|
|
I’m trying to protect my privacy on the Net, and for years I have been using and advocating (in German) the anonymization tools JonDonym and Tor towards that end. Before you continue reading, please be warned that I’m an anonymization hobbyist. There are ongoing discussions on the tor-talk mailing list concerning network diversity and the protection Tor may or may not be able to provide in view of global surveillance. Maybe I’m missing something fundamental in the following. Let’s see.
Basically, with anonymization tools such as Tor my communication is encrypted and re-routed over several middleman (so-called Tor nodes or JonDo mixes) before the final middleman performs the communication with the real target (say, spiegel.de or guardian.co.uk) on my behalf; responses flow back through those middlemen in reverse order, again encrypted. Thus, my ISP cannot learn any longer, what I’m doing on the Net. Similarly, the real targets do not see who is really visiting them (they see a middleman). This scheme is assumed to be secure as long as no party can observe both ends of the communication, namely the encrypted communication between me and the first middleman as well as the communication between the final middleman and the real target. If someone can do so, they may be able to correlate the traffic at both ends, identifying me as the real source communicating with the real target. (According to this calculation they’ll have a hard job, though, thanks to the Base Rate Fallacy.)
Now, if I, as a German, choose the first middleman in the US, I’m almost certain that my end of the communication will be observed by NSA and GCHQ, thanks to PRISM, Tempora, and whatnot. In fact, if I choose the first middleman anywhere but in Germany I can be pretty sure that some foreign intelligence agency will monitor and maybe store my network traffic. Whether one of those parties will also see the other end of the communication depends on the locations of the final middleman and the target, as well as the degree of those parties’ collusion.
I’m operating under the assumption that if my human rights, dignity, and privacy are still worth anything at all, then this is the case in my own country, where those values are protected by the constitution, at least on paper. In my view, this protection on paper is worth something, if only a fight. In every other country, I appear to be literally outlawed, fair game for foreign intelligence.
For now, I’m changing my choice of anonymization middlemen. I’d like to make sure that my first middleman is located in Germany. Thus, to spy on my communication with the first middleman in Germany, someone needs to conduct illegal wiretapping in Germany and violate my constitutionally granted rights (which is currently happening; that situation could change, which reminds me that elections are coming up). I see no reason at all to re-route that communication without need into hostile territory where I’m outlawed.
When using Tor or JonDonym without special precautions, though, data will most likely be routed away from Germany into hostile territory, even if my communication is local to Germany (say, I’m fetching e-mail from a German e-mail provider). Thus, my attempt to protect my privacy via anonymization may very well show the adverse effect of delivering my data to foreign spies (which might not see a single bit of the communication without anonymization).
To avoid such situations, I generated and analyzed traceroute data to Tor nodes, looking for potentially hostile places. Essentially, traceroute is a networking tool to enumerate some of the routers that forward my data along its way through the Internet. For the purposes of this analysis, I’m trying to avoid routers where some data source tells me that (a) the router does not appear to be located in Germany or that (b) the router appears to be located in an Internet eXchange Point (IXP). (IXPs receive lots of network traffic from all over the world, which makes them very attractive for and worthy of wiretapping by intelligence agencies.)
I’m using the following sources to obtain country and IXP information:
- Internet eXchange Point data from http://www-rp.lip6.fr/~augustin/ixp/ based on the paper: Brice Augustin, Balachander Krishnamurthy, Walter Willinger, “IXPs: Mapped?”, Internet Measurement Conference, November 2009.
- Team Cymrus’s whois service. This provides Autonomy System information, IP prefixes, and country information.
- Optionally, the python modules pygeoip and TorCtl (both of which make use of MaxMind’s geolocation database).
Beware: The IXP data was collected in 2009, so don’t expect it to be accurate any longer. I added missing German IXPs from https://www.peeringdb.com/. Other countries probably need similar updates. In addition, geolocation data is never entirely accurate, and traceroute only shows a subset of the machines that see your Internet communication. Thus, analysis results will likely contain false positives and false negatives.
I wrote Python code to select my Tor guards based on the above data. (With Tor, the first middleman is chosen from a set of nodes, which are called guards, and Tor configuration options allow to explicitly restrict those guards.) I’m hoping that my communication with those selected guards does not pass wiretapped territory. If this hope is justified, my end of the communication will be invisible to spies, giving me anonymity. Which everyone should have.
Of course, I’m only hoping that systematic wiretapping is restricted to IXPs in my country (and does not happen everywhere), and I’m only hoping that my communication is not forwarded to additional places, which are invisible to traceroute. If this was not the case, I can be sure, though, that someone conducts illegal wiretapping in Germany and violates my constitutionally granted rights. Thus, there is hope to fight such illegal conduct. As it should be.
Here is a summary of what I found. I started out with a list of 826 Tor nodes located in DE, generated on 2013/07/15 at http://torstatus.blutmagie.de/. Out of these, 232 are named guards, and 78 are named exits. I analyzed traceroute data both at work and at home.
At work:
Only a small number of 25 guards are safe in the sense their paths appear to flow neither through IXPs nor through foreign places. DE-CIX alone is traversed to reach 179 guards. However, 4 guards are located in my own Autonomous System (AS). It seems very attractive to use only those (instead of all 25 candidates). What do you think?
I’d like to point out that during this week I observed route changes. Sometimes, less routes go through DE-CIX, so that up to 39 guards appear to be safe. Thus, repeated tests are a must.
For Tor exits, traceroute data between me and the exit is less useful. Traceroutes between the exits and my communication partners would allow to identify IXPs along that way. I’m not in the position to obtain that data. Nevertheless, if I want to anonymize communication that should be local to my country, I’m restricting the exits to those that do not show foreign hops. I found 58 of those.
At home:
Many guards (126) appear to be safe, only one is located in my own AS.
I’d like to share two sample unsafe routes to Tor guards raspitor2 and YanLunYiZou, where IP addresses of intermediate hops and targets with their estimated locations are shown:
raspitor2 (89.144.24.210): 213.20.59.10;DE → 195.71.10.242;DE → 195.71.212.242;DE → 195.69.145.103;NL (via IXP AMS-IX) → 193.34.48.162;GB → 193.34.48.74;GB → 193.34.48.74;GB → 185.14.92.22;DE → 193.24.211.57;DE → raspitor2 (89.144.24.210);DE (via IXP AMS-IX)
YanLunYiZou (109.69.68.157): 213.20.59.10;DE → 195.71.10.242;DE → 195.71.254.93;DE → 84.16.8.141;ES → 84.16.14.93;ES → 212.73.205.225;GB → 4.69.168.190;US → 4.69.161.93;US → 4.69.143.137;US → 4.69.140.14;US → 4.69.163.9;US → 4.69.143.177;US → 4.69.133.181;US → 4.69.133.178;US → 212.162.18.226;GB → 91.202.40.254;DE → YanLunYiZou (109.69.68.157);DE
Those are examples of so-called boomerang routes, where source and target appear to be located in the same country, yet traffic does impressive sightseeing and receives lots of unwanted attention. Consequently, I’d like to warn against the Tor options to restrict nodes based on country codes.
Finally, at home I found 63 Tor exits that appear to be non-foreign. The intersection between work and home contains the following 53 routers, which may be useful for German Tor users:
0x3d002, 5268A6ED09875EA2F5, AbelianGrape, Atorisinthesky, BZHack, Biverse, DaJoker, Datenmuehle, FoeBuD3, HarryTuttle, KOP1, KiwibirdSuperstar, LookAnotherExit, MagmaSoft, Musashi, NeefEef2, Piper, Resistance, TommysTorServer, Tor4Freedom, Torboinaz, TuringComplete, arbitrary, armselig, brotherjacob, cce12eb07e2d92a7, chee, devilproxytor, eisler, felixker, filiprem, ftcalip, germangang, hamradioboard, hanfisTorRelay, hellinterface, honk, jabla, landfox, memyselfandi, neonustor, ppbytor1, randomserver, riqochet, rollmops, skyplace, smurfix, spdytor1, superblyhidden, supercow12k, th0rnsrelay, tor3aendych, zapit02
My analysis code is available under the GNU GPLv3+:
The tarball’s README.txt lists necessary prerequisites and explains how you can identify your own guards.
Als Buzzword der letzten Jahre ist die „Cloud“ (Wolke) in vieler Munde, jedoch mit unterschiedlichen Bedeutungen. Zunächst kann Cloud Computing im Sinne der Vision „Utility Computing“ von McCarthy aus den 1960er Jahren verstanden werden, nach der Rechenleistung bei Bedarf über Netzwerke überall praktisch unbegrenzt zur Verfügung stehen soll, ähnlich wie Strom und Wasser. Konkreter nutzen Unternehmen das Cloud Computing, um weniger eigene Hard- und Software anzuschaffen und stattdessen bei Bedarf auf Rechner externer Dienstleister zuzugreifen, wo die benötigten Anwendungen betrieben werden. Im privaten Umfeld ist häufig von der Cloud die Rede, wenn Terminkalender, Adressbücher, Fotoalben, Musik- und Videosammlungen oder (Office-) Dokumente nicht mehr (oder nicht mehr nur) auf eigenen Geräten gespeichert werden, sondern darüber hinaus in Rechenzentren – eben in der Cloud. Die Speicherung in Rechenzentren ermöglicht es dann, über das Internet praktisch überall auf der Welt per Smartphone oder PC auf diese Daten zuzugreifen, sie zwischen unterschiedlichsten Geräten zu synchronisieren und sie einfach mit Freunden, Bekannten oder Kollegen zu teilen. Mir geht es hier ausschließlich um diese letztgenannte Sicht der Cloud für private Daten. Anbieter derartiger Cloud-Dienste sind renommierte Unternehmen wie Apple, Amazon, Dropbox, Facebook, Google oder Microsoft, und wer ein Smartphone oder E-Book besitzt, benutzt solche Dienste mit hoher Wahrscheinlichkeit: Sie sind vorinstalliert, praktisch einfach und einfach praktisch.
Ich nutze sie nicht.
Auch ich möchte mit verschiedenen Geräten auf meine Termine, Kontakte und Dateien zugreifen können. Trotzdem kommt die Nutzung solcher Dienste für mich nicht in Frage. Ich vertraue private Daten, die ich nicht auch auf einem Web-Server öffentlich zur Verfügung stellen würde, nicht dauerhaft unbekannten Dritten an, schon gar nicht wenn diese sich außerhalb der EU befinden.
Ich besitze ein Android-Smartphone, daher wäre die Synchronisation über Google-Dienste einfach. Weil ich Google aber als unbekannten Dritten betrachte, kommen diese Dienste für mich nicht in Frage. Google ist mir aus verschiedenen Gründen unbekannt: Ich weiß nicht, welche Google-Angestellten dort wann auf meine Daten zugreifen würden. Ich weiß auch nicht, welche Kriminellen dort wann auf meine Daten zugreifen würden (Kriminelle angeblich chinesischen Ursprungs gehen in allen amerikanischen Firmen und Behörden ein und aus). Anderswo ist es höchstwahrscheinlich nicht besser.
Ich darf mir aber sicher sein, dass US-Behörden auf meine Daten zugreifen würden. Zunächst ist aus US-amerikanischer Sicht klar, dass grenzüberschreitende Kommunikation (also solche, bei der vermutlich Nicht-Amerikaner beteiligt sind, die Terroristen oder Schwerstkriminelle sein könnten) ausspioniert werden darf und muss. Patriot Act und FISA erlauben direkte Cloud-Zugriffe ohne richterliche Genehmigungen oder Benachrichtung der Betroffenen, was auch durch EU-Datenschutzbestimmungen nicht verhindert werden kann. Die NSA richtet neue Rechenzentren ein, um die anfallenden Datenmassen auszuwerten, und mit PRISM ist gerade berichtet worden, dass die NSA direkt auf die Server von Microsoft, Yahoo, Google, Facebook, PalTalk, AOL, Skype, YouTube und Apple zugreift. Ferner ist es interessant, dass es in den USA zumindest dann Diskussionen über die Rechtmäßigkeit derartiger Überwachungsmaßnahmen gibt, wenn US-Bürger betroffen sind; laut Präsident Obama werden US-Bürger von PRISM zumindest nicht ohne Genehmigung ausspioniert.
Nun ist es leider nicht so, dass wir nur von den USA ausspioniert würden, sondern dies geschieht weltweit, wie Hogan Lovells zusammengetragen hat. Einzelheiten werden in Deutschland etwa im „Gesetz zur Beschränkung des Brief-, Post- und Fernmeldegeheimnisses“ und in Paragraph 110 des Telekommunikationsgesetzes (TKG) geregelt.
Als guter deutscher Beamter ohne terroristische oder kriminelle Ambitionen habe ich wenig zu verbergen. Dennoch würde ich weder mein Adressbuch noch meinen Terminkalender noch mein E-Mail-Archiv oder meine Fotos irgendeinem x-beliebigen Fremden geben, der mich auf der Straße danach fragt. Ebenso wenig möchte ich, dass mir unbekannte Dritte auf diese Daten zugreifen können, ohne mich zu fragen. Ich weiß nicht warum, aber ich empfinde den Gedanken als zutiefst entwürdigend, dass meine Daten unter dem Vorwand der Kriminalitätsbekämpfung routinemäßig durchleuchtet oder gar für eingehendere Analysen gespeichert werden.
Die Cloud ist Teil des von Eben Moglen beschriebenen „verworrenen Netzes“. Um mich in diesem Netz nicht weiter zu verheddern und um Herr „meiner“ Daten zu bleiben, synchronisiere ich sie nicht in die Cloud. Im Normalfall google ich nicht, sondern suche per TorBrowser über DuckDuckGo.com oder ohne Tor mit dem in Europa beheimateten Startpage.com. Zur Begutachtung freier Synchronisations-Alternativen (wie Funambol, ownCloud und Zarafa) plane ich für das kommende Wintersemester eine Lehrveranstaltung. (Diesen Text habe ich als Vorbereitung auf die zugehörige Informationsveranstaltung geschrieben, in der ich um Studierende werben werde.)
Currently, our phones are stained with blood, literally, as exemplified by the well-known Foxconn suicides or the less well-known role of conflict minerals to sustain war and murder in Congo. FairPhone is an endeavor to produce smartphones in a fairer way, and after three years of preparatory work, the Dutch start-up just started its pre-order campaign (restricted to Europe). This page explains their approach in detail, while technical specs are available here.
Today I ordered my FairPhone (two, actually). If FairPhone receives 5000 orders, production will start in June (delivery is estimated for October). The phone will come with Android pre-installed but installation of alternative OSes should be possible. I’ll certainly free my devices once I receive them.
If you think about buying a new phone, why not start a movement?
The FSFE Fellowship Card is an OpenPGP smartcard to hold GnuPG signature, encryption, and authentication keys. The fundamental idea of OpenPGP smartcards is to store your key material securely on the card, where all cryptographic operations are executed, maybe after entering the card’s PIN. Thus, secret keys never leave the card. [Note that without smartcards (along the “normal” way) keys are stored on disk and protected via passphrases; thus, a Trojan with keylogger will be able to steal everything, secret key and passphrase, leaving you without protection.]
Big Picture
Initially, the process of smartcard setup and usage appeared rather foggy to me; however, it’s actually quite easy to lift that fog. In the following, I’m trying to explain what I learned. I assume that you are familiar with public key cryptography and GnuPG and describe the big picture in high-level terms first. Afterwards, I point to more specific details concerning smartcard setup and use as well as some error messages.
Key Generation
First, generate a new master key. This master key will only be used to sign other keys (including the subkeys that you create subsequently during the setup process), and it will not be stored on the smartcard but in a secure place (preferably offline, e.g., on a USB stick in a vault). For daily use, generate further subkeys, at least one signature key (to sign files and messages, not keys—that is the purpose of the master key) and one encryption key, optionally also an authentication key. Then, make a backup of your public and secret keyrings containing the newly generated keys and store that backup in a secure place.
Key Transfer
Afterwards, transfer the newly generated subkeys to the smartcard. Importantly, after such a transfer the keyring does not contain the secret key any longer; instead, in the keyring the secret key is replaced with a so-called stub. Such a stub is not a real key but only a pointer to the key stored on the smartcard. To finish the initial setup, remove the (secret part of the) master key from your keyring. Now, the master secret key exists only as backup in a secure place, while the secret parts of the subkeys are available for daily use on the smartcard and exist as backup (together with the master key); importantly, none of the secret keys is stored in the keyring on disk any longer.
Smartcard Use
The final piece of the puzzle is how to use the smartcard on different machines. Of course, the keyring on a different machine needs to know what keys are contained on the smartcard. Towards that end, you may first import the master key’s public key (e.g., from a USB stick); afterwards, execute gpg --card-status or gpg --card-edit with inserted smartcard, which—somewhat surprisingly—constructs the stubs for the secret subkeys in the keyring. Alternatively, on a networked machine you may execute gpg --card-edit followed by the command fetch, which downloads the public key from the “URL of public key” stored on the smartcard and updates the keyring accordingly.
Confusing Terms
Next, in various sources you may read about gpg-agent, scdaemon, and udev; maybe also about pcscd, hotplug, and gpgkey2ssh; probably also about gpg and gpg2. Let’s consider those things in turn. gpg-agent manages keys and caches passphrases and PINs. It is started automatically, either by gpg if necessary or when your GUI is initialized, and there is no reason to start it manually. If you choose to transfer an authentication key to your smartcard, gpg-agent replaces ssh-agent and should be started with your GUI (see below). gpgkey2ssh is a tool of historical interest. scdaemon manages your smartcard and is started automatically by gpg-agent; again, you do not start it manually. pcscd also manages smartcards; I do not need it—in fact, it was installed on one of my systems and caused major problems (see below). udev and hotplug are mechanisms to manage all kinds of devices; essentially, udev has replaced hotplug; it may need manual configuration to work with your smartcard (which was not the case for me, neither on a fresh Ubuntu 12.04.2 LTS nor on “aged” Ubuntu 10.04.4 LTS). Finally, gpg represents GnuPG version 1.x while gpg2 stands for GnuPG version 2.x, both of which are actively maintained; they may even be installed in parallel. gpg2 has better smartcard support and uses scdaemon to talk with the smartcard; in contrast gpg has built-in smartcard support so that scdaemon may not be necessary, but it works with scdaemon as well. However, if you want to enter your PIN with the PIN pad of the card reader (instead of your keyboard where a keylogger may be listening) you probably need scdaemon, even with gpg.
In short, make sure that scdaemon and gpg-agent are installed and forget about all the rest. If you compile gpg2 from source, gpg-agent and scdaemon are included; otherwise, on Ubuntu you may find gpg-agent in its own package and scdaemon—quite surprisingly—in the package gpgsm.
Card Setup
The details of the card setup process are described in this HowTo.
Here is what I suggest to follow that HowTo. First, use a fresh system to generate the master key (for example, Ubuntu 12.04.2 LTS), as a fresh system is far less likely to be compromised than one which has been in use for a while. (Actually, I used c’t Bankix, a German project for secure online banking, instead of Ubuntu 12.04.2 LTS.)
Note that I must warn you against Ubuntu 12.10 and 13.04 beta. Do not use them!
You only need to burn/install the ISO image to a CD or USB stick (booting from CD may be preferable as that is a read-only medium, although it is slower).
Be sure to verify the checksum of the ISO image!
Then you can immediately boot from that medium to test Ubuntu without installing it to your hard disk, in fact without modifying your hard disk. Before booting, disconnect your computer from the net, maybe disable wireless networking via suitable hotkeys. Once the boot process is completed, you find yourself in a fully functional Ubuntu system that is suitable to generate GnuPG keys and transfer them to the smartcard. Connect your smartcard reader and insert the smartcard. gpg is installed and udev configured correctly. Thus, the following command shows the contents of your card.
$ gpg --card-status
Note that neither gpg-agent nor scdaemon are installed. Thus, smartcard PINs need to be entered on the keyboard. This should not be a problem as (a) you disconnected the machine from the net and (b) nothing is stored on disk. (Be careful with a USB stick, though. Maybe format it in the end.)
However, the system is not ready to follow the HowTo yet. After creation of the master key (gpg --gen-key), access to the card via (gpg --card-status) fails, as the Gnome keyring daemon interferes:
gpg: selecting openpgp failed: unknown command
gpg: OpenPGP card not available: general error
Thus, kill gnome-keyring-daemon:
$ pkill -f gnome-keyring-daemon
Now, gpg --card-status should work again.
Follow the HowTo. When it instructs you to use a search engine for authentication keys, use gpg --edit-key again and type the command addcardkey. Choose “authentication key” when asked what type of key you want. Continue to follow the HowTo.
Afterwards, your new master key and new subkeys are stored on the smartcard, the secret keys are stored in a secret place (except for the authentication key, which was generated directly on the smartcard), and your public key is exported to a file.
System Setup for Card Usage
To get rid of the Gnome keyring problem mentioned above, go to directory /etc/xdg/autostart and delete (or rename) the files gnome-keyring-ssh.desktop and gnome-keyring-gpg.desktop.
Next, make sure that scdaemon and gpg-agent are installed. As noted above, either compile gpg2 from source or install the appropriate packages (gpgsm and gpg-agent). Set up ~/.gnupg/gpg-agent.conf for ssh support, maybe also increase the duration for which PINs will be cached, e.g.:
enable-ssh-support
# Cache for 6h = 6*60*60 seconds, instead of the default of 10 minutes.
# Upon access, default-cache-ttl re-starts.
default-cache-ttl 21600
default-cache-ttl-ssh 21600
# Enter passphrases for keys that are not stored on smartcard:
pinentry-program /usr/bin/pinentry-gtk-2
Then, configure your system not to start ssh-agent any more, but to start gpg-agent upon login instead. The necessary steps are system-specific. For Ubuntu (12.04.2, also 10.04), check the files under directory /etc/X11/Xsession.d. You should see the file 90gpg-agent, where you may need to adjust the path for GPGAGENT if you compiled from source; you also see that you need to include configuration option use-agent in your gpg.conf. Moreover, you should see the file 90x11-common_ssh-agent, which makes use of option use-ssh-agent, which in turn can be removed from the file /etc/X11/Xsession.options. Apply necessary changes and log off and on again.
Finally, add your public authentication key to the file ~/.ssh/authorized_keys on all machines into which you want to ssh by just entering the smartcard’s PIN. The command
$ ssh-add -L
should show all known keys for ssh authentication, including those on the smartcard, which can be recognized by the identifier cardno:<your-card-number>. Append that key (as usual) to ~/.ssh/authorized_keys. (Don’t use gpgkey2ssh.) If you don’t see such a key, make sure that you followed the advice concerning gnome-keyring-ssh.desktop above.
That’s it. Enjoy your smartcard.
Strange Errors
On one of my machines, gpg2 --card-status showed errors like this:
gpg: selecting openpgp failed: Kartenfehler
gpg: OpenPGP Karte ist nicht vorhanden: Kartenfehler
Upon repeated attempts:
gpg: OpenPGP Karte ist nicht vorhanden: Nicht unterstützt
The English messages are:
gpg: selecting openpgp failed: Card error
gpg: OpenPGP card not available: Card error
gpg: OpenPGP card not available: Not supported
Moreover, debug messages for scdaemon (enabled via ~/.gnupg/scdaemon.conf) showed this:
scdaemon[7615] PC/SC OPEN failed: comm error
Ultimately, pcscd was running as root (started from /etc/init.d/pcscd) and interfered with scdaemon. I killed that process and disabled it:
$ sudo update-rc.d -f pcscd remove
Everything was good.
What GNU/Linux distribution do you recommend to your friends?
Friends with neither much knowledge about nor interest in computers, who just want a machine that works?
Ubuntu is supposed to be a particularly user-friendly GNU/Linux distribution, and I’ve been using various versions of Ubuntu for several years, although I’m aware that it is not endorsed by the Free Software Foundation. However, even as a long-time user of Ubuntu I must warn you to not install the most recent versions of Ubuntu!
I repeat: Do not install Ubuntu 12.10 or 13.04 beta.
Starting with version 12.10 the company behind Ubuntu, Canonical, made the unforgivable decision to connect Ubuntu’s desktop search with Canonical and with Amazon (and lots of other parties): Your personal search keywords (where you may be searching for private e-mails or office documents containing certain keywords) are sent to Canonical and from there relayed to third parties which can include ads for their products among your search results (and Canonical earns money from affiliate programs). Your machine then downloads images for the search results directly from third party servers. All this has been known for a while, and you may want to read the first (?) report on this issue and comment on the bug.
Thus, not only does Canonical learn your search terms—which is none of their business—but additionally third parties can correlate the search terms coming through Canonical with the requests for images from your machine. Effectively, a number of third parties learn what you are searching for—which is none of their business either. That idea is still present in Ubuntu 13.04 beta. If you do not mind that your browser downloads embedded images from Amazon and 7digital, you may want to check out this External Image Report visualizing a search for “privacy [ … wait a little … ] breach”, generated with chaosreader based on network traffic of Ubuntu 13.04 beta. Note that the report does not only include images from Amazon but also from 7digital, which is totally unknown to me, but which now knows my search terms.
Such conduct represents a major privacy breach, ignoring any thought to privacy-by-design principles. (It does not help that online search can be disabled, if you know how.)
For the time being I’m recommending Ubuntu 12.04.2 LTS (Precise Pangolin), where desktop search remains our private business. That version is a so-called “long-term support” version, and it will be supported until April 2017, which should give enough time to get used to the freedom and simplicity of GNU/Linux and to switch to something else.
So, let me ask you, again, what GNU/Linux distribution do you recommend to your friends? One among those?
Eben Moglen hat in „The Tangled Web We Have Woven—Seeking to protect the fundamental privacy of network interactions“ beschrieben, wie unser Denken und Handeln im Web (in das unsere Telefone und Bücher eingewoben sind) kontinuierlich überwacht werden, und regt an, Privatsphäre als ökologische Herausforderung zu betrachten. Der Autor stellt zudem die Idee eines Privatsphäre-Proxies auf Basis freier Software als Abhilfe vor, etwa in Form der FreedomBox.
Ich wünsche dem Artikel eine breite Leserschaft, habe ihn daher ins Deutsche übersetzt und greife hier einige Aspekte erläuternd auf. Die Übersetzung entpuppte sich im Detail als überraschend schwierig; ich habe mich um eine möglichst direkte Übersetzung bemüht, empfehle aber trotzdem die Lektüre im Original.
Zum Begriff „Privatsphäre“.
Ich habe zunächst mit dem Gedanken gespielt, „Privacy“ mit „informationeller Selbstbestimmung“ zu übersetzen, da sich der Artikel im Umfeld des Missbrauchs personenbezogener Informationen im Web bewegt. Nach Rücksprache mit dem Autor habe ich diesen Gedanken fallen gelassen und „Privatsphäre“ als umfassenderen Begriff gewählt: „Informationelle Selbstbestimmung“ und insbesondere „Datenschutz“ sind juristisch vorbelegte und vorbelastete Begriffe, wobei die juristischen Mechanismen keinen Schutz bieten. Fragen Sie sich selbst, wie vielen Nutzungs- und DatenschatzDatenschutzbedingungen Sie im Web per Klick „zugestimmt“ haben. Wie viele davon haben Sie gelesen? Wie viele verstanden?
Durch diese Klicks werden die juristischen Schutzmaßnahmen routinemäßig, jederzeit und überall unterlaufen.
Diese Argumentation hat mich überzeugt, den Begriff „Privatsphäre“ zu verwenden, um die erforderliche psychologische, kulturelle, soziale und politische Autonomie des Einzelnen in Relation zum Netz zu bezeichnen, die umfasst, was wirkliche „informationelle Selbstbestimmung“ wäre, wenn irgendeine Regierung der Erde sie ernst nähme.
Zum ersten Satz.
Der Autor hat im ersten Satz bewusst das Present Progressive (“The last generation is now being born”) gewählt, um anzudeuten, dass wir zwischen zwei Epochen menschlicher Existenz leben: Noch wachsen unsere Kinder ohne direkte, permanente Verbindung zum Netz auf. Dies wird mit dem sich ausdehnenden Internet der Dinge bald nicht mehr der Fall sein.
Dieser Satz deutet zudem an, dass „Netz“ und „Web“ wesentlich weiter gedacht werden sollten als miteinander verbundene Computer und bloße Web-Seiten.
Zu technischen Begriffen.
Ich gebe im Folgenden Hinweise, die ich nicht mit dem Autor abgestimmt habe.
Der Autor bewirbt Privatsphäre-Proxies. Ein Proxy ist eine aktive Komponente, die in die Kommunikation zwischen anderen Komponenten eingebunden wird und dort beliebig komplizierte Aufgaben übernehmen kann; so eine Komponente kann sowohl durch separate Geräte als auch durch zusätzliche Software auf bestehenden Geräten (etwa Internet-Router, PC oder Smartphone) bereitgestellt werden. Der Privatsphäre-Proxy hat die Aufgabe, private Kommunikation zu ermöglichen. Dazu fängt der Proxy bislang ungeschützte Kommunikation automatisch ab, entfernt schädliche Elemente, sichert sie durch kryptografische Maßnahmen und leitet sie dann abgesichert zur Kommunikationspartnerin (bzw. deren Proxy) weiter. Insbesondere wird ein neues Netz von Privatsphäre-Proxies direkte Kommunikation ohne Umwege über (in- und ausländische) Datenkraken erlauben.
Cookies und Web-Bugs sind Beispiele potenziell schädlicher Elemente, die durch den Proxy entfernt werden können. Worum es geht, habe ich anderswo beschrieben.
„HTTPS everywhere“ deutet die Notwendigkeit und angestrebte Normalität kryptografisch abgesicherter Kommunikation an; während kryptografische Maßnahmen heute überwiegend als Schutzmaßnahmen für „besondere“ Daten (etwa Finanzdaten) verstanden werden, gibt es keinen Grund, jederzeit unbekannte Dritte bei unseren „normalen“ alltäglichen Handlungen und Unterhaltungen im Web zuhören und zusehen zu lassen.
HTTPS ist das Standardprotokoll zur verschlüsselten (Vertraulichkeit und Integrität sichernden) Übertragung von Daten im Web. Auf die Tatsache, dass HTTPS auf einem nicht vertrauenswürdigen, gescheiterten Vertrauensmodell basiert und der Sicherheitsgewinn daher fraglich ist, möchte ich nicht eingehen, sondern nur an den Verkauf von Man-in-the-Middle-Zertifikaten durch Trustwave oder den „Fall“ DigiNotar erinnern. Ungeachtet der resultierenden Zweifel an der Sicherheit von HTTPS gibt es für den freien Web-Browser Firefox eine freie Erweiterung Namens „HTTPS Everywhere“, die verschlüsselte Verbindungen auch zu solchen Seiten herstellt, bei denen dies zwar möglich, aber schwierig ist. Zudem gibt es Bestrebungen, das gescheiterte Vertrauensmodell abzulösen, etwa durch die freie Firefox-Erweiterung Convergence.
SSH (Secure Shell) und VPN (virtuelles privates Netz) bieten verbreitete, von HTTPS unabhängige Möglichkeiten, die Netz-Kommunikation abzusichern. Insbesondere sollte auf so ziemlich jedem GNU/Linux-Rechner ein SSH-Server (sshd) laufen.
Das im Text angesprochene XMPP (früher Jabber) ist ein Chat-Protokoll, das Echtzeitkommunikation ohne Beteiligung unbekannter Dritter ermöglicht. Insbesondere unterstützen vernünftige Chat-Programme XMPP mit Off-the-Record Messaging, das die Eigenschaften eines „normalen“ Vier-Augen-Gesprächs (ohne technische Hilfs- und Überwachungsmittel) anstrebt: Die Kommunikation bleibt unter vier Augen, ist also vertraulich. Die Kommunikationspartner wissen, mit wem sie sprechen und wer was gesagt hat (Integritätsschutz); trotzdem können sie ihre Äußerungen jederzeit abstreiten. Schließlich bleiben nach Ende des Gesprächs keine Spuren zurück (Perfect Forward Secrecy).
Ein Privatsphäre-Proxy, der dies und mehr richtig macht, ist eine hervorragende Idee.
Zum Prinzen.
Im letzten Absatz deutet der Autor Konsequenzen von Willkür und Missbrauch weltlicher und geistlicher Macht an. All Stellvertreter für weltliche Macht wählt er „Prince“, was im Deutschen sowohl „Prinz“ als auch „Fürst“ bedeuten kann. Die Macht beider beruht auf unterschiedlicher Legitimation, und vor welcher Art Sie wann mehr zu befürchten haben, müssen Sie selbst entscheiden.
Das verworrene Web, das wir gewoben haben
Auf der Suche nach Schutz für die fundamentale Privatsphäre von Netzwerk-Interaktionen1
Eben Moglen
Übersetzung von Jens Lechtenbörger
Die letzte Generation wird gerade geboren, deren Gehirn sich unabhängig vom Netz entwickeln wird. Von nun an wird die Art, wie das Web arbeitet, eine dominante Rolle bei der Sozialisierung der menschlichen Rasse spielen. Aber weil wir die Web-Infrastruktur ohne Berücksichtigung von Privatsphäre aufgebaut haben, gefährden wir auch unsere Grundfreiheiten. Wir stehen kurz davor, das Grundrecht, in unseren Gedanken allein zu sein, für immer zu eliminieren.
Zu Beginn des sechzehnten Jahrhunderts schuf der Buchdruck mit beweglichen Lettern die Erfahrung des privaten Lesens, und mit ihm konnte sich die westliche Idee des individuellen Selbst frei entwickeln, selbstbestimmt durch einen privaten Prozess des Lesens und Denkens. In der Religion führte dies zur revolutionären Entwicklung individualistischer Formen des protestantischen Christentums. Die säkulare Gesellschaft übernahm wissenschaftliche Methoden, wodurch soziale Zustände radikal verbessert wurden. Die Öffnung des Lernens ermöglichte auch die allmähliche Verwandlung der westlichen politischen Landschaft in Richtung demokratischer Selbstverwaltung und den verfassungsrechtlichen Schutz der Freiheit des Denkens.
Das Netz sollte diesen Prozess nun der gesamten menschlichen Rasse eröffnen, sollte es jedem Menschen auf der Erde ermöglichen zu lesen, zuzusehen, zuzuhören und sich an jeder Form von Lernen und Kultur zu beteiligen; überall, ohne Diskriminierung zwischen reich und arm, alt und jung, männlich und weiblich. Dieses wahrhaft universale Lernsystem würde das Wohlergehen der Menschheit unermesslich verbessern. Aber wenn wir die grundlegende Privatsphäre von Netzwerk-Interaktionen nicht schützen, wenn wir nicht nur die aktive Überwachung, sondern auch umfangreiches Data Mining auf persönlichen Informationen im Netz ermöglichen, werden wir dieses Versprechen nicht einlösen. Denn wenn das Netz nicht entwickelt wird, um Privatsphäre zu schützen, wird es stattdessen zu einem Gefängnis des menschlichen Körpers und der menschlichen Seele werden.
Wir scheitern aktuell, weil unser Netz verwendet wird, um uns ständig auszuspionieren, während wir es nutzen, um unser Leben zu bereichern. Die Innovationen im Bereich der Überwachung entstammen der Industrie. Aufzeichnungen darüber, wie wir das Netz nutzen – wonach wir suchen, was wir lesen, wen wir kontaktieren – werden intensiv und unmittelbar auf ihren Wert für diejenigen analysiert, die uns etwas verkaufen wollen. Was wir mit unseren Freunden und unserer Familie teilen, auch der Inhalt unserer E-Mails und andere private Kommunikation, wird zum selben Zweck genauestens untersucht von Unternehmen, die uns „Dienstleistungen“ im Gegenzug für den Zugang zu unseren privaten Daten anbieten. Alle diese von Unternehmen zum Zwecke der Profitorientierung unermüdlich gesammelten Daten stehen unabhängig davon, wie verantwortungsvoll sie verwaltet werden, jeder Regierung zur Verfügung, die es versteht – per Gesetz, Gewalt oder Betrug – die sammelnden Unternehmen zur Zusammenarbeit zu bewegen.
Jenseits der Daten selbst liegt die neue Mathematik, aus ihnen zu folgern. „Data Mining“, das sich jetzt selbst höflich als „Data Science“ bezeichnet, ist eine neue Teildisziplin der Statistik, die auf die Verwendung all dieser sowohl individuell identifizierbaren als auch aggregierten Verhaltensdaten für die Vorhersage menschlicher sozialer Handlungen ausgerichtet ist. Unabhängig davon, ob jemand pharmazeutische Erzeugnisse, Spielzeug, Werbeplätze oder einen politischen Kandidaten verkauft, verwendet Data Science nun unsere persönlichen Daten, um dem Verkäufer zu helfen, uns zu identifizieren, zu verfolgen und zu überzeugen. Unser Konsum liefert Informationen, die verwendet werden können, um unsere Gedanken zu lesen.
Die Situation wird noch verschlimmert, weil wir in rasantem Tempo persönliche Service-Roboter einsetzen, die nicht ausschließlich in unserem Interesse arbeiten. Anders als die unter uns lebenden Roboter in Science-Fiction-Welten unserer Kindheit besitzen diese Roboter keine Hände und Füße – wir2 sind ihre Hände und Füße. Sie sehen, auf was wir sie richten; sie haben Ohren, um alles zu hören, was um uns herum geschieht; sie kennen jederzeit unseren Aufenthaltsort. Diese Roboter, die wir Smartphones und Tablets nennen, enthalten häufig Software, die wir weder lesen noch verstehen können, geschweige denn ändern. Wir kontrollieren sie nicht, sondern bieten anderen die Möglichkeit, uns zu kontrollieren.
Die Entwicklungen auf dem privaten Technologiemarkt, um Individuen durch das Netz zu überwachen, vorherzusagen und zu beeinflussen, haben natürlich die Aufmerksamkeit von Staaten auf sich gezogen. Regierungen bewegen sich schnell, in vollstem Umfang ihrer unterschiedlichen Mittel, um ihre soziale Kontrolle zu erhöhen, indem sie die Macht der großen persönlichen Datenmengen ausnutzen. Unabhängig von Ihren politischen Präferenzen fängt irgendwo auf der Welt jetzt eine Regierung, deren Prinzipien Sie komplett ablehnen, damit an, das Netz zu nutzen, um Unterstützung zu finden, Einfluss auf die Bevölkerung zu nehmen und ihre Feinde zu entdecken. Überall auf der Welt werden von nun an die Regierungen, die tyrannische Züge annehmen, über ungeheuer leistungsfähige neue Werkzeuge verfügen, um dauerhaft an der Macht zu bleiben.
Die Krise der Privatsphäre ist ökologisch. Die unbeabsichtigten Folgen kleiner individueller Aktivitäten erzeugen, wenn sie über die gesamte Bandbreite des Netzes aggregiert werden, eine Bedrohung für unsere gemeinsamen menschlichen Interessen auf globaler Ebene.
Weil die Bestandteile dieser Krise alle unserer Schöpfung entspringen, können wir das Problem glücklicherweise beheben. Wir müssen die Betriebs-Software des Netzes im Einklang mit bestimmten ethischen Grundsätzen neu aufbauen. Dies erfordert nicht, Menschen oder Unternehmen zu zwingen, ihre aktuellen Handlungen zu ändern. Es erfordert, ein Gegenstück zu Grünen Technologien bereitzustellen und den Menschen zu helfen, auf sie umzusteigen.
Zuerst müssen wir daher unter Beachtung der Privatsphäre der Nutzer verantwortungsvolle Ersatz-Software für bestehende Funktionen entwickeln, um Systeme abzulösen, die gefährlich für Privatsphäre sind. Aktuelle Webmail-Dienste und soziale Netzwerke beispielsweise speichern die Kommunikation aller ihrer Nutzer mit ihren jeweiligen sozialen Kreisen innerhalb riesiger zentraler Datenbanken, die vom Dienstanbieter betrieben werden; dieser erhält im Gegenzug für Speicherung und Bereitstellung anspruchsvoller Zugriffsdienste für die Nutzer das Recht, die Daten zu analysieren, die jetzt zentralisiert und anfällig für staatlichen Zugriff sind.
Allerdings sind E-Mail und Web per Design föderierte Dienste, in denen einzelne Server Speicher- und Zugriffsdienste kostengünstig, sicher und mit nahezu perfekter Zuverlässigkeit für einzelne Nutzer erbringen können. Nutzer begannen, zentralisierte Dienste zu verwenden, die ihre Privatsphäre verletzten, weil sie greifbaren Komfort ohne offensichtliche Kosten erhielten. Niemand wusste, wie sie3 ihren eigenen Mail-Server oder Web-Server betreibt, und wir haben es nicht einfach gemacht, dies zu erlernen. Aber wir können – und wir sollten – den Menschen helfen, freie Software und eine kommende Flut preiswerter „Personal-Server“-Hardware einzusetzen, um persönliche Privatsphäre-Geräte zu bauen.
Die FreedomBox-Foundation, die ich derzeit berate, ist ein Beispiel für einen Versuch in dieser Richtung, der freie persönliche Privatsphäre-Software erstellt, um solche Geräte zu bauen. Kleine, preiswerte, wenig Strom verbrauchende Geräte, die Sie nur anschließen und vergessen – diese halten Ihre Kommunikation privat, helfen Ihnen, im Web zu navigieren, ohne bespitzelt zu werden, und lassen Sie sich der Welt sicher mitteilen. Lassen Sie mich in wenigen Sätzen technisch werden, um zu beschreiben, wie.
Ein Großteil der Implementierung eines solchen Software-Stacks beinhaltet die Verwendung vorhandener freier Software-Werkzeuge. Ein Privatsphäre-Proxy im Router zwischen dem Browser auf dem Smartphone oder dem PC und dem öffentlichen Netz kann Werbung und Web-Bugs entfernen, den Cookie-Fluss verwalten und Surf-Privatsphäre und -Sicherheit durch die Bereitstellung von „HTTPS everywhere“ verbessern. Der automatisierte Einsatz von SSH-Proxies und persönlichen VPNs kann nicht nur Privatsphäre für den Web-Zugang hinter der als Router genutzten FreedomBox gewähren, er kann auch sichere Kommunikation und privatsphäregeschützten Web-Zugriff von einem mobilen Gerät ermöglichen, das in nicht vertrauenswürdigen Netzwerken fern der Heimat verwendet wird.
Einige der für persönliche Privatsphäre-Geräte benötigten Werkzeuge sind Kombinationen von vorhandenen Funktionalitäten. Beispielsweise ergibt die Kombination eines HTTPS-Web-Servers und eines XMPP-Servers mit OpenPGP-basierter Authentifizierung zusammen mit einem Verfahren zum Aufbau des „Netz des Vertrauens“ (engl. web of trust) durch Austausch in QR-Codes (von Smartphones erkannte 2D-Barcodes) eingebetteter öffentlicher Schlüssel ein Verfahren für sicheren Text-, Sprach- und Video-Chat, dessen Nutzung für durchschnittliche Anwender einfach ist. Dies wiederum lässt sich leicht zu einem Verfahren zur sicheren Kommunikation mit Journalisten und öffentlichen Medien erweitern, um Video- und Audio-Aufnahmen von Handys weiterzuleiten. Jenseits unseres gegenwärtigen Entwicklungsstandes befinden sich neuartige Werkzeuge, die wir entwickeln müssen, wie föderierte Social-Networking-Software, die nahtlos und ohne das Netz des sozialen (Mit-) Teilens zu stören, Facebook und ähnliche „Dienste“ ersetzen können, die uns zentrale Speicherung, Data Mining und Kontrolle auferlegt haben.
Bald werden solche Privatsphäre-Server verfügbar sein, um Ihren eigenen Wireless Router oder ähnliche Geräte unter geringeren Kosten zu ersetzen, aber mit einem enormen gesamtgesellschaftlichen Nutzen. Betrachten Sie sie als persönliche Abgasfilter, die so gut wie nichts kosten, aber die Atmosphäre verbessern, die wir alle atmen.
Aber das ist noch nicht alles. Wir müssen auch zur klaren, sachlichen, technischen Aufklärung der Öffentlichkeit über Privatsphäre und „die Cloud“ beitragen. Derzeit fehlen grundlegende technische Informationen entweder ganz oder werden in der öffentlichen Debatte verzerrt dargestellt. Wir müssen den Menschen helfen zu verstehen, warum sie besser daran täten, ihre persönlichen Daten auf physischen Objekten in ihrem Besitz zu speichern als in Rechenzentren anderer Leute in „der Cloud“. Wir sollten die Ergebnisse der „Data Science“ einer Öffentlichkeit zugänglich machen, die sich niemals für Mathematik interessieren wird.
Wir müssen den Menschen helfen, ökologisch über Privatsphäre nachzudenken. Nutzer erkennen nicht, dass die Privatsphäre ihrer Gesprächspartner verletzt wird, wenn sie einen „kostenlosen“ E-Mail-Dienst verwenden, der jede gesendete und empfangene E-Mail mitliest und analysiert. Sie erkennen nicht, dass jede auf den Fotos, die sie auf zentralen sozialen Netzwerken veröffentlichen, per Gesichtserkennung identifiziert und markiert wird; dass der Betreiber des sozialen Netzwerkes Zugang zu allen Bildern und Markierungen hat, ebenso wie jede, mit der der Betreiber „kooperiert“. Wir müssen erklären, dass jede kleine Entscheidung, eigene Informationen preiszugeben, auch Informationen anderer Menschen preisgibt. Wir können die Menschen lehren, dass wir, wenn wir handeln, um unsere eigene Privatsphäre zu verbessern, auch die Privatsphäre unserer Kinder, unserer Familien und unserer Freunde schützen. Wenn wir den Menschen um uns herum helfen, die Auswirkungen ihres Handelns auf andere zu verstehen, werden sie für sich selbst entscheiden, welche Änderungen sie vornehmen sollten.
Das Entwirren des Web, die Wiederherstellung der Privatsphäre in Bezug auf unser Handeln und der Anonymität in Bezug auf unser Lesen wird nicht einfach. Viele schöne Unternehmen werden ein bisschen weniger Geld verdienen, wenn wir ihnen nicht alle unsere persönlichen Daten anbieten, die sie von Intermediären in ihrem Namen analysieren lassen. Regierungen – so ziemlich alle Regierungen jeglicher Ausrichtung – entdecken schnell, wie viel reale Kontrolle sie erhalten können, ohne zu zeigen, dass ihre Hände im Spiel sind, wenn sie sich das derzeit falsch konfigurierte Anti-Privatsphäre-Netz zu Nutze machen. Es bildet sich ein Konsens der Mächtigen gegen Privatsphäre; derjenige gegen Anonymität ist bereits ausgewachsen. Stellen Sie sich vor, wie anders unsere Welt wäre, wenn alle Bücher der westlichen Welt des letzten halben Jahrtausends ihre Leser an das Hauptquartier gemeldet hätten, einschließlich der Mitteilungen an den Prinzen oder den Papst, wie viele Sekunden jeder Leser mit jeder Seite zugebracht hat. Das Buch, das jede sich selbst in der Privatsphäre ihres Verstandes vorlesen konnte, wird von einem Gerät ersetzt, das Ihr Leseverhalten für den Buchhändler protokolliert, vorbehaltlich der Vorladung des Prinzen. Es wird nicht leicht sein, Privatsphäre zu retten. Aber wenn wir an Freiheit glauben, haben wir absolut keine andere Wahl.
Im Original erschienen als: Eben Moglen: The Tangled Web We Have Woven—Seeking to protect the fundamental privacy of network interactions, CACM, Vol. 56, No. 2, February 2013. Übersetzung mit freundlicher Genehmigung des Autors; dieser Text steht unter der Creative-Commons-Lizenz CC BY 3.0 DE. ↩
Betonung vom Übersetzer hinzugefügt. ↩
Der Autor verwendet weibliche Personalpronomen (her, herself), um Sprache selbst daran zu hindern, dem Männlichen automatisch Macht und Wichtigkeit zu verleihen. Der Übersetzer wählt ein entsprechendes Vorgehen im Deutschen, indem er diese weiblichen Pronomen wörtlich übersetzt und die Indefinitpronomen everyone und anyone weiblich übersetzt, da er das Anliegen des Autors teilt. ↩
Ich weiß nicht warum, aber ich muss beim Wort „De-Mail“ immer an die schreiend komische Szene zum „De-Gnoming the Garden“ denken, wo Harry den Weasleys hilft, das Ungeziefer aus dem Garten zu entfernen.
„De“ ist lateinisch, bedeutet „ab“ oder „weg“ und wird auch im Deutschen als Vorsilbe verwendet, wenn etwas weggenommen wird. „De-Gnoming“ bedeutet also „Entfernen der Gnome“, wobei die Gnome zunächst im Kreis gewirbelt werden, bis sie die Orientierung verlieren, und dann möglichst weit weggeworfen werden. „De-Mailing“ könnte entsprechend „Entfernen der E-Mail durch Verlust der Orientierung“ bedeuten.
Während ich De-Gnoming schreiend komisch finde, hat De-Mail mit Komik nicht das Entfernteste zu tun.
Ich hoffe immer noch, dass De-Mail sich nicht durchsetzen wird (was dann auch ein De-De-Mailing überflüssig machen würde). Warum ich De-Mail für Quatsch halte, habe ich zum Jahreswechsel 2010/11 hier subjektiv und hier wissenschaftlich beschrieben. Danach war das Projekt für mich erledigt; es kann in Vorlesungen zur Informationssicherheit aber immer noch als abschreckendes Beispiel dienen. Angesichts des Projektfortschritts (sowohl aus legislativer als auch aus kommerzieller Sicht) erscheint es mir sinnvoll, sowohl an die Schwächen als auch an Alternativen zu erinnern. Wie gesagt: Meine Sicht auf die Schwächen finden Sie hier und dort, zudem beispielsweise beim CCC.
Die kurzfristigen Alternativen sind OpenPGP, implementiert durch die freie Software GnuPG, deren Nutzung im „GNU-Handbuch zum Schutze der Privatsphäre“ dargestellt wird, oder zur Not S/MIME.
Eine längerfristige Ergänzung sehe ich im eigenen Mail-Server in der Vision der FreedomBox.
Happy De-De-Mailing!
Im Februar 2013 ist der äußerst empfehlenswerte Artikel The Tangled Web We Have Woven—Seeking to protect the fundamental privacy of network interactions von Eben Moglen erschienen. Er beschreibt eindrücklich, wie unser Denken und Handeln im Web (in das unsere Telefone und Bücher eingewoben sind) kontinuierlich überwacht werden, und regt an, Privatsphäre als ökologische Herausforderung zu betrachten. Der Autor stellt zudem die Idee eines Privatsphäre-Proxies als Abhilfe vor, etwa in Form der FreedomBox; dieser Proxy wird unter anderem Web-Bugs entfernen und Cookies verwalten. Inspiriert durch den Artikel habe ich meine Web-Seite zur informationellen Selbstbestimmung um einen Abschnitt zur Firefox-Erweiterung Collusion ergänzt, die visualisieren kann, warum so ein Proxy notwendig ist. Der folgende Text ist eine Kopie dieses Abschnitts.
Alice und Bob verwenden die freie Software Firefox als Web-Browser, den sie nach ihren Vorstellungen ausführen, untersuchen und verbessern, weitergeben und sogar nach ihren Verbesserungen in geänderter Form weitergeben dürfen.
Alice und Bob lesen immer mal wieder in verschiedenen Sprachen und unterschiedlich ausgerichteten Quellen, dass sie im Web für Werbezwecke auf Schritt und Klick verfolgt werden. Dank der freien Firefox-Erweiterung Collusion (das Wort bedeutet „geheime“ oder „betrügerische Absprache“) können sie einen anschaulichen Einblick in das Ausmaß des Problems erhalten. (Es geht hier nur um die Überwachung zu Werbezwecken; staatliche und anderweitig kriminelle Überwachungen lassen sich so nicht erkennen …)
Zunächst installieren Alice und Bob die Erweiterung Collusion. Darauf erscheint ein zusätzliches Icon in der rechten unteren Ecke des Browsers sowie der Menüeintrag „Extras“ / „Collusion Graph“. Durch Klick auf das Icon bzw. Auswahl des Menüeintrags öffnet sich ein neuer Reiter, in dem Collusion visualisiert, welche Parteien unter einer Decke stecken, um Handlungen im Web zu verfolgen, zu analysieren, vorherzusagen und generell unbekannte Dinge zu tun.
Die folgenden Ausführungen beziehen sich auf Experimente am 10. März 2013. Nach Besuch des Online-Shops www.zalando.de, der hier als besonders abstoßendes und daher schon wieder faszinierendes Beispiel dienen soll, zeigte Collusion den folgenden Graphen.
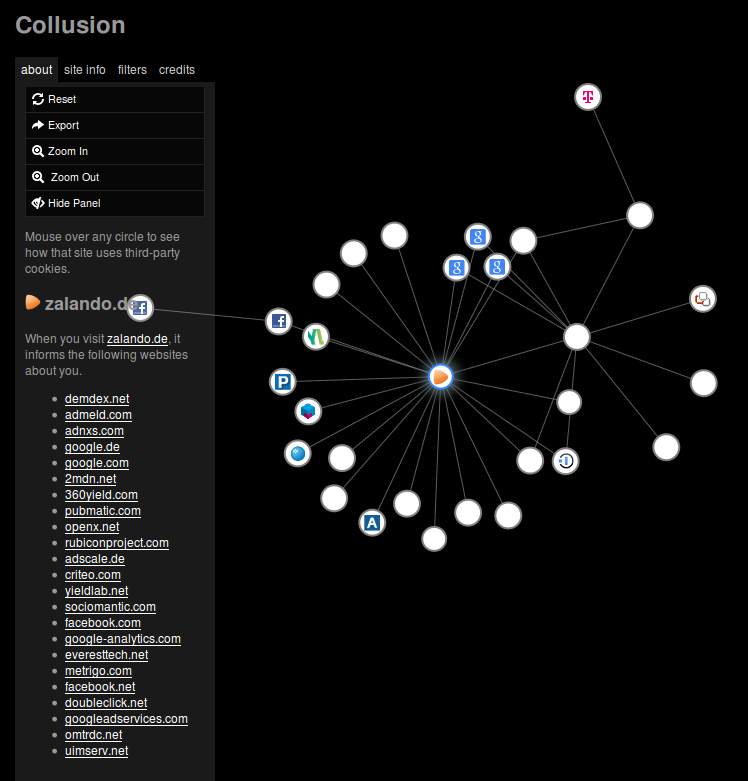
Blau umrandete Knoten zeigen in Collusion Web-Seiten, die direkt aufgerufen wurden; hier gibt es nur einen zentralen, blau umrandeten Knoten, der Zalando selbst repräsentiert. Weitere Knoten zeigen weitere Parteien, mit denen der Browser im Hintergrund kommuniziert, und Verbindungen zwischen Knoten machen deutlich, über welche Zwischenstationen mit welchen Parteien Kommunikation stattfindet. Es sind sowohl die üblichen Verdächtigen dabei (das „g“- und das „f“-Logo erkennen wohl die meisten) als auch zahlreiche wenig bis gar nicht bekannte DNS-Domänen. Jede Domäne repräsentiert Web-Server im Internet, die von zunächst unbekannten Betreibern mit unbekannten Interessen betrieben werden. Dabei ist es durchaus üblich, dass mehrere Domänen zu einem Unternehmen gehören.
Durch Auswahl eines Knotens mit der Maus werden Details zur zugehörigen Domäne angezeigt. Am linken Rand ist hier der Anfang der Details zu Zalando zu sehen, nämlich an wen Daten übertragen werden; eine stattliche Liste, und von den meisten Domänen haben weder Alice noch Bob jemals gehört …
Nun ist es nicht ungewöhnlich, dass der Browser die Web-Server mehrerer Domänen für die Anzeige einer einzigen Web-Seite kontaktiert, z. B. werden oftmals Bilder sowie CSS- und JavaScript-Dateien von externen Servern eingebunden. In der Tat werden viele Inhalte für die Zalando-Seite nicht von Servern der Domäne zalando.de sondern von ztat.net ausgeliefert. Wie an anderer Stelle erläutert kann jeder dieser Server Cookies für seine Domäne setzen, und dies geschieht hier in Hülle und Fülle: Ein frischer Browser ohne Cookies verfügte nach dem Aufruf der Zalando-Startseite sowie einem einzigen Klick auf einen zufällig ausgewählten Artikel über genau 100 Cookies aus 44 Domänen. Von diesen 100 Cookies waren lediglich 13 zalando.de-Domänen zugeordnet (3 für www.zalando.de, 8 für zalando.de, 2 für track.zalando.de). 86 der 100 Cookies waren keine Sitzungs-Cookies, sondern blieben auch nach dem Browser-Neustart erhalten, teilweise mit einem Haltbarkeitsdatum bis ins Jahr 2038. Welche HTTP-Aufrufe der Browser dabei durchgeführt hat, können Sie dieser Log-Datei entnehmen, die ich mittels meiner Chaosreader-Version aus einem Wireshark-Mitschnitt erstellt habe, nachdem ich die zahlreichen Aufrufe zur oben erwähnten Domäne ztat.net entfernt habe. Jede Zeile der Log-Datei zeigt eine sogenannte HTTP-Get-Anfrage des Browsers einschließlich eines eventuellen Referrer-Headers und führt zudem auf, ob mit dieser Anfrage (mindestens) ein Cookie verschickt wurde („Cookie sent.“) und ob in der zugehörigen Antwort des Web-Servers (mindestens) ein Cookie gesetzt wurde („Sets cookie.“).
Mit 100 Cookies hätte Zalando in dieser Untersuchung des Wall Street Journal im Jahre 2010 eine auch international hervorragende Platzierung erreichen können. Glückwunsch!
Spannender als der Besuch einer einzelnen Web-Seite ist natürlich das Surf-Verhalten über einen längeren Zeitraum. Die folgende Abbildung stellt den Collusion-Graphen nach dem Besuch der Web-Seiten von Zalando, Amazon, Süddeutscher Zeitung und Spiegel dar (wiederum mit jeweils einem Klick auf einen zufällig ausgewählten Artikel).

Interessant werden nun Knoten, die zentral angeordnet sind und über viele Kanten verfügen, die also viel über das gesamte Surf-Verhalten lernen. Hier sehen Alice und Bob z. B., dass ihr Browser der Domäne doubleclick.net permanent mitgeteilt hat, was sie tun. Insbesondere sehen sie links im Bild die Mitteilung von Collusion, dass doubleclick.net sie vermutlich auf allen vier von ihnen aktiv besuchten Domänen und einer weiteren, die sie gar nicht kennen, gesehen hat.
Warum dürfen die das? Keine Ahnung.
Warum können die das? Weil der Browser mitspielt.
Das muss aber nicht so sein. Wie ich anderswo zur PC-Grundsicherung darlege, empfehle ich die freien Firefox-Erweiterungen Adblock Plus [Update am 2.7.2013: Link entfernt. Diese Erweiterung ist nicht länger empfehlenswert, siehe letzten Absatz] und NoScript.
Alice und Bob installieren zunächst Adblock Plus. Bei Wiederholung des obigen Experiments zeigt sich (unter Verwendung der voreingestellten „EasyList Germany+EasyList“ mit voreingestelltem Zulassen „nicht aufdringlicher Werbung“) folgendes Bild.
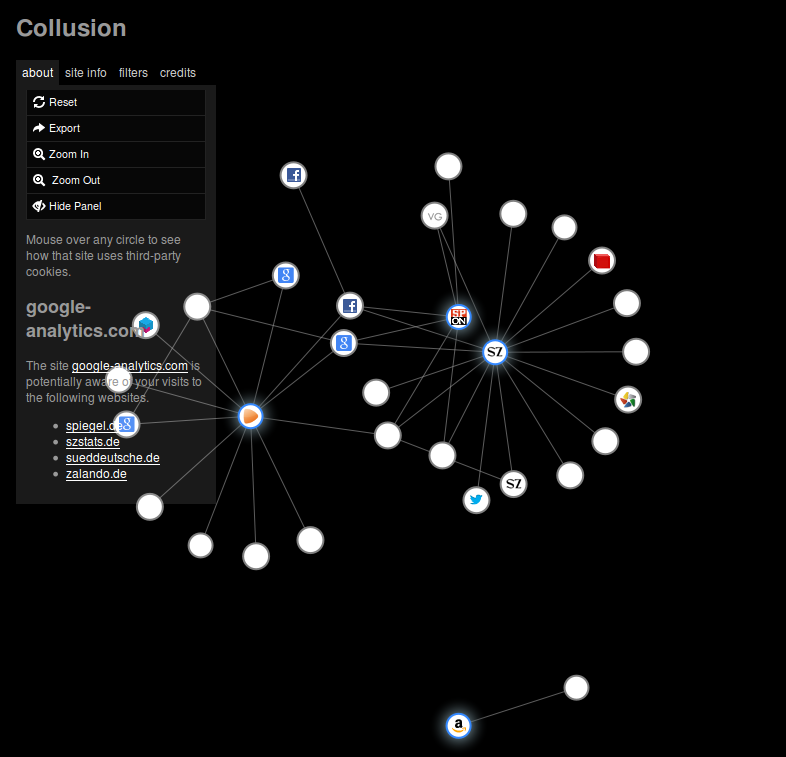
Der Graph ist deutlich ausgedünnt. Zentral sind jetzt Facebook und Google sowie google-analytics.com zu erkennen, wobei letzteres lediglich den Besuch bei (dem im Graphen nun isolierten) Amazon verpasst hat. Alle drei sind hier nicht als Werbenetze aktiv, sehen Alice und Bob aber trotzdem zu. Demgegenüber hat doubleclick.net nur noch den Besuch von Zalando registriert (der weiße Knoten über dem Zalando-Kreis).
Alice und Bob installieren spätestens jetzt (zusätzlich zu Adblock Plus) NoScript, das die Ausführung von JavaScript verhindert. Dann funktionieren viele Web-Seiten nicht mehr; für diejenigen, die ihnen wichtig sind, können sie die Ausführung von JavaScript allerdings von Hand erlauben. Bei Wiederholung des obigen Experiments ohne NoScript-Änderungen zeigt sich schließlich folgendes Bild.
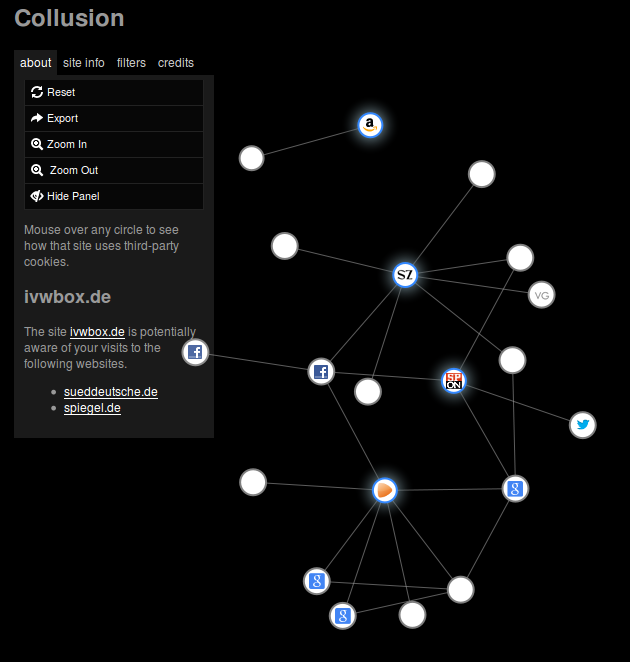
Facebook liegt immer noch in aussichtsreicher Position. Erwähnenswert ist außerdem ivwbox.de, das als weißer Knoten rechts zu sehen ist (verbunden mit der Süddeutschen und dem Spiegel) und unsere Lektüre auf zahlreichen deutschsprachigen journalistischen Angeboten begleitet.
Alice und Bob erhalten langsam eine Idee davon, wie verworren das Web ist und wer ihnen so zusieht. Sie könnten jetzt weitere Filterlisten in Adblock Plus hinzufügen oder eigene Regeln definieren. Als weitere Filterliste empfehle ich EasyPrivacy, die über das Menü „Extras“ / „Adblock Plus“ / „Filtereinstellungen …“ / „Filterabonnement hinzufügen …“ / „Anderes Abonnement hinzufügen“ in der dann erscheinenden Auswahlliste wählbar sein sollte. Mit ihr verschwinden die Collusion-Knoten zu ivwbox.de und doubleclick.net, und google-analytics.com wird eingeschränkt. Entlang dieses Menü-Pfades entfernen sie unter den Filtereinstellungen ihre Zustimmung zu „nicht aufdringlicher Werbung“, da sie weder aufdringlich noch unaufdringlich überwacht werden wollen.
Ein Privatsphäre-Proxy, der dies und mehr richtig macht, ist eine hervorragende Idee.
[Update am 2.7.2013] Nach den Recherchen von Sascha Pallenberg zur „nicht aufdringlichen Werbung“, die auch bei Heise zusammengefasst wird, kann ich Adblock Plus nicht mehr empfehlen. Die Zustimmung zur „nicht aufdringlichen Werbung“ sollten Sie wie oben beschrieben zurückziehen. Besser ist es vermutlich, auf Adblock Edge zu setzen. Adblock Edge basiert auf dem Code einer früheren Version von Adblock Plus und kennt keine Erlaubnis für „nicht aufdringliche Werbung“.
|
|

