Filesystem Abstractions for L4Re
Tuesday, February 12th, 2019In my previous posts, I discussed the possibility of using “real world” filesystems in L4Re, initially considering the nature of code to access an ext2-based filesystem using the library known as libext2fs, then getting some of that code working within L4Re itself. Having previously investigated the nature of abstractions for providing filesystems and file objects to applications, it was inevitable that I would now want to incorporate libext2fs into those abstractions and to try and access files residing in an ext2 filesystem using those abstractions.
It should be remembered that L4Re already provides a framework for filesystem access, known as Vfs or “virtual file system”. This appears to be the way the standard file access functions are supported, with the “rom” part of the filesystem hierarchy being supported by a “namespace filesystem” library that understands the way that the deployed payload modules are made available as files. To support other kinds of filesystem, other libraries must apparently be registered and made available to programs.
Although I am sure that the developers of the existing Vfs framework are highly competent, I found the mechanisms difficult to follow and quite unlike what I expected, which was to see a clear separation between programs accessing files and other programs providing those files. Indeed, this is what one sees when looking at other systems such as Minix 3 and its virtual filesystem. I must also admit that I became tired of having to dig into the code to understand the abstractions in order to supplement the reference documentation for the Vfs framework in L4Re.
An Alternative Framework
It might be too soon to label what I have done as a framework, but at the very least I needed to decide upon a few mechanisms to implement an alternative approach to providing file-like abstractions to programs within L4Re. There were a few essential characteristics to be incorporated:
- A way of requesting access to a named file
- The provision of objects maintaining the state of access to an opened file
- The transmission of file content to file readers and from file writers
- A way of cleaning up when programs are no longer accessing files
One characteristic that I did want to uphold in any solution was to make programs largely oblivious to the nature of the accessed filesystems. They would navigate a virtual filesystem hierarchy, just as one does in Unix-like systems, with certain directories acting as gateways to devices exposing potentially different filesystems with superficially similar semantics.
Requesting File Access
In a system like L4Re, with notions of clients and servers already prevalent, it seems natural to support a mechanism for requesting access to files that sees a client – a program wanting to access a file – delegating the task of locating that file to a server. How the server performs this task may be as simple or as complicated as we wish, depending on what kind of architecture we choose to support. In an operating system with a “monolithic” kernel, like GNU/Linux, we also see such delegation occurring, with the kernel being the entity having to support the necessary wiring up of filesystems contributing to the virtual filesystem.
So, it makes sense to support an “open” system call just like in other operating systems. The difference here, however, is that since L4Re is a microkernel-based environment, both the caller and the target of the call are mere programs, with the kernel only getting involved to route the call or message between the programs concerned. We would first need to make sure that the program accessing files has a reference (known as a “capability”) to another program that provides a filesystem and can respond to this “open” message. This wiring up of programs is a task for the system’s configuration file, as featured in some of my previous articles.
We may now consider what the filesystem-providing program or filesystem “server” needs to do when receiving an “open” message. Let us consider the failure to find the requested file: the filesystem server would, in such an event, probably just return a response indicating failure without any real need to do anything else. It is in the case of a successful lookup that the response to the caller or client needs some more consideration: the server could indicate success, but what is the client going to do with such information? And how should the server then facilitate further access to the file itself?
Providing Objects for File Access
It becomes gradually clearer that the filesystem server will need to allocate some resources for the client to conduct its activities, to hold information read from the filesystem itself and to hold data sent for writing back to the opened file. The server could manage this within a single abstraction and support a range of different operations, accommodating not only requests to open files but also operations on the opened files themselves. However, this might make the abstraction complicated and also raise issues around things like concurrency.
What if this server object ends up being so busy that while waiting for reading or writing operations to complete on a file for one program, it leaves other programs queuing up to ask about or gain access to other files? It all starts to sound like another kind of abstraction would be beneficial for access to specific files for specific clients. Consequently, we end up with an arrangement like this:
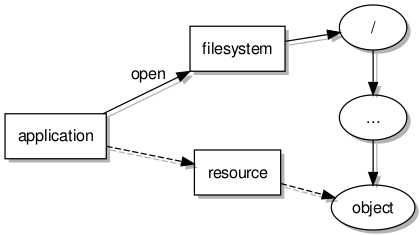
Accessing a filesystem and a resource
When a filesystem server receives an “open” message and locates a file, it allocates a separate object to act as a contact point for subsequent access to that file. This leaves the filesystem object free to service other requests, with these separate resource objects dealing with the needs of the programs wanting to read from and write to each individual file.
The underlying mechanisms by which a separate resource object is created and exposed are as follows:
- The instantiation of an object in the filesystem server program holding the details of the accessed file.
- The creation of a new thread of execution in which the object will run. This permits it to handle incoming messages concurrently with the filesystem object.
- The creation of an “IPC gate” for the thread. This effectively exposes the object to the wider environment as what often appears to be known as a “kernel object” (rather confusingly, but it simply means that the kernel is aware of it and has to do some housekeeping for it).
Once activated, the thread created for the resource is dedicated to listening for incoming messages and handling them, invoking methods on the resource object as a proxy for the client sending those messages to achieve the same effect.
Transmitting File Content
Although we have looked at how files manifest themselves and may be referenced, the matter of obtaining their contents has not been examined too closely so far. A program might be able to obtain a reference to a resource object and to send it messages and receive responses, but this is not likely to be sufficient for transferring content to and from the file. The reason for this is that the messages sent between programs – or processes, since this is how we usually call programs that are running – are deliberately limited in size.
Thus, another way of exchanging this data is needed. In a situation where we are reading from a file, what we would most likely want to see is a read operation populate some memory for us in our process. Indeed, in a system like GNU/Linux, I imagine that the Linux kernel shuttles the file data from the filesystem module responsible to an area of memory that it has reserved and exposed to the process. In a microkernel-based system, things have to be done more “collaboratively”.
The answer, it would seem to me, is to have dedicated memory that is shared between processes. Fortunately, and arguably unsurprisingly, L4Re provides an abstraction known as a “dataspace” that provides the foundation for such sharing. My approach, then, involves requesting a dataspace to act as a conduit for data, making the dataspace available to the file-accessing client and the file-providing server object, and then having a protocol to notify each other about data being sent in each direction.
I considered whether it would be most appropriate for the client to request the memory or whether the server should do so, eventually concluding that the client could decide how much space it would want as a buffer, handing this over to the server to use to whatever extent it could. A benefit of doing things this way is that the client may communicate initialisation details when it contacts the server, and so it becomes possible to transfer a filesystem path – the location of a file from the root of the filesystem hierarchy – without it being limited to the size of an interprocess message.
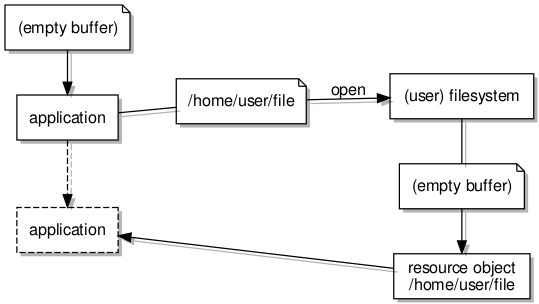
Opening a file using a path written to shared memory
So, the “open” message references the newly-created dataspace, and the filesystem server reads the path written to the dataspace’s memory so that it may use it to locate the requested file. The dataspace is not retained by the filesystem object but is instead passed to the resource object which will then share the memory with the application or client. As described above, a reference to the resource object is returned in the response to the “open” message.
It is worthwhile to consider the act of reading from a file exposed in this way. Although both client (the application in the above diagram) and server (resource object) should be able to access the shared “buffer”, it would not be a good idea to let them do so freely. Instead, their roles should be defined by the protocol employed for communication with one another. For a simple synchronous approach it would look like this:
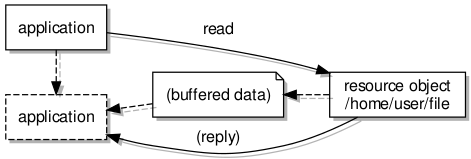
Reading data from a resource via a shared buffer
Here, upon the application or client invoking the “read” operation (in other words, sending the “read” message) on the resource object, the resource is able to take control of the buffer, obtaining data from the file and writing it to the buffer memory. When it is done, its reply or response needs to indicate the updated state of the buffer so that the client will know how much data there is available, potentially amongst other things of interest.
Cleaning Up
Many of us will be familiar with the workflow of opening, reading and writing, and closing files. This final activity is essential not only for our own programs but also for the system, so that it does not tie up resources for activities that are no longer taking place. In the filesystem server, for the resource object, a “close” operation can be provided that causes the allocated memory to be freed and the resource object to be discarded.
However, merely providing a “close” operation does not guarantee that a program would use it, and we would not want a situation where a program exits or crashes without having invoked this operation, leaving the server holding resources that it cannot safely discard. We therefore need a way of cleaning up after a program regardless of whether it sees the need to do so itself.
In my earliest experiments with L4Re on the MIPS Creator CI20, I had previously encountered the use of interrupt request (IRQ) objects, in that case signalling hardware-initiated events such as the pressing of physical switches. But I also knew that the IRQ abstraction is employed more widely in L4Re to allow programs to participate in activities that would normally be the responsibility of the kernel in a monolithic architecture. It made me wonder whether there might be interrupts communicating the termination of a process that could then be used to clean up afterwards.
One area of interest is that concerning the “IPC gate” mentioned above. This provides the channel through which messages are delivered to a particular running program, and up to this point, we have considered how a resource object has its own IPC gate for the delivery of messages intended for it. But it also turns out that we can also enable notifications with regard to the status of the IPC gate via the same mechanism.
By creating an IRQ object and associating it with a thread as the “deletion IRQ”, when the kernel decides that the IPC gate is no longer needed, this IRQ will be delivered. And the kernel will make this decision when nothing in the system needs to use the IPC gate any more. Since the IPC gate was only created to service messages from a single client, it is precisely when that client terminates that the kernel will realise that the IPC gate has no other users.

Resource deletion upon the termination of a client
To enable this to actually work, however, a little trick is required: the server must indicate that it is ready to dispose of the IPC gate whenever necessary, doing so by decreasing the “reference count” which tracks how many things in the system are using the IPC gate. So this is what happens:
- The IPC gate is created for the resource thread, and its details are passed to the client, exposing the resource object.
- An IRQ object is bound to the thread and associated with the IPC gate deletion event.
- The server decreases its reference count, relinquishing the IPC gate and allowing its eventual destruction.
- The client and server communicate as desired.
- Upon the client terminating, the kernel disassociates the client from the IPC gate, decreasing the reference count.
- The kernel notices that the reference count is zero and sends an IRQ telling the server about the impending IPC gate deletion.
- The resource thread in the server deallocates the resource object and terminates.
- The IPC gate is deleted.
Using the “gate label”, the thread handling communications for the resource object is able to distinguish between the interrupt condition and normal messages from the client. Consequently, it is able to invoke the appropriate cleaning up routine, to discard the resource object, and to terminate the thread. Hopefully, with this approach, resource objects will no longer be hanging around long after their clients have disappeared.
Other Approaches
Another approach to providing file content did also occur to me, and I wondered whether this might have been a component of the “namespace filesystem” in L4Re. One technique for accessing files involves mapping the entire file into memory using a “mmap” function. This could be supported by requesting a dataspace of a suitable size, but only choosing to populate a region of it initially.
The file-accessing program would attempt to access the memory associated with the file, and upon straying outside the populated region, some kind of “fault” would occur. A filesystem server would have the job of handling this fault, fetching more data, allocating more memory pages, mapping them into the file’s memory area, and disposing of unwanted pages, potentially writing modified pages to the appropriate parts of the file.
In effect, the filesystem server would act as a pager, as far as I can tell, and I believe it to be the case that Moe – the root task – acts in such a way to provide the “rom” files from the deployed payload modules. Currently, I don’t find it particularly obvious from the documentation how I might implement a pager, and I imagine that if I choose to support such things, I will end up having to trawl the code for hints on how it might be done.
Client Library Functions
To present a relatively convenient interface to programs wanting to use files, some client library functions need to be provided. The intention with these is to support the traditional C library paradigms and for these functions to behave like those that C programmers are generally familiar with. This means performing interprocess communications using the “open”, “read”, “write”, “close” and other messages when necessary, hiding the act of sending such messages from the library user.
The details of such a client library are probably best left to another article. With some kind of mechanism in place for accessing files, it becomes a matter of experimentation to see what the demands of the different operations are, and how they may be tuned to reduce the need for interactions with server objects, hopefully allowing file-accessing programs to operate efficiently.
The next article on this topic is likely to consider the integration of libext2fs with this effort, along with the library functionality required to exercise and test it. And it will hopefully be able to report some real experiences of accessing ext2-resident files in relatively understandable programs.



