I’m sitting in the train from Zurich to Burgdorf (Switzerland) and want to report, dear reader, about my first week of KDE (or atm qt) development. It was not really as I planned it, I did not work a whole day on qt and kde, but several hours during the week.
As I told you last week my first week was about an xml indenter. Some years ago when I started to track routes for OpenStreetMap.org my Garmin GPS device spat out bad formatted xml (GPX) files. Bad means here that all of the content was on one line and as I sometimes wanted to extract single tracks me and the dear editor (Kwrite or Kate) had some problems to read and understand it. So then I wished there was a simple possibility to indent and format this piece of … I’m sure there are tools for this and probably I would have found them quite fast but as I didn’t search that much … Now in the last weeks when I played with QtXml and the dom API i stumbled over a simple function which did exactly what I wanted.
And so last week on my train home (other track 😉 I took out my laptop and decided to write this little program to solve my indention problem. 50 lines and 15 minutes later it worked. You can download it here if it’s of any use for you. It takes two arguments (input file and output file name) and a third optional one (number of indention spaces) and is of cource a command line tool. And don’t forget: I’m no code peat – at least not yet.
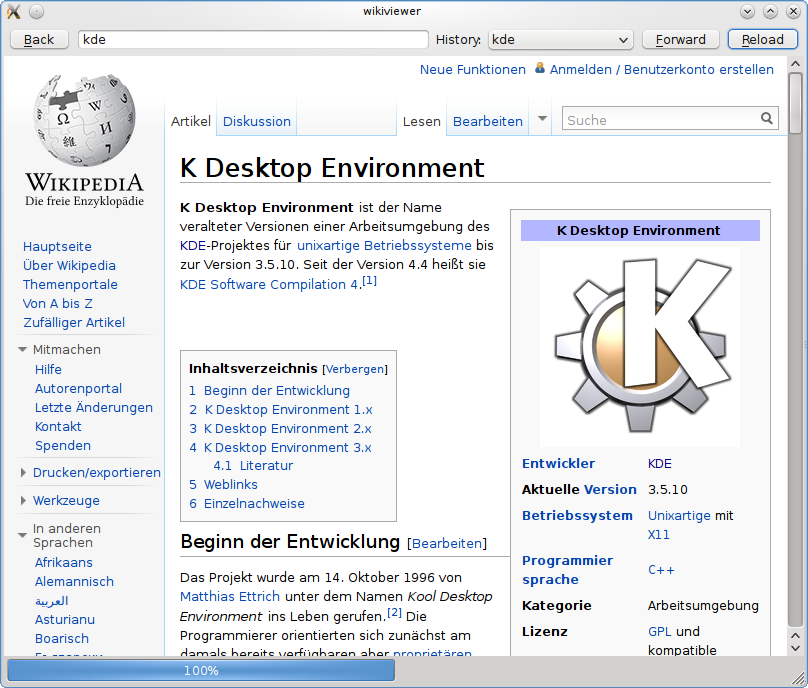
The other project was about a Wikipedia reader or Wikipedia viewer. Almost the same circumstances here. Some weeks or a year ago I already played a bit with Qts WebView component (QtWebkit). It was amazing how easy it was to write a webbrowser ;-). So last Friday on the train (which got broken after ten minutes what gave me more time to hack 😉 (btw it was the same track as this one (and yes I like nesting ;-)) to my girlfriend I did it.
It was amazing for me how easy it was and how good the Qt documentation is. After something like an hour there was it. A simple Wikipedia reader where you just have to write the word or concept you want to search for and it shows you the corresponding Wikipedia article (hopefully even in the right language). If you are a KDE or Qt developer you’ll say how simple this thing is but for me it was a great experience.
As I did not have an internet connection on the train I could not try it out. But the internet connection where my girlfriend (and soon I 😉 live does not yet work for my Debian laptop. So on the other day I thought to myself: let’s try to “port” the Wikipedia reader to her Windows notebook which has internet access. “Port” is in quotation marks because it was not really porting. I download the Qt SDK for Windows (Open Source version of course) which was actually the hardest part of “porting” (not because of Qt or Nokia but because of the lame internet connection).
Two hours later I just copied my wikiviewer folder to a usb stick, plugged it into the Windows laptop, imported the .pro file (waited a moment and yes, I don’t like Windows Vista and yes my girlfriend will get a GNU/Linux installation and yes I asked her ;-), pushed the “Run” button and it worked. It just worked. Sorry, I know. It may be normal for you but I’m amazed.
During the last week and days I did a lot of reading. Beneath the reading of blog posts on planet.kde.org and the lurking and reading of 10 to 20 kde mailing lists I read a lot about RDF (Resource Description Framework), LinkedData, RDFs (RDF schema), OWL, etc. Almost all of the stuff where presentation slides of a course I took a year or so ago at the university about the semantic web. After some reading I wanted myself to visualize some ontologies (the meaning, semantics or vocabulary). And I (re)found the W3C RDF validator which outputs the graphs in different graphics formats.
After downloading the Nepomuk (and here we are finally 😉 ontologies in the RDF/XML format I saw that the validator takes URLs as input as well (anyway I want to work with the RDF/XML version as well). Interestingly three of the ontologies failed to produce a graph (namely the NIE core, the NID3 and the PIMO ontology). I don’t know where the failure is but there could be something wrong.
This blog post gets longer and longer and there is still some stuff remaining (hope somebody likes to read it anyway). During the playing with the Wikipedia reader I recognized that already with such small things and few lines of code a version control system could be handy. So next week I want to read about Git, work and play with it and probably set up a git server (for the Strafful project I need it anyway).
And yes (or no) Strafful will be open source and free software but I won’t publish it before it has some basic features and some things I want it to have. The earliest you’ll see a 1.0 version is January 2011. And no (or yes 😉 It will be about RDF, Nepomuk, the semantic web and the end of Google ;-).
So next week you’ll read here about Git, hopefully about my setup of a KDE development environment (and yes, we need something that easy like the Qt SDK for KDE: choose the platform, download a package and begin to develop. Qt has a great development platform but KDE’s is even better) and probably I’ll tell you what “Strafful”, the name, actually means.
My plan is still that I dedicate a whole weekday for Qt/KDE development, more or less half of it reading documenation (at least at the beginning) and half of it developing. And at most 30 to 45 minutes to write a blog post about it. Hope to be shorter next time and for something somehow unrelated: do you know www.TED.com and the TEDtalks? Great page, visit it!
BTW: Now I miss a feature in Blogilo: checking if all the links work.