This blog has moved
My blog can now be found at https://iain.learmonth.me/
My blog can now be found at https://iain.learmonth.me/
GNU MediaGoblin is a web application for hosting and sharing media. At 57North Hacklab, we currently have a Flickr group but to post to Flickr it is necessary to have a Yahoo! account and this seems like an unreasonable requirement to impose on members that want to share photos. This led to me setting up MediaGoblin. Hopefully it will also be useful for sharing other forms of media beyond photos too.
The instructions for installing MediaGoblin only cover Linux environments so here is my documentation of an installation on FreeBSD.
Start off by installing some dependencies (as root):
# pkg install git python py27-lxml py27-imaging py27-virtualenv
Then install some postgresql things (as root):
# pkg install postgresql92-server postgresql92-client py27-psycopg2
Do some setup of postgresql to initialise it and make it start on boot (as root):
# echo 'postgresql_enable="YES"' >> /etc/rc.conf # /usr/local/etc/rc.d/postgresql initdb # /usr/local/etc/rc.d/postgresql start
Create the new postgresql user and database (as root):
# su pgsql -c "createuser mediagoblin" # su pgsql -c "createdb -E UNICODE -O mediagoblin mediagoblin"
Create the system user (as root):
# adduser Username: mediagoblin Full name: MediaGoblin Unprivileged User Uid (Leave empty for default): 201 Login group [mediagoblin]: Login group is mediagoblin. Invite mediagoblin into other groups? []: Login class [default]: Shell (sh csh tcsh bash rbash zsh rzsh git-shell nologin) [sh]: Home directory [/home/mediagoblin]: /usr/local/srv/mediagoblin Home directory permissions (Leave empty for default): Use password-based authentication? [yes]: no Lock out the account after creation? [no]: Username : mediagoblin Password : Full Name : MediaGoblin Unprivileged User Uid : 201 Class : Groups : mediagoblin Home : /usr/local/srv/mediagoblin Home Mode : Shell : /bin/sh Locked : no OK? (yes/no): yes pw: mkdir(/srv/mediagoblin): No such file or directory adduser: INFO: Successfully added (mediagoblin) to the user database. Add another user? (yes/no): no Goodbye!
The next step is to actually fetch the MediaGoblin sources (as root):
# su mediagoblin # cd ~ # git clone git://gitorious.org/mediagoblin/mediagoblin.git # cd mediagoblin # git submodule init && git submodule update
Then build the MediaGoblin virtualenv (as mediagoblin):
$ (virtualenv --system-site-packages . || virtualenv .) && ./bin/python setup.py develop
To deploy with FastCGI, flup is apparently useful (as mediagoblin):
$ ./bin/easy_install flup
From here, you can follow the official documentation. Just start at “Deploying MediaGoblin Services”. Do remember though that your configuration files for web servers are going to be in /usr/local/etc not /etc
I’ve recently started playing with radios again and I’ve been looking mainly at packet radio. APRS is a system which uses amateur radio to transmit position reports, weather reports, and messages between users. There is an Internet backbone for APRS called APRS-IS that can be used to access a filtered feed of APRS broadcasts. I thought it would be nice if such a feed were also available via XMPP so set about building a gateway.
This was not as easy as I’d hoped it would be. All the libraries I tried to use to access APRS-IS data either were in a language I didn’t want to touch (i.e. Perl) or wouldn’t run on my system without segfaulting. Luckily, it is quite easy to talk to the APRS-IS servers as it turns out. Opening a TCP connection and sending:
user MM6MVQ-1 pass -1 vers testsoftware 1.0_05 filter r/57.1526/-2.1100/50\r\n
caused the server to begin sending me all the APRS packets broadcast within 50km of Aberdeen.
Next up was the XMPP bit. I really wanted to get a pubsub service going, but I had no idea how they worked, and after fighting with libraries again and even giving up on the server software and using jabber.ccc.de’s server instead I went for the easier option of just sending messages to a MUC for now.
Check out xmpp:aprs-aberdeen@conference.jabber.ccc.de?join to see the messages being broadcast around me.
CodeTheCity is an event that I was loosely involved in organising that we’re now half way through. It’s all about rapid prototyping of services for the community. While the event is structured as a hackathon, many of those invited were not coders at all and a few times I heard mix ups like confusing Windows with Office and anti-virus software with a firewall. You would think that at an event where the aim is to produce a prototype these people might hold hacks back but it became apparent quickly that the domain knowledge they had could help jumpstart a project. The developers in the teams seemed to code with more confidence knowing they’d got the requirements directly from the person that would be using the system.
Unfortunately, my team did not have any potential end users. I did have a look around the other projects happening but I had basically already decided before attending the event that I was going to work on indexing and making searchable Freedom of Information Act disclosure logs. My team consists of myself and Johnny McKenzie.
Aberdeen City Council publish a FOI disclosure log but it is not searchable and rather difficult to navigate.
Our first aim was to see what data could easily be extracted from the website and from this we developed a Information Request Ontology that could be used to represent the data. I then set about transforming this into the RDF/XML schema, creating a database schema and a D2RQ mapping while Johnny looked at using Python’s BeautifulSoup to scrape the web pages.
I finished quicker than I anticipated I would and looked at BeautifulSoup too, this time for scraping the East Lothian Council’s log to aggregate into the same database. At the end of day one, we had D2RQ serving linked data and allowing SPARQL queries of the East Lothian disclosures and the code in place to start scraping in the Aberdeen City disclosures.

Depending on how I feel tomorrow, another scraper may be added or maybe an interface for human-friendly search (SPARQL is fine for me, not so much for those that are confusing Windows and Office). An interesting challenge would be to run OCR on the rasterised PDFs to get some bags of words for a better search.
Last weekend, I attended the Debian Med Sprint for 2014 in Stonehaven, Aberdeen. The event was essentially an unconference hackathon with a few untalks.
On the Saturday, I participated in Andreas‘ live packaging session where
we packaged seqtk and dnaclust. I found the documentation for dnaclust
and produced a man page for inclusion in the package.
With my new Debian packaging knowledge, I packaged a personal project
python-fitbitscraper as python3-fitbitscraper in Debian. This effort
ran to the end of the sprint.
Luca gave a talk on a peer-to-peer database he has developed and I noticed it has a similar source structure to the python-fitbitscraper package. I have agreed to work with him on the documentation and produce Debian packages once the documentation is complete.
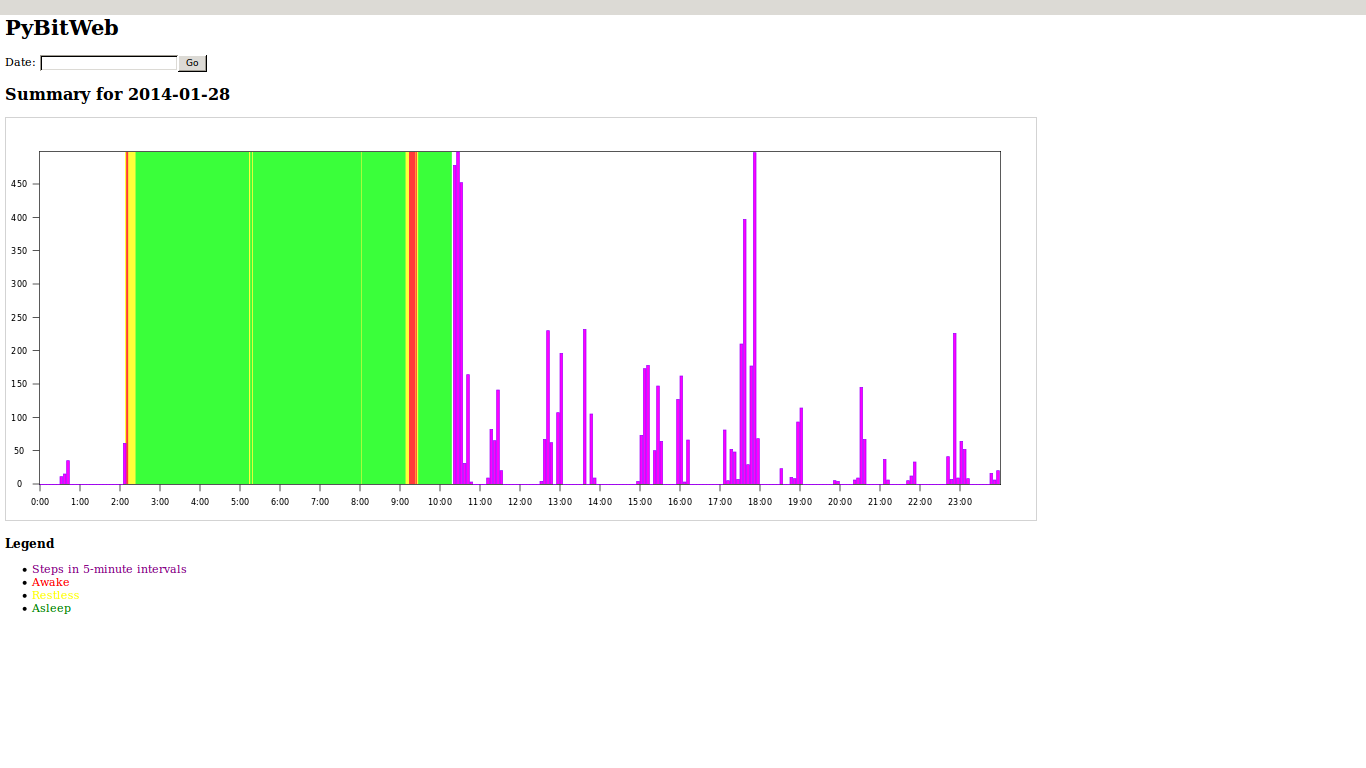
On the Sunday, I gave a short demo of an example application using personal health data from FitBit. Here is a screenshot of the application in action and some photos I took of the sprint activity:









This was my first sprint and my first face-to-face interaction with Debian and it was very enjoyable. Thanks to everyone involved.

The web used to be simple. It used to be a place where you could go and find reference materials, news and discussions about just about anything. All this content was wrapped up in HTML, maybe with some CSS to give it a tidier look, and served over HTTP. Unfortunately this is no longer the case. You can no longer survive on the web with cookies or JavaScript disabled as websites have been designed expecting that people will have those features available in their browser. On top of that, not satisfied with HTML, CSS and JavaScript (which, by the way, is Turing-compatible – there is not really a need for anything beyond JavaScript for client side scripting in the browser) we’ve got Adobe Flash, Microsoft Silverlight and Java applets too. Because these technologies exist, they are used, and anyone attempting to visit a site using them will have a pretty difficult time in navigating it without allowing the code, that you’ve likely never seen the source to and have no reason to trust, to run on your computer.
Navigating to a URL is seen as implicit consent that whatever happens to be there can run on your computer automatically. It’s true that Java has been riddled with enough security problems that there are now a series of “Are you sure?” boxes, but for Flash, Silverlight and especially JavaScript there are no such warnings. If you want to browse the web without problems, you have to accept that there are going to be security risks and eventually you’re going to get punched in the face by a malicious bit of code. Bug-proof software doesn’t exist, but blindly allowing code authored by strangers run on your computer seems like a bit of a risky strategy to me.
When I was using Linux, I would use Vimperator (a Firefox extension to make Firefox behave like Vim). Now that I’m trying to be more security aware, this is definitely not an option any more for the reasons given above. Then I thought, well, if the attack is inevitable does it really matter which browser I’m using? I then turned my research efforts to looking at “sandboxing” the browser. My initial thought was to use a virtual machine but this was far too great an inconvenience. Having to boot up twice to browse the web would get rather annoying. Then I thought about chrooting, which would prevent the browser from messing with my system in any real permanent way (hopefully) although a browser is a complex thing and so building a chroot environment for it would also be a complex thing.
Then I came across systrace in OpenBSD. systrace allows for an application to be wrapped by it so that any system calls can be audited and blocked if they do not match the policy. There is even an option to automatically generate a policy based on what the application uses during normal use, which can of course be edited by hand later. This appeared to be a perfect convenient solution to the problem. Unfortunately, it seems that systrace has some fundamental flaws that prevent it from being reliable as a security tool. The idea was good, but the way in which OpenBSD implements system calls just doesn’t allow for the sort of thing that systrace was aiming for.
So, building a sandbox is either going to involve a complicated initial setup (the chroot) or an inconvenience every time I want to browse the web (a virtual machine). It seems the long term solution is going to be do build the chroot, but until then, it would be nice to have at least a slightly more secure system than Firefox alone provides. This is when I came across xombrero, which I’m using to write this blog post. According to the xombrero website:
xombrero is a minimalist web browser with sophisticated security features designed-in, rather than through an add-on after-the-fact. In particular, it provides both persistent and per-session controls for scripts and cookies, making it easy to thwart tracking and scripting attacks.
In additional to providing a familiar mouse-based interface like other web browsers, it offers a set of vi-like keyboard commands for users who prefer to keep their hands on their keyboard.
The default settings provide a secure environment. With simple keyboard commands, the user can “whitelist” specific sites, allowing cookies and scripts from those sites.
It seems that “secure by default” is not actually the case in the build I’m using (from the OpenBSD 5.3 packages repository) but it was easy enough to disable JavaScript and cookies. This way nothing is enabled until it’s actually needed and at that point you can make the decision, although not necessarily an informed one, as to whether or not you want to take the risk.
Of course, I’m still vulnerable to malicious code in sites I thought I could trust, and helpless to libpng exploits as images are loaded by default and any bugs in the HTML/CSS rendering engine (WebKit in the case of xombrero) but this is definitely a step closer to the secure browser I’m dreaming of. The trouble with the web is that it’s always becoming a more complex system when really, for a lot of sites, simpler would definitely be better.

Full disk encryption is becoming (it should always have been) more popular. When your laptop gets stolen, a login password is only a minor inconvenience to a hacker trying to steal your identity. Pop in a live CD or USB stick with Knoppix or Backtrack (or in fact basically any Linux distribution) and all your information is there for the attacker to use to steal your identity, impersonate you online and perhaps even empty your bank accounts. By booting not into the installed operating system, but into their own, the computer obeys the attacker and any protection your login password could have offered is irrelevant as the installed operating system isn’t running. If an attacker has physical access to a machine and enough time, it becomes the attacker’s machine, but the data doesn’t have to become that attacker’s data. This is where full disk encryption comes in.
OpenBSD long ago tackled the problem of swap data persisting through reboots by introducing encrypted swap partitions. For swap, the Blowfish cypher is used, as it is strong, fast, with a big key space. Obviously, there’s a small speed penalty but in my opinion, definitely worth it for the added security. Encrypted swap was easier to implement than full disk encryption as swap isn’t actually needed until the system has already booted, or at least, once a considerable part of the system has been loaded. Full disk encryption though requires that the computer is able to boot using encrypted media so all the tools to decrypt the disk must be present in the boot loader. OpenBSD 5.3 is capable of booting from an encrypted disk, but it took a while to get here. For a full technical discussion on the problems see this blog post on Ciphertite.
If you’re looking for instructions on how to set up full disk encryption on OpenBSD 5.3, these are the instructions I used, and I recommend them.
After setting the system up, I realised that I’d had to come up with three (disk encryption, root user and local non-privileged user) secure easy-to-remember-hard-to-guess passwords that to be secure I was going to have to change regularly. Once my OpenPGP card arrives, I’ll be able to replace the root and local non-privileged user passwords with the smartcard and PIN but until then, I’ll have to make sure I can remember them.
Unfortunately, the ability to boot from encrypted media is only present on i386 and amd64 so my SPARC Classic is going to have to settle for an encrypted /home partition. I plan on using it only for the offline generation and storage of crypto keys so this isn’t really a big deal.