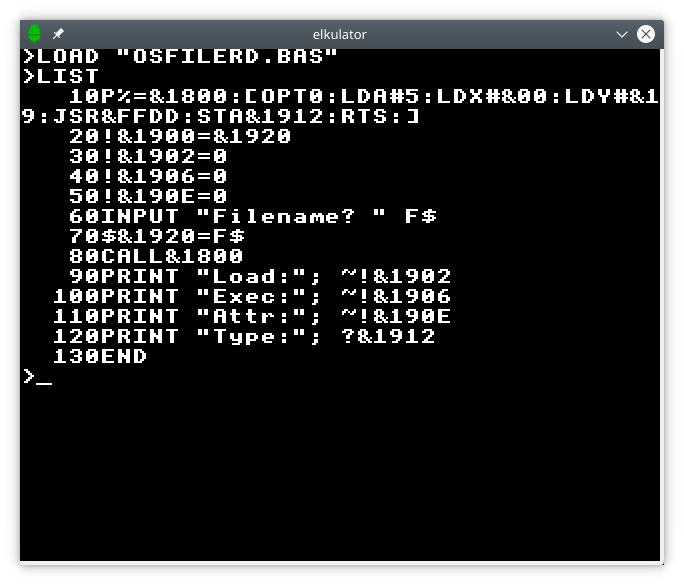
Loading a BASIC program from the Unix host.
Beyond straightforward operations like these, BASIC also provides random-access file operations through various keywords and constructs, utilising the underlying operating system interfaces that invoke filing system operations to perform such work. VIEW also appears to use these operations, so it seems sensible not to ignore them, even if many programmers might have preferred to use bulk transfer operations – the standard load and save – to get data in and out of memory quickly.
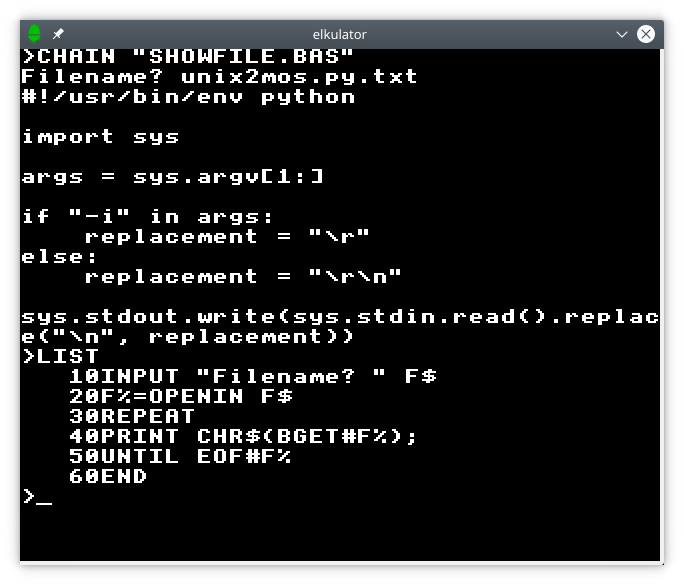
A BASIC program reading and showing a file.
Interactions between printing, the operating system’s own spooling support, outputting characters and reading and writing data are tricky. A degree of experimentation was required to make these things work together. In principle, it should be possible to print and spool at the same time, even with output generated by the remote host that has been sent over the serial line for display on the Electron!
Of course, as a hybrid terminal, the exercise would not be complete without terminal functionality. Here, I wanted to avoid going down another rabbit hole and implementing a full terminal emulator, but I still wanted to demonstrate the invocation of a shell on the Unix host and the ability to run commands. To show just another shell session transcript would be rather dull, so here I present the perusal of a Python program to generate control codes that change the text colour on the Electron, along with the program’s effects:
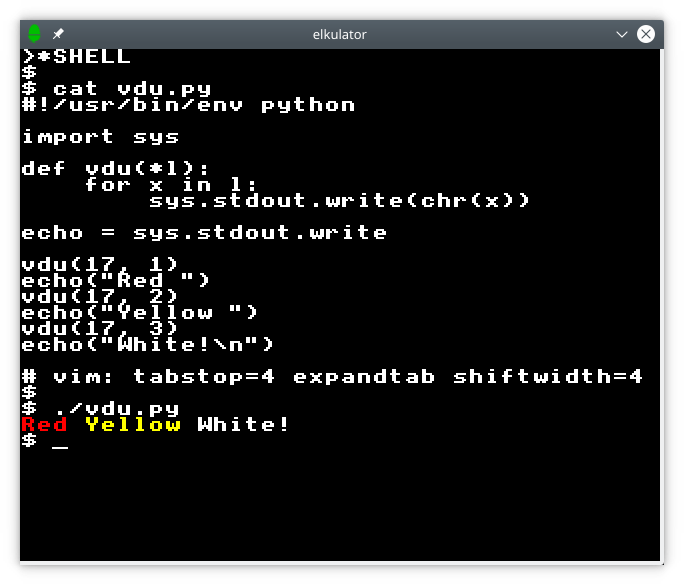
Interaction with the shell featuring multiple text colours.
As a bitmapped terminal, the Electron is capable of much more than this. Although limited to moderate resolutions by the standards of the fanciest graphics terminals even of that era, there are interesting possibilities for Unix programs and scripts to generate graphical output.
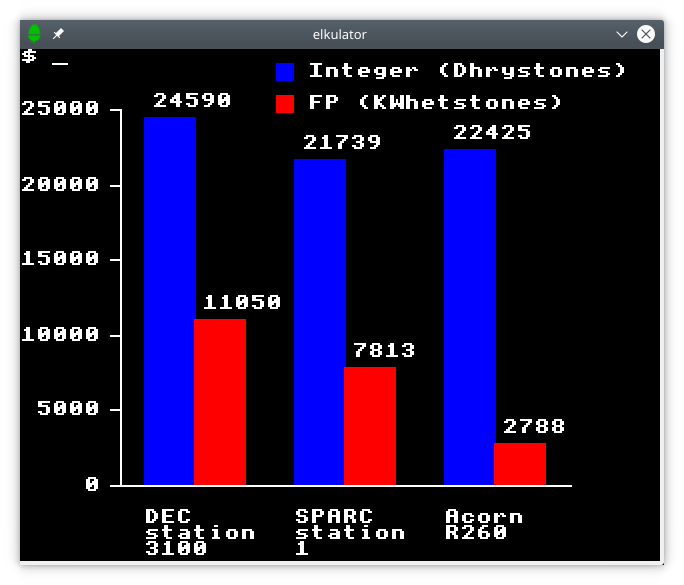
A chart generated by a Python program showing workstation performance results.
Sending arbitrary character codes requires a bit of terminal configuration magic so that line feeds do not get translated into other things (the termios manual page is helpful, here, suggesting the ONLCR flag as the culprit), but the challenge, as always, is to discover the piece of the stack of technologies that is working against you. Similar things can be said on the Electron as well, with its own awkward confluence of character codes for output and output control, requiring the character output state to be tracked so that certain values do not get misinterpreted in the wrong context.
Others have investigated terminal connectivity on Acorn’s 8-bit microcomputers and demonstrated other interesting ways of producing graphical output from Unix programs. Acornsoft’s Termulator could even emulate a Tektronix 4010 graphical terminal. Curiously, Termulator also supported file transfer between a BBC Micro and the host machine, although only as a dedicated mode and limited to ASCII-only text files, leaving the hybrid terminal concept unexplored.
Reflections and Remarks
I embarked on this exercise with some cautiousness, knowing that plenty of uncertainties lay ahead in implementing a functional piece of software, and there were plenty of frustrating moments as some of the different elements of the rather underdocumented software stack conspired to produce undesirable behaviour. In addition, the behaviour of my serial emulation code had a confounding influence, requiring some low-level debugging (tracing execution within the emulator instruction by instruction, noting the state of the emulated CPU), some slowly dawning realisations, and some adjustments to hopefully make it work in a more cooperative fashion.
There are several areas of potential improvement. I first programmed in 6502 assembly language maybe thirty-five years ago, and although I managed to get some sprite and scrolling routines working, I never wrote any large programs, nor had to interact with the operating system frameworks. I personally find the 6502 primitive, rigid, and not particularly conducive to higher-level programming techniques, and I found myself writing some macros to take away the tedium of shuffling values between registers and the stack, constantly aware of various pitfalls with regard to corrupting registers.
My routines extending the operating system framework possibly do not do things the right way or misunderstand some details. That, I will blame on the vague documentation as well as any mistakes made micromanaging the registers. Particularly frustrating was the way that my ROM code would be called with interrupts disabled in certain cases. This made implementation challenging when my routines needed to communicate over the serial connection, when such communication itself requires interrupts to be enabled. Quite what the intention of the MOS designers was in such circumstances remains something of a mystery. While writing this article, I realised that I could have implemented the printing functionality in a different way, and this might have simplified things, right up to the point where I saw, thanks to the debugger provided by Elkulator, that the routines involved are called – surprise! – with interrupts disabled.
Performance could be a lot better, with this partly due to my own code undoubtedly requiring optimisation. The existing software stack is probably optimised to a reasonable extent, but there are various persistent background activities that probably steal CPU cycles unnecessarily. One unfortunate contributor to performance limitations is the hardware architecture of the Electron. Indeed, I discovered while testing in one of the 80-column display modes that serial transfers were not reliable at the default transfer rate of 9600 baud, instead needing to be slowed down to only 2400 baud. Some diagnosis confirmed that the software was not reading the data from the serial chip quickly enough, causing an overflow condition and data being lost.
Motivated by cost reduction and product positioning considerations – the desire to avoid introducing a product that might negatively affect BBC Micro sales – the Electron was deliberately designed to use a narrow data bus to fewer RAM chips than otherwise would have been used, with a seemingly clever technique being employed to allow the video circuitry to get the data at the desired rate to produce a high-resolution or high-bandwidth display. Unfortunately, the adoption of the narrow data bus, facilitated by the adoption of this particular technique, meant that the CPU could only ever access RAM at half its rated speed. And with the narrow data bus, the video circuitry effectively halts the CPU altogether for a substantial portion of its time in high-bandwidth display modes. Since serial communications handling relies on the delivery and handling of interrupts, if the CPU is effectively blocked from responding quickly enough, it can quickly fall behind if the data is arriving and the interrupts are occurring too often.
That does raise the issue of reliability and of error correction techniques. Admittedly, this work relies on a reliable connection between the emulated Electron and the host. Some measures are taken to improve the robustness of the communication when messages are interrupted so that the host in particular is not left trying to send or receive large volumes of data that are no longer welcome or available, and other measures are taken to prevent misinterpretation of stray data received in a different and thus inappropriate context. I imagine that I may have reinvented the wheel badly here, but these frustrations did provide a level of appreciation of the challenges involved.
Some Broader Thoughts
It is possible that Acorn, having engineered the Electron too aggressively for cost, made the machine less than ideal for the broader range of applications for which it was envisaged. That said, it should have been possible to revise the design and produce a more performant machine. Experiments suggest that a wider data path to RAM would have helped with the general performance of the Electron, but to avoid most of the interrupt handling problems experienced with the kind of application being demonstrated here, the video system would have needed to employ its existing “clever” memory access technique in conjunction with that wider data path so as to be able to share the bandwidth more readily with the CPU.
Contingency plans should have been made to change or upgrade the machine, if that had eventually been deemed necessary, starting at the point in time when the original design compromises were introduced. Such flexibility and forethought would also have made a product with a longer appeal to potential purchasers, as opposed to a product that risked being commercially viable for only a limited period of time. However, it seems that the lessons accompanying such reflections on strategy and product design were rarely learned by Acorn. If lessons were learned, they appear to have reinforced a particular mindset and design culture.
Virtue is often made of the Acorn design philosophy and the sometimes rudely expressed and dismissive views of competing technologies that led the company to develop the ARM processor. This approach enabled comparatively fast and low-cost systems to be delivered by introducing a powerful CPU to do everything in a system from running applications to servicing interrupts for data transfers, striving for maximal utilisation of the available memory bandwidth by keeping the CPU busy. That formula worked well enough at the low end of the market, but when the company tried to move upmarket once again, its products were unable to compete with those of other companies. Ultimately, this sealed the company’s fate, even if more fortuitous developments occurred to keep ARM in the running.
(In the chart shown earlier demonstating graphical terminal output and illustrating workstation performance, circa 1990, Acorn’s R260 workstation is depicted as almost looking competitive until one learns that the other workstations depicted arrived a year earlier and that the red bar showing floating-point performance only applies to Acorn’s machine three years after its launch. It would not be flattering to show the competitors at that point in history, nor would it necessarily be flattering to compare whole-system performance, either, if any publication sufficiently interested in such figures had bothered to do so. There is probably an interesting story to be told about these topics, particularly how Acorn’s floating-point hardware arrived so late, but I doubt that there is the same willingness to tell it as there is to re-tell the usual celebratory story of ARM for the nth time.)
Acorn went on to make the Communicator as a computer that would operate in a kind of network computing environment, relying on network file servers to provide persistent storage. It reused some of the technology in the Electron and the BT Merlin M2105, particularly the same display generator and its narrow data bus to RAM, but ostensibly confining that aspect of the Electron’s architecture to a specialised role, and providing other facilities for applications and, as in the M2105, for interaction with peripherals. Sadly, the group responsible in Acorn had already been marginalised and eventually departed, apparently looking to pursue the concept elsewhere.
As for this particular application of an old computer and a product that was largely left uncontemplated, I think there probably was some mileage in deploying microcomputers in this way, even outside companies like Acorn where such computers were being developed and used, together with software development companies with their own sophisticated needs, where minicomputers like the DEC VAX would have been available for certain corporate or technical functions. Public (or semi-public) access terminals were fairly common in universities, and later microcomputers were also adopted in academia due to their low cost and apparently sufficient capabilities.
Although such adoption appears to have focused on terminal applications, it cannot have been beyond the wit of those involved to consider closer integration between the microcomputing and multi-user environments. In further and higher education, students will have had microcomputing experience and would have been able to leverage their existing skills whilst learning new ones. They might have brought their microcomputers along with them, giving them the opportunity to transfer or migrate their existing content – their notes, essays, programs – to the bright and emerging new world of Unix, as well as updating their expertise.
As for updating my own expertise, it has been an enlightening experience in some ways, and I may well continue to augment the implemented functionality, fix and improve things, and investigate the possibilities this work brings. I hope that this rather lengthy presentation of the effort has provided insights into experiences of the past that was and the past that might have been.