For et par år siden satte Universitetet i Oslo i gang en prosess for å vurdere gruppevareløsninger (systemer som skal motta, lagre og sende organisasjonens e-postmeldinger og samtidig tillate lagring og deling av kalenderinformasjon som avtaler og møter). Prosessen vurderte et ukjent antall løsninger, droppet alle bortsett fra fire hovedkandidater, og lot være å vurdere en av kandidatene fordi den var det eksisterende kalendersystemet i bruk hos universitetet. Prosessens utfall var en oppsummering av de tre gjenstående løsningene med fordeler og ulemper beskrevet i en 23-siders rapport.
Rapportens konklusjon var at én av løsningene ikke nådde opp til forventninger omkring brukervennlighet eller åpenhet, én hadde tilstrekkelig brukervennlighet og baseres på fri programvare og åpne standarder, og én ble betraktet som å være mest brukervennlig selv om den baseres på et proprietært produkt og proprietære teknologier. Det ble skrevet at universitetet kunne “eventuelt” drifte begge de to sistnevnte løsningene men at den åpne bør foretrekkes med mindre noen spesielle strategiske hensyn styrer valget mot den proprietære, og om det skulle være tilfellet, så ville implementeringen innebære en betydelig arbeidsmengde for institusjonens IT-organisasjon.
Man kan vel komme med kritikk til måten selve prosessen ble utført, men etter å ha lest rapporten ville man trodd at i en offentlig organisasjon som ofte sliter med å dekke alle behov med tilstrekkelige midler, ville man valgt løsningen som fortsetter “tradisjonen” for åpne løsninger og ikke belastet organisasjonen med “ressurskrevende innføring” og andre ulemper. Prosjektets konklusjonen, derimot, var at universitetet skulle innføre Microsoft Exchange – den proprietære løsningen – og dermed skifte ut vesentlige deler av institusjonens infrastruktur for e-post, overføre lagrede meldinger til den proprietære Exchange løsningen, og flytte brukere til nye programvarer og systemer.
Man begynner å få en følelse at på et eller annet sted i ledelseshierarkiet noen har sagt “jeg må ha”, og ettersom ingen har nektet dem noe de “måtte ha” tidligere i livet, så har de fått det de “måtte ha” i denne situasjonen også. Man får også en følelse at rapporten i sitt endelige utkast ble formulert slik at beslutningstakerne raskt kunne avfeie ulempene og risikoene og så få “grønt lys” for et valg de ville ta helt på begynnelsen av prosessen: når det står i “svart på hvitt” at innføringen av den forhåndsutvalgte løsningen er gjennomførbar, føler de at de har alt de trenger for å bare sette i gang, koster det som det bare må.
For Nyhets Skyld
Men tilbake til prosessen. Det første som forbauset meg med prosessen var at man skulle vurdere implementering av helt nye systemer i det hele tatt. Prosessen fikk sin opprinnelse i et tilsynelatende behov for en “integrert” e-post- og kalenderløsning: noe som anses som ganske uviktig hos mange, men man kan ikke nekte for at noen ville opplevd en slik integrasjon av tjenester som nyttig. Men oppgaven å integrere tjenester trenger ikke å innebære en innføring av kun ett stort system som skal dekke alle funksjonelle områder og som skal erstatte alle eksisterende systemer som hadde noe å gjøre med tjenestene som integreres: en slik forenklet oppfatning av hvordan teknologiske systemer fungerer ville føre til at man insisterer at hele Internettet drives fra kun én stormaskin eller på kun én teknologisk plattform; alle som har satt seg inn i hvordan nettet fungerer vet at det ikke er slik (selv om noen organisasjoner ville foretrukket at alle kunne overvåkes på ett sted).
Det kan hende at beslutningstakerne faktisk tror på utilstrekkelige og overforenklede modeller av hvordan teknologi anvendes, eller at de velger bare å avfeie virkeligheten med en “få det gjort” mentalitet som lett kobles sammen med vrangforestillingen at ett produkt og én leverandør er som regel “løsningen”. Men infrastruktur i de fleste organisasjonene vil alltid bestå av forskjellige systemer, ofte med forskjellige opphav, som ofte fungerer sammen for å levere det som virker som kun én løsning eller tjeneste til utenforstående. Akkurat dette har faktisk vært situasjonen inne i universitetets infrastruktur for e-post frem til nå. Hvis den nåværende infrastrukturen mangler en forbindelse mellom e-postmeldinger og kalenderdata, hvorfor kan man ikke legge til en ny komponent eller tjeneste for å realisere den manglende integrasjonen som folk savner?
Og så blir det interessant å se nærmere på løsninger som likner på den eksisterende infrastrukturen universitetet bruker, og på produkter og prosjekter som leverer den savnede delen av infrastrukturen. Hvis det finnes liknende løsninger og tilsvarende infrastrukturbeskrivelser, spesielt om de finnes som fri programvare akkurat som programvarene universitetet allerede bruker, og hvis avstanden mellom det som kjøres nå og en fremtidig “fullstendig” løsning består bare av noen tilleggskomponenter og litt arbeid, ville det ikke vært interessant å se litt nærmere på slike ting først?
Gruppevare: Et Perspektiv
Jeg har vært interessert i gruppevare og kalenderløsninger i ganske lenge. For noen år siden utviklet jeg en nettleser-basert applikasjon for å behandle personlige kommunikasjoner og avtaler, og denne brukte eksisterende teknologier og standarder for å utveksle, fremvise og redigere informasjonen som ble lagret og behandlet. Selv om jeg etterhvert ble mindre overbevist på akkurat den måten jeg hadde valgt å implementere applikasjonen, hadde jeg likevel fått et innblikk i teknologiene som brukes og standardene som finnes for å utveksle gruppevaredata. Tross alt, uansett hvordan meldinger og kalenderinformasjon lagres og håndteres må man fortsatt forholde seg til andre programmer og systemer. Og etter at jeg ble mer opptatt av wikisystemer og fikk muligheten til å implementere en kalendertjeneste for en av de mest utbredte wikiløsningene, ble jeg oppmerksom på nytt på standardiseringsretninger, praktiske forhold i implementasjon av gruppevaresystemer, og ikke minst hva slags eksisterende løsninger som fantes.
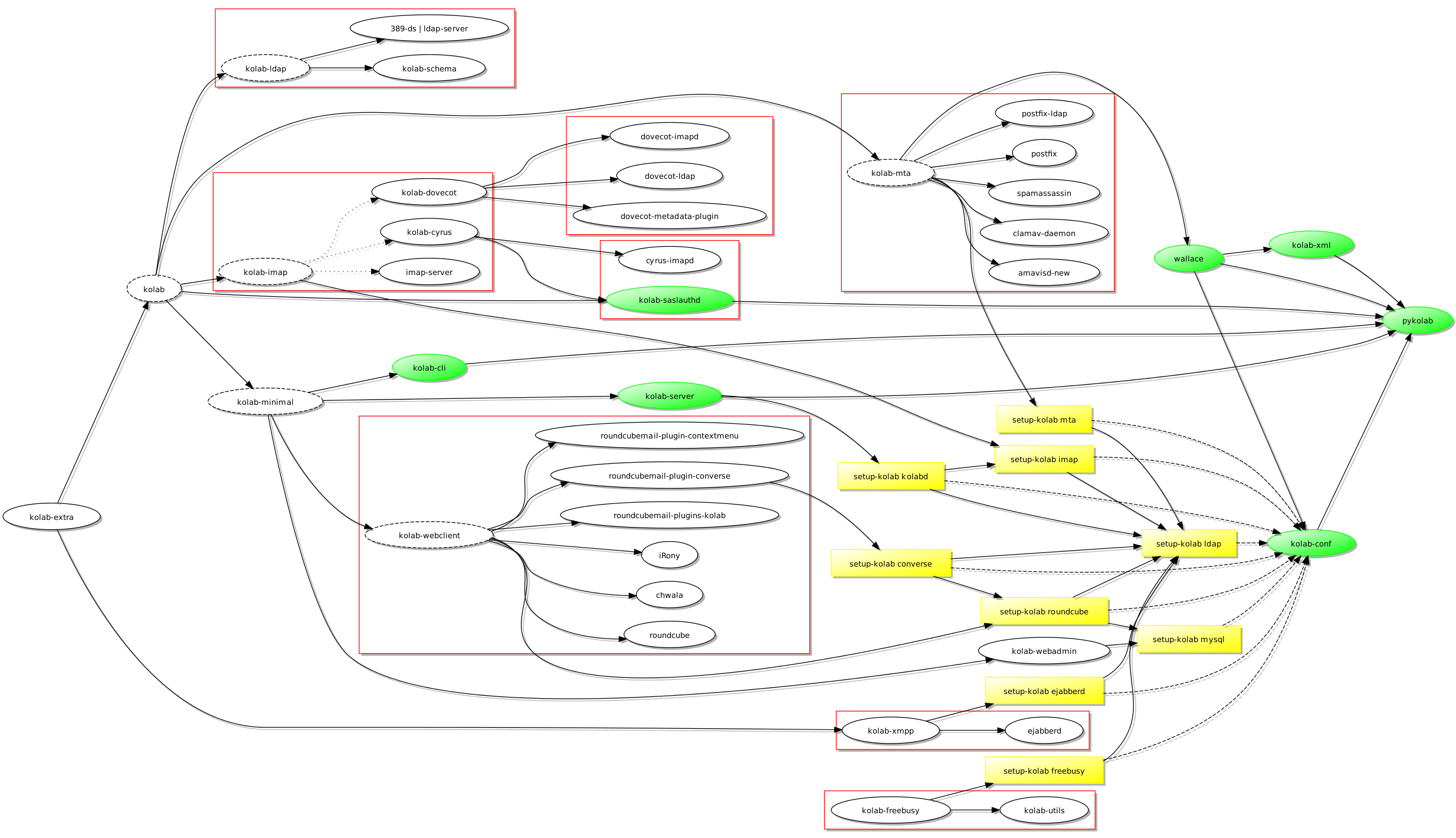
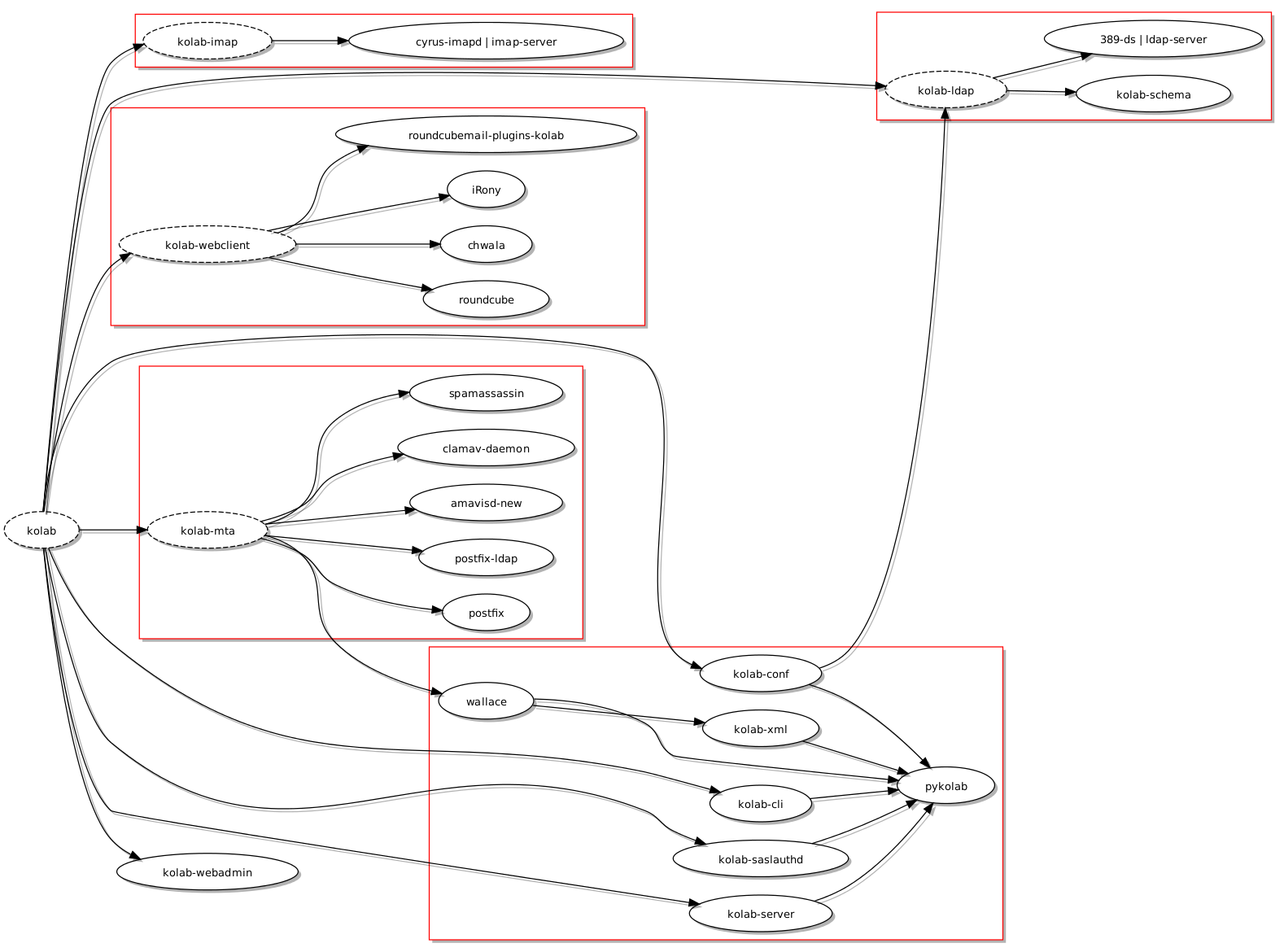
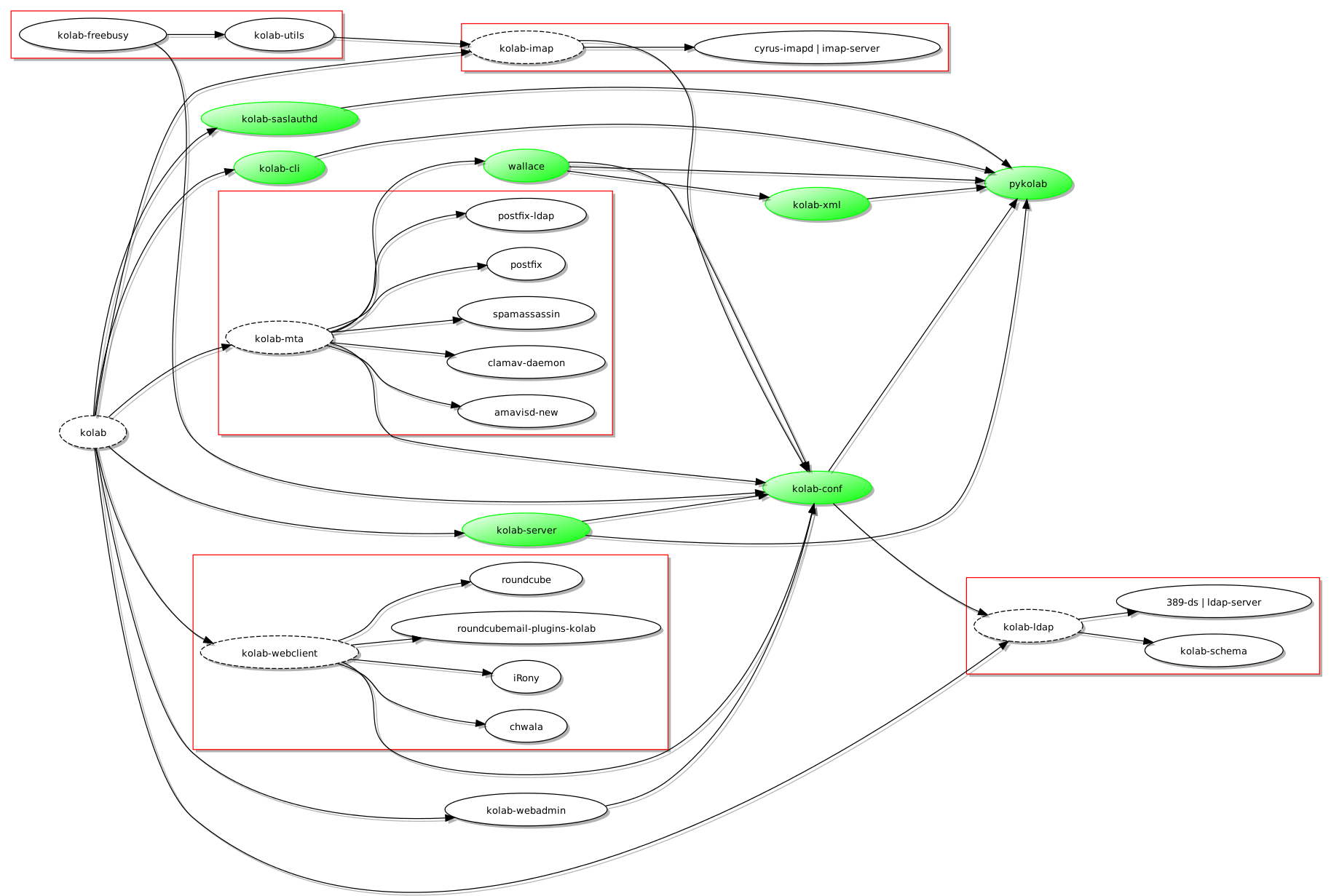
Et gruppevaresystem jeg hadde hørt om for mange år siden var Kolab, som består av noen godt etablerte komponenter og programmer (som også er fri programvare), ettersom produktet og prosjektet bak ble grunnlagt for å styrke tilbudet på serversiden slik at klientprogrammer som Evolution og KMail kunne kommunisere med fullstendige gruppevaretjenester som også ville være fri programvare. Et slikt behov ble identifisert da personer og organisasjoner tilknyttet Kolab leverte en e-postløsning bygget på KMail (med kryptering som viktig element) til en del av den tyske stat. Hvorfor bruke fri programvare kun på klientsiden og dermed måtte tåle skiftende forhold og varierende støtte for åpne standarder og interoperabilitet på serversiden?
Nesten Framme
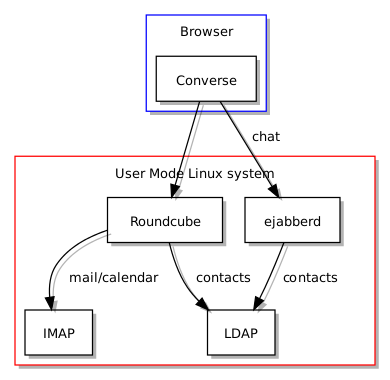
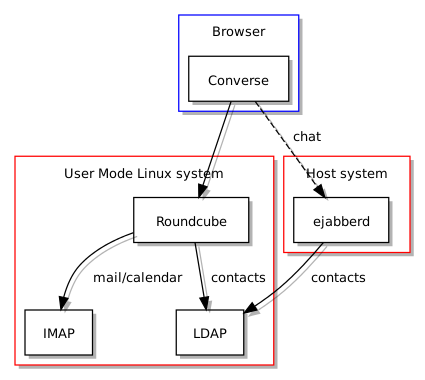
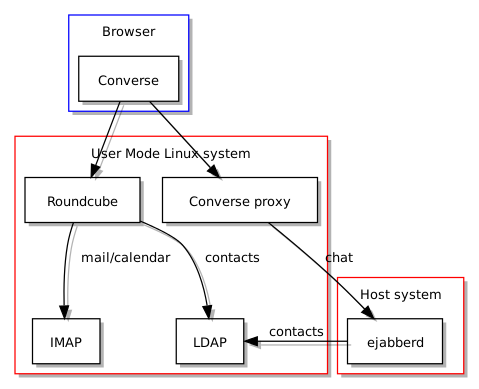
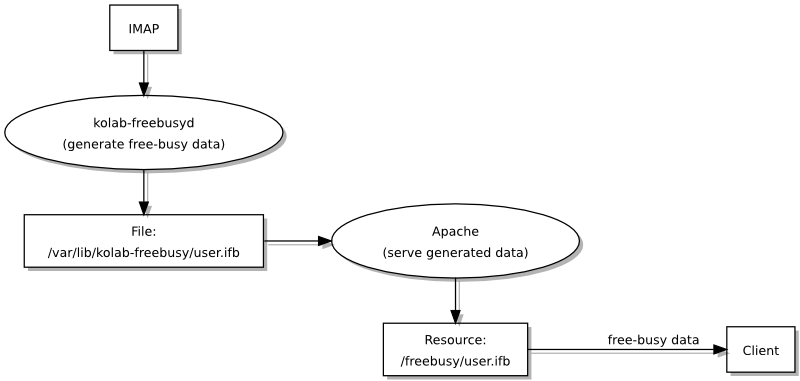
Når man ser på Kolab er det slående hvor mye løsningen har til felles med universitetets nåværende infrastruktur: begge bruker LDAP som autentiseringsgrunnlag, begge bruker felles antispam og antivirus teknologier, og Roundcube står ganske sentralt som “webmail” løsning. Selv om noen funksjoner leveres av forskjellige programvarer, når man sammenlikner Kolab med infrastrukturen til UiO, kan man likevel påstå at avstanden mellom de ulike komponentene som brukes på hver sin side ikke er altfor stor for at man enten kunne bytte ut en komponent til fordel for komponenten Kolab helst vil bruke, eller kunne tilpasse Kolab slik at den kunne bruke den eksisterende komponenten istedenfor sin egen foretrukne komponent. Begge måter å håndtere slike forskjeller kunne benytte dokumentasjonen og ekspertisen som finnes på en mengde steder på nettet og i andre former som bøker og – ikke overraskende – organisasjonens egne fagpersoner.
Man trenger dog egentlig ikke å “bytte” til Kolab i det hele tatt: man kunne ta i bruk delene som dekker manglene i den nåværende infrastrukturen, eller man kunne ta i bruk andre komponenter som kan utføre slike jobber. Poenget er at det finnes alternativer som ligger ganske nær infrastrukturen som brukes i dag, og når man må velge mellom en storslått gjenimplementering av den infrastrukturen eller en mindre oppgradering som sannsynligvis kommer til å levere omtrent det samme resultatet, burde man begrunne og dokumentere avgjørelsen om å ikke se nærmere på slike nærliggende løsninger istedenfor å bare droppe dem fra vurderingen i stillhet og håpe at ingen ville merket at de forsvant uten å bli omtalt i det hele tatt.
I et dokument som oppsummerer prosjektets arbeid står det nettopp at SOGo – den foretrukne åpne løsningen – opptrer som et ledd mellom systemer som allerede er i drift. Man kunne godt tenkt at en vurdering av Kolab ville informert vurderingen av SOGo, og omvendt, slik at forståelsen for en eventuell oppgraderingsløsning kunne blitt grundigere og bedre, og kanskje førte til at en blanding av de mest interessante elementene tas i bruk slik at organisasjonen får ut det beste fra begge (og enda flere) løsninger.
Gjennom Nåløyet
Som skrevet ovenfor er jeg interessert i gruppevare og bestemte meg for å oppdage hvorfor en løsning slik som Kolab (og liknende løsninger, selvsagt) kunne vært fraværende fra sluttrapporten. Selv om det ikke ville vært riktig å publisere samtalene mellom prosjektets talsperson og meg, kan jeg likevel oppsummere det jeg lærte gjennom meldingsutvekslingen: en enkel oversikt over hvilke løsninger som ble vurdert (bortsett fra de som omtales i rapporten) finnes trolig ikke, og prosjektdeltakerne kunne ikke med det første huske hvorfor Kolab ikke ble tatt med til sluttrapporten. Dermed, når rapporten avfeier alt som ikke blir beskrevet i sin tekst, som om det fantes en grundig prosess for å sive ut alt som ikke nådde opp til prosjektets behov, kan dette anses nesten som ren bløff: det finnes ingen bevis for at evalueringen av tilgjengelige løsninger var på noen som helst måte omfattende eller balansert.
Man kan vel hevde at det skader ingen å publisere en rapport på nettet som velger ut verdige systemer for en organisasjons gruppevarebehov – konklusjonene vil naturligvis dreie seg ganske mye om hva slags organisasjon det er som omtales, og man kan alltid lese gjennom teksten og bedømme kompetansen til forfatterne – men det er også tilfellet at andre i samme situasjon ofte vil bruke materialer som likner på det de selv må produsere som utgangspunkt for sitt eget evalueringsarbeid. Når kjente systemer utelates vil lesere kanskje konkludere at slike systemer måtte ha hatt grunnleggende mangler eller vært fullstendig uaktuelle: hvorfor ellers ville de ikke blitt tatt med? Det er flott at organisasjoner foretar slikt arbeid på en åpen måte, men man bør ikke undervurdere propagandaverdien som sitter i en rapport som dropper noen systemer uten begrunnelse slik at systemene som gjenstår kan tolkes som de aller beste eller de eneste relevante, og at andre systemer bare ikke når opp og dermed har ingen plass i slike vurderinger hos andre institusjoner.
Etter litt frem og tilbake ble jeg endelig fortalt at Kolab ikke hadde vist tilstrekkelige livstegn i utvikler- og brukersamfunnet rundt prosjektet, og det var grunnen til at programvaren ikke ble vurdert videre; eksempler trukket frem handlet om prosjektets dokumentasjon som ikke var godt nok oppdatert. Selv om prosjektet har forbedringspotensial i noen områder – jeg har selv foreslått at noe gjøres med wikitjenesten til prosjektet i perioden etter jeg avsluttet mine samtaler med universitetets prosjektdeltakere og begynte å sette meg inn i situasjonen angående fri programvare og gruppevare – må det sies at tilbakemeldingene virket litt forhastede og tilfeldige: e-postlistene til Kolab-prosjektet viser relativt mye aktivitet, og det finnes ikke noen tegn som tyder på at noen fra universitetet tok kontakt med prosjektets utviklersamfunn for å fordype seg i mulige forbedringer i dokumentasjon, fremtidige planer, og muligheter for å gjenbruke kompetanse og materialer for komponenter og systemer som Kolab har til felles med andre løsninger, blant annet de som brukes hos universitetet.
Enda merkeligere var kommentarer fra prosjektgruppen som handlet om Roundcube. Rapporten omtalte Roundcube som en tilstrekkelig løsning som ikke bare brukes frem til i dag hos universitetet, men også ville vært brukt som erstatning for webmail-løsningen i SOGo. Plutselig, ifølge prosjektets talsperson, var Roundcube ikke godt nok i ett navngitt område, men rapporten brukte ikke noen som helst plass om slike påståtte mangler: rart når man tenker at det ville helt sikkert vært en veldig god anledning til å beskrive slike mangler og så forenkle beslutningsgrunnlaget vesentlig. Det han hende at slike ting ble funnet ut i etterkant av rapportens publisering, men man får et inntrykk – begrunnet eller ikke – at slike ting også kan finnes opp i etterkant for å begrunne en avgjørelse som ikke nødvendigvis trenger å bli forankret i faktagrunnlaget.
(Jeg ble bedt om å ikke dele prosjektgruppens oppfatninger om Roundcube med andre i offentligheten, og selv om jeg foreslo at de tok opp de påståtte manglene direkte med Roundcube-prosjektet, er jeg ikke overbevist at de hadde noen som helst hensikt å gjøre det. Beleilig at man kan kritisere noe eller noen uten at de har muligheten til å forklare eller forsvare seg!)
Og til slutt, brukte rapporten en god del plass for å beskrive proprietære Exchange-teknologier og hvordan man kunne få andre systemer til å bruke dem, samtidig som åpne og frie løsninger måtte tilpasses Outlook og det produktets avhengighet på proprietær kommunikasjon for å fungere med alle funksjoner slått på. Relativt lite plass og prioritering ble tildelt alternative klienter. Til tross for bekymringer om Thunderbird – den foretrukne e-postklienten frem til nå – og hvordan den skal utvides med kalenderfunksjon, har jeg aldri sett Kontact eller KMail nevnt en eneste gang, ikke en gang i Linux-sammenheng til tross for at Kontact har vært tilgjengelig i universitetets påbudte Linux-distribusjon – Red Hat Enterprise Linux – i årevis og fungerer helt greit med e-postsystemene som nå skal vrakes. Det kan hende at folk anser Kontact som gammeldags – en holdning jeg oppdaget på IRC for noen uker siden uten at den kunne begrunnes videre eller med mer substans – men den er en moden e-postklient med kalenderfunksjon som har fungert for mange over lengre tid. Pussig at ingen i vurderingsarbeidet vil nevne denne programvaren.
Må Bare Ha
Det begynner med en organisasjon som har godt fungerende systemer som kunne bygges på slik at nye behov tilfredsstilles. Imidlertid, ble det kjørt en prosess som ser ut til å ha begynt med forutsetningen at ingenting kan gjøres med disse godt fungerende systemene, og at de må skiftes ut med “ressurskrevende innføring” til fordel for et proprietært system som skal skape en dypere avhengighet på en beryktet leverandør (og monopolist). Og for å styrke denne tvilsomme forutsetningen ble kjente løsninger utelatt fra vurderingene som ble gjort, tilsynelatende slik at en enklere og “passende” avgjørelse kunne tas.
Inntrykket som blir igjen tyder på at prosessen ikke nødvendigvis ble brukt til å informere avgjørelser, men at avgjørelser informerte eller dirigerte prosessen. Hvorfor dette kan ha skjedd er kanskje en historie for en annen gang: en historie som handler om ulike perspektiver i forhold til etikk, demokrati, og investeringer i kunnskap og kompetanse. Og som man kunne forvente ut ifra det som er skrevet ovenfor, er det ikke nødvendigvis en historie som setter organisasjonens “dirigenter” i et så veldig godt lys.