Brian Gough’s Notes
occasional GNU-related news
GNU Hackers Meeting in Paris (25 – 28 August 2011)
July 26th, 2011
It’s one month till the next GNU Hackers Meeting in Paris (Thursday 25 August – Sunday 28 August). There are about 45 GNU maintainers and contributors registered so far (details of how to register are on the meeting web page).
Speakers include Jim Meyering on “The perils of relying on output streams in C”, Stefano Zacchiroli (Debian Project Leader) on “Distributions, upstreams and downstreams” and Jim Blandy (Mozilla) on “Extensibility in Firefox” among others.
The meeting is hosted by IRILL, the Initiative de Recherche et Innovation sur le Logiciel Libre at the INRIA building near the Place d’Italie. Looks like a great location:

Some pre-release checks for GNU packages
April 4th, 2011
Here’s a list of pre-release checks I’ve found useful over the years. Most of them should apply to any package, but they’ve been used for a C library (“libfoo” in the examples below, with exported header files foo/*.h and source files src/*.c).
- Make sure all internal functions are static, and all exported functions & variables prefixed with foo_ or FOO_. Here’s a command for checking this:
nm -A -g -P *.a | perl -a -n -e 'print if $F[1] !~ /foo_/ && $F[2] ne "U"'
- Make sure config.h is used consistently – it should be present in source files, but not in any exported headers.
grep config.h foo/*.h --- shouldn't match anything grep -L config.h src/*.c --- gives files not using config.h
- Make a master header file of all exported headers and try compiling it to test for conflicts between different header files.
cat foo/*.h > tmp.c gcc tmp.c
- Check that the library passes “make check” with various options. Some good ones are:
-O3 -mfpmath=sse -msse2 -funsigned-char (to simulate Power/ARM) -std=c89 -ansi -pedantic (now that GCC uses c99 by default instead of c89)
- Test with valgrind. You can run all the tests under valgrind with the TESTS_ENVIRONMENT variable
$ TESTS_ENVIRONMENT="valgrind --tool=memcheck" make check
This only works if configure was run with –disable-shared, because otherwise the shared library libtool shell-scripts themselves are run under valgrind.
Regarding memory leaks, the GNU coding standards say “Memory leak detectors such as valgrind can be useful, but don’t complicate a program merely to avoid their false alarms. For example, if memory is used until just before a process exits, don’t free it simply to silence a leak detector.”
For libraries I’ve found it’s very helpful (actually, essential) to have a test suite that is leak-free. Then if any test program exits with memory still allocated it indicates a problem. This is how I have caught any memory leaks during development.
- Do make distcheck the local copy of install-sh provided by automake, in addition to /usr/bin/install. Depending on the end user’s environment, either of these could end up being used.
make distcheck # will use /usr/bin/install make distcheck INSTALL=$HOME/foo/install-sh # absolute location of install-sh
When you do “make install” yourself, it will probably use /usr/bin/install since that is present on GNU/Linux systems. If so, you would not detect any problem with the install-sh shipped in your package – for example, if it had got corrupted for some reason (e.g. a stray edit or in my case, after doing a repository conversion I somehow ended up with my working directory containing the first ever version of install-sh that was checked in – which dated from 1994 – it didn’t work properly on modern systems, but I never noticed that because I was always using /usr/bin/install).
- Try running the build and make check with a memory limit to be sure that excessive memory is not required to do the compilation.
ulimit -v 65536 # some reasonable memory limit make make check
- Check that the texinfo manual works for postscript/pdf
make dvi # or make pdf
It’s easy to miss a diagram or other texinput file that is needed by texi2dvi but not by makeinfo.
Autocache
March 9th, 2011
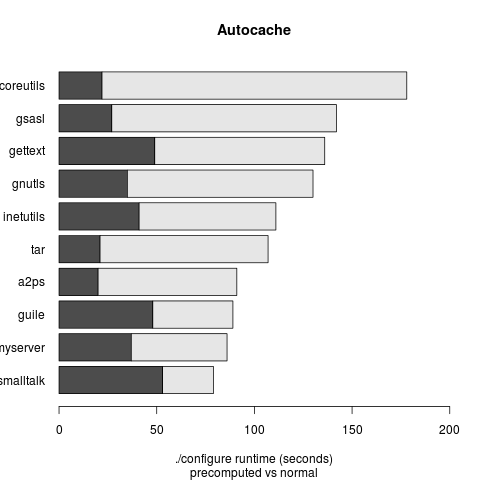
At FOSDEM, Alfred (ams@gnu.org) came up with the idea of “Autocache” – a system-wide precomputed cache of autoconf tests that makes every configure script run instantaneously. A crazy idea that cannot work completely in practice, of course, but there might be something to it.
He sent me an implementation which works like this: you make a configure script from all the autoconf tests in Gnulib (excluding some obvious ones that should not be cached). The idea is to pick tests which are unlikely to change on a given system. You run this huge configure script once and make a copy of the resulting config.cache file. You then use this as an initial config.cache for any package you’re compiling.
I tested it on GSRC and it worked surprisingly well – out of ~100 packages there were only a handful of failures where somehow the cache had bad results. Here are the timing results for the top ten longest-running GNU configure scripts with/without autocache.
Decentralised systems and the tendency to centralisation
February 12th, 2011
In his presentation at FOSDEM on “Power, Freedom, Software. Why we need to divide and re-conquer our systems” Karsten Gerloff talked about the difference between decentralised systems, which are networks of client-server systems (such as Email), and distributed systems, where all nodes are equal (such as peer to peer filesharing networks like GNUnet).
If the client and the server of a decentralised system are both free software then anyone can start their own server and be free from control. In practice, decentralised systems have a tendency to become centralised, and in some cases highly centralised for most users.
The tendency to centralisation is a result of two factors: asymmetric costs and economies of scale.
- Asymmetric costs: in client-server systems, the server generally requires more administration that the client. Users have an incentive to transfer administration to a third-party, either for a fee or trading away privacy, in the case of advertising-supported services.
- Economies of scale: server administration is subject to significant economies of scale. Larger providers drive out smaller providers over time, leading to a high degree of centralisation.
These two factors form a positive feedback loop, as larger providers can offer better services at lower cost, thereby attracting more users.
As a specific example, consider email. In the early days, each group of users had their own mail server at their local site. Over time, email has been outsourced to ISPs, ISPs have merged and been taken over, and finally been overtaken by a small number of global mail providers with userbases in the hundreds of millions.
Although the factors driving this process are universal the degree of centralisation is not uniform, but depends on the relative cost of administration and value of privacy for different users. For example, email has become effectively centralised for individual non-technical users, where the relative cost of running a mail server is high and the perceived privacy problem is low. For large companies, the relative cost of running a mail server is lower, confidentiality of corporate information is valued, and most maintain their own mail systems in-house.
Autoconf caching – an option I didn’t know about
February 10th, 2011
In his talk about Autotools at the FOSDEM GNU Dev Room, Ralf Wildenheus mentioned an autoconf option that I wasn’t aware of. It’s the “-C” option and it enables caching, which speeds up multiple runs of a ./configure script enormously.
$ ./configure --help
--cache-file=FILE cache test results in FILE [disabled]
-C, --config-cache alias for `--cache-file=config.cache'
$ ./configure -C configure: loading cache config.cache ...
Caching used to be the default up to about 10 years ago, but was turned off as the cache gets out of sync with the system if new packages are installed. Also it really only benefits developers, as end-users typically only need to run ./configure once.
In the 1990’s I got used to caching being enabled by default and when it was turned off I never noticed the change — except that somehow running ./configure while developing seemed a lot slower in the past ten years!
Thanks to Ralf for pointing out this option as I am now using -C all the time.
GNU Devroom at FOSDEM 2011 (Brussels)
February 8th, 2011
The GNU dev room at FOSDEM 2011 was great, the room had 100 seats and every talk was packed out with people standing at the sides.
The GNU talks were:
Org-Mode: your life in plain text by Bastien Guerry on the amazing personal organizer mode for emacs
Dynamic hacking with Guile by Andy Wingo on the new release of Guile 2.0 and hacking a twitter clone (“Peeple”) live in 15 minutes using Guile’s new web framework – amazing,.
GNU Autotools by Ralf Wildenhues with lots of useful tips for autoconf and automake.
GNU Network Security Labyrinth by Simon Josefsson, a nice tutorial on how different security protocols have developed over time, in order to solve the problems with earlier attempts.
GNU recutils: your data in plain text by Jose E. Marchesi, tools to work with your data on the command-line.
There were also two talks from FSF Europe,
Power, Freedom, Software. Why we need to divide and re-conquer our systems by Karsten Gerloff.
Non-free software advertisement – presented by your government by Matthias Kirschner, about the successful PDFreaders.org campaign.
Thanks to José and Andy for organising the day, it was a great set of topics.

Karsten Gerloff talking about freedom and the cloud.

Simon Josefsson finishing his talk

The room
Apache reference manual
January 31st, 2011
This is the latest printed free software manual I’ve been working on – The Apache Reference Manual (for Apache version 2.2.17) (ISBN 9781906966034, RRP £19.95). It’s the biggest single volume I’ve published – over 850 pages. I’m donating $1 to the Apache Software Foundation for each copy sold.

GNU Parallel – a map operator for the command line
January 13th, 2011
GNU Parallel is a nice recent addition to my unix toolkit. It can do a lot of things, my favorite is as a “map” operator for the command-line, automatically parallelising over the arguments of a command.
The command
parallel command {} ::: arg1 arg2 arg3 ...
is equivalent to
command arg1 & command arg2 & command arg3 & ...
run in parallel. The {} is replaced by each argument in turn.
As part of the regular updates to GSRC I need to run “make check-update” for several hundred directories for all the gnu packages. With a for loop that takes a long time, as “check-update” examines remote urls to see if a new version of a package has been released. With parallel I can use
parallel make -C {} check-update ::: gnu/*/
to get the same effect but in parallel (by default 9 processes simultaneously – to change it use -j N).
The author of GNU Parallel, Ole Tange, is giving a talk at FOSDEM (Brussels) in the GNU Dev room on Saturday 5 Feb 2011, see http://www.gnu.org/ghm/2011/fosdem/ for details. Hope to see you there!
Org Mode manual published
December 17th, 2010
I’ve published a paperback edition of the Org Mode 7 Reference Manual (subtitled “Organize your life in GNU Emacs”). For each copy sold $1 is donated to the Org project.
PostgreSQL 9 manuals
December 16th, 2010
I’ve just published the PostgreSQL 9 Reference Manual (in 4 volumes) through my company Network Theory Ltd.
It’s over 1,600 pages, so proofreading it was quite a task! One of the side-benefits of publishing free software manuals is that I do get to know all the features of the software.
The main new PostgreSQL feature that I’ll be using is full text indexing, for a Django site I’m working on. I was previously running PostgreSQL 8.2 on my server and updated it to PostgreSQL 9 yesterday to get support for this. Thanks to the new pg_upgrade migration tool in PostgreSQL 9 that should also the last time I’ll need to do the full pg_dump/pg_restore upgrade (always a bit of a hassle on a large database).
Incidentally, for every volume of the manual sold I’m donating $1 to the PostgreSQL project. I was able to give over $2,000 from the sales of the previous edition for PostgreSQL version 8.